Semantic segmentation
- 지난번의 image classification을 영상 단위가 아닌 픽셀단위로 수행하는 것
- 하나의 픽셀이 어느 객체인지를 구분하는 문제 → 하나의 영상 안에 있는 모든 객체를 검출
- semantic segmentation을 사용하게 되면 object들이 나눠지게 되고 이 특징들을 이용하여 특정 object만 변경할 수 있다.

Fully convolution networks(FCN)
-
first end-to-end semantic segmentation
-
이전에는 여러 알고리즘의 결합으로 semantic segmentation을 수행했었기 때문에, 데이터가 많더라도 학습 가능한 부분이 굉장히 제한적이었다.
-
예를 들어, Alexnet에서 convolution layer 뒤쪽에 flatten을 통하여 벡터화를 시켜주는데 이렇게 되면 입력 해상도가 호환되지 않아 학습된 fc layer를 사용하지 못하는 한계가 존재한다.
-
이러한 한계는 FCN을 통해 입력으로 임의의 해상도를 넣을 수 있으며, 입력 해상도에 맞는 출력을 나타낼 수 있게 됨으로 한계를 뛰어 넘게 되었다.
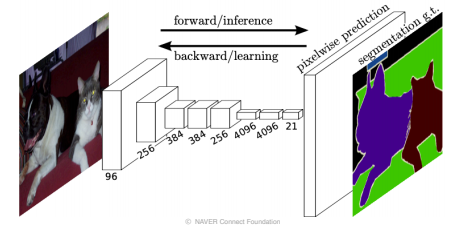
fully connected layer vs fully convolutional layer
- fully connected layer(fc layer)
- 기본적으로 공간적인 정보를 고려하지 않고 fix dimension의 벡터가 주어지면 또 다른 fix dimension의 벡터로 변환해주는 layer이다.
- fully convolutional layer
- 입력을 activation map로 받아 공간 정보를 포함(spatial coordinates)하는 activation map을 출력할 수 있다.
- 보통 1x1 conv로 구성이 되며, 각 위치마다 classification을 결과를 출력하는 map형태로 출력이 정해진다.
FCN with 1x1 convolutions
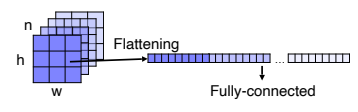
- Alexnet에서는 이전 layer에서 activation map이 출력이 되면 flattening을 통해 벡터화를 시켜 fc layer의 input으로 넣어 분류를 하게 되는데, 이때 출력은 영상의 공간 정보를 포함하지 않는다.
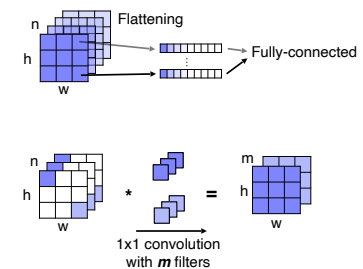
-
위치 정보를 담기 위해서 각 위치마다 channel 축으로 flattening하여 벡터 형식으로 쌓게 되면 그 위치에 대한 정보를 포함하는 벡터를 생성할 수 있다.
-
1x1 conv layer는 위의 방법과 동일한 연산으로 activation map에서 각 위치 별 channel 축으로 1x1 kernel 연산은 한 것은 fc layer의 한 weight columns으로 볼 수 있다.
-
convolution 연산은 sliding window 방식으로 weight를 공유하면서 적용되기 때문에 위치 정보가 유지될 수 있다.
-
따라서, FCN은 fc layer를 convolution layer로 대체함으로써 어떤 입력사이즈에도 대응가능한 네트워크를 만들 수 있다.
-
위의 방법으로 출력된 결과는 pooling과 stride에 의해 매우 작은 해상도의 출력이 나타나기 때문에, 이를 다시 원본 이미지의 해상도에 맞게끔 키워줌으로써 semantic segmentation을 진행한다.
-
이때 사용하는 방법이 Upsampling이다.
Upsampling
- stride나 pooling을 제거하게 되면 receptive filed를 키울 수 없고, 반대로 넣게 되면 해상도가 작아지는 trade off가 일어나게 된다.
- 그래서 일단은 작게 만들어서 Upsampling을 통해 해상도를 맞춰주는 방법을 사용한다.
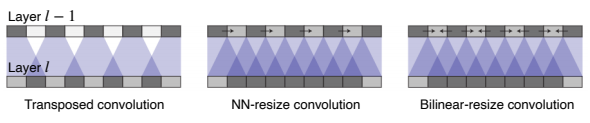
-
Transposed convolution
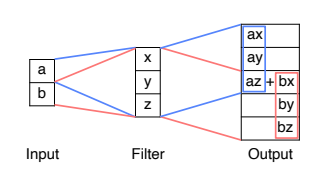
- 두 개의 입력이 들어왔을 때 filter를 해당 위치에 집어 넣어 중첩된 부분은 더하여 나타낸다.
- 여기서 주의해야 할 점은 중첩되는 부분이 계속 더해지기 때문에 kernel size와 stride를 잘 조절해서 중첩되는 부분이 생기지 않게 신경써서 튜닝해야 한다.
- 하지만 이러한 방법은 Upsampling과 convolution을 같이 이용하는 것으로 쉽게 구현 할 수 있으면서 성능도 좋게 만들 수 있다.
-
NN-resize convolution & Bilinear-resize convolution
- upsampling operation을 두 개로 분리하여 간단한 영상 처리 방법을 사용되는 Nearest-neighbor , Biliner 와 같은 보간법을 사용였다.
- 여기까지는 어떤 학습가능한 파라미터가 들어가지 않고, 그저 해상도만 키워주었다.
- 이제 학습가능한 learnable upsampling으로 만들어 주기 위해 convolution layer를 적용해준다.
-
다시 FCN..
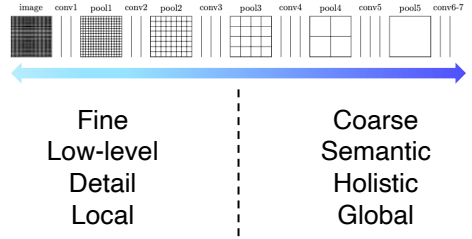
- 이렇게 Upsampling을 이용하여 해상도를 다시 늘린다 하더라도 이전에 잃어버린 정보를 다시 살리기는 쉽지 않다.
- 낮은 layer쪽은 작은 차이에도 민감한 경향이 있기에 세세한 의미를 파악할 수 있으며, 높은 layer쪽에서는 큰 receptive filed를 가지기 때문에 전반적으로 global한 의미를 파악할 수 있다.
- Semantic segmentation을 위해서는 각 픽셀별로 의미를 파악해야하고, 영상 전체를 바라보면서 현재 픽셀이 물체의 경계선 안쪽에 해당하는지에 대해 알아야 하므로 위의 두 특징 모두 필요하다.
-
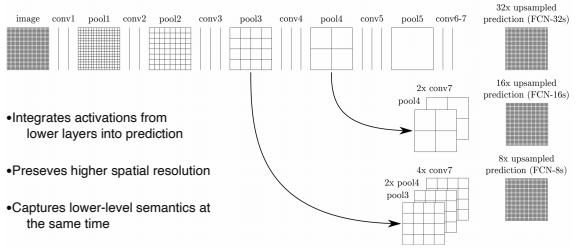
두 특징을 모두 가져오기 위해 높은 layer 뿐만 아니라 중간 layer들도 Upsampling을 통해 해상도를 늘려서 가져온다.
-
이후 가져온 layer들을 concat하여 최종 출력을 나타내는데, 위의 사진과 같이 사용된 layer에 따라 모델이 달라진다

- FCN-32s : 단순히 맨 마지막 fc layer를 fc convolutional layer로 변경한 것
- FCN-16s : FCN-32s에서 추가로 pool4에서 정보를 가져와서 만든 모델
- FCN-8s : FCN-32s에서 추가로 pool3 , pool4 에서 정보를 가져와서 만든 모델
Hypercolumns for object segmentation
- FCN과 비슷하게 semantic segmentation을 target으로 하는 논문
- FCN과의 차이점은 강조하는 부분이 낮은 layer와 높은 layer를 융합하는 부분이었고, fully convolution layer 또는 1x1 conv를 강조하지는 않았다.
- FCN의 마지막 부분과 같이 낮은 layer와 높은 layer를 융합하는 방법을 제시
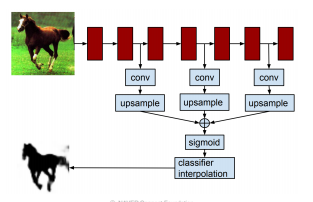
- 여기서 소개하는 방법은 end-to-end가 아니고, 다른 third party 알고리즘을 사용하여 물체의 bounding box를 추출한 뒤 적용하는 방법으로 소개되었다.
U-Net
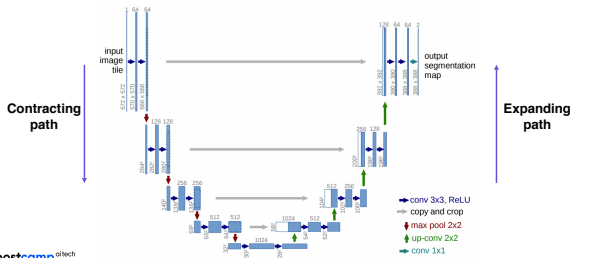
- 영상 전체가 아닌 일부분을 자세하게 보는 대부분 기술의 기원은 U-net이 있다.
- 이 네트워크 역시 fully convolutional networks이며, skip connection을 통해 낮은 layer와 높은 layer를 조금 더 잘 융합할 수 있게 설계되었다.
- U자처럼 보이는 구조를 띄기 때문에 U-Net이다.
Architecture
-
Contracting path
- 처음 입력 부분을 살펴보면, 입력을 여러 convlution layer를 통과시키고 receptive field를 크게 확보하기 위해서 pooling을 통해 해상도를 낮추는 대신 channel수를 늘린다.
- 이를 반복하여 작은 activation map을 구하고 이것에 영상의 전반적인 정보가 포함되어 있다고 가정한다.
-
Expanding path
- U-net에서 달라지는 부분은 decoding이라 불리우는 Upsampling이 달라지는데, 한번에 upsampling 하는 대신 점진적으로 activation map의 해상도를 늘리고 channel을 줄여준다.
- 이 때 단계 별로 이전의 contracting path의 채널 수와 receptive filed크기와 대칭으로 대응되게 동일하게 맞춰서 낮은 layer에 있던 activation map을 합쳐서(concat) 사용할 수 있게 만든다.
-
skip connection
- expanding path를 진행하면서 contractiong path의 activation map을 융합하는데, 이 때 resnet처럼 더하는 방식이 아닌 concatenation을 하여 사용한다.
-
위의 과정을 거치면 낮은 layer서 전달되는 특징이 localized한 정보를 가지고, 높은 layer에 전달된다.
- 공간적으로 높은 해상도와 입력이 약간 바뀌는 것 만으로 민감한 정보를 제공하기 때문에, 경계선이나 공간적으로 중요한 정보들을 뒤쪽 layer에 바로 전달하는 역할을 한다.
-
U-net에서 주의해야 할 점
- contracting 과 expanding 의 activation map을 concat하기 위해서는 차원이 맞아야 하는데, activation map이 홀수를 가지게 되면 어떻게 될까?
- 7 x 7 activation map을 downsampling 하게 되면 보통 버림이 되어서 3 x 3이 나타난다.
- 이를 다시 upsampling하게 되면 7 x 7 이 아닌 6 x 6이 생성되고 이 둘을 concat할 수 없게 되므로 activation이 홀수가 되지 않게 항상 유의해야 한다.
Implementation
# contracting path
def double_conv(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3),
nn.ReLU(inplace=True)
)
self.dconv_down1 = double_conv(3,64)
self.maxpool_2x2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.dconv_down2 = double_conv(64,128)
self.maxpool_2x2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.dconv_down3 = double_conv(128,256)
self.maxpool_2x2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.dconv_down4 = double_conv(256,512)
self.maxpool_2x2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.dconv_down5 = double.conv(512,1024)
# extracting path
self.up_trans_1 = nn.ConvTransposed2d(in_channels=1024,out_channels=512, kernel_size=2, stride=2)
self.up_conv_1 = double_conv(1024,512)
self.up_trans_2 = nn.ConvTransposed2d(in_channels=1024,out_channels=512, kernel_size=2, stride=2)
self.up_conv_2 = double_conv(1024,512)
self.up_trans_3 = nn.ConvTransposed2d(in_channels=1024,out_channels=512, kernel_size=2, stride=2)
self.up_conv_3 = double_conv(1024,512)
self.up_trans_4 = nn.ConvTransposed2d(in_channels=1024,out_channels=512, kernel_size=2, stride=2)
self.up_conv_4 = double_conv(1024,512)
self.out = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1)DeepLab
- semantic segmentation에서 중요한 한 획을 그음.
- 여기서 핵심은 conditional random field(CRF)라는 후처리의 존재와 atrous convolution이라 불리는 convolution operation의 사용 이 두 가지이다.
Conditional Random Fields(CRF)
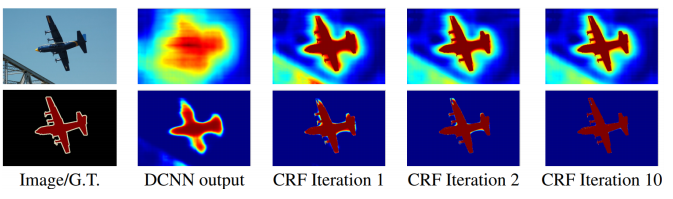
-
픽셀과 픽셀 사이의 관계를 모두 이어주어 regular 한 grid를 그래프로 나타내어 경계를 잘 찾을 수 있게 모델링
-
처음 결과를 뽑고 나면 처음 사진처럼 굉장히 흐릿한 출력이 나타나는데, 이를 해결하기 위해 러프하게 나온 출력 스코어맵이 이미지의 경계선에 잘 들어맞게 하기 위해 확산을 시켜준다.
-
반대로 배경에 대한 스코어맵은 물체의 안쪽과 바깥쪽 모두 확산이 일어나게 만들고, 물체의 마스크와 배경의 마스크를 타이트하게 만들어준다.
-
이를 반복하면 맨 오른쪽의 그림과 같이 물체를 잘 구분할 수 있는 결과를 얻을 수 있다.
Atrous convolution(Dilated convolution)
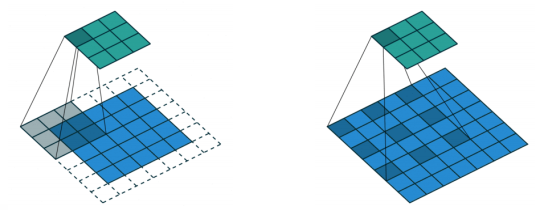
- convolution kernel 사이에 일정 공간을 넣어주어 실제 convolution kernel보다 넓은 영역을 고려하게 만들면서 파라미터 수는 유지할 수 있다.
- 이를 단순히 반복함으로써 receptive field 사이즈를 확 증가시킬 수 있는 효과를 얻을 수 있다.
Depthwise separable convolution
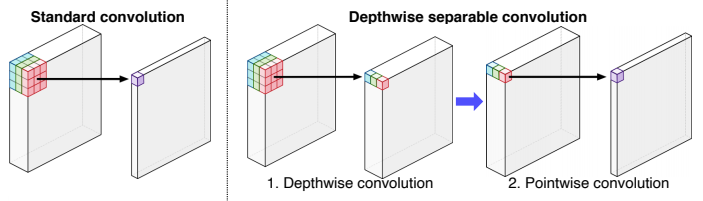
- Deeplab v3+ 에서는 semantic segmentation의 입력 해상도가 너무 크기 때문에 연산이 오래걸리는 것을 줄여보기 위해 Dilated convolution과 Depthwise separable convolution을 결합한 방법을 사용했다.
- 이는 기존의 activation map 생성 방법을 두 단계로 나누었는데, 각 channel축으로 convlution하여 값을 뽑는 단계와 이 값을 또 다시 convolution하는 단계로 나누었다.
- 이를 통해 파라미터 수를 줄이는 효과를 얻을 수 있었다고 한다.
- standard conv : → 6승
- depthwise separable conv : → 5승 + 4승
Deeplab v3+
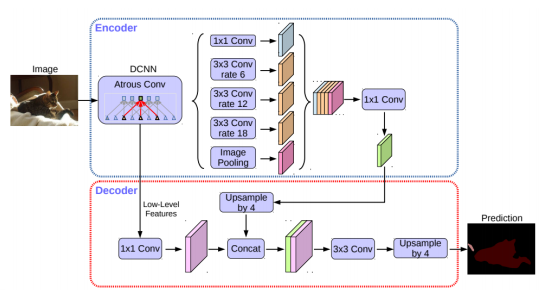
- Dilated convolution을 통해 더 큰 receptive filed를 가지는 CNN을 적용
- 영역별로 연관되는 주변 물체, 배경과의 거리가 모두 다르므로, 다양한 rate에 Dilated convolution를 사용하여 multi scale을 처리할 수 있는 Atrous spatial pyramid pooling을 구현하였다.
- 이렇게 구해진 feature map들은 하나로 concat하여 1x1 conv를 통해 합쳐준다.
- 이후 decoder 단계를 통해 low level feature와 pyramid pooling을 거친 feature를 결합하고 upsampling을 통해 최종 결과를 출력하는 구조로 이루어져있다.
