자연어 처리, NLP(Natural Language Processing)
자연어 : 사람들이 일상적으로 쓰는 언어를 인공적으로 만들어진 언어인 인공어와 구분하여 부르는 개념
인공어의 반대, 자연적으로 발생된 언어
자연어가 아닌 것 : 에스페란토어, 코딩 언어 등
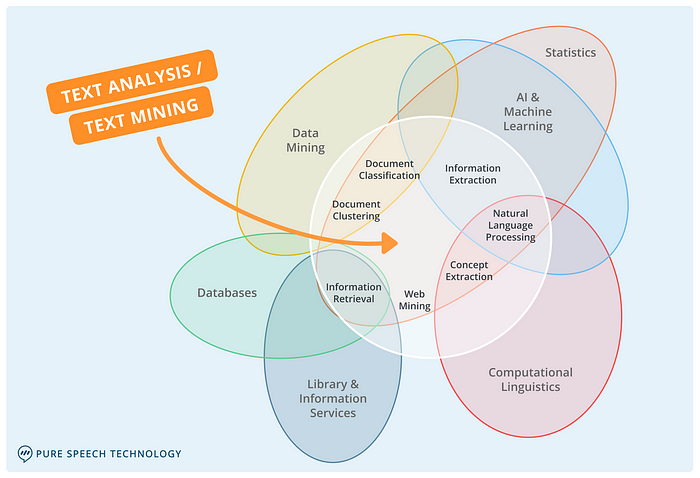
자연어를 컴퓨터로 처리하는 기술을 자연어 처리라고 함
자연어 처리로 할 수 있는 일들
1. 자연어 이해
1. 분류 (Positive or Negative)
2. 추론 (True or False)
3. 기계 독해 (비문학 문제 풀기)
4. 품사 태깅
2. 자연어 생성 (텍스트 생성, 뉴스 or 가사)
3. NLU & NLG (이해와 생성)
1. 기계 번역
2. 요약
3. 챗봇
4. 기타
1. TTS(Text to Speech)
2. SST(Speech to Text)
3. Image Captioning : 이미지를 설명하는 문장 생성
벡터화(Vectorize)
컴퓨터가 자연어를 이해할 수 있도록 자연어를 처리하는 과정
1. 등장 횟수 기반의 단어 표현 : 단어가 문서(혹은 문장)에 등장하는 횟수를 기반으로 벡터화하는 방법
- Bog-of-Words(CounterVectorizer)
- TF-IDF(TfidVectorizer) ⭐⭐⭐
2. 분포 기반의 단어 표현 : 타겟 단어 주변에 있는 단어를 기반으로 벡터화하는 방법텍스트 전처리(Text Preprocessing)

전처리 방법
- 대소문자 통일
- 정규표현식(Regular expression, Regex)
- 불용어(Stop words) 처리
- 통계적 트리밍(Trimming)
- 어간/표제어(Lemmatization) 추출
- 내장 메서드를 사용한 전처리(lower, replace, ...)
전처리 하는 이유
특성의 개수가 선형적으로 늘어날 때 동일한 설명력을 가지기 위해 필요한 인스턴스의 수는 지수적으로 증가한다.
즉 동일한 개수의 인스턴스를 가지는 데이터셋의 차원이 늘어날수록 설명력이 떨어지게 된다.
-> 복잡해서
정규표현식(Regex)

구두점이나 특수문자 등 필요없는 문자가 말뭉치 내에 있을 경우 토큰화가 제대로 이루어지지 않는다
re 라이브러리 사용
[a-z] : 소문자 a-z까지 인식
[A-Z] : 대문자 A-Z까지 인식
[^a-z] : a-z를 제외하고 모두
[가-힣] : 한글 인식
- re.sub(정규표현식, 치환할 문자, 치환대상)
-> '치환 대상'안에 '정규표현식'을 '치환할 문자'로 바꿔주세요
ex) re.sub(r'[a-z]', 't','amazon') = 'tttttt'
Spacy 구조
Spacy에서는 기본적으로 doc와 token을 사용한다
doc : token으로 이루어진 문장(문서)
token : 다양한 태그가 되어 있는 데이터
ex) # 기존 text 타입은 string
# 해당 텍스트가 문자열 인 것만 알 수 있고, 각각 명사인지, 표제어는 무엇인지 등을 알 수는 없다.
# 토큰화가 되어 있다면?
# 각 토큰마다 다양한 토큰을 통해 전처리를 할 수 있다.
# is_alpha, lemma, idx, vector 등등)Spacy 사용 순서
Pipeline(model) 호출
doc 생성
Token 처리
import spacy
# 1.Pipeline(model) 호출
nlp = spacy.load("en_core_web_
# 2. doc 생성
doc = nlp(text) # 다수의 텍스트로 이루어진 리스트인 경우 nlp.pipe(texts)
# 3. token 처리
for sentence in doc:
for token in sentence:
# 이후에 토큰마다 불용어처리, 표제어 추출 등 진행대소문자 통일, Text Preprocessing
Python 내장 메소드 lower() 사용
pandas 형식인 경우 : apply 활용
df['reviews.text'].apply(lambda x:x.lower
spacy 사용할 경우 token의 Attribute 중 lower_사용
token.lower()
불용어(Stop words) 처리
불용어 set을 생성하여 조건문 사용
if word not in STOP_WORDS:
token_list.append(word.lower())- Spacy token의 is_stop 사용
if token.is_stop == False:
token_list.append(token.lower_)임베딩, Count - Based Representation
사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 과정 전체
- 횟수 기반 표현
- TF : 단어들의 빈도만 고려
- TF-IDF : TF + 단어가 등장하는 문서 비율 고려 - 분산 기반 표현
- Word2Vec
- FastText

ㅋㄷ