[PaperRevie]Deep Learning for Anomaly Detection:A Review, An Evalution of Anonamaly Detection and Diagnosis in Multivariate Time Series
0
paper review&implementation
목록 보기
2/7
1. PURPOSE
- 이상탐지 관련 여러가지 deep learning 기반 모델에 대해 파악하고 각 모델들에 대한 실험 결과를 확인할 수 있음
- 최적 모델을 선정하는데 평가 기준 지표에 대한 이해를 바탕으로 추후 진행될 실험과 모델 선정에 도움이 될것으로 생각됨
2. CONTENTS
Introduction
- 적절한 anomaly scoring function
- 기존 이상탐지 방법론의 모델 성능 향상
- 모델의 차이보다 더 중요할 수 있음
- 최적의 evaluation metric 선정 :
- 이상 탐지시 Robust한 metric으로 F1 score를 사용
- 기존 F1 score는 이상에 대한 event 단위가 아닌 time point 단위로 evaluation 하므로 robust 하지 않음
- event 단위로 이상탐지를 수행하는 metric을 논문에서 제안
Background
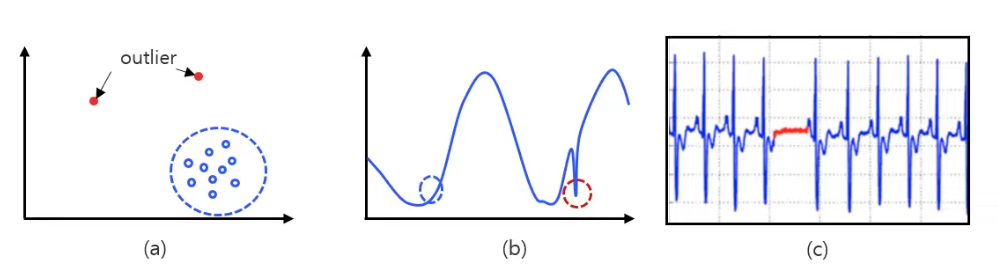
이상치 종류
- Pattern 종류 에 따른 분류
- Point outlier : 특정 point 들이 outlier 된 경우
- Contxtual outlier : 흐름상 이상한 경우
- Collective outlier : 하나의 점으로는 이상하지 않지만 모여져 있을때 전체 패턴과 상이한 경우
- 비교 범위에 따라 분류
- Local outlier (LOF) : local한 지점만 봤을때 이상치
- GLobal outlier : 전체를 봤을 때 이상치
- Input data type 에 따라 분류
- Vector outlier : multi-dimension으로 이루어진 data(numeric or categorical value)
- Graph outlier : 데이터간 상호 의존성을 나타내는 node와 edge로 이뤄진 data
이상치 탐지 방법론 분류
- Supervised Learning
- Semi-Supervised Learning
- 정상 데이터만 가지고 모델 학습 (정상과 다른 pattern을 이상으로 탐지) ex. one-class SVM, Deep SVDD 등
- 학습된 boundary가 정상 데이터에 과적합 될 확률이 높음
- 가장 현실적인 모델
- Un-Supervised Learning
- 대부분의 데이터가 normal sample이라는 가정을 통해 label 없이 학습 (ex. PCA, AE)
Deep leaning
- Deep learning 기반 이상탐지
- 단변량 시계열 데이터에 이상탐지에 좋음
- 고전적인 방법에 비해 고차원 데이터와 복잡한 pattern에 대해 더 잘 학습할 수 있음
- Distance based 에 비해 streaming data에 강점이 있음
- window 기반 학습 및 inference를 통해 시계열 시점에 대해 localization 할 수 있음
- Deep learning methods vs Traditional methods
- 딥러닝 기반은 end2end optimization 가능
- DL method 는 anomaly detection 목적에 맞게 represenstation learning 가능

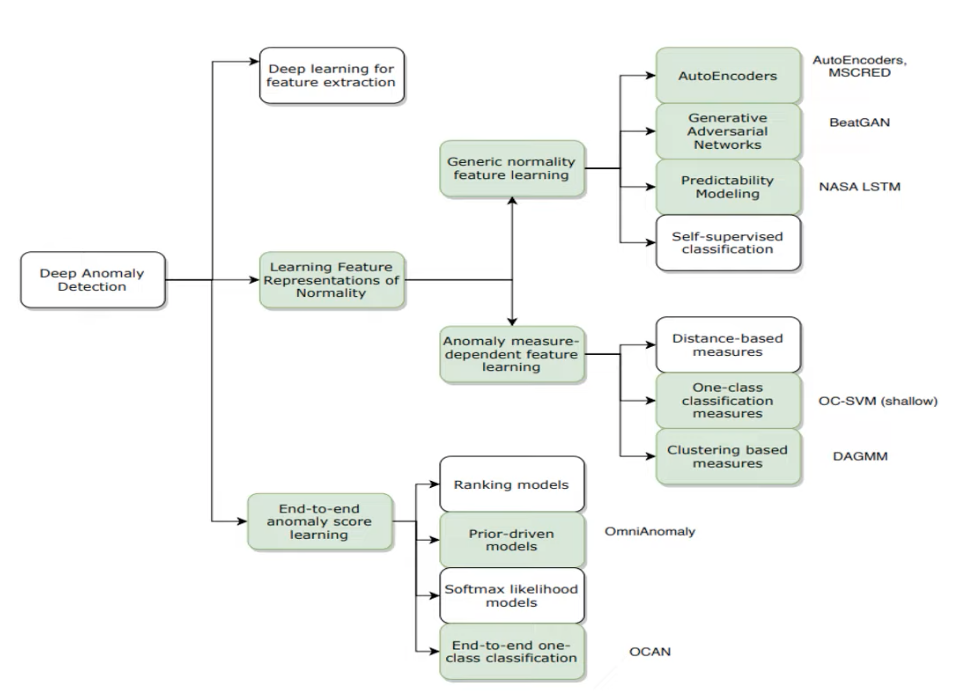
Deep Anomaly Detection approach
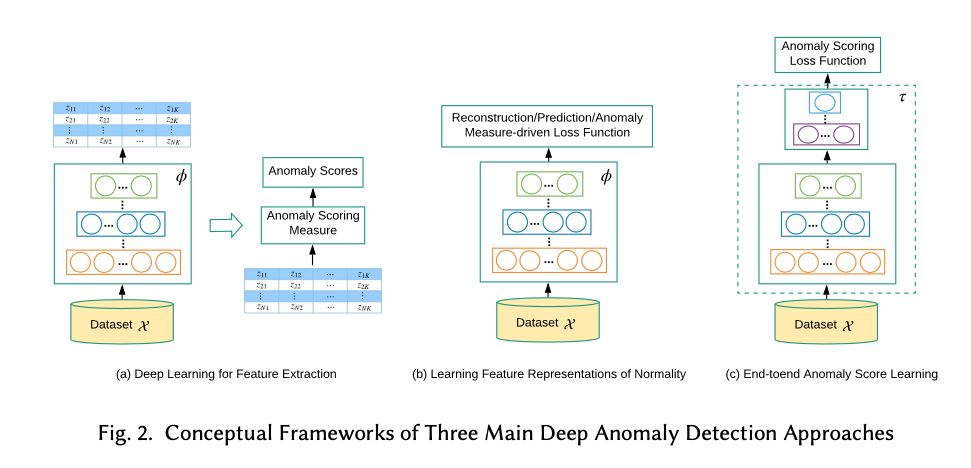
- Deep learning for Feature Extraction
- anomaly scoring과 개별적으로 feature extraction에만 deep learning 사용.
- pre train 모델을 통해 feature extraction 수행
- Learning Feature Representation of Normality
- feature extraction을 하면서 reconstruction error 및 anomaly measure를 통한 output을 도출하는 방법론
- LSTM base AE가 여기에 해당
- End to End Anomaly score learning
- anomaly socre를 loss fuction으로 사용하여 특성 추출 및 anomaly socring 이 이상탐지 목적에 맞춰 한번에 이뤄지는 모델
- PReNet이 여기에 해당
Auto Encoder
- input data가 normal이라고 가정
- inference시 reconstruction error 가 abnormal score값으로 도출
- 미리 선정된 threshold 값 이상의 복원오차 발생시 이상 으로 판단
GAN
- Random Z vector를 입력하여 fake data 생성
- generator에서 나온 fake 데이터와 실제 데이터를 discriminator로 구분
- generator로부터 생성된 데이터와 실제 데이터의 차이를 이용하여 anomaly score 산출
- AE 방식과 유사
- BeatGAN 등이 있음
- Discriminator를 이용해 AE구조에서 output이 더 input에 가까운 결과를 갖도록 함
- AE의 경우 regularization term이 없어 overfitting 될 수 있지만 discriminator로 인해 정규화됨
- generator를 통해 생성된 output - input 차이를 anomaly score로 산출 → 큰 방식은 AE와 같음
one class 이상탐지
- Deep SVDD
- 딥러닝을 통해 feature extraction을 하고 정상 데이터를 둘러싸는 가장 작은 구를 찾아 구 밖의 데이터를 이상치로 규정
Clustering
- GMM
- 데이터가 여러개의 가우시안 분포로 결합되어 있다는 가정으로 개별 데이터를 각각의 가우시안 분포로 묶는다.
- Expetation : 개별 데이터의 각 정규분포에서의 likelihood를 계산하여 가장 높은 확률을 가진 정규분포에 할당
- Maximization : 각 그룹의 데이터 포인트를 이용하여 MLE를 통해 모평균과 모분산 추정
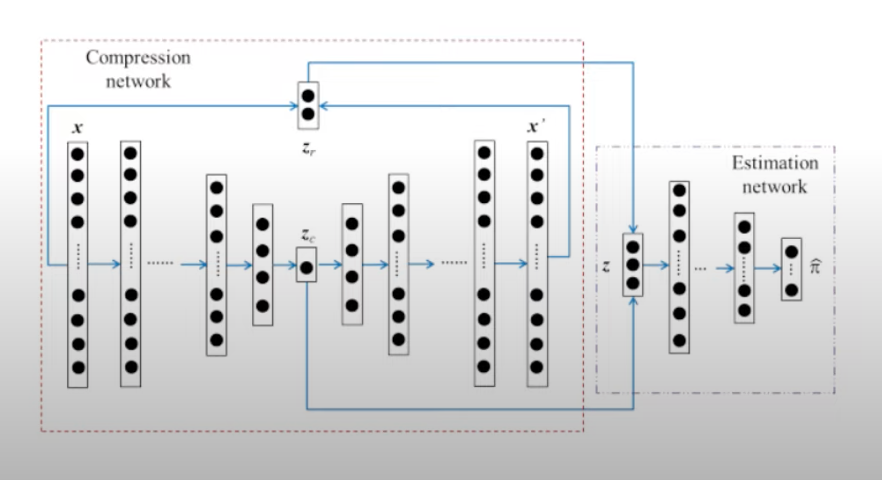
- DAGMM
- AutoEncoder를 이용한 압축 네트워크와 GMM을 이용한 estimation 네트워크로 구성
- 저차원 데이터의 정보와 복원된 output을 모두 활용하여 GMM을 진행
Omni-Anomaly (A stochastic RNN for Anomaly detection)
- 잘 모르겠음
Methodology
Problem setting
- anomaly detection
- only normal dataset으로 학습한 후 streaming test data에 대해서 이상탐지 검증
- 어떤 변수로 인해 이상으로 탐지되었는지 검증하는 task
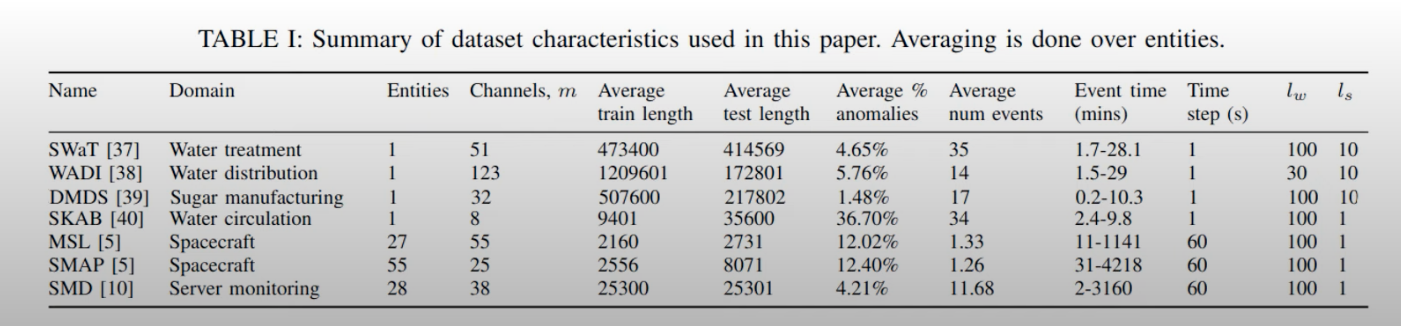
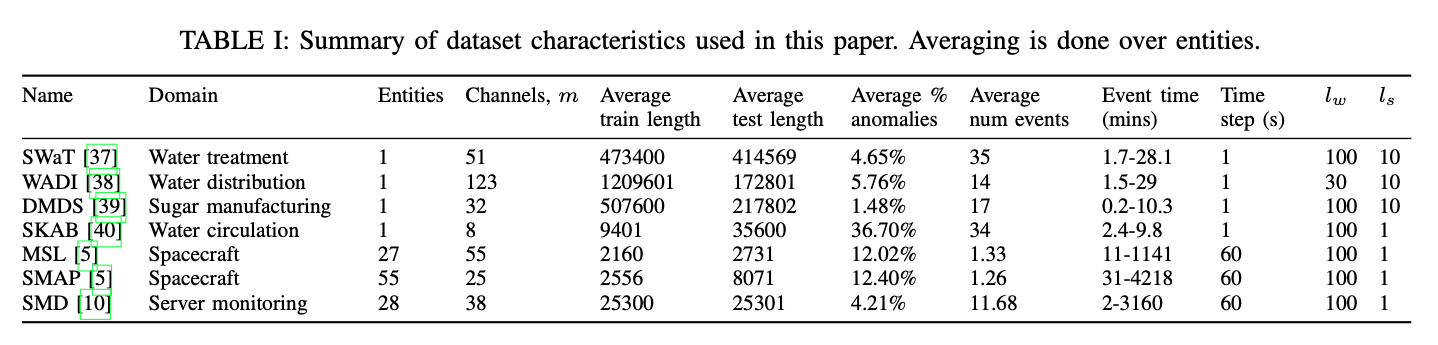
- Data set
- 7개의 다변량 시계열 데이터를 이용하여 실험 진행
- 사용된 데이터셋은 cross channel anomaly를 가지지 않고 temporal anomaly에 초첨을 두고 연구 수행
Modular Framework
- First Modul : Reconstruction or prediction model,
- 데이터 복원 및 예측을 통한 reconstruction error 기반 anomaly detection
- : i번째 channel, t 번째 time point의 error값
- Second Module : Scoring function
- t번째 시점에서 모든 channel의 anomaly score를 산출
- : 첫 번째 모듈에서 얻은 error를 각 channel 별 anomaly score로 변환 이상 구간에서 가장 높은 이상치를 갖는 channel구분시 사용
- : 각 channel별 이상치를 합하여 해당 시점의 총 이상치 산출
- Final module : threshild function,
- threshold를 값을 설정하여 binary label 도출 ⇒ normal or abnormal
Scoring Function

Threshold Function

Evaluation Metric
- 기존에 사용된 시점 단위의 F-score는 사용하기 단순하지만 실제 현업에서는 event 단위 detection에 더 관심이 많음
- point adjusted F-score()
- 이상에 대해 event 구간에서 하나라도 이상치가 속해있으면 이상으로 구분하는 방법
- 이렇게 구분한 결과를 이용하여 point wise F-score 산출 (기존 방법이랑 같음 )
- 단점으로는 event 구간이 길 경우 제대로 분류하지 않은 경우에도 높은 F-score가 도출될 수 있음
- score
- score는 time-wise precision 과 event0wise recall의 harmonic mean이다.
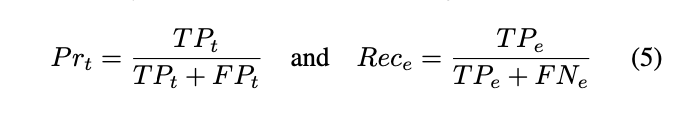
Experiments
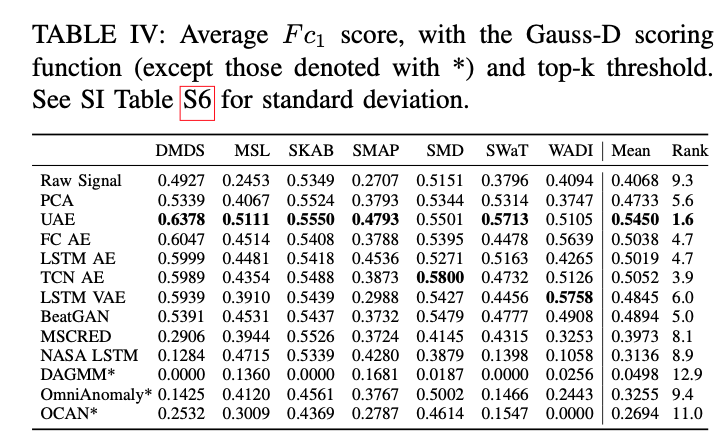
- UAE 가 가장 높은 성능을 보여주고 뒤를 이어 TCN AE, LSTM AE, FC AE 등이 높은 성능을 보였다.
- 하지만 이는 각 채널간의 관계를 고려하지 않는 데이터 셋을 사용했기 때문에 나온 결과로 생각되며 cross channel problem에서는 lstm이나 TCN이 더 좋은 성능을 보일것으로 생각된다.,
Conclusion
- 기존의 F1 score는 구간을 탐색하는 모델 성능을 평가하는데 적절하지 못함 (평가절하 될 가능성이 있음 )
- temporal abnormal이 더 자주 발생하는 domain의 경우 UAE 처럼 각 channel별로 이상치를 산출한 후 총 이상치를 산출하는 것이 모델 성능 향상에 도움이 됨 (논문의 결론)
- 실제로 말이 되는지는 의문
3. RESULT
- 기존에 LSTM based AE에 top-k 방법을 적용하면 더 좋을 것으로 보임
- 기본에 LSTM based AE에 을 조금 변형해서 적용하면 좋을 것 같음
- window에서 30%이상 발생했을때와 같이 여지를 좀 더 넓게 만들면 더 정확한 탐지가 될 것으로 보임
- AE 모델이 크게 나쁘지 않을것으로 생각됨
4. ADDITION
참고자료
[Paper Review] Deep Learning for Anomaly Detection: A Review

머신러닝 엔지니어 김태종입니다. anomaly detection, recommendation system에 관심있습니다.