드디어 드디어 attention is all you need 논문을 정리해봤다. 그 동안 nlp분야에 관심이 크게 없어서 미루고 미뤘었는데 더 이상 이걸 제대로 정리하지 않으면 이 분야에 있다고 말할 수 없는 지경에 다달았다.
2024년 노벨상을 2개나 인공지능 분야에서 받았다. 물론 인공지능의 원류가 되었던 발견에 대해서 상을 주었지만 내가 생각할 때 인공지능의 시작이 neural network 였다면 가장 큰 진보는 transformer 아닐까 싶다. 그런 이유로 미루고 미뤄왔던 Attention is All You Need를 읽어보았다. 볼 때마다 느끼는 거지만 이름을 너무 잘 지었다. 내용을 천천히 읽어보니 왜 이렇게 지었는지도 알 것같다. 정말 attention이 네가 필요로 하는 전부라고 논문은 설명하고 실제로 그렇게 구현하고 있다.
What?
- attention mechanism을 사용한 transformer라는 간단한 구조를 통해 기존의 RNN, encoder and decoder 구조를 뛰어넘는 성능을 보여준다.
- parallelizable and requiring significantly less time to train
RNN은 구조적으로 한계가 있다
- 순서대로 처리해야 하니 병렬처리가 불가능하다.
- factorization trick을 사용해 계산의 진보가 있었고 기타 발전이 있었지만 여전히 근본적으로 순차적 계산이라는 한계가 있다.
In all but a few cases : 일부 경우를 제외하고 전부
지금까지 Attention mechanism은 잘못 사용되어왔다
- attention mechanism은 sequence modeling과 변환 모델을 강제하는 부분으로 통함 되어왔다.
그래서 Transformer가 나왔다.
- RNN은 사용안한다.
- relying entirely on an attention mechanism to draw global dependencies between input and output. →전체적으로 attention mechanism에 의존한다. input과 output사이의 global dependencies를 끌어내기 위해
How?
Background
- 기존의 병렬 작업을 하는 모델들은 두 개의 추상적인 input, output 신호를 연관짓는 수많은 작업들이 위시사이의 거리에서 성장한다. 그리고 이 과정은 position들의 거리 사이에서 의존성을 학습하기 어렵게 만든다.
- Transformer에서는 그런 작업들을 줄인다. 비록 averaging attentio-weighted positions, Multi-Head Attention으로 보완하는 효과 때문에 복원력이 떨어질 지라도
- Transformer는 처음으로 전체를 다 self-attention으로 representation을 계산하는 첫 모델이다.
Model architecture
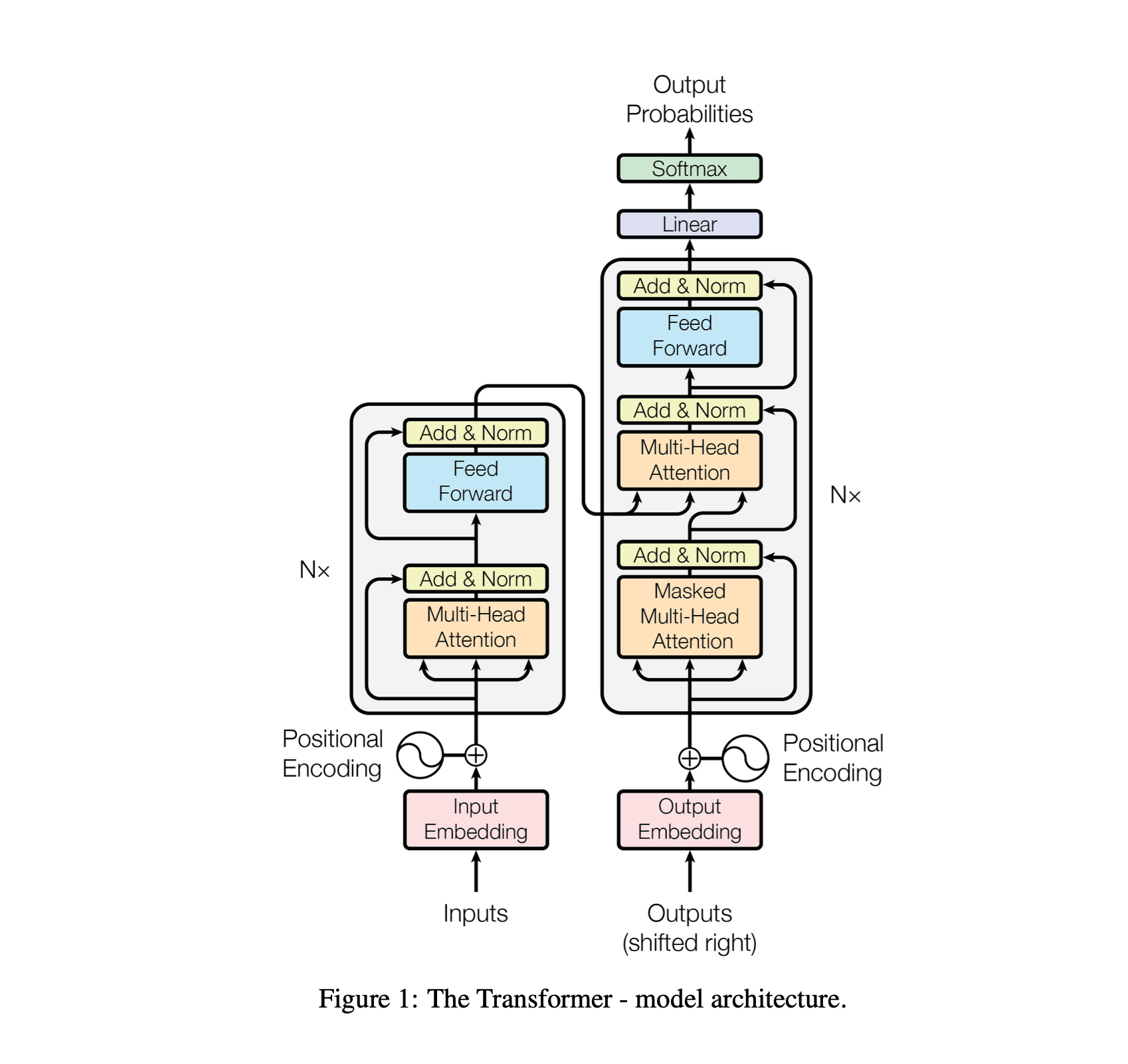
- self-attention and point-wise, fully connected layers로만 이루어짐
Encodewr and Decoder Stacks
Encoder
- a multi-head self-attention mechanism, position- wise fully connected feed-forward network, residual connection
Decoder
- inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack
- We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. → decoder가 아직 등장하지 않은 뒤의 단어를 참조하지 않도록 수정했다.
Attention
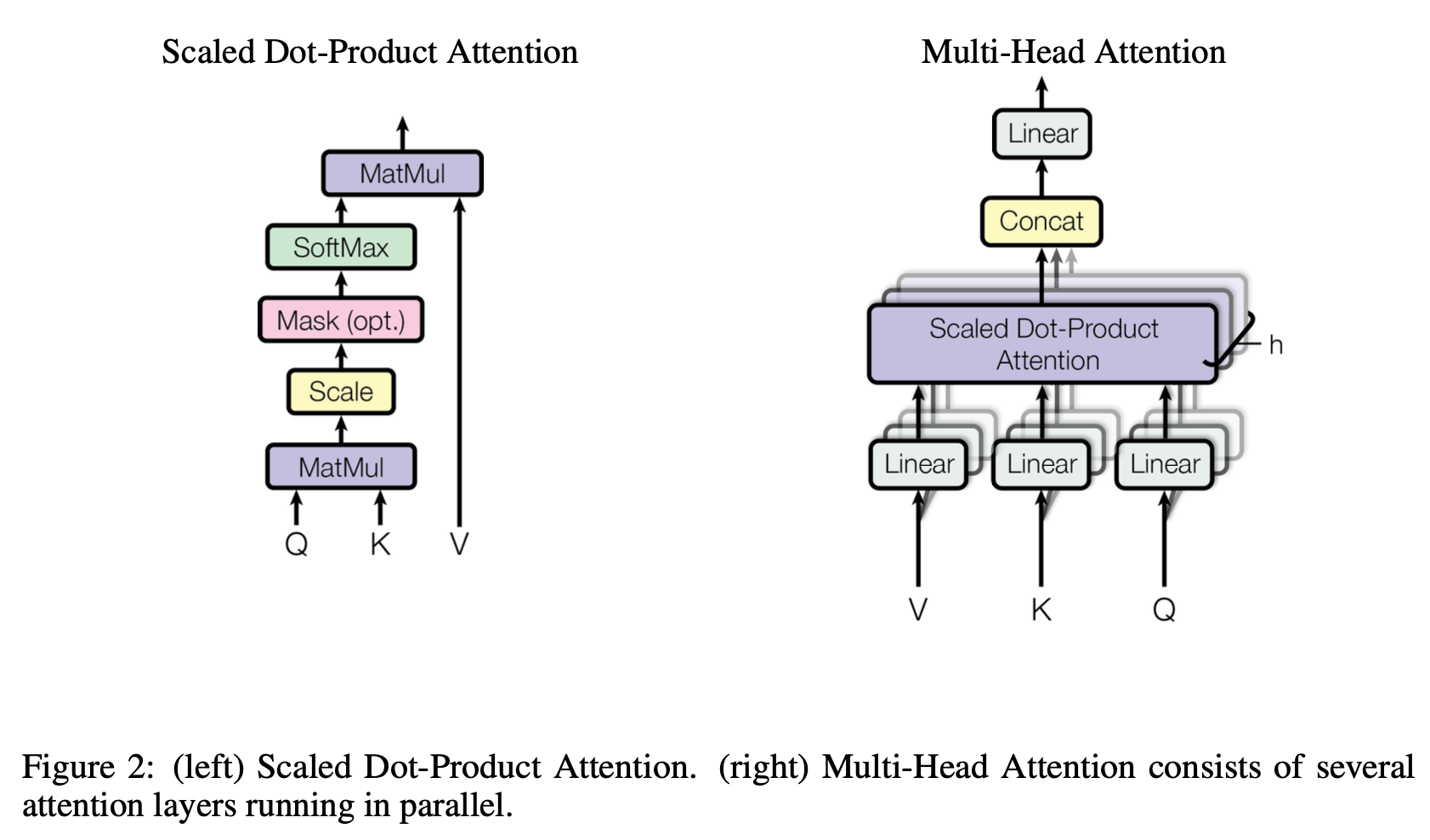
- query, key, value → 모든 단어에 대해서 다 생성된다.
- 간단하게 설명하면 query는 현재 보는 단어, key는 참조할 단어, value는 단어의 가치이다.
- 단어가 3종류의 linear layer를 거쳐서 Q, K, V로 변환되고 scaled dot-product attention에 들어간다.
Scaled Dot-Product Attention
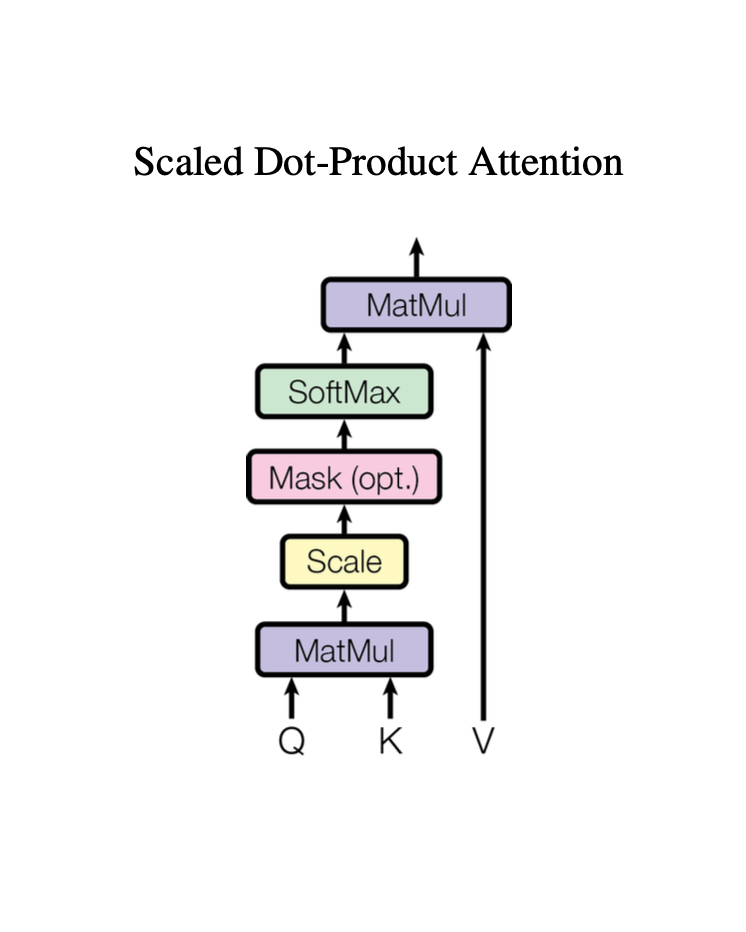
위의 그림을 보면 대부분 이해할 수 있는 구조로 되어있다.
단어가 Q, K, V로 각각 벡터화→ 벡터화 된 → scale(?) →. mask(?) → softmax → matmul for v
이 과정에서 scale과 mask과정이 이해가 가지 않는다.
- 먼저 scale이란 query, key의 벡터 차원 로 나눠주는 것을 말한다. 말 그래도 스케일 조정이다.
- mask(opt.)는 optional mask라는 뜻이다. 위에서 decoder에서만 mask를 사용한다고 했기 때문에 그림에 넣은것 같다. (opt.)가 뭔뜻인지 몰라서 한참 고민했다…..
그래서 결과적으로
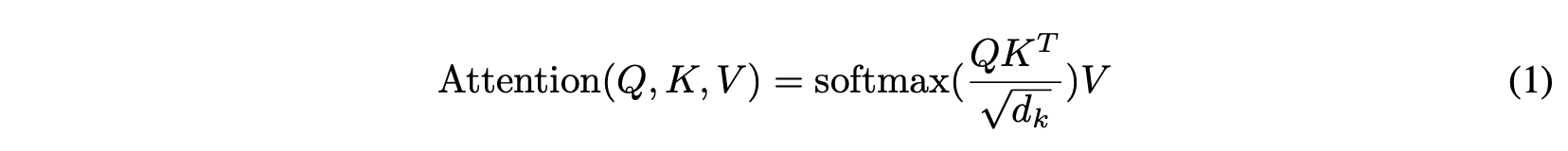
이 간단한 식이 scaled dot product attention의 전 과정이다.
Multi Head Attention
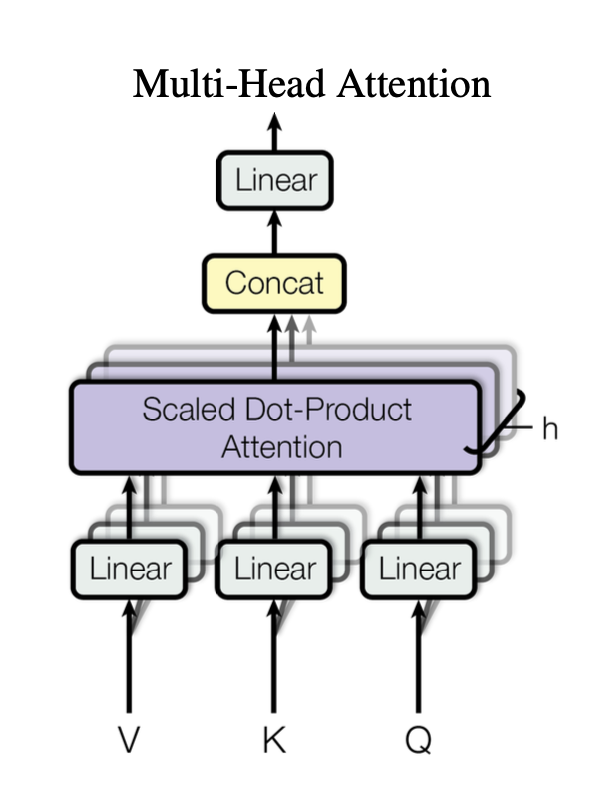
- scaled dot product attention만 이해했다면 나머지 구조는 어렵지 않다.
- 문장의 모든 단어를 Q, K, V로 임베딩하고 이를 linear layer → SDPA → concat → linear 이다.
- 이과정을 하나의 식으로표현하면

- 여기서 h번 SDPA를 반복한다고 하는데 이는 QKV를 각각 여러 다른 차원으로 학습하면 다양한 의미를 학습 할 수 있기 때문이라고 한다.
- 이 때, 원래의 QKV 차원을 그대로 사용하면 계산량이 너무 많아지니까 반복하는 횟수만큼 나눠서 차원을 줄인다음에 학습하고 concat하는 방식으로 표현 정보의 다양성을 확보한다.
Results
- 이미 이 논문의 여파는 유명하다고 말하는 것 자체가 어색할 만큼 엄청난 파급력을 보여줬다. 그러므로 실험과 이 후 과정에 대해서는 생략하도록 한다.
- 이외에도 positional encoding, FFN 등 빼먹은 부분이 많다. 하지만 오늘날까지 가장 큰 영향을 미치고 있는 부분은 결국 Multi Head Attention 부분이 이므로 이 논문에 대한 이해는 충분하다고 본다.

머신러닝 엔지니어 김태종입니다. anomaly detection, recommendation system에 관심있습니다.