2. Annotation Data Efficient Learning
Data Augmentation
-
우리가 학습에 사용하는 데이터는 모두 사람이 보기 좋게 찍은 사진들이지만, 실제 데이터들은 어떻게 들어올지 모르는 데이터들이다.
-
우리의 데이터셋이 real data를 충분하게 표현하지 못한다면 여러 문제가 발생한다.

eg ) 밝은 영상으로만 이루어진 데이터로 모델을 학습시켰을때 이 모델이 어두운 배경의 고양이가 들어왔을 때 제대로 인식하지 못한다.
-
이러한 경우 Data Augmentation을 활용하여 이 세상에 찍힐 수 있는 여러 데이터를 표현할 수 있게 가능성을 높일 수 있다.
-
Brightness adjustment
-
이미지 밝기를 높이기 위해서는 단순히 숫자를 더하는 것으로 할 수 있다.
-
여기서 주의해야 할 점은 이미지가 0 ~ 255 를 넘지 않게 조절해 줘야 한다.
def brightness_augmentation(img): img[:,:,0] = img[:,:,0] + 100 img[:,:,1] = img[:,:,1] + 100 img[:,:,2] = img[:,:,2] + 100 img[:,:,0][img[:,:,0]>255] = 255 img[:,:,1][img[:,:,1]>255] = 255 img[:,:,2][img[:,:,2]>255] = 255
-
-
Rotate, flip using OpenCV
-
opencv를 통해 상하좌우 변환은 쉽게 구현할 수 있다.
img_rotated = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE) img_flipped = cv2.rotate(image, cv2.ROTATE_180)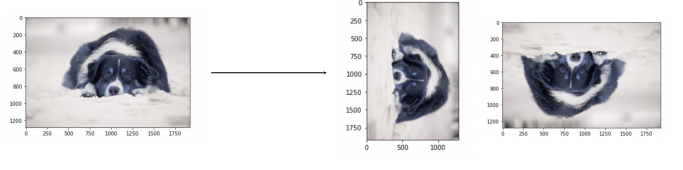
-
-
Crop
-
다음과 같이 인덱싱을 통해 구현할 수 있다
y_start = 500 crop_y_size = 400 x_start = 300 crop_x_size = 800 img_cropped = image[y_start : y_start + crop_y_size, x_start : x_start + crop_x_size, :]
-
- Affine transform
-
변환 전과 후에도 선은 선대로 유지가 되고, 길이의 비율과 평행관계가 유지되는 변환을 말한다.
-
변환된 사진의 3개의 점을 변환 후에도 형태를 그대로 유지할 수 있게 대응하는 쌍을 지정하여 변환할 수 있다.
rows, cols, ch = image.shape pts1 = np.float32([[50,50],[200,50],[50,200]]) # 변환 전 pts2 = np.float32([[10,100],[200,50],[100,250]]) # 변환 후 M = cv2.getAffineTransform(pts1,pts2) shear_img = cv2.wrapAffine(image, M, (cols,rows))
-
- CutMix
-
다른 두 영상을 합치는 방법인데, 이 때 라벨도 같은 비율에 따라 합성해 주는 것이 중요하다.
-
이 방법을 사용하면 의미있는 수준의 성능향상과 물체의 위치를 정교하게 캐치할 수 있게 할 수 있다.

-
- RandAugment
- 다양한 augmentation 영상을 만들기 위해서 여러 기능들을 조합하여 각자 전혀 다른 새로운 영상들을 만들 수 있다.
- 이러한 여러 기능들의 조합을 모두 해볼순 없으니, 랜덤하게 기능들을 샘플링해서 수행해보고 그 중 성능이 잘 나온 것을 가져다 쓰는 기법
- 두 가지의 파라미터
- 어떤 방법들을 사용할까?
- 어느 정도로 적용할까?
Leveraging pre-trained information
-
데이터를 적게 쓰고도 좋은 성능을 내기 위해서 다른 데이터 셋에서 학습된 정보를 활용하는 방법
-
Transfer learning
- 기존의 학습시켜 놓은 사전 지식을 활용하여 연관된 새로운 task에 적은 노력으로도 높은 성능에 도달할 수 있다.
- 다른 데이터 셋이지만 영상이라는 공통점과 일부에서는 비슷한 패턴을 찾을 수 있다.
- 한 데이터 셋에서 배운 지식 중에 다른 데이터 셋에 적용할만한 공통된 지식이 의외로 많지 않을까 해서 탄생한 것이 Transfer learning
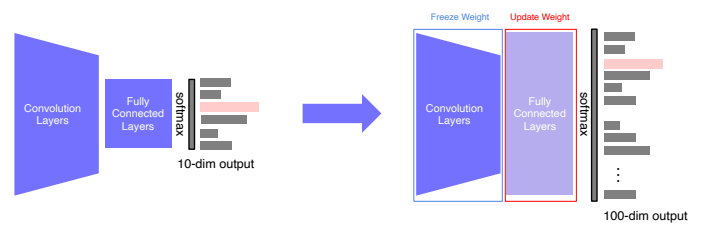
- Convolution Layer는 fix시켜놓고 fc layer만 업데이트하는 방식으로 학습
- Convolution Layer는 낮은 lr로 학습시켜 업데이트가 느리게 되고, 새로운 fc layer는 높은 lr을 사용하여 새로운 target task에 빨리 적응하게 된다.
knowledge distillation(Teacher-student learning)
- 이미 학습된 Teacher 네트워크의 지식을 더 작은 모델인 student 네트워크에 주입하여 학습하는데에 많이 사용된다.
- 큰 네트워크에서 작은 네트워크로 지식을 전달함으로써 모델 압축에 유용하게 사용할 수 있는 방법이다.
- 이때, student 네트워크는 teacher 네트워크보다 더 작은 모델을 사용하는 것이 일반적이다.
standard Knowledge distillation
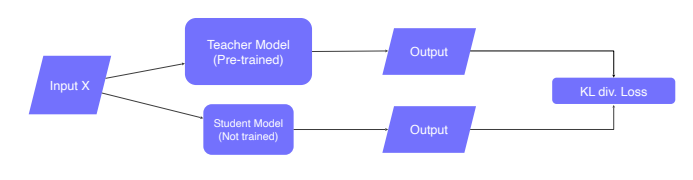
- Pretrained model을 teacher model로 준비하고 아직 학습되지 않은 student model을 initialization한다.
- input을 동시에 두 모델에 feeding하여 output을 출력한다.
- 두 output의 차이를 KL div.Loss를 이용하여 측정하고 student model만 역전파를 통해 학습한다.
-
이 과정은 결국 student 모델이 teacher 모델의 행동을 따라하게 만드는 학습법이라고 이해할 수 있다.
-
또한, label을 전혀 사용하지 않았으므로 unsupervised learning에 해당하며, 임의의 데이터를 사용할 수 있다.
-
레이블이 존재할 때의 Knowledge distillation
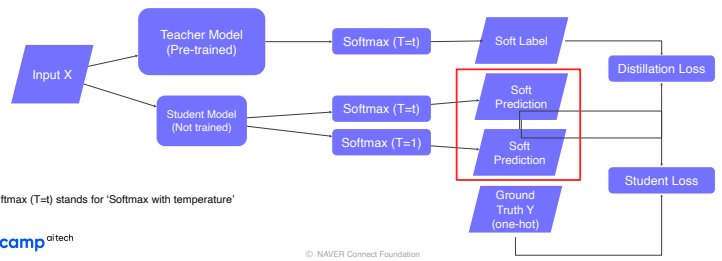
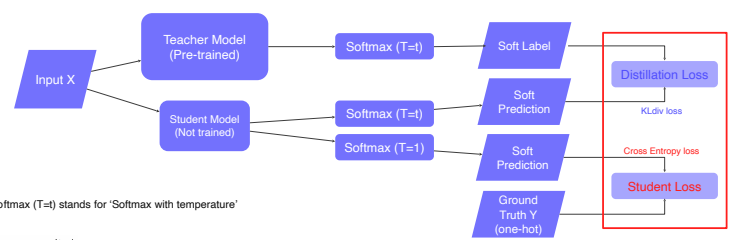
- ground truth label을 사용한 loss를 student loss라고 하며, teacher를 따라하게 만드는 KL-divergence loss를 Distillation Loss라고 한다.
- 이때 특징은 Distillation loss를 구할 때 soft prediction 을 사용한다.
Soft Prediction
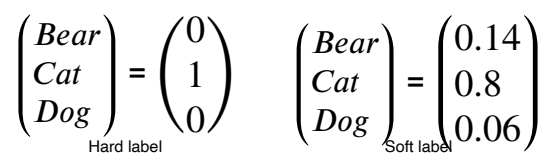
- Hard label
- 0과 1이 binary 형태(One-hot vector)
- Soft label
- 0과 1의 binary 형태가 아니라 이 사이값들을 말한다.
- 각각의 값들의 전반적인 경향성이 knowledge를 나타낸다고 가정을 하고 하나의 모델이 입력을 보고 어떤 생각을 하고 있는지 soft label을 통해 확인할 수 있다.

- 0 또는 1 의 값만 가지는 것 보다 0과 1사이의 중앙값도 가지면서 입력에 따라 민감하게 변하는 신호를 따라하게 만들어 student가 teacher를 더 잘 따라할 수 있게 한다.
- teacher에서 나온 output이 pretrained할 때 사용되었던 이전의 task class와 연관이 되어있지만, student loss로 학습하는 데이터는 pretrained 데이터와 전혀 상관이 없다.
- 따라서, teacher output으로 생성된 soft label에 내포되어 있는 각각의 값들의 의미가 중요하기 보다는, 전체적인 개형이 추상적인 형태의 지식을 표현하고 있고, 이를 student가 이를 따라하게 하는 것이 중요하다.
-
Distillation Loss
- KLdiv(Soft label, Soft prediction)
- 두 개의 분포의 차이, 거리를 재는 Loss로 sum to one인 probability distribution을 갖는다.
- Teacher 와 student 의 prediction의 차이를 측정하고, student가 teacher 를 따라하게 하는 Loss
-
Student Loss
- CrossEntropy(Hard label, Soft prediction)
- Hard label이 ground truth를 통해 주어지기 때문에, Cross Entropy를 사용
- student 네트워크가 실제 True label과 일치하게 만드는 Loss
-
결국에는 Distillation Loss와 Student Loss의 weighted sum을 통해 Soft prediction 부분으로만 역전파가 이루어져 학습이 진행된다.
Leveraging unlabeled dataset for training
- Semi-supervised learning
- unlabeled 된 엄청난 양의 데이터와 label된 적은 양의 데이터를 둘 다 활용하는 학습법
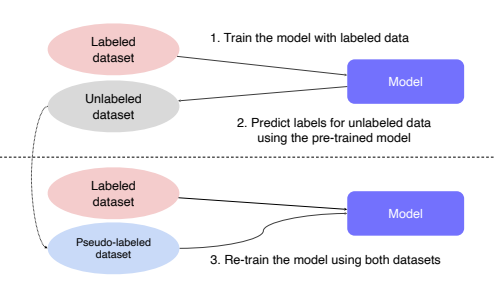
- labeled dataset으로 pre-train하여 model 생성
- unlabeld dataset을 model에 넣어 가짜 label을 가지는 데이터 셋 생성
- 생성된 가짜 label dataset과 labeled dataset을 합쳐서 이전의 모델을 다시 재학습
Self-training
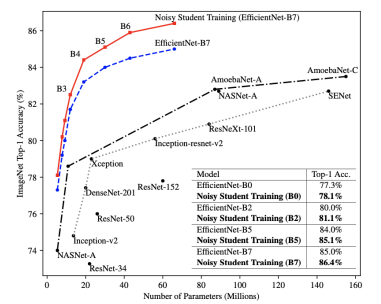
- 2019년 당시 image classification에서 가장 높은 성능을 보여주는 방법
- Augmentation + Teacher-Student networks + semi-supervised learning
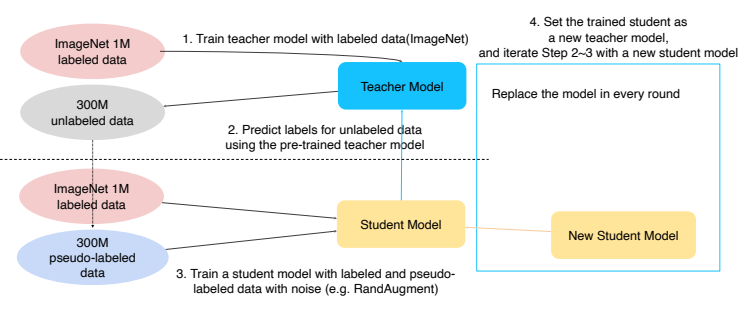
- ImageNet dataset을 teacher 모델을 미리 학습
- unlabled된 데이터를 방금 학습한 모델을 이용하여 가짜 label이 생성된 데이터 셋 생성
- 이 두 데이터셋 을 합쳐서 Student model을 학습시키는데, randAugment를 이용해서 더 방대한 양의 데이터를 학습시킨다.
- 마지막으로, student 모델의 학습이 끝나면 이전의 Teacher model을 날려버리고 방금 학습한 student 모델을 Teacher 모델로 하여 1~3을 반복한다.
