Problems with deeper layers
-
AlexNet부터 VGGNet으로 가면서 더 깊은 네트워크가 더 좋은 성능을 낸다는 것을 확인하였다.
-
모델의 깊으면 더 복잡한 관계에 대해 학습이 가능하고, receptive field를 가지기 때문에 신중히 결론을 내릴 수 있기에 좋은 성능이 나온다.
-
이 논리라면 깊이를 무조건 깊게하면 성능을 높일 수 있지만, 여기에는 gradient vanishing/exploding 문제가 나타난다.
-
또한, 계산복잡도가 올라가기에 더 큰 GPU가 필요하다
-
이전에는 모델 파라미터 수가 표현력이 과하게 좋으니 overfitting에 취약할 것이다 라고 생각했지만, overfitting이 아닌 degradation problem 때문이라는 것이 밝혀졌다.
GoogleNet
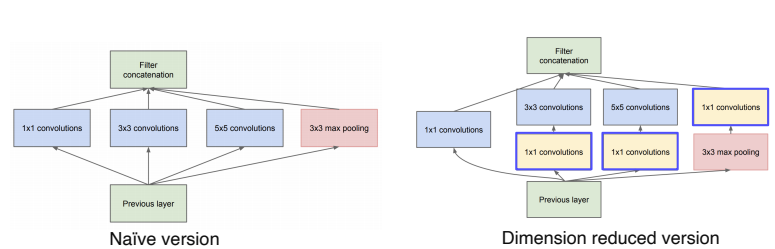
- Inception module
- 하나의 레이어에서 다양한 크기의 convolution filter를 사용하여 여러 측면으로 activation을 관찰한다.
- 이 모듈은 깊이가 아닌 수평으로 layer를 확장시켜서 나타난 activation map들을 채널 축으로 concat하여 다음 블록으로 넘겨주는 구조이다.
- 하지만 이렇게 한 층에 여러 필터를 많이 사용하게되면 계산복잡도와 용량이 커지게 되는데 이를 해결하기 위해 1x1 convolution을 사용한다.
- 또한, MaxPooling 단계에서도 1x1 convolution을 사용하여 채널 차원을 맞춰주었다
1x1 convolutions
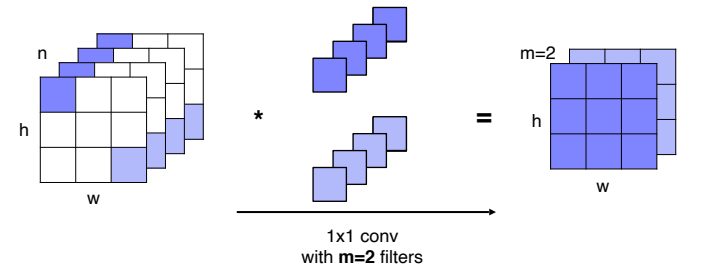
- activation map상에서 픽셀 위치에 해당하는 채널 축으로 값들을 쌓으면 하나의 벡터로 표현할 수 있다.
- 이렇게 생성된 feature vector와 1x1 convoluiton인 filter의 내적을 하고 이를 sliding window 방법을 통해 모든 픽셀에 대한 계산을 거치면 공간의 크기는 유지하면서 채널의 수를 조절할 수 있다.
- 위의 그림은 n개의 채널을 2개의 채널로 변경하는 예시이다.
Googlenet 구조
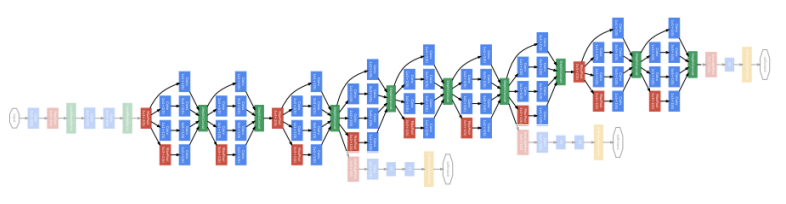
- 일반적인 CNN 구조로 몇 단계 거친다
- Inception module을 여러 단계 쌓는다.
- 이렇게 깊게 쌓으면 gradient vanishing이 생기기 때문에 중간중간 Auxiliary classifier를 통해 gradient를 직접 주입 해준다.
- 최종 출력은 하나의 fc layer를 통해 soft max classification score를 출력하는 구조
Auxiliary classifier
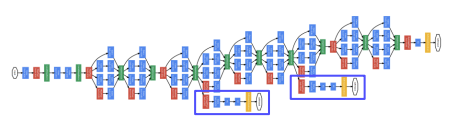
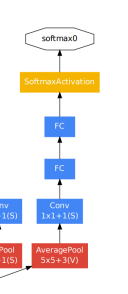
- 최종 부분까지 gradient가 중간에 소실되지 않게 도와주는 역할을 하기 위한 classifier
- 두 개의 fc layer와 1x1 convolution layer 하나로 구성된다.
- 위의 그림에서 파란색 박스에 해당하는 부분은 학습 도중에만 사용하고 실제 test시에는 제일 마지막 부분의 classifier 만을 결과만 사용한다.
ResNet
- 지금도 대부분의 backbone과 실험은 Resnet을 기본으로 할 만큼 큰 영향력을 발휘하고 있는 네트워크
- 최초로 100개 이상의 layer를 쌓음으로써 네트워크의 깊이가 깊어질수록 성능이 증가하는 것을 보여주는 첫 논문
- 처음으로 ImageNet 대회에서 인간성능을 뛰어넘는 네트워크로 classifier뿐만 아니라 localization, detection, segmentation 모두 1등을 차지한 모델이다.
https://velog.io/@ysw2946/ResNet
DenseNet
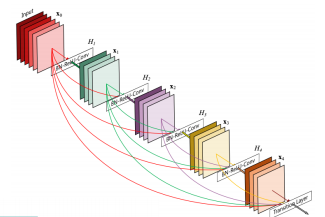
- Resnet에서는 skip connection을 통해 identity mapping을 더했지만, DenseNet에서는 채널 축으로 concat 한다.
- concat을 통해 채널은 늘어나지만 feature의 정보를 그대로 보존할 수 있다.
- 바로 직전 블록의 입력을 더해주는 것 뿐만 아니라 그 이전의 블록들의 입력도 더해줌으로써 상위 레이어에서도 하위 레이어의 특징들을 참조해서 재활용할 수 있는 기회를 제공한다.
SENet
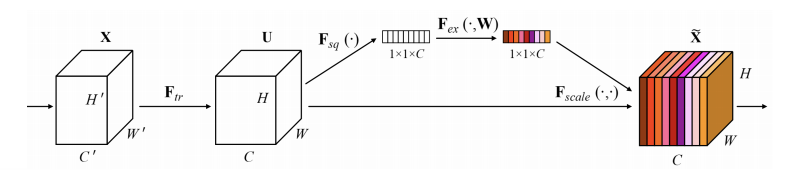
-
현재 주어진 activation 관계가 명확해질 수 있도록 channel간의 관계를 모델링하고 중요도를 파악해서 attention을 할 수 있게 하는 방법론
-
attention의 방법
- Squeeze
- global average pooling을 통해 각 채널의 공간 정보를 없애고 분포를 구한다.
- Excitation
- fc layer하나를 통해 channel간의 연관성을 고려해본다.
- 하나의 벡터가 들어왔을때 W를 곱하여 channel을 gating하기 위한 attention score를 생성한다.
- Squeeze
-
이렇게 생긴 attention과 입력 attention으로 activation을 re-scaling하여 중요도가 떨어지는 것은 값을 낮추고, 중요도가 높다고 생각하는 것은 더욱 강하게 만드는 작업을 수행한다.
EfficientNet

-
성능을 높이기 위한 네트워크 설계 방법
- width scaling
- 채널 축을 늘리는 작업, 즉 googlenet의 inception module과 같이 채널의 폭을 넓히는 작업 수행
- depth scaling
- resnet과 같이 깊이를 더 깊게 쌓음
- resolution scaling
- input 이미지의 resolution(해상도)을 애초에 크게 넣어준다.
- width scaling
-
compound scaling
- 위의 3가지의 scaling들이 있는데, 이 방법들은 어느 순간 saturation 상태가 온다.
- 따라서, 이 3가지를 적절하게 어떤 비율을 통해 동시에 scaling을 하면 더 효과적인 모델이 나오지 않을까 해서 compound scaling 방법이 나타났다.
-
이렇게 compound scaling을 사용한 efficientnet가 나타났다.
Deformable convolution
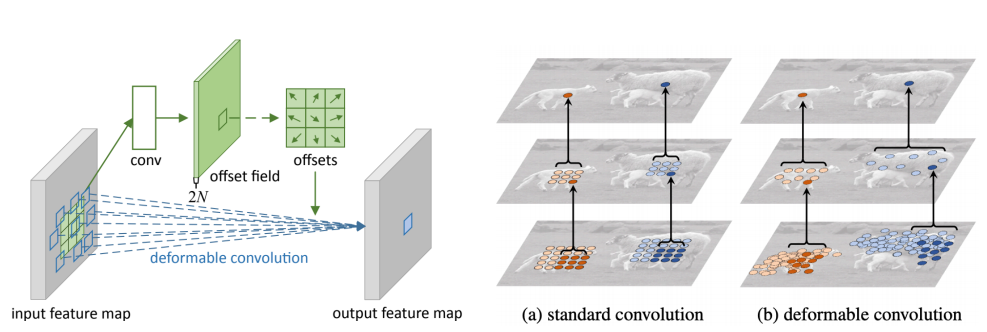
-
자동차 같이 형태가 일정한 것 외에 팔과 다리가 움직이는 사람과 동물 같은 Irregular 한 이미지를 인식하기 위해서는 deformable한 부분이 고려되어야 한다.
-
위의 그림에서는 fix된 3x3 만큼의 파라미터가 존재하고, 이 외에 2d offset map을 추정하기 위한 branch가 따로 결합이 되어있다.
Deformable convolution
- input이 들어오고 offset filed를 생성한다.
- 이에 따라 각각의 weight들을 벌려준다.
- 이 위치에 맞게끔 activation과 irregular한 filter를 내적을 해서 한 가지 값을 도출하게 된다.
Summary of image classification
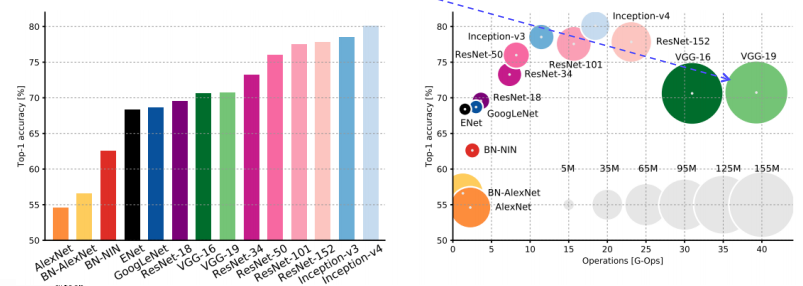
-
원의 크기는 모델의 사이즈를 의미한다.
-
AlexNet
- image net scale에서 작동하는 가장 간단한 구조로써, 다른 애들에 비해 사이즈가 결코 적지 않으며, 성능이 낮다.
-
VggNet
- 간단한 3x3 conv로 구현이 되어있음에도 속도가 가장 느리고, 모델 사이즈도 가장 많이 차지한다.
-
GoogleNet
- inception 계열 network
- 최근 efficientnet에 비하면 성능이 좋지 않다.
-
ResNet
- 많은 layer 수를 자랑하면서도 vgg에 비해서는 적절한 계산량을 보이며, 메모리 사이즈도 좀 더 적은 것을 볼 수 있다.
- 하지만 inception 계열 네트워크보단 확실히 크고 느리다.
-
이렇게 보면 GoogleNet은 AlexNet, VggNet, ResNet과 비교해서 가장 효율적인 CNN으로 볼 수 있다.
-
하지만, 학습과 이용을 조금 복잡하게 만드는 요소들이 있고, 수평적인 확장을 구현하기가 어려운 부분이 있다.
