1. 언어 모델(Language Model)
문장과 같은 단어 시퀀스에서 각 단어의 확률을 계산하는 모델
ex) 'Word2Vec'
개의 단어로 구성된 문장은 아래와 같이 나타낼 수 있다
CBoW가 타겟 단어(target word)를 예측할 확률
통계적 언어 모델(Statistical Language Model, SLM)
신경망 언어 모델이 주목받기 전부터 연구되어 온 전통적인 접근 방식
- 통계적 언어 모델의 확률 계산
단어의 등장 횟수를 바탕으로 조건부 확률을 계산한다
전체 말뭉치의 문장 중에서 시작할 때 "I" 로 시작하는 문장의 횟수를 구함. 전체 말뭉치의 문장이 1000개이고, 그 중 "I" 로 시작하는 문장이 100개라면
다음으로, "I" 로 시작하는 100개의 문장 중 바로 다음에 "am" 이 등장하는 문장이 50개라면
모든 조건부 확률을 구한 뒤 서로를 곱해주면 문장이 등장할 확률 을 구할 수 있다
- 통계적 언어 모델의 한계점
희소성(sparsity)문제를 가지고 있다.
개선하기 위해 N-gram이나 스무딩(smoothing), 백오프(boack-off) 같은 방법이 고안됨
신경망 언어 모델(Neural Langauge Model)
횟수 기반 대신 Word2Vec 이나 fastText 등의 출력값인 임베딩 벡터를 사용한다
말뭉치에 등장하지 않더라도 의미적, 문법적으로 유사한 단어라면 선택될 수 있다
2. 순환 신경망(Recurrent Neural Network, RNN)
연속형 데이터(Sequential Data)
어떤 순서로 오느냐에 따라서 단위의 의미가 달라지는 데이터
RNN의 구조
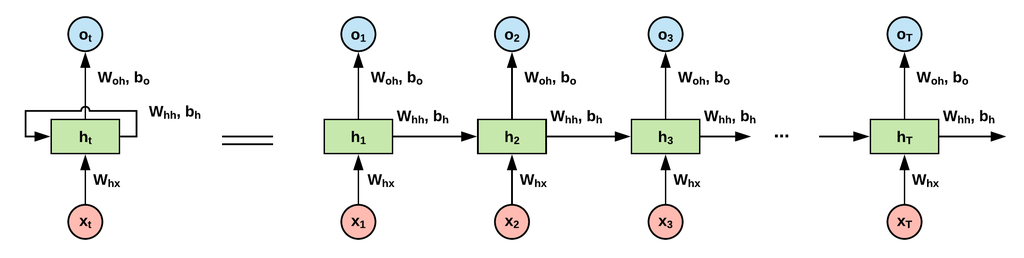
등호 왼쪽
1. 입력 벡터가 은닉층에 들어가는 화살표
2. 은닉층으로부터 출력 벡터가 생성되는 화살표
3. 은닉층에서 나와 다시 은닉층으로 입력되는 화살표
3번 화살표는 특정 시점에서의 은닉 벡터가 다음 시점의 입력 벡터로 다시 들어가는 과정
출력 벡터가 다시 입력되는 특성 때문에 '순환 신경망'
RNN의 장점과 단점
- RNN의 장점
모델이 간단하고 어떤 길이의 sequential 데이터라도 처리할 수 있음 - RNN의 단점 1 : 병렬화 불가능
벡터가 순차적으로 입력됨 GPU 연산을 하였을 때 이점이 없다 - RNN의 단점 2 : 기울기 폭발, 기울기 소실
3. LSTM & GRU
장단기기억망(Long Term Short Memory, LSTM)
RNN에 기울기 정보 크기를 조절하기 위한 Gate를 추가한 모델
대부분 RNN보다 LSTM사용
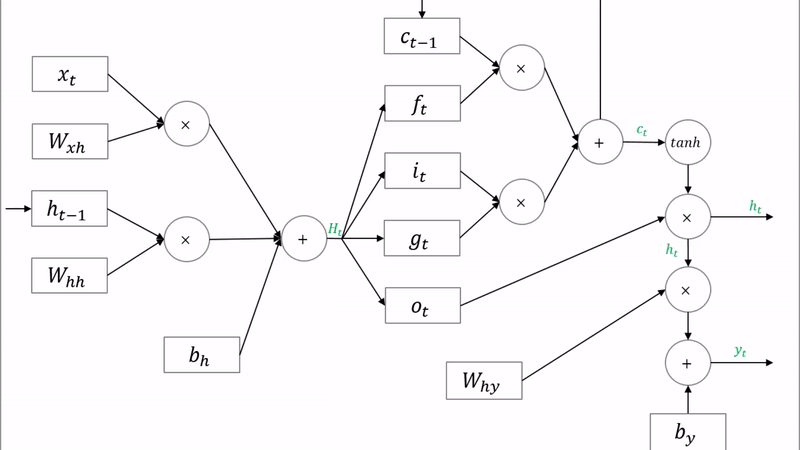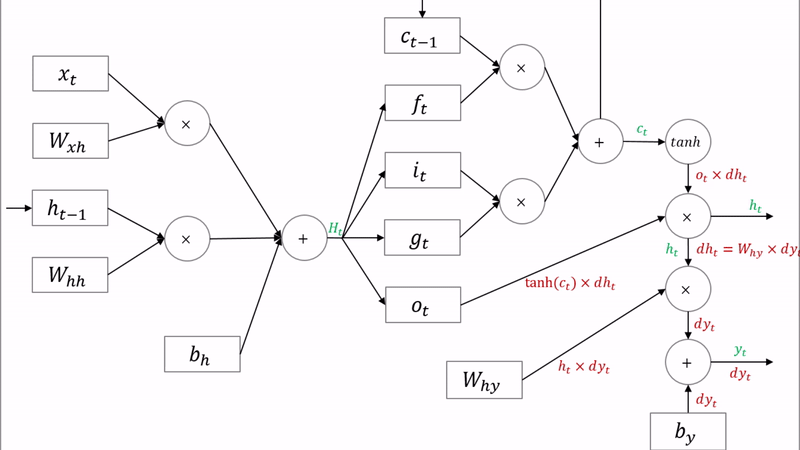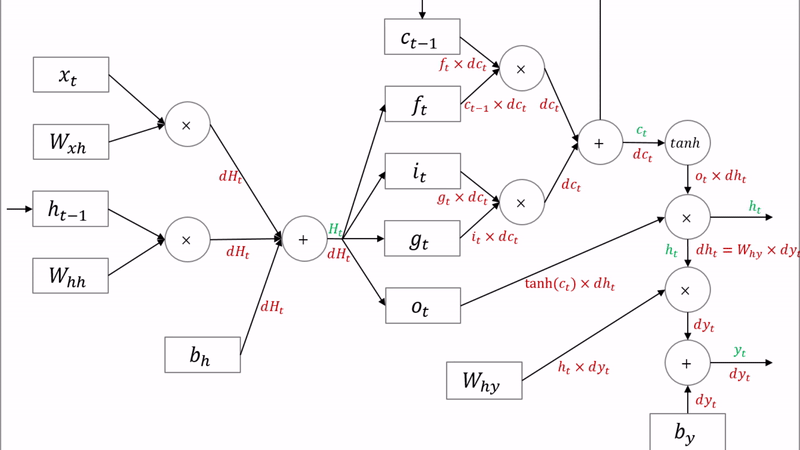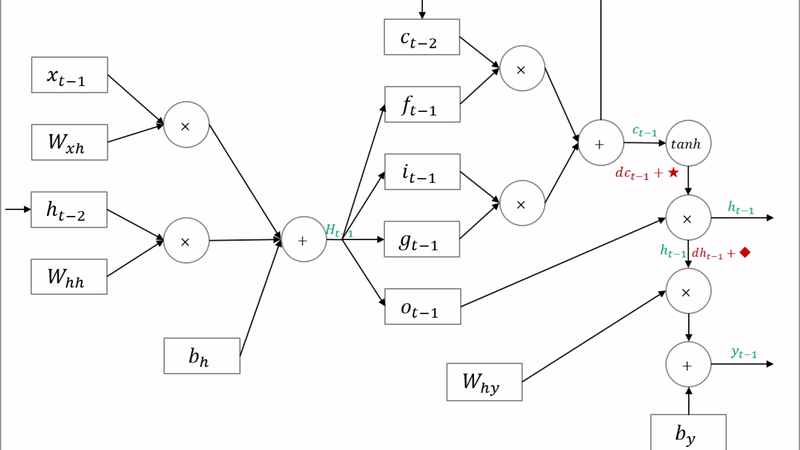
- LSTM의 구조
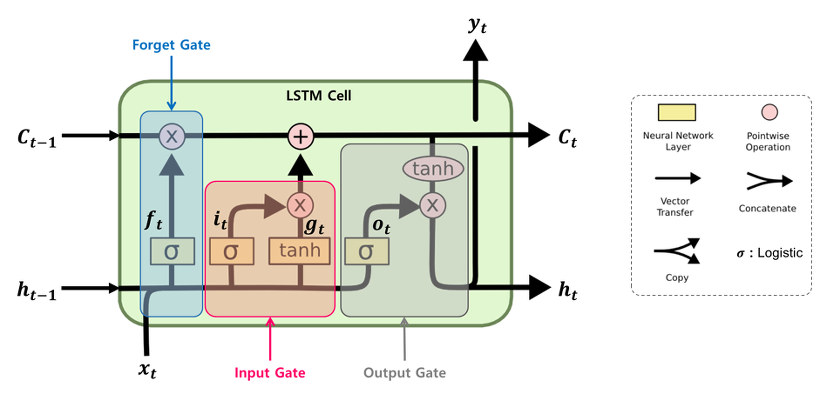
기울기 소실문제를 해결하기 위해 등장
GRU(Gated Recurrent Unit)
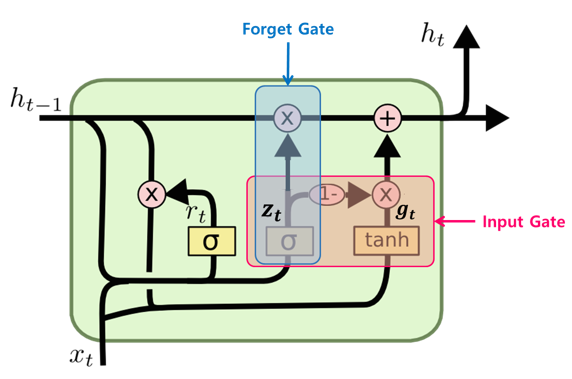
- GRU 셀의 특징
- LSTM에 있었던 cell-state가 사라짐
- 하나의 Gate가 forget, input gate를 모두 제어한다
- GRU 셀에서는 output 게이트가 없다
4. RNN구조에 Attention 적용하기
RNN의 가장 큰 단점 중 하나는 기울기소실로부터 나타나는 장기 의존성(Long-term dependency)문제
장기 의존성 문제 : 문장이 길어질 경우 앞 단어의 정보를 잃어버리게 되는 현상
아무리 LSTM, GRU가 장기 의존성 문제를 개선했다하더라도 문장이 매우 길어지면(30-50단어) 모든 단어 정보를 고정 길이의 hidden-state 벡터에 담기 어려움
해결방법 : Attention(어텐션)
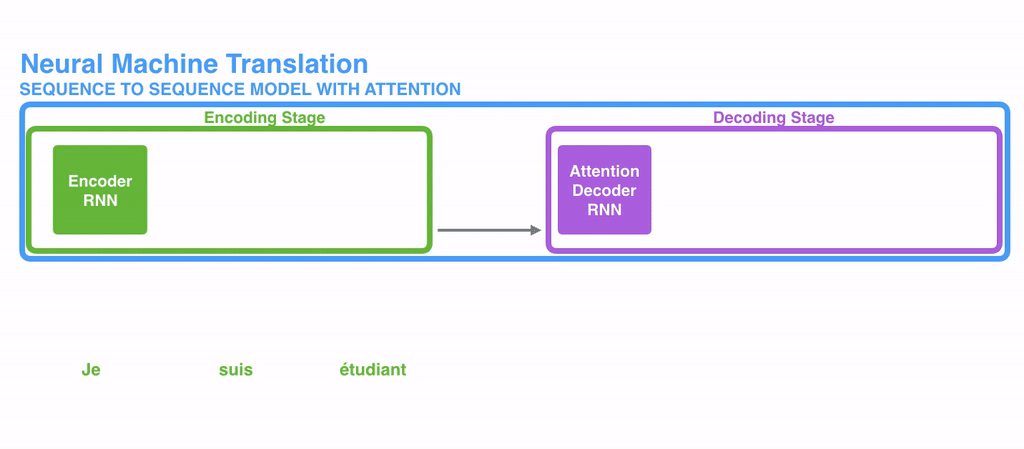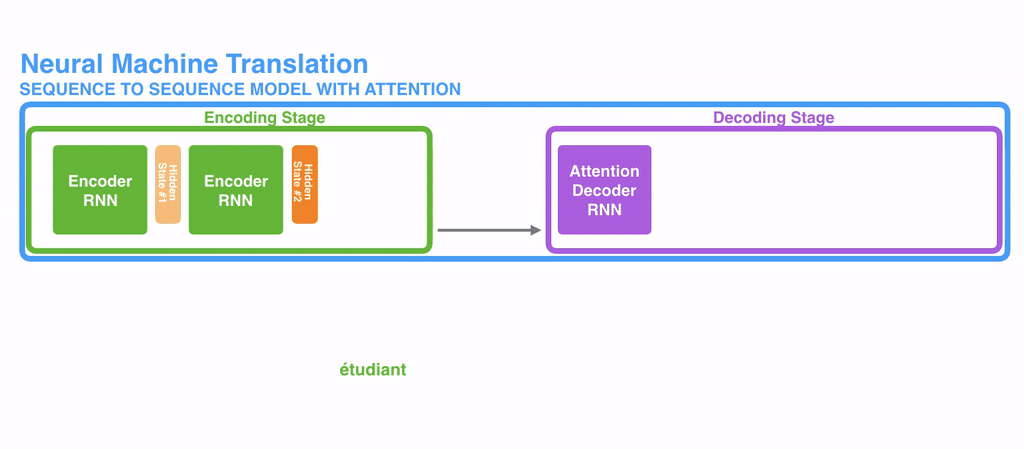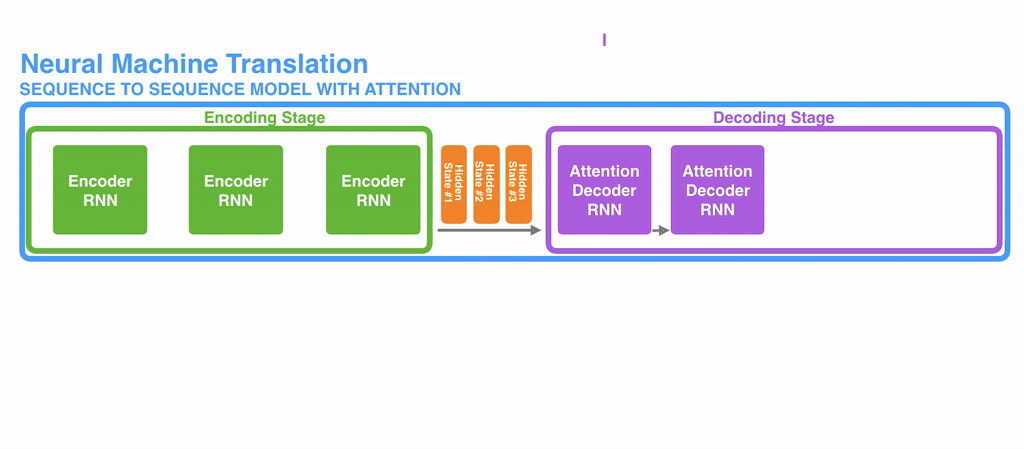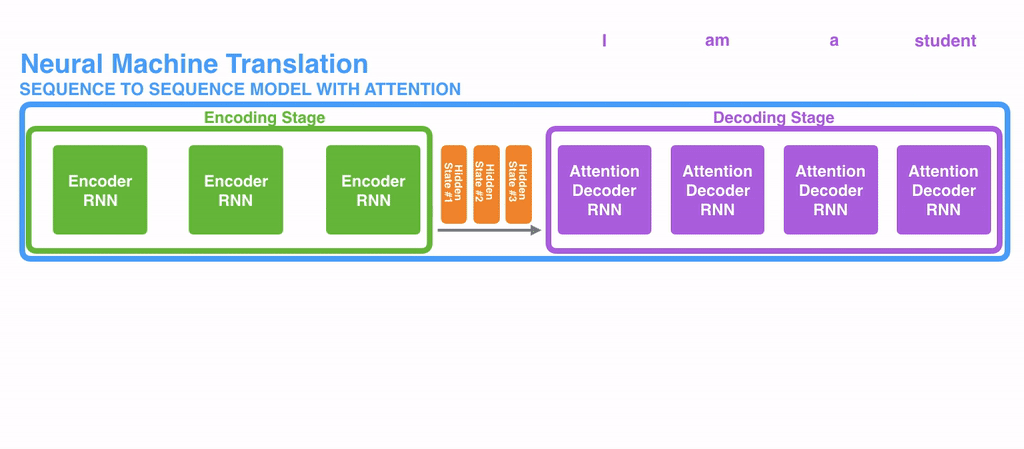
Attention은 각 인코더의 Time-tep 마다 생성되는 hidden-state 벡터를 간직한다
입력 단어가 N개라면 N개의 hidden-state 벡터를 모두 간직한다
모든 단어가 입력되면 생성된 hidden-state 벡터를 모두 디코더에 넘겨준다
디코더에서 Attention이 동작하는 방법
디코더의 각 time-step 마다의 hidden-state 벡터는 쿼리로 작용한다
인코더에서 넘어온 N개의 hidden-state 벡터를 키(key)로 여기고 이들과의 연관성을 계산
이 때 계산은 내적(dot-product)을 사용하고 내적의 결과를 Attention 가중치로 사용한다
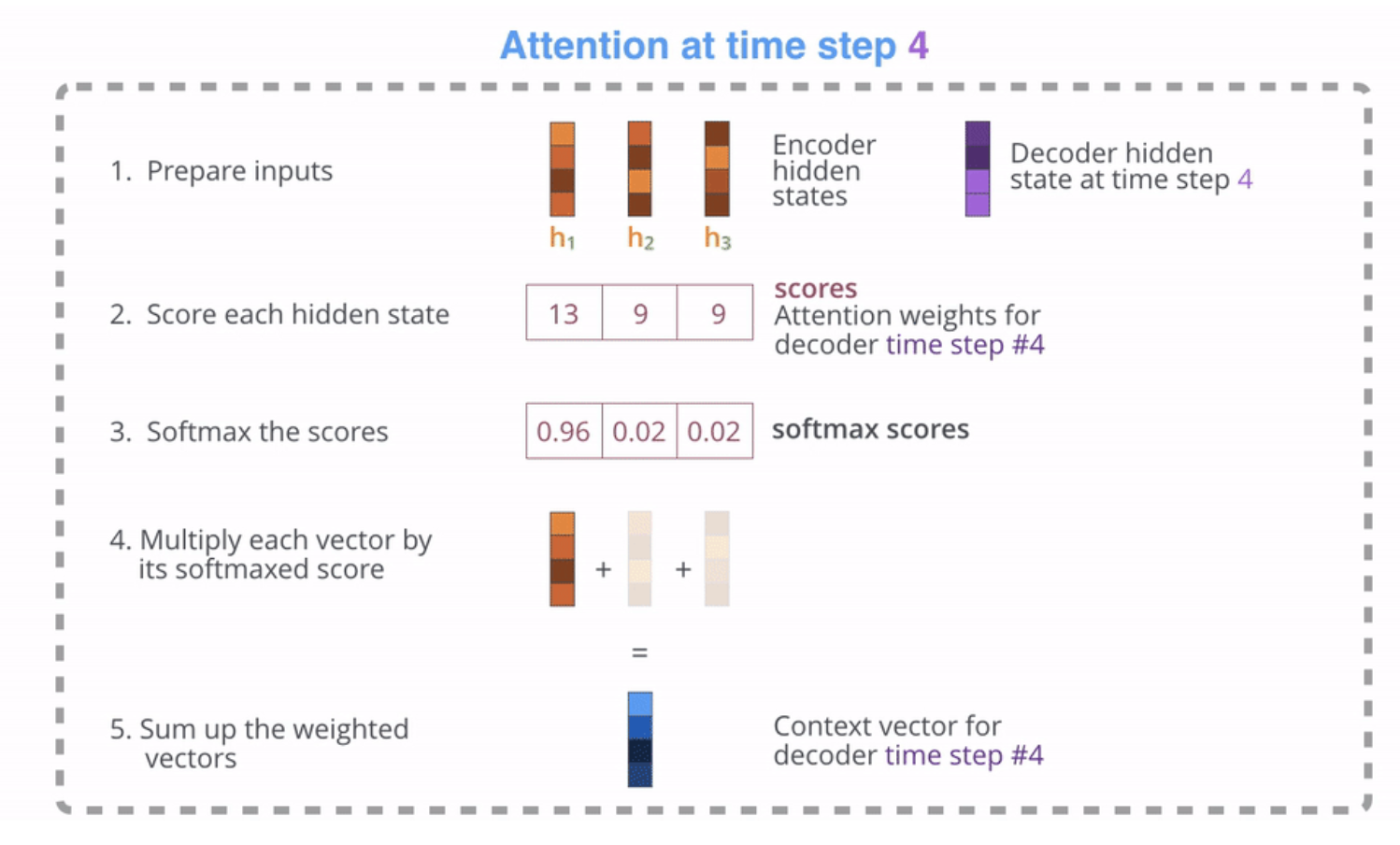
- 쿼리(Query)인 디코더의 hidden-state 벡터, 키(Key)인 인코더에서 넘어온 hidden-state 벡터를 준비합니다.
- 각각의 벡터를 내적한 값을 구합니다.
- 이 값에 소프트맥스(softmax) 함수를 취해줍니다.
- 소프트맥스를 취하여 나온 값에 밸류(Value)에 해당하는 인코더에서 넘어온 hidden-state 벡터를 곱해줍니다.
- 이 벡터를 모두 더해줍니다. 이 벡터의 성분 중에는 쿼리-키 연관성이 높은 밸류 벡터의 성분이 더 많이 들어있게 됩니다.
- (그림에는 나와있지 않지만) 최종적으로 5에서 생성된 벡터와 디코더의 hidden-state 벡터를 사용하여 출력 단어를 결정하게 됩니다.

