수식기반 모델
Linear Regression-회귀,분류
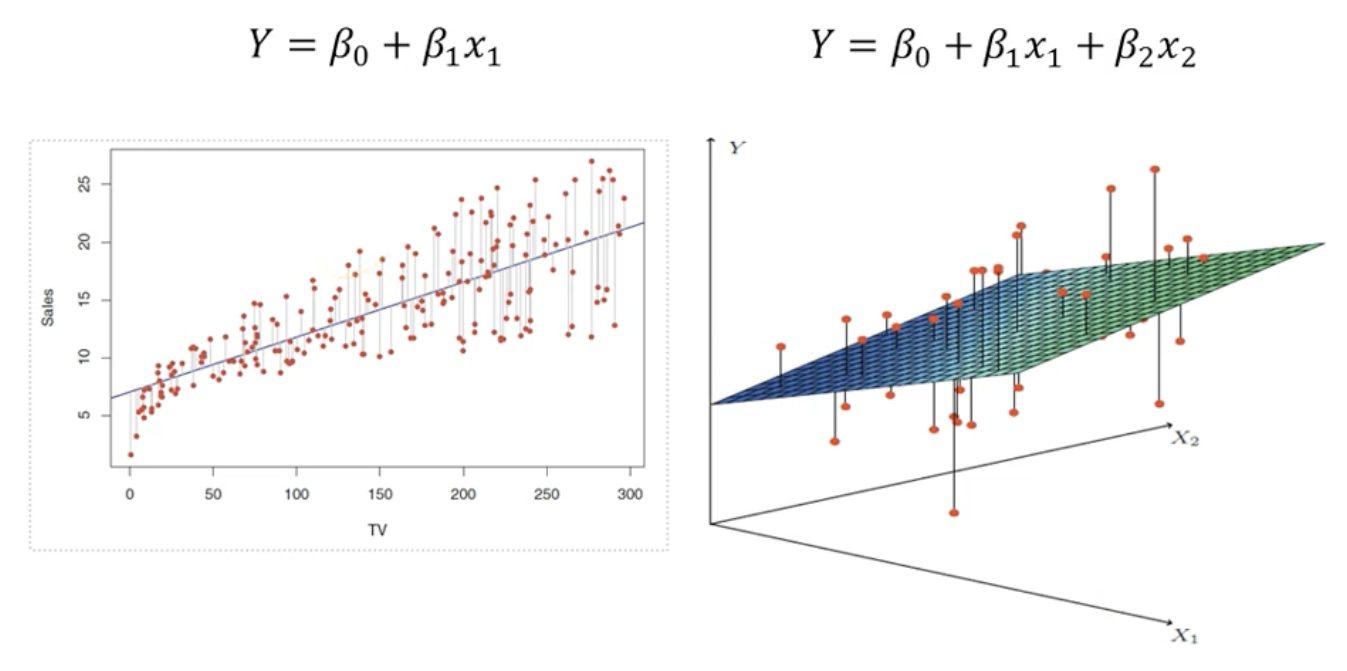
- 단순 성형 회귀(특성이 1개) : y=Wx+b
- 다중 선형 회귀(특성이 여러개) : y=W1x1+W2x2+...+Wnxn+b
- 입력된 특성들로 선형함수를 만들어 예측
- 경사하강법을 통해 훈련 데이터셋으로 부터 나타나는 오차를 최소화 할 수 있는 선 결정
- 특성이 적은 경우 다른 모델의 성능이 더 나을 수 있음
- 복잡도를 제어할 방법이 없어서 과적합되기 쉬움
Lasso(L1)
- Linear Regression의 과대적합을 방지할 목적으로 등장
- 절대값으로 제약을 줘서 통해 일반화된 모형을 찾음
- 가중치들이 0이되게 함으로써 특성 선택 효과
- 많은 특성 중 일부만 중요한 특성일 때 효과적
Ridge(L2)
- Linear Regression의 과대적합을 방지할 목적으로 등장
- 라쏘와의 차이점이라면 제약을 비율로 줘서 가중치들이 0에 가까워질 뿐 0이 되지는 않는다
- 특성이 많을 때 중요도가 전체적으로 비슷할 때 효과적
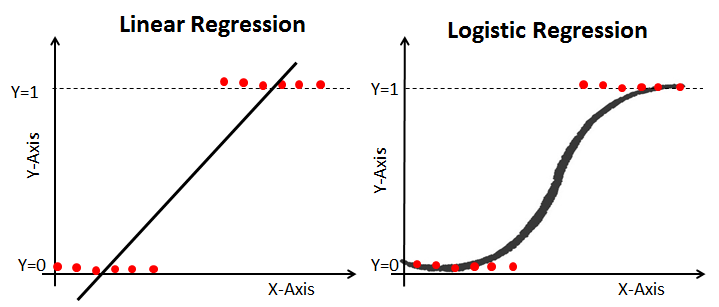
Logisitic Regression-분류
- 선형회귀로는 fitting하기 어려운 경우 곡선으로 fitting하기위해 logistic함수를 사용해 로짓변환
- 새로운 데이터가 어떤 범주에 속할지 확률을 0~1사이 값으로 예측
거리기반 모델
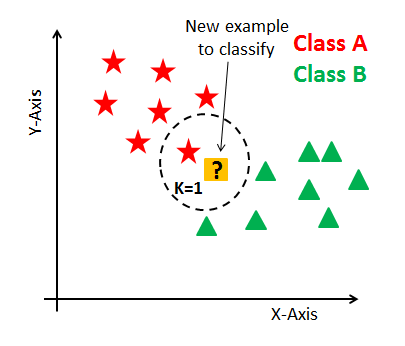
KNN(k-Nearest Neibors)-분류,회귀
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터셋의 데이터 포인트를 찾아 예측
- k 값에 따라 가까운 이웃의 수가 예측값을 결정
- 분류와 회귀 모두에 사용 가능
- 적은 이웃을 참조할수록 모델의 복잡도 상승 ➡️ 과대적합
- 많은 이웃을 참조할수록 ➡️ 과소적합
- 훈련 데이터 세트가 크면 예측이 느림
- 거리를 측정하기 때문에 특성간 scale이 같도록 정규화 필요
- 수백 개 이상의 많은 특성을 가진 데이터 세트와 특성 값 대부분이 0인 희소(sparse)한 데이터 세트에는 잘 작동하지 않음
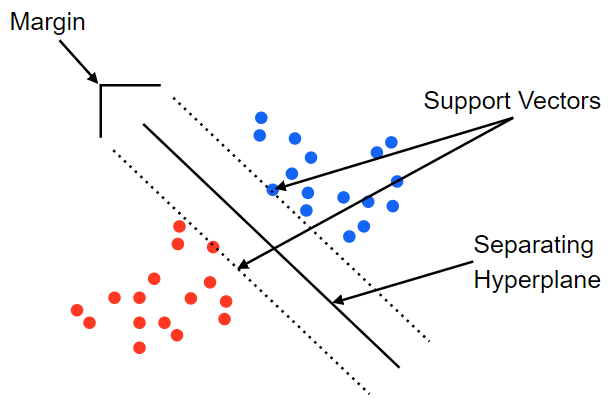
SVM(Support Vector Machine)-분류
- 서포트벡터머신은 마진이 최대가 되도록 결정 경계선을 긋고 새로운 데이터 포인트가 어느 경계에 속하는지 예측
- 특성이 2개가 아니라 3개가 되면 3차원으로 늘어나며 경계는 선이 아닌 평면(그 이상은 초평면)
- 선형으로 분리할 수 없는 경우 커널을 사용
- 선형 데이터 뿐만아니라 비선형적이고 고차원 공간에서도 성능이 탁월
- SVM은 이상치를 얼마나 허용할 것인지가 매우 중요
- 앙상블로 사용하기도함
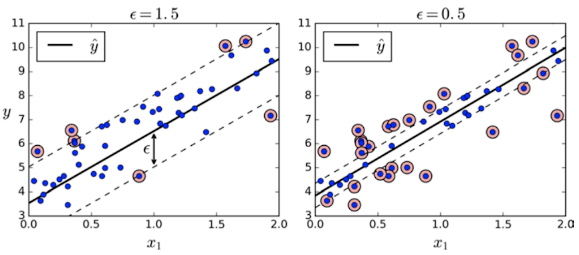
SVR(Support Vector Regressor)-회귀
- SVR은 SVM과 반대로 마진 내부에 데이터가 최대한 많이 들어가도록 학습
- 마진의 폭은 epilson이라는 파라미터를 사용하여 조절
논리기반 모델
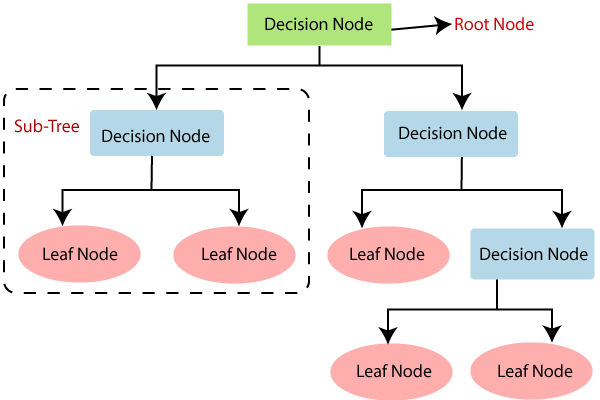
Decision Tree-분류,회귀
- 새로운 데이터 포인트가 들어오면 해당하는 노드를 찾음
- 분류면 더 많은 클래스를 선택, 회귀라면 평균을 구함
- 각 특성이 개별 처리되기 때문에 데이터 스케일링에 영향을 받지 않아 특성의 정규화나 표준화가 필요업음
- 트리 구성 시 각 특성의 중요도를 계산하기 때문에 특성 선택에 활용 가능
- 훈련 데이터 범위 밖의 포인트는 예측 불가(ex:시계열 데이터)
- ❓엔트로피(Entropy) :
- ❓지니불순도(Gini Impurity) :
- 모든 노드가 순수 노드가 될 때 까지 학습 ➡️ 과대적합
앙상블
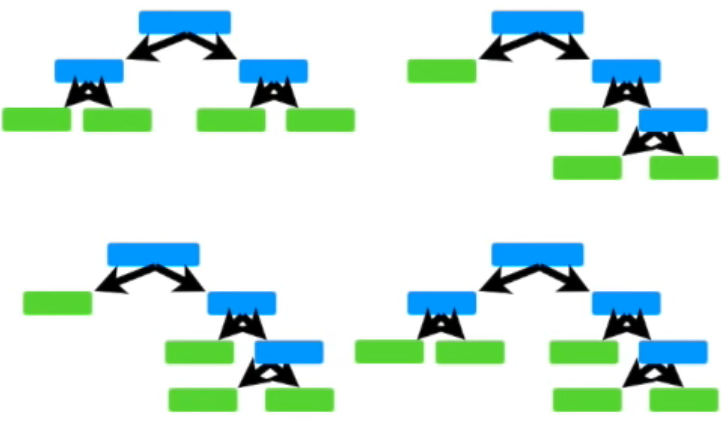
RandomForest
- 의사결정 나무를 활용한 앙상블 모델(배깅)
- 여러 개의 트리의 결과를 합산해서 최종 예측(다수결의 원칙, 각각의 트리는 동등한 가중치)
- 여러개의 의사결정 나무를 만들고 숲을 이뤄서 Forest라 불림
- Random은 의사결정 나무에 쓰이는 특성을 랜덤하게 선택하기 때문
- 결측치를 다루기 쉬움
- 대용량 데이터 처리에 효과적
- 과적합 문제를 어느정도 회피하여 정확도 향상 가능
AdaBoost
- 스텀프를 활용한 앙상블 모델(부스팅)
- ❓stump : 노드 하나에 두개의 리프를 지닌 트리
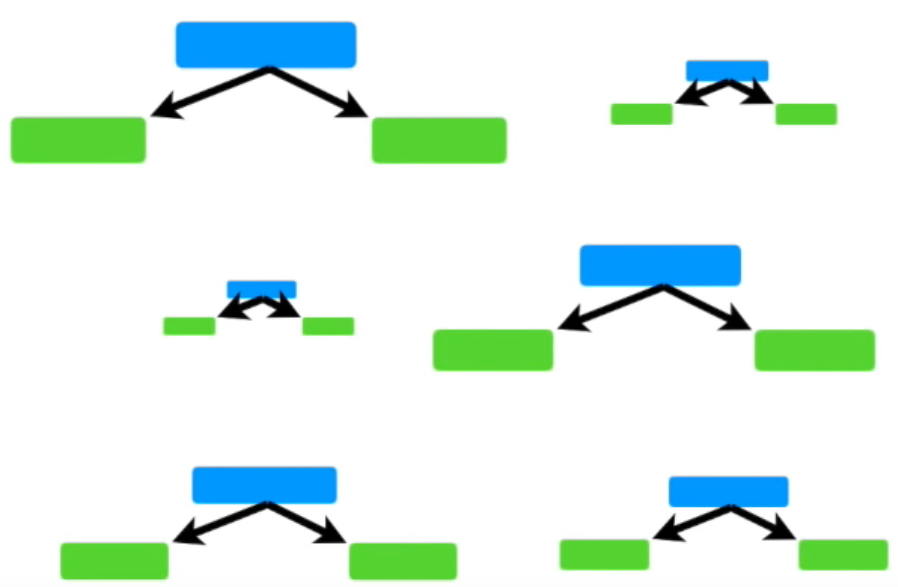
- AdaBoost는 아래와 같이 여러개의 stump로 구성
- 여러 질문을 통해 분류하는 트리와 다르게 stump는 하나의 질문으로 데이터를 분류해서 약한 학습기
- 랜덤 포레스트와 달리 특정 stump가 다른 stump보다 더 중요(가중치가 더 높음)
- 또한 부스팅의 특성 상 앞에서 발생한 error는 뒤의 stump에 영향을 미침
GBM(GradientBoost)
- 의사결정 나무를 활용한 앙상블 모델(부스팅)
- stump나 tree가 아니라 leaf부터 시작?

velog에는 이론을 주로 정리하고, 코드와 관련된 것은 Git-hub로 관리하고 있어요. 포트폴리오는 링크된 Yun Lab 홈페이지를 참고해주시면 감사하겠습니다!