Transformer : Attention is All You Need
트랜스포머(Transformer)란?

기계 번역을 위한 새로운 모델
Attention 메커니즘을 극대화하여 뛰어난 번역 성능 기록
자연어처리 모델의 기본 아이디어는 거의 모두 트랜스포머를 기반으로 함
자연어처리가 아닌 다른 문제도 잘 풀고있기 때문에 최근 CV에도 적용하려는 시도가 있음
RNN기반 모델의 단점은 단어가 순차적으로 들어온다는 점
트랜스포머는 이런 문제를 해결하기 위해 등장한 모델
모든 토큰을 동시에 입력받아 병렬 처리하기 때문에 GPU 연산에 최적화
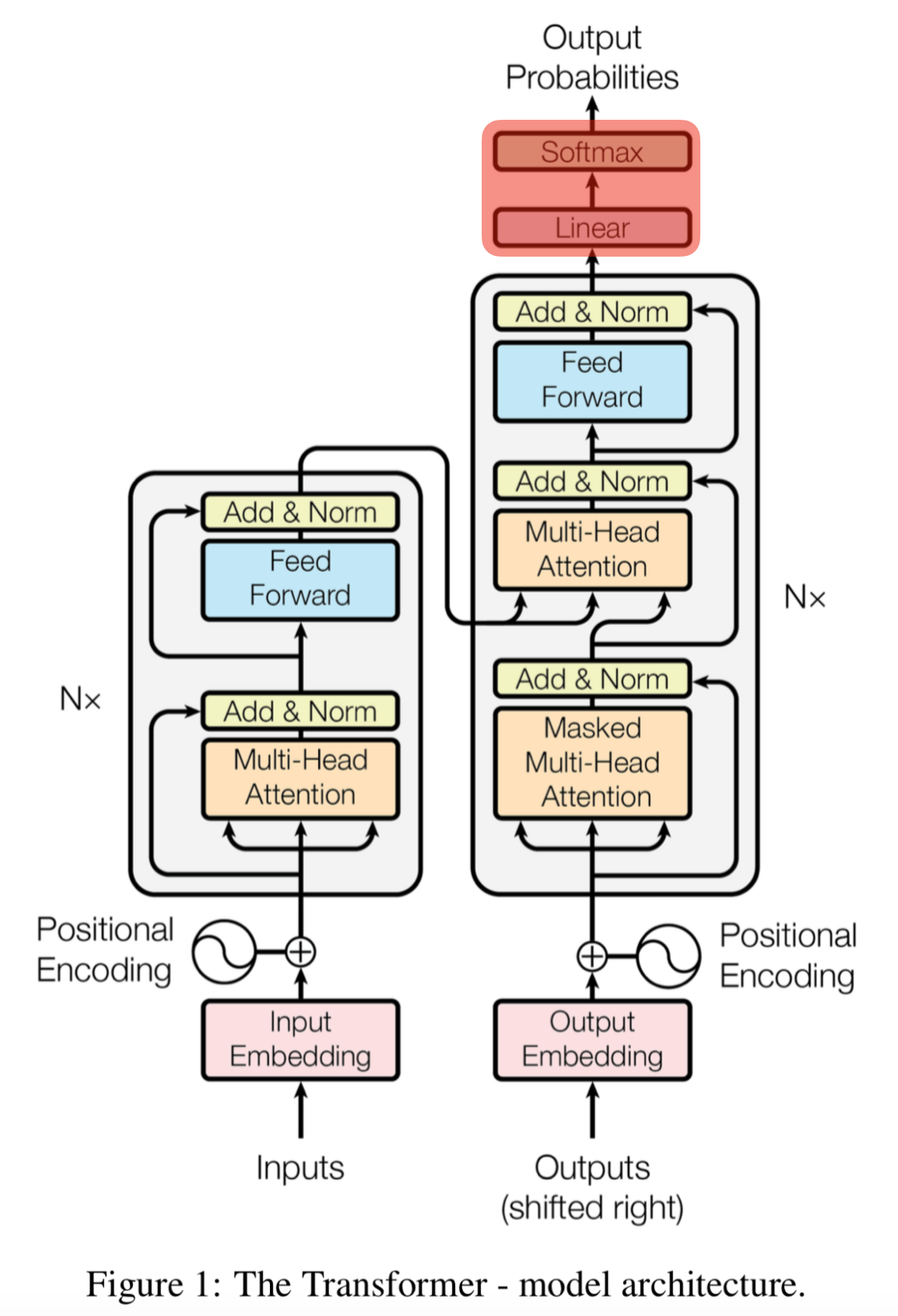
- 트랜스포머의 구조
트랜스포머는 인코더 블록과 디코더 블록이 6개씩 모여있는 구조
트랜스포머에서는 병렬화를 위해 모든 단어 벡터를 동시에 입력받음
컴퓨터가 단어의 위치를 알 수 있도록 위치 정보를 담은 벡터를 따로 제공해주어야 함
단어의 상대적인 위치 정보를 담은 벡터를 만드는 과정을 Positional Encoding 이라고 함
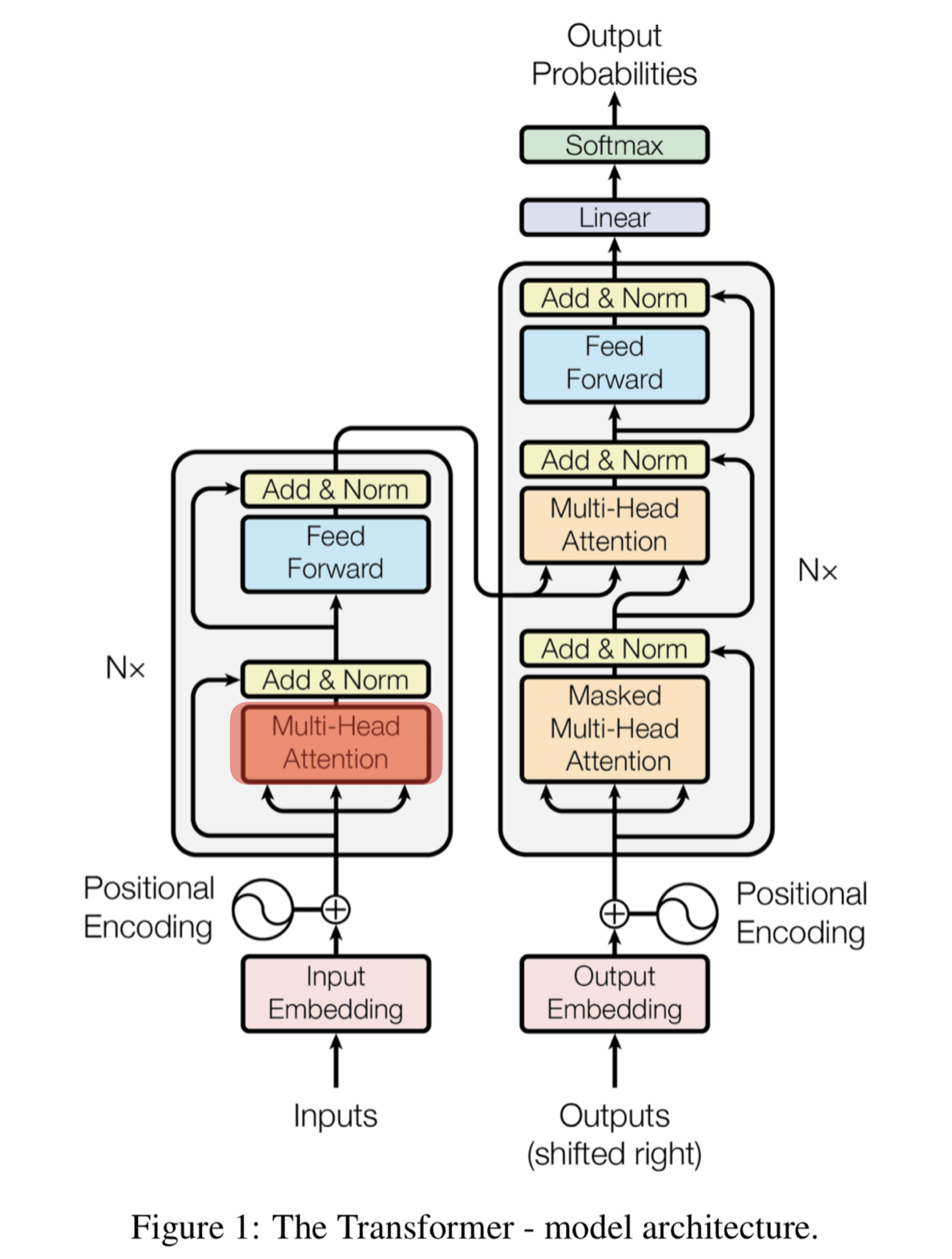
셀프-어텐션(Self-Attention)
트랜스포머의 주요 매커니즘
The animal didn't cross the street because it was too tired
다음과 같은문장이 있을때 문장을 제대로 번역하려면 "it"과 같은 지시대명사가 어떤 대상을 가리키는지 알아야 함

트랜스포머에서는 번역하려는 문장 내부 요소의 관계를 잘 파악하기 위해서 문장 자신에 대해 어텐션 매커니즘을 적용함
이를 Self-Attention 이라고 함
셀프-어텐션은 세가지 가중치 벡터를 대상으로 어텐션을 적용함
1. 특정 단어의 쿼리 벡터와 모든 단어의 키 벡터를 내적. 내적을 통해 나오는 값이 Attention 스코어
2. 계산값을 안정적으로 만들어주기 위한 계산 보정
3. Softmax를 취함. 쿼리에 해당하는 단어와 문장 내 다른 단어가 가지는 관계의 비율을 구할 수 있다
4. 밸류 각 단어의 벡터를 곱해준 후 모두 더하면 Self-Attention 과정 끝
def scaled_dot_product_attention(q, k, v, mask):
"""
Attention 가중치를 구하는 함수입니다.
q, k, v 의 leading dimension은 동일해야 합니다.
k, v의 penultimate dimension이 동일해야 합니다, i.e.: seq_len_k = seq_len_v.
Mask는 타입(padding or look ahead)에 따라 다른 차원을 가질 수 있습니다.
덧셈시에는 브로드캐스팅 될 수 있어야합니다.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# matmul_qk(쿼리와 키의 내적)을 dk의 제곱근으로 scaling 합니다.
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 마스킹을 진행합니다.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# 소프트맥스(softmax) 함수를 통해서 attention weight 를 구해봅시다.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weightsMulti-Head Attention
멀티헤드 어텐션을 적용하면 여러 개의 Attention 매커니즘을 동시에 병렬적으로 실행
각 Head마다 다른 Attention 결과를 내어주기 대문에 앙상블과 유사한 효과, 병렬화 효과 극대화
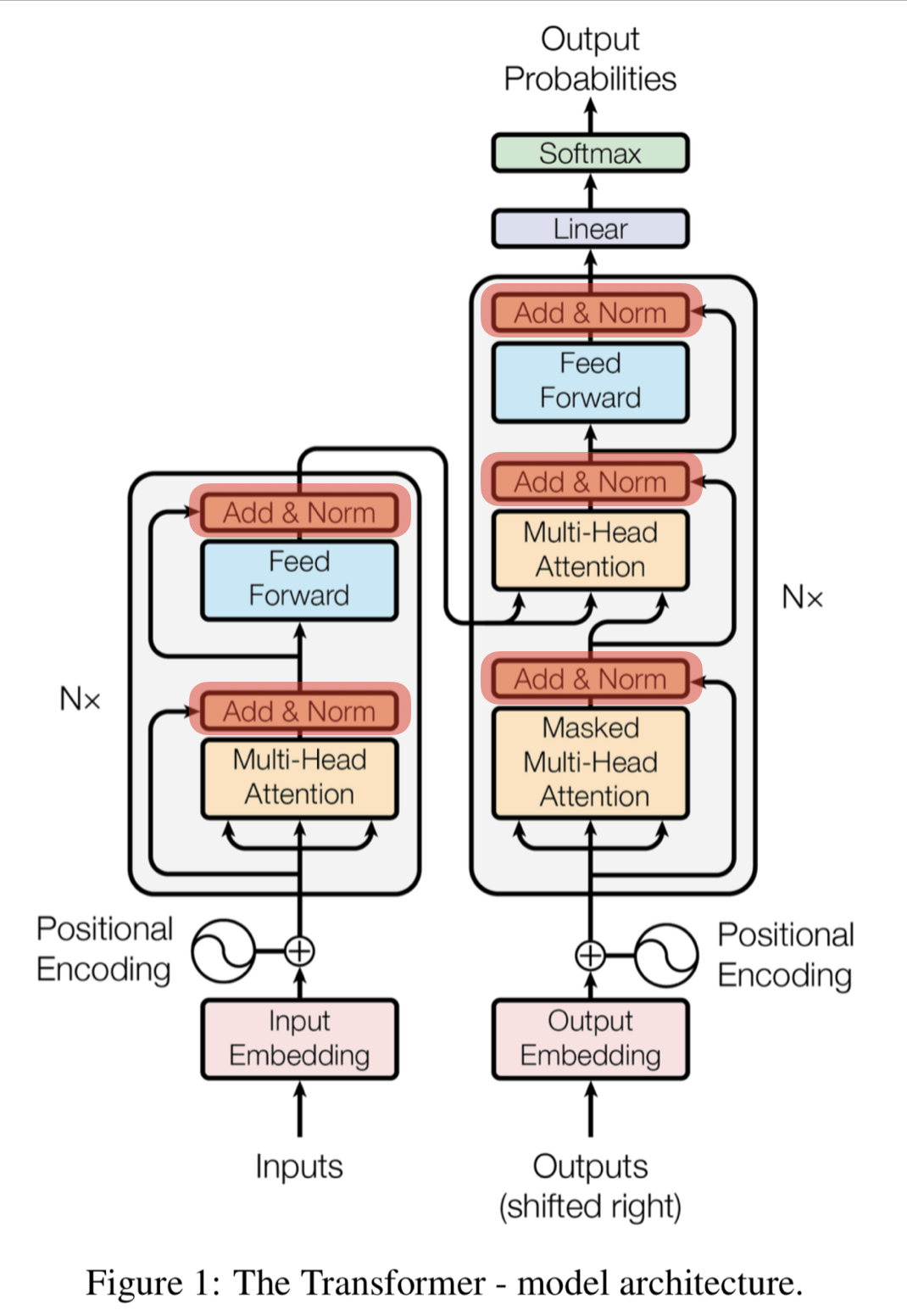
Layer Normalization & Skip connection
트랜스포머의 모든 sub-layer에서 출력된 벡터는 Layer Nnormalization과 Skip connection을 거치게 된다
Skip connection은 역전파 과정에서 정보가 소실되지 않도록 한다
Feed Forward Neural Network(FFNN)
은닉층의 차원이 늘어났다가 다시 원래 차원으로 줄어드는 단순한 2층 신경망
활서와 함수로 ReLU를 사용
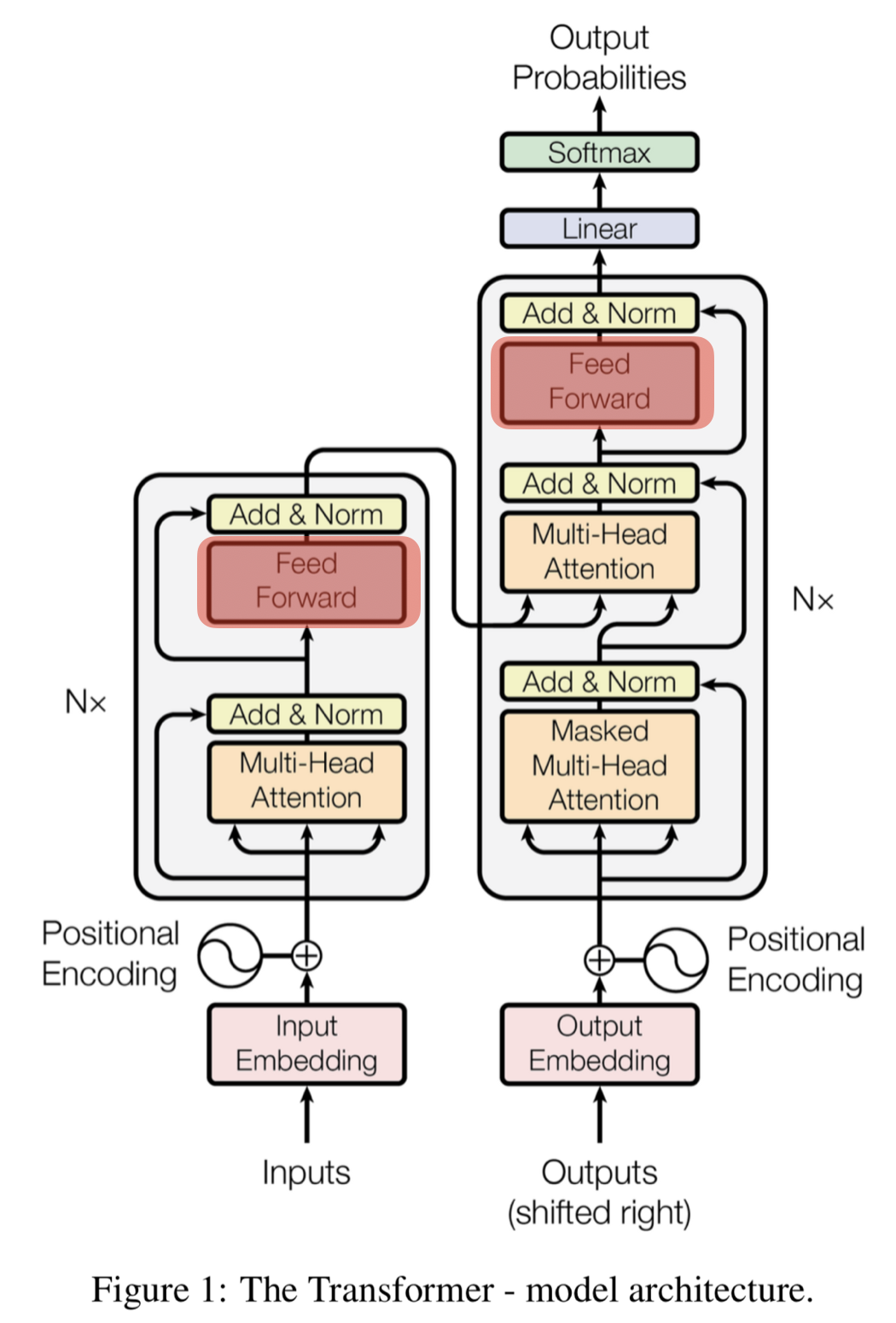
Masked Self-Attention
디코더 블록에서 사용하기 위해 마스킹 과정이 포함된 Self-Attention
해당 위치 타깃 단어 뒤에 위치한 단어는 Self-Attention에 영향을 주지 않도록 마스킹을 해주게 됨
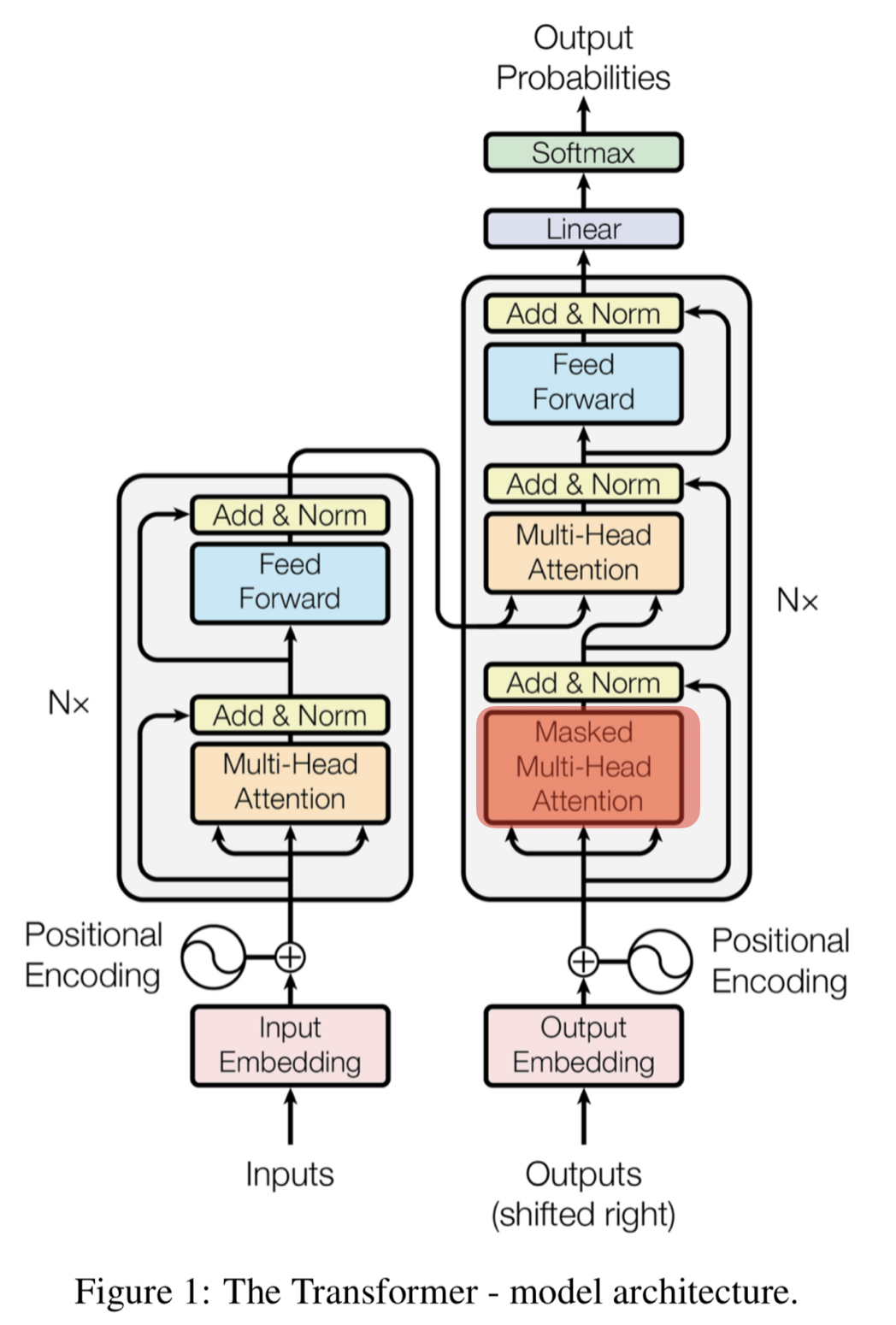
Encoder-Decoder Attention
디코더에서 Masked Self-Attention 층을 지난 벡터는 Encoder-Decoder Attention층으로 들어감
좋은 번역을 위해서는 번역할 문장과 번역된 문장간의 관계 중요
번역할 문장과 번역되는 문장의 정보 관계를 엮어주는 부분
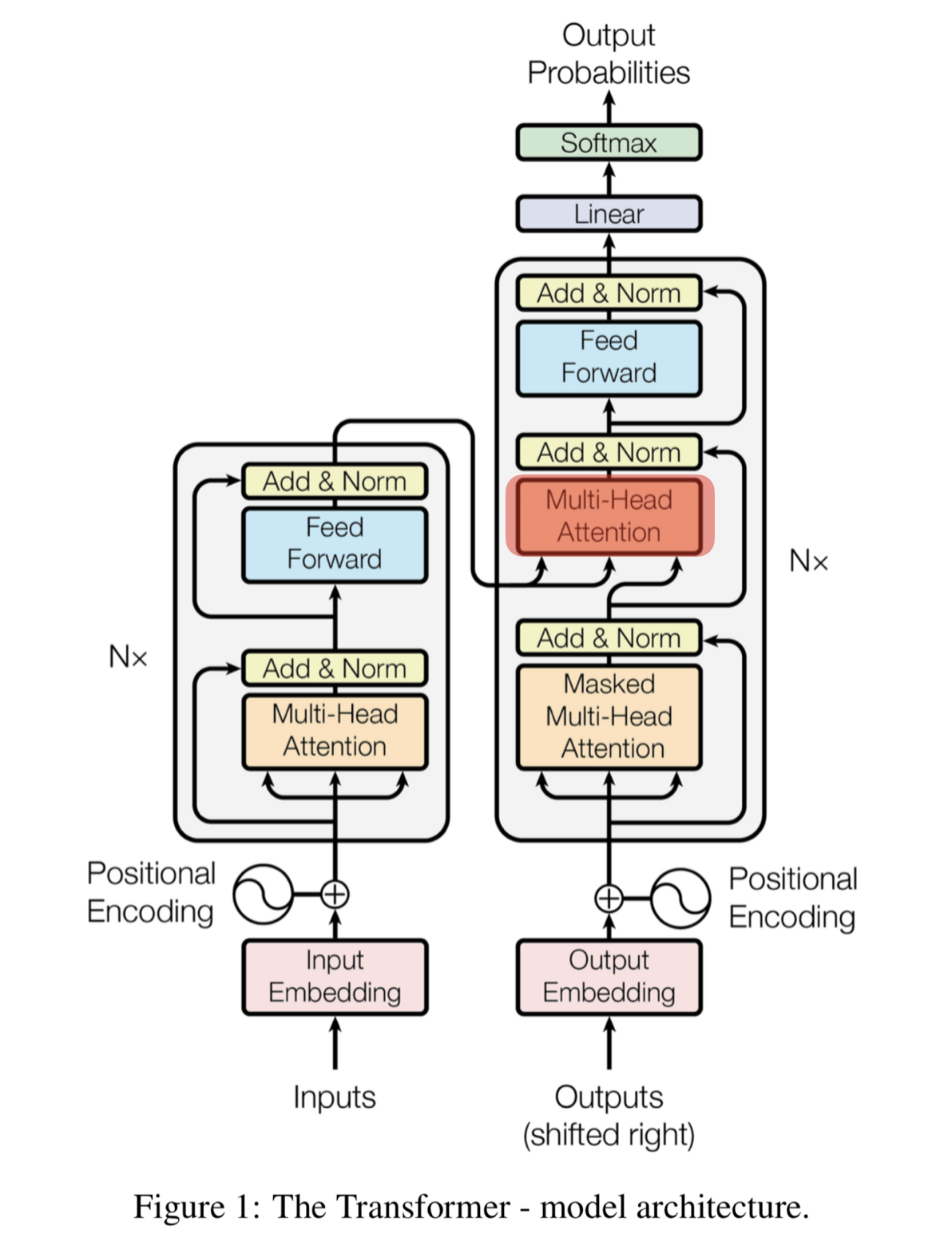
Linear & Softmax Layer
디코더의 최상층을 통과한 벡터들은 Linear 층을 지난 후 Softmax 를 통해 예측할 단어의 확률을 구함