BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
paper review&implementation
Abstract
우리는 새로운 언어 표현 모델 BERT,Bidirectional Encoder Representation from Transformers 로 말할 수 있는, 를 소개하겠다.
- which stands for Bidirectional Encoder Representations from Transformers. → stands for 의 해석이 특이하다. 여기서는 의미하다 정도가 적당할 것 같다.
최근의 language representation model들과 달리, BERT는 deep bidirectional representations로 pre-train하도록 디자인되었다. unlabeled text를 사용해서 조건부 결합확률에 의한 양방향 학습으로 모든 층에서
결과적으로, pre-trained BERT는 fine-tune할 수 있다. 하나의 output layer만 추가하면, 다양한 작업을 위한 SOTA 모델을 만들기 위해, question answering and language inference와 같은, 실제로 특별한 구조의 변화 없이
BERT는 개념적으로 간단하고 실질적으로 강력한 성능을 보인다. 이것은 새로운 SOTA 결과들을 얻었다, 11개의 nlp 작업에서, GLUE score를 80.5%까지 끌어올린 것을 포함하여, (생략) 다양한 점수를 끌어 올렸다. (아무튼 점수 많이 올랐다 브로)
Conclusion
- 최근 실제로 전이학습 모델이 발달한건 비지도 학습으로 사전학습이 가능해지면서 너무나도 많은 데이터가 학습이 가능해졌기 때문이다.
- 양방향 구조를 깊게 만들고 사전학습 모델이 다양한 자연어 처리에 적용될 수 있도록 만든것이 큰 기여라고 한다.
Introduction
현존하는 전략에는 두 가지가 있다. feature-based와 fine-tuning
- feature based
- ELMo같은 모델이 있다.
- task에 특화된 구조를 바탕으로 pre-train을 한다.
- fine-tune
- Generative Pre-trained Transformer(GPT)와 같은 모델이 있다.
- task에 최대한 특화되지 않도록 하고 간단하게 fine-tuning할 수 있다.
-
이 두 접근법은 모두 같은 pre-training objective function을 가지고 있다. 근데 둘 다 uni-direction이다.
-
이 방법이 pre-training의 힘을 제한한다고 본다. 특히 fine-tune에서
-
BERT는 masked language model(MLM) pre-training objective를 사용해 단방향 학습의 한계를 해결한다.
- MLM은 랜덤하게 input의 일부 token에 mask를 씌우는 것이다. (즉, 가린다.)
- 그리고 objective는 가려진 단어를 예측한다.
-
MLM은 왼쪽과 오른쪽의 맥락을 섞을 수 있다.
Summery
- BERT는 깊은 양방향 사전학습을 할 수 있는 masked language models을 사용한다.
- BERT는 너무 복잡하게 만들지 않았다.
- 11개의 NLP 분야에서 SOTA를 달성했다.
BERT
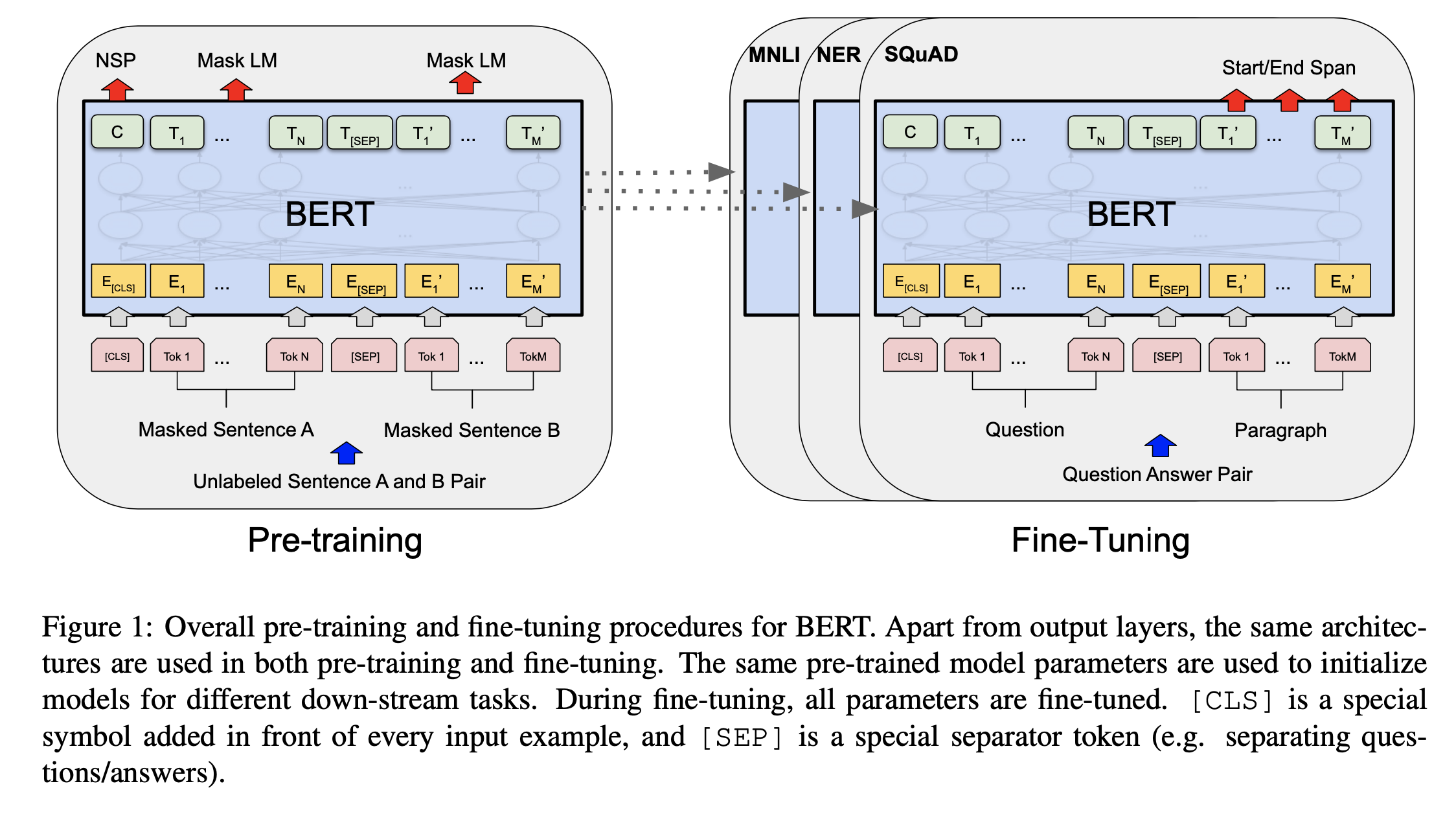
- pre-train과 fine-tune과정 두 가지로 나눠진다.
- pre-train과 fine-tune의 과정이 크게 분리되어있지 않다.
Model Architecture
- multi-layer bidirectional Transformer encoder를 사용한다.
- (L=12, H=768, A=12, Total Param-eters=110M) and (L=24, H=1024, A=16, Total Parameters=340M).
- 는 OpenAI GPT(당시 기준)과 같은 사이즈이다.
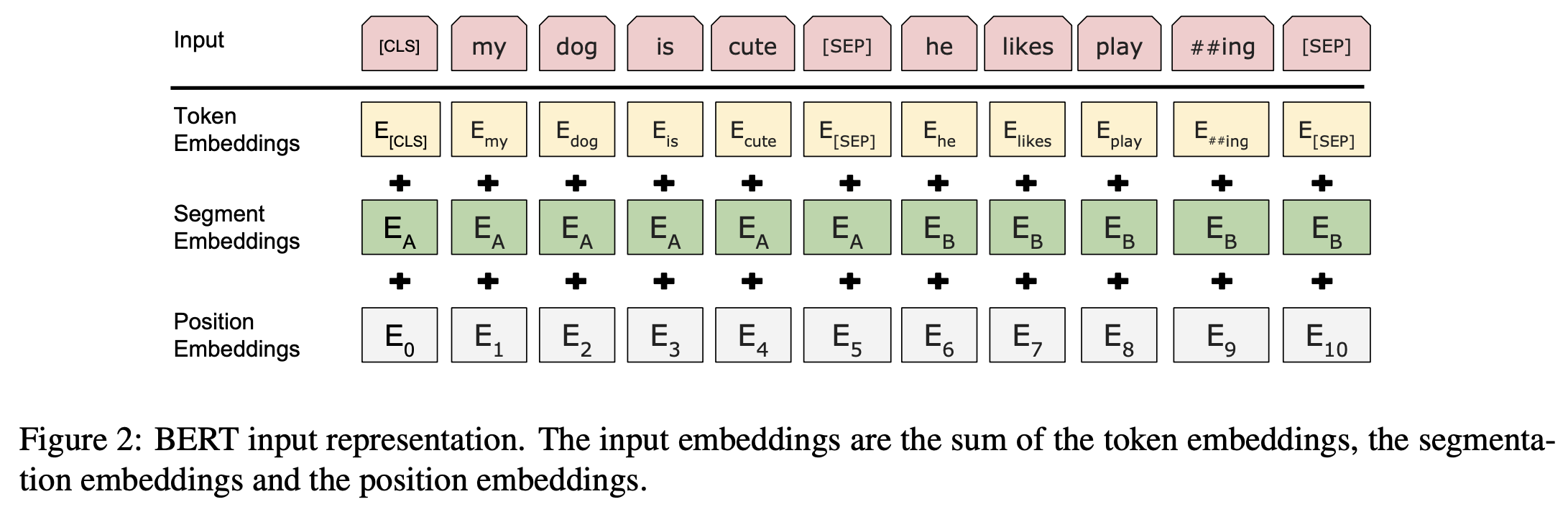
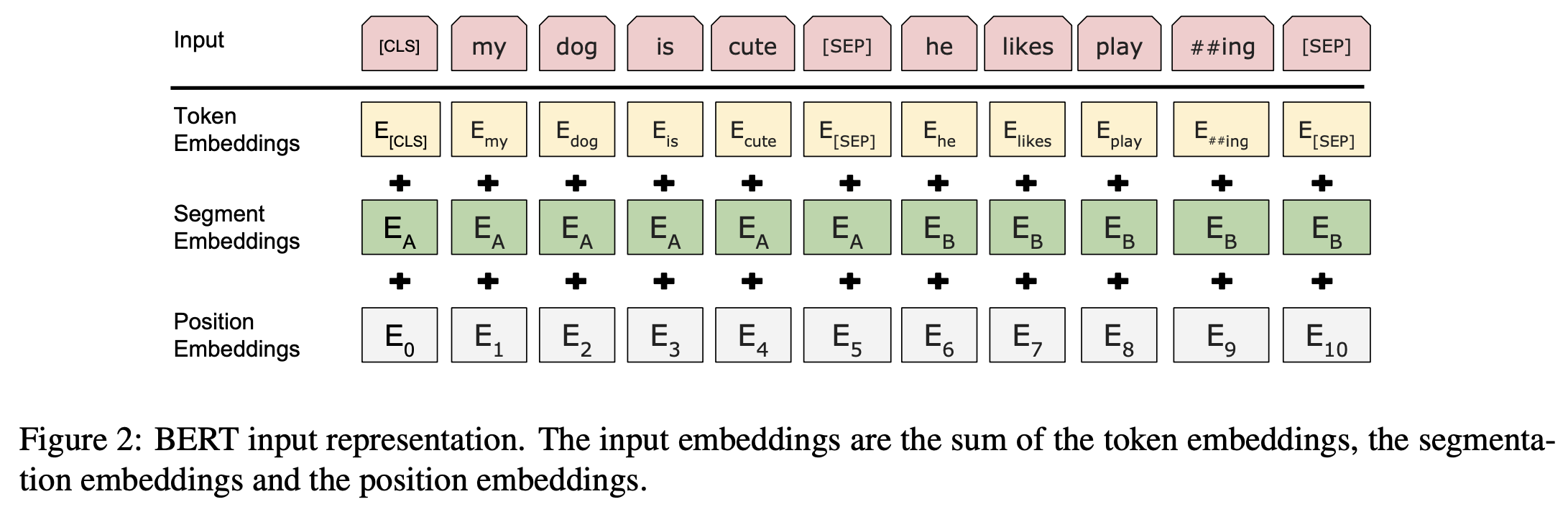
Input/Output Representations
- 다양한 down-stream task에 적용하기 위해 input representation이 더 명확하게 표현될 수 있다.
- 30,000 token짜리 WordPiece embedding을 사용한다.
- [CLS] 토큰은 모든 문장의 처음에 등장하며, 분류 문제에서는 최종 출력을 기반으로 분류를 예측하는 토큰으로 사용된다. (설명이 어렵다…)
- [SEP]은 문장 묶음으로 sequence가 이루어져있을 때, 각 문장을 구분하는 역할을 한다.
- 각 토큰이 어떤 문장에 속하는지 표시해준다.
Pre-training BERT
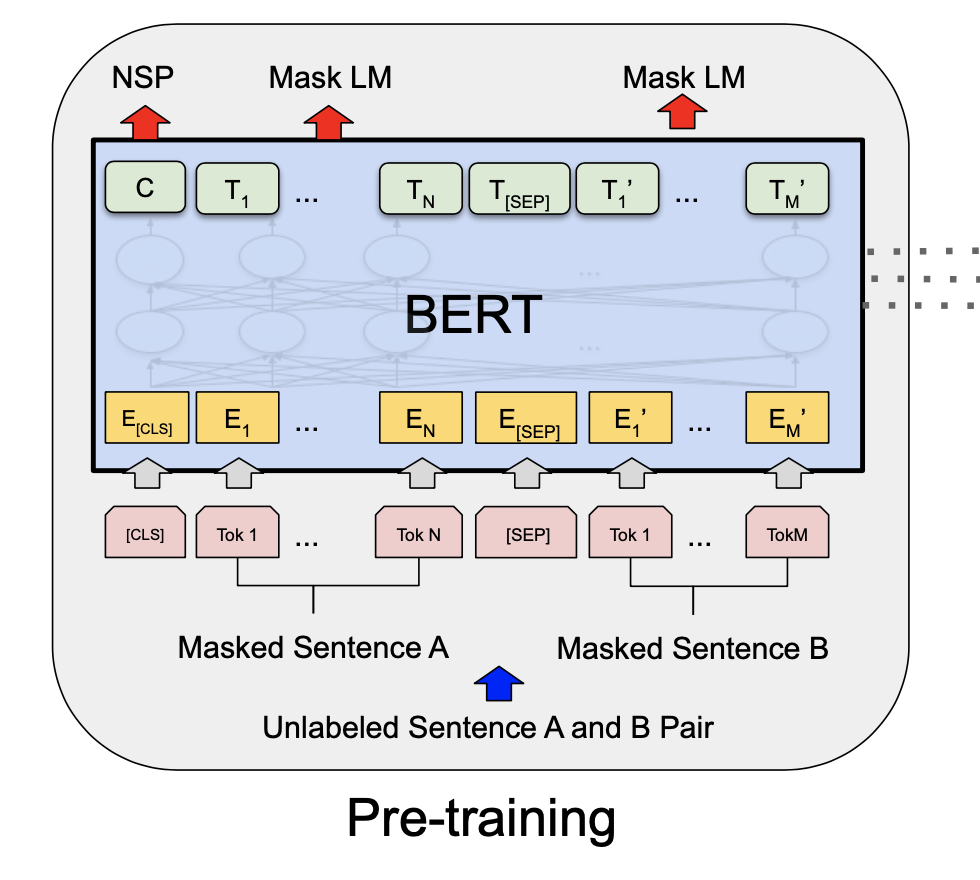
- 2개의 비지도 학습 과정을 사용해 사전학습한다.
Task #1: Masked LM
- 일반적인 언어모델은 단방향 학습을 사용하는데, 양방향 조건이 각각의 단어가 간접적으로 보여지도록 밖에 못하기 때문이다. 그리고 이런 모델은 다층 문맥에서 target word를 사소하게 예측할 것이다.
- Input에다 일부 비중만큼 랜덤하게 mask를 씌울것이다. → masked LM(MLM)
- 논문에서는 15% 정도 넣었다.
- mask token에 해당하는 마지막 히든 벡터가 output softmax에 들어간다.
- 이것은 denoising AE랑은 다르게 우리는 mask된 단어만 찾는다.
- 이걸 pre-train에만 할 수 있어서 fine-tune할 때 약간의 문제가 있다.
- 그래서 80%는 실제로 [mask]로 바꾸고 10%는 랜덤 단어로 바꾸고 10%는 안 바꾼다.(랜덤 단어로 바꾸면 그 단어가 잘못 학습되는게 아닌가?)
Task #2: Next Sentence Prediction(NSP)
- 문장을 pair를 학습하는데 A,B로 이루어져있다면 B의 50%는 진짜 이어지는 문장, 나머지 50%는 랜덤한 문장이다.
- 진짜 이어지는 문장일때는 IsNext로 라벨링 되어있고, 아닐때는 NotNext라고 되어있다.
- 이런 NSP task는 represenstation learning objective와 긴밀하게 연관되어있다.
Fine-tuning BERT
- Fine-tuning은 간단하다. self-attention덕분에 BERT가 많은 세부 작업을 모델링할 수 있게 한다.
- 이 때 single text든 text pair이든 상관 없다.
- 적절하게 input과 output을 교환하는 방법으로 이걸 가능하게 한다. (??)
- 이전에는 양방양 학습을 위해 두 개의 단계를 거쳐야 했지만, BERT는 두 개의 단계를 통합하기 위해 self-attention을 사용한다. 두 개 문장 사이의 bidirectional cross attention을 효과적으로 포함하기 위해 합쳐진 text pair와 self-attention을 encoding 함으로서
실험은 생략…
후기
논문을 어떻게 하면 좀 더 잘 읽을 수 있을까에 대한 고민을 많이 했었는데 가장 추천하는 방법이 abstract->conclusion->introduction 순으로 읽는 거였다. 확실히 전반적인 개요와 결과를 알고 논문을 보니 어떤 부분이 나올지, 어떤 부분이 보다 중요한지 더 눈에 잘 들어오는 듯한 느낌이다.
BERT는 masked attention 방법이 가장 중요해 보였다. 기본적으로는 transformer의 구조를 따르면서 약간 autoencoder같은 느낌으로 학습한다고 느꼈다. 물론 결과적으로 현재에는 GPT가 승자이지만 텍스트 모델 말고 다른 문제를 해결할때 사용할 수도 있지 않을까 하는 생각이 든다.
