1. 벡터화
1) 원-핫 인코딩(One-hot Encoding)
범주형 변수(Categorical fatture)를 벡터로 나타나는 방법
"I am a student"
라는 문장에서 각 단어를 원-핫 인코딩으로 나타내면
I : [1 0 0 0]
am : [0 1 0 0]
a : [0 0 1 0]
student : [0 0 0 1]
원-핫 인코딩의 치명적 단점 : 단어 간 유사도 구할 수 없다
원-핫 인코딩을 적용한 서로 다른 두 벡터의 내적은 항상 0이므로, 어떤 두 단어를 골라 코사인 유사도를 구하더라도 그 값은 0이 된다
따라서 코사인 유사도(cosine similarity)를 사용한다
2) 임베딩
단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타내기 때문
임베딩을 거친 단어 벡터는 원-핫 인코딩과는 다른 형태의 값을 가진다
ex)
[0.04227, -0.0033, 0.1607, -0.0236, ...]
2. Word2Vec
Word to Vector, 단어를 벡터로 나타내는 방법, 가장 널리 사용되는 임베딩 방법 중 하나
1) CBow 와 Skip-gram
Cbow와 'Skip-gram'의 차이
1. 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델 ▶️ CBow(Continuous Bag-of-Words)
2. 중심 단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델 ▶️ Skip-gram
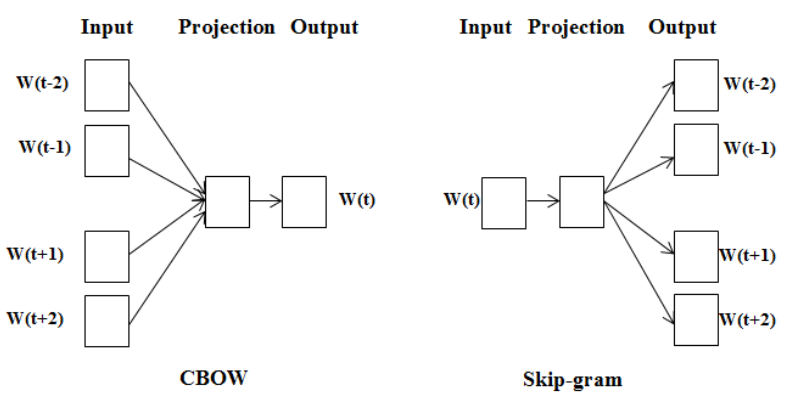
역전파 관점에서 보면 Skip-gram에서 훨씬 더 많은 학습이 일어나기 때문에 Skip-gram의 성능이 조금 더 좋게 나타난다
물론 계산량이 많기 때문에 Skip-gram에 드는 리소스가 더 크다
2) Word2Vec 모델의 구조
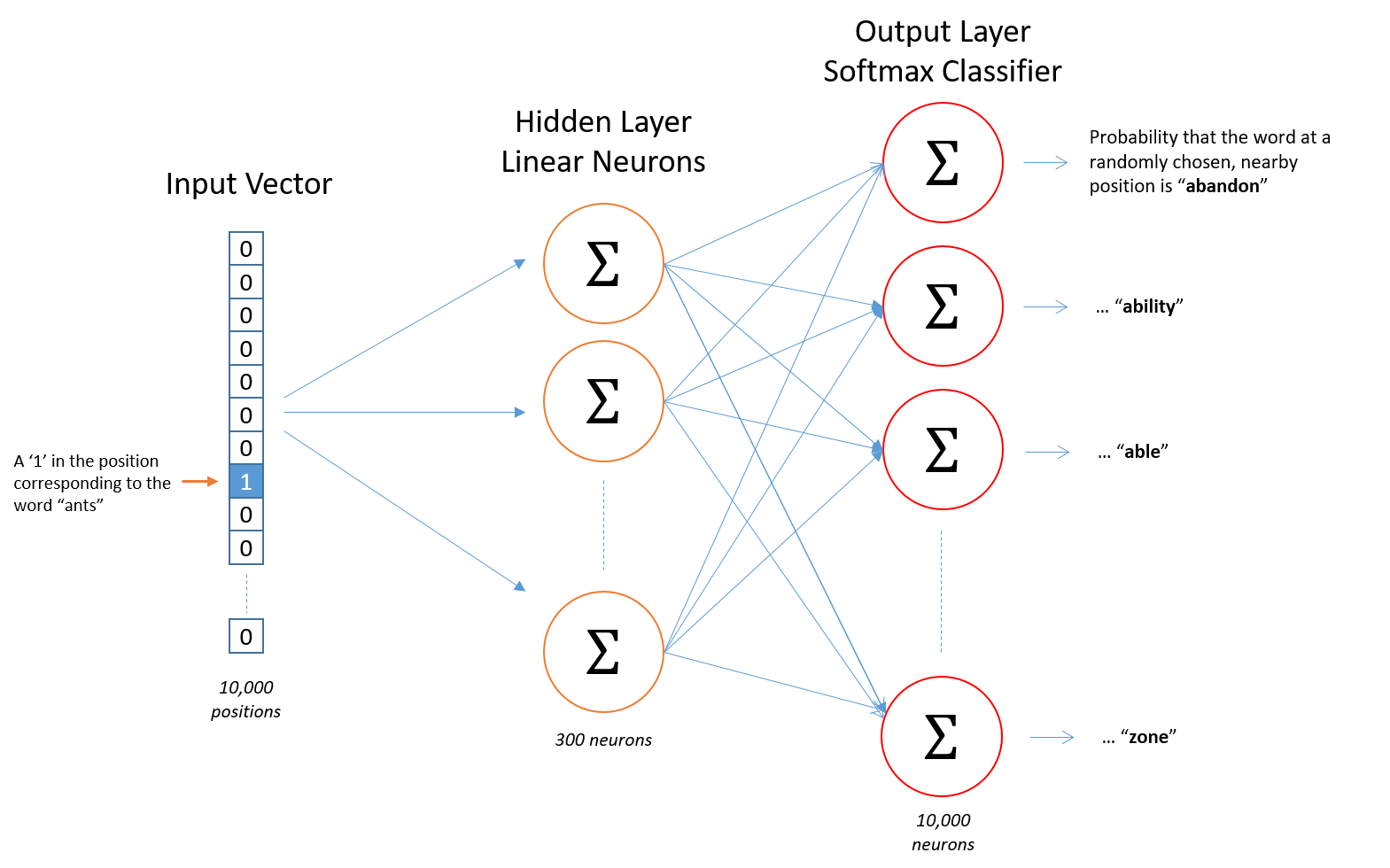
성능 = Skip-gram > CBow
- 입력 : Word2Vec의 입력은 원-핫 인코딩된 단어 벡터
- 은닉층 : 임베딩 벡터의 차원수 만큼의 노드로 굿어된 은닉층이 1개인 신경망
- 출력층 : 단어 개수 만큼의 노드로 이루어져 있으며 활성화 함수로 소프트맥스 사용
3) Word2Vec 학습을 위한 학습 데이터 디자인
효율적으로 학습하기위해 디자인을 해야한다
예를 들어, "The tortoise jumped into the lake" 라는 문장에 대해 단어쌍을 구성하면
윈도우 크기가 2인 경우 다음과 같이 Skip-gram을 학습하기 위한 데이터 쌍을 구축할 수 있다
- 중심 단어 : The, 주변 문맥 단어 : tortoise, jumped
- 학습 샘플: (the, tortoise), (the, jumped)
- 중심 단어 : tortoise, 주변 문맥 단어 : the, jumped, into
- 학습 샘플: (tortoise, the), (tortoise, jumped), (tortoise, into)
- 중심 단어 : jumped, 주변 문맥 단어 : the, tortoise, into, the
- 학습 샘플: (jumped, the), (jumped, tortoise), (jumped, into), (jumped, the)
- 중심 단어 : into, 주변 문맥 단어 : tortoise, jumped, the, lake
- 학습 샘플: (into, tortoise), (into, jumped), (into, the), (into, lake)
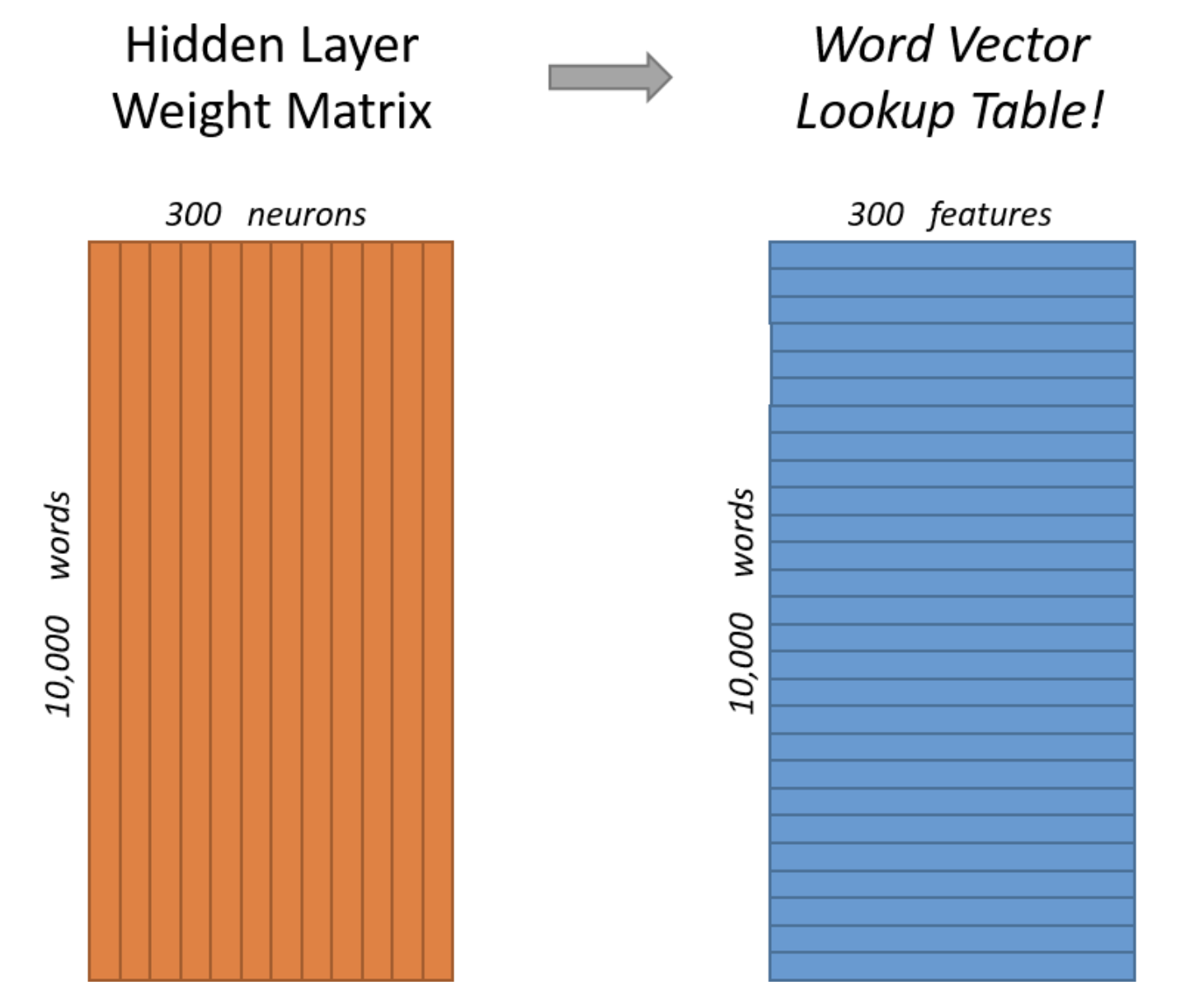
4) Word2Vec의 결과
학습이 끝나면 임베딩 벡터가 생성된다
만약 임베딩 벡터의 차원을 조절하고 싶다면 은닉층의 노드 수를 줄이거나 늘릴 수 있다
5) Word2Vec으로 임베딩한 벡터 시각화
Word2Vec을 통해 얻은 임베딩 벡터는 단어간의 의미적, 문법적 관계를 잘 나타낸다
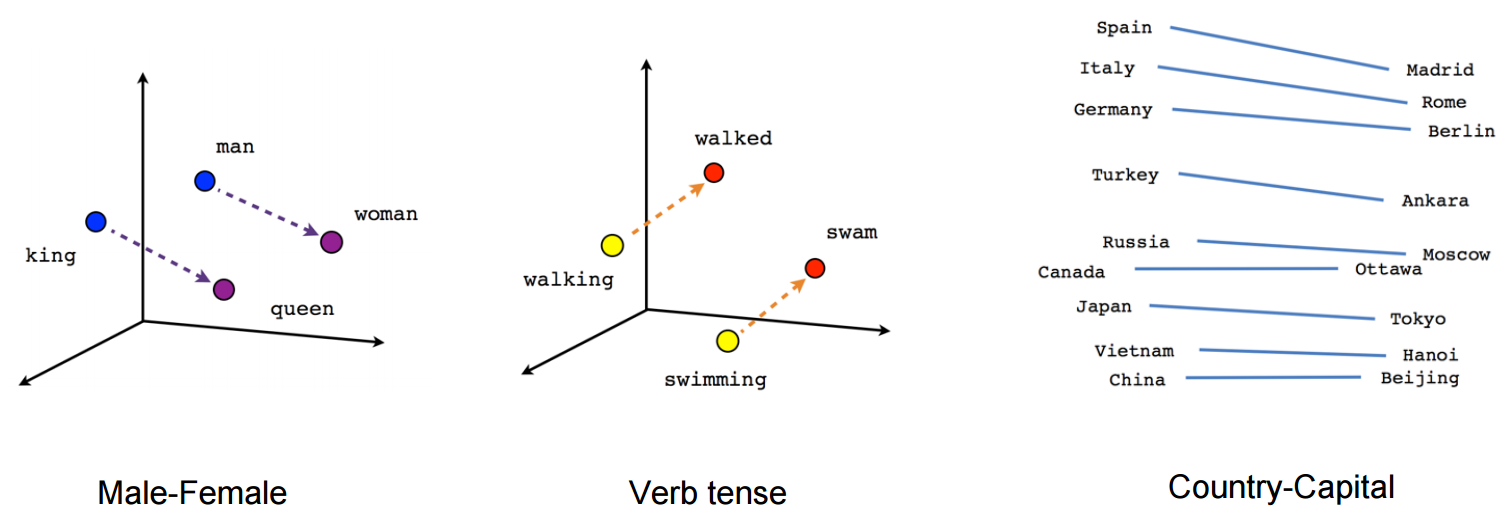
1. man - woman 사이의 관계와 king - queen 사이의 관계가 매우 유사하게 나타난다
생성된 임베딩 벡터가 단어의 의미적(Semantic) 관계를 잘 표현하는 것을 확인할 수 있습니다.
2. walking - walked 사이의 관계와 swimming - swam 사이의 관계가 매우 유사하게 나타난다
생성된 임베딩 벡터가 단어의 문법적(혹은 구조적, Syntactic)인 관계도 잘 표현하는 것을 확인할 수 있습니다.
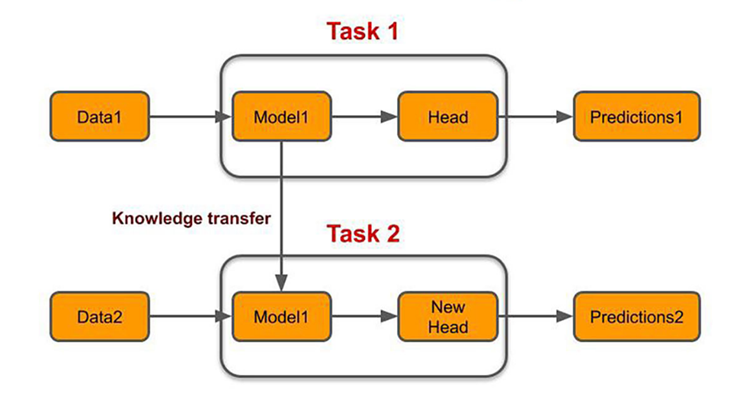
전이 학습(Transfer Learning)
대량의 데이터로 이미 학습한 사전 학습 모델의 가중치를 가져와 해결하려는 task에 맞게 추가적인 신경망을 만들고 학습하는 것
일반적으로는 가져온 가중치는 동결(학습 시 업데이트 하지 않음)시키기 때문에 모델 자체의 학습 속도가 빠르면서 준수한 성능을 보여줄 수 있다는 장점을 가지고 있다