JPA
1.Spring Data JPA
\-JPA(Java Persistence API)는 언어를 통해서 데이터베이와 같은 영속 계층을 처리하는 스펙 이다. \-ORM 을 java언어에 맞게 사용하는 스펙이다.JPA를 들어가기전 ORM을 알아햐 한다! ORM 이란..?\_\-ORM(Object Relatio
2.JPA Repository
\-Spring Data Jpa가 개발에 필요한것은 두종류의 코드로 가능하다1.엔티티 객체들을 처리하는 기능을 가진 Repository2\. jpa를 통해 관리하게 되는 객체를 위한 엔티티 클래스즉, 쉽게 요약해서 말하자면 엔티티 클래스를 만들고(DB에서 TABLE)
3.페이징/정렬 처리하기
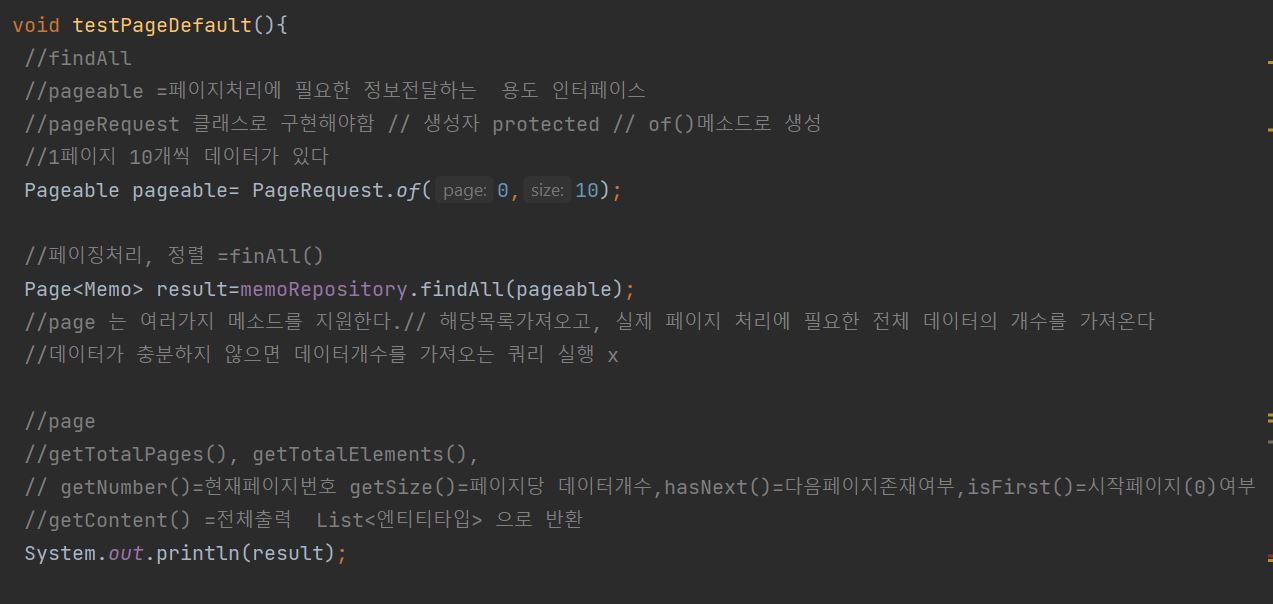
\-JPA 는 페이징처리와 정렬처리를 finAll()이라는 메서드를 사용한다.\-findAll()은 JpaRepository 인터페이스의 상위인 PagingSortRepository의 메서드로 전달되는 Pageablwe이라는 타입의 객체에 의해서 실행되는 쿼리를 결정하
4.쿼리메서드
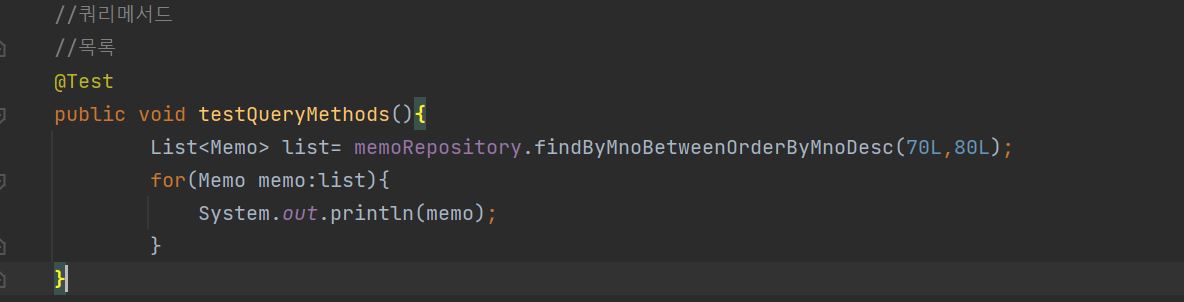
\-마지막 으로 살펴볼 기능은 쿼리메서드와 JPQL이라고 불리는 객체 지향 쿼리에 대한 기능이다.WHY Query method???\-앞의 예제에서 아쉬운 점은 다양한 검색 조건 이 불가능 하다는 점이다\-이 문제를 해결하기 위해 Spring data jpa 에서는 다
5.스프링MVC와 Thymeleaf
Thymeleaf는 JSP 처럼 화면처리에 쓰인다.Thymeleaf 는 JSP 를 사용해 본적이 있다면 별다른 어렴움 없이 사용 가능하다\-특정 태그를 제외한 타임리프는 항상 html 태그와 함께 쓰인다.\-항상 "html lang="en" xmlns:th="http
6.연관관계
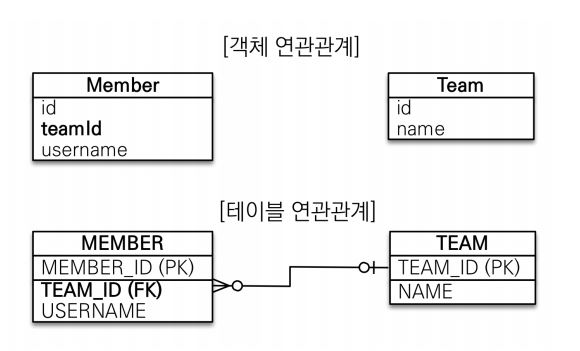
엔티티를 만들때 마다 너무 헷갈려서 한번 정리한다. 이건 왜이리 헷갈리는지...테이블은 외래키 하나로 두테이블이 연관관계를 맺는다.객체는 양방향 관계 참조가 2군데(사실 양방향이란거 없고 단방향 2개이다)그러므로 객체에서는 누가 외래키를 관리할지 정해준다.(연관관계
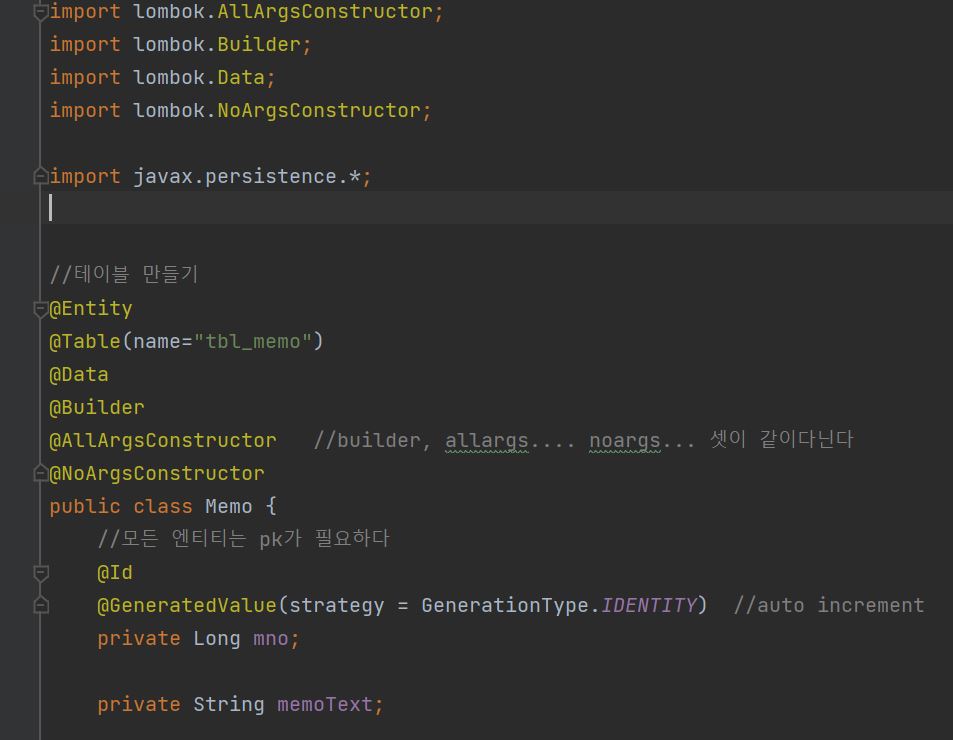
7.엔티티 맵핑
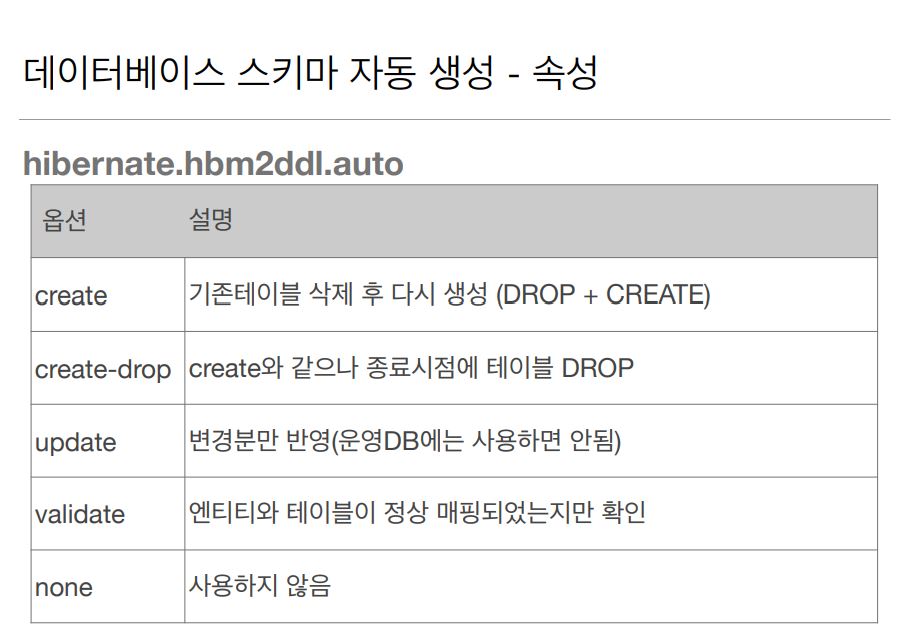
엔티티 기본맵핑에 대해 자세히 알아보자 내가 몰랐던 내용이나 좀더 중요한 내용을 중점으로 정리를 했다. 데이터베이스 스키마 이기능을 처음 봣을때 와 진짜 편하다 라는 생각에 마구 남발 했던 기억이난다. 그래서 협업을 할떄도 그냥 올려놓고 쓰면 되는거 아닌가 하면
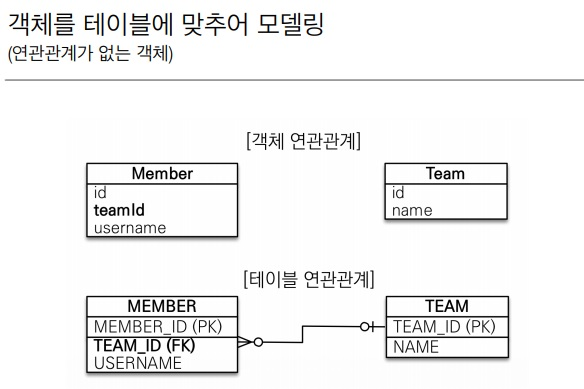
8.연관관계 맵핑
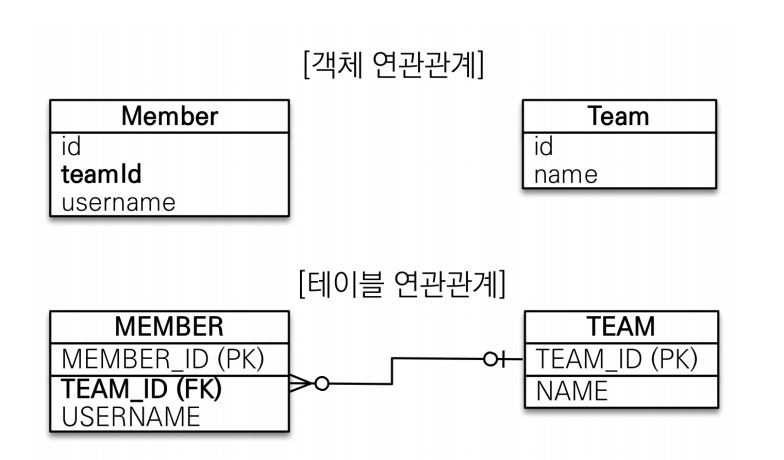
책으로 배웠을떄 그려러니 하면서 넘어가서 활용을 할때 잘 사용하지 못했던 부분에 대해서 다시 뒤로돌아가 배워봤다.이런식으로 연관관계를 만들어준다. 중요한점은 객체와 테이블의 연관관계의 차이점을 아는것이 가장 중요하다.객체연관관계를 설정 해준다. (참조 대신에 외래키를
9.@Query / 페이징처리
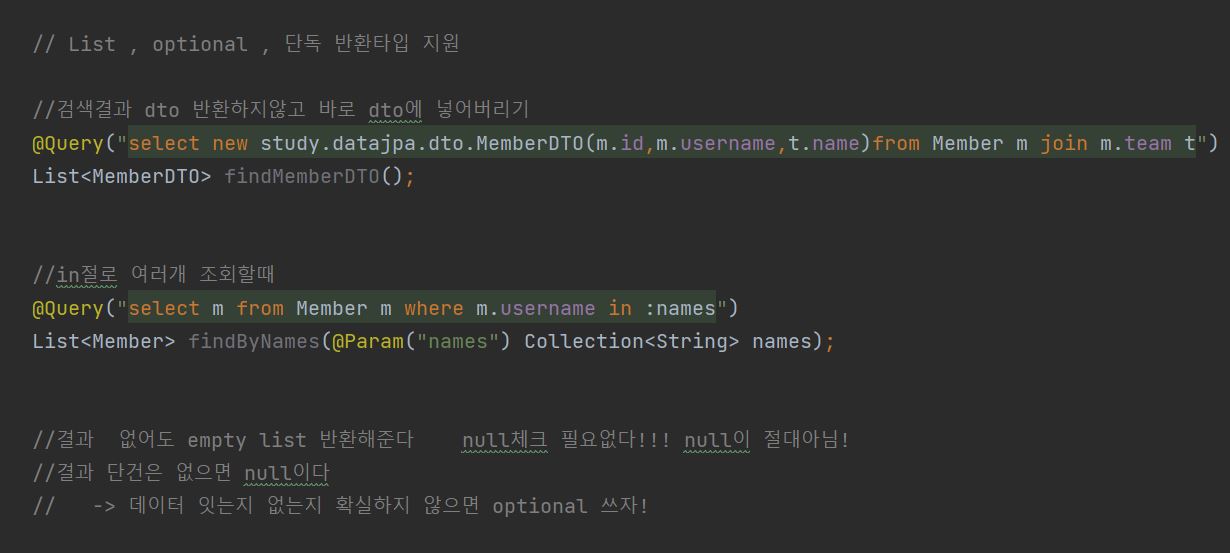
블로그 초반에 서 언급한듯이 내가 몰랐던점 이나 새로 알게된 사실에 대해서만 포스팅 할 예정이다.레퍼지토리에 쿼리문을 직접 작성하며 직접 db에서 데이터를 가져온다.결과를 반환하는 반환 타입에는 크게 List , Optional , 단독엔티티 가 있다.보통은 엔티티
10.벌크성 수정 쿼리
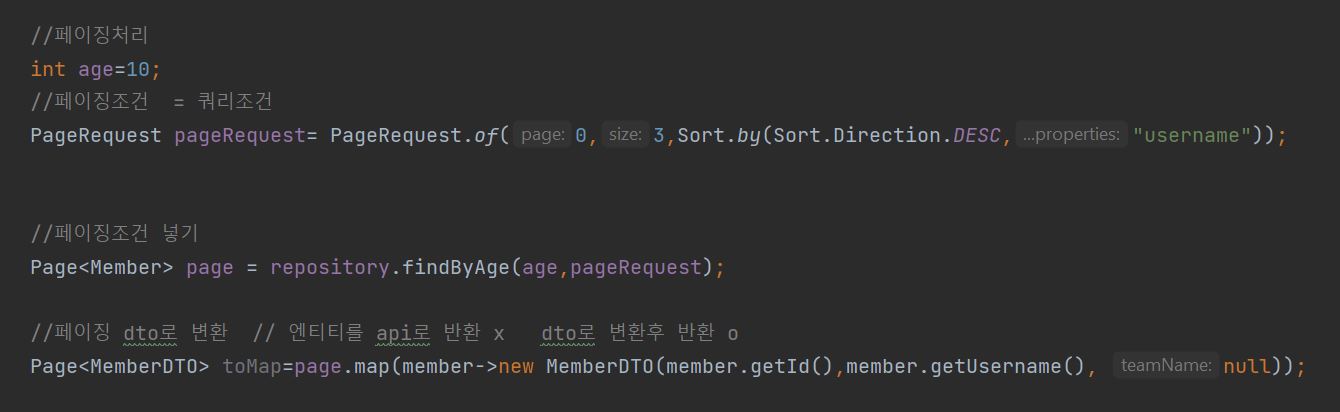
말그대로 한건한건이 아닌 여러건의 수정을 의미한다.벌크 연산은 영속성 컨텍스트를 무시하고 DB에 바로 접근한다.( 영속성 컨텍스트와 DB간의 데이터 차이 발생!!)벌크 연산후 영속성 컨텍스트 날려줘야함 ( Flusch() , -> clear() )@Modifying
11.Fetch Join / @EntityGraph
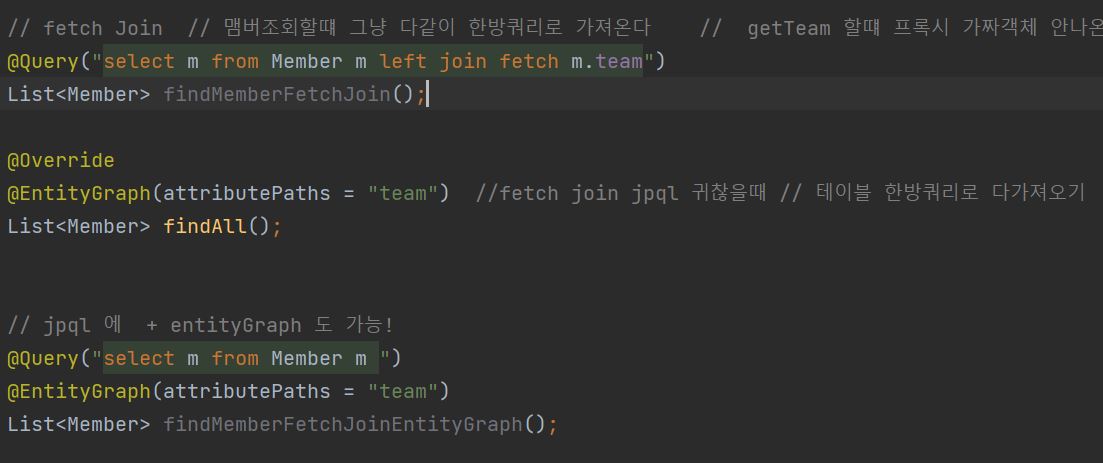
Fetch Join/@EntityGraph Member ->Team 지연관계 team의 데이터를 조회할때마다 쿼리가 실행된다 -> team 객체를 조회하면 프록시라는 가짜 객체를 넣고 부른다. 왜냐 Lazy 로딩떄문 -> team 의 내용을 건드리는 순간 진짜 데이
12.Hint / Lock
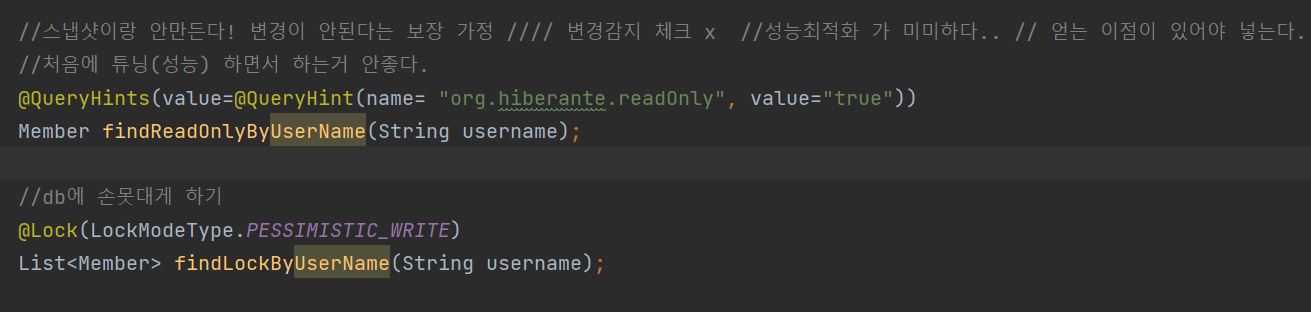
Hint SpringDataJPA 에서는 변경이 있을경우 변경감지(Dirty checking)이 발생한다. 엔티티가 영속성 컨텍스트에 최초에 들어왔을떄 스냅샷 이란걸 1차캐쉬에 남겨둔다. 나중에 변화가 있을때 비교하기위해 스냅샷 + 변화된 엔티티까지 저장해야하므
13.고급맵핑 / MappedSuperClass
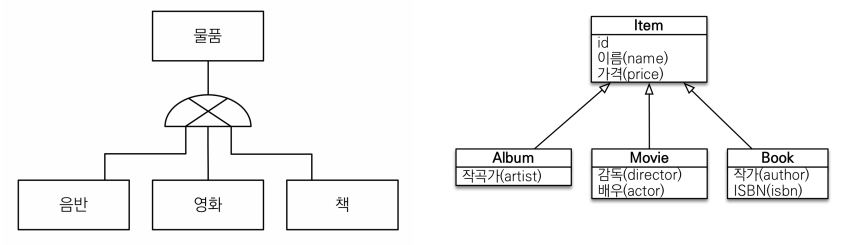
관계형 데이터베이스는 상송관계가 없다슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사하다상속관계 맵핑: 객체의 상속 구조와 DB의 슈퍼타입 서브타입 관계를 맵핑 상속관계 맵핑에는 크게 3가지 방법이 있다.각각테이블로 변환 -> Join전략 \->(@Inher
14.SpringDataJPA 구현체

JPA에서는 수정이나 삭제 등록에는 꼭 @Transactional 이 쓰여야 한다. SpringDataJPA 가 제공하는 공통 구현체인 SimpleJpaRepository 는 기본적으로 @Transactional 이 선언되있다.( 그러므로 우리가 등록/수정/삭제를 할
15.영속성 전이 (CASCADE)/ 고아객체
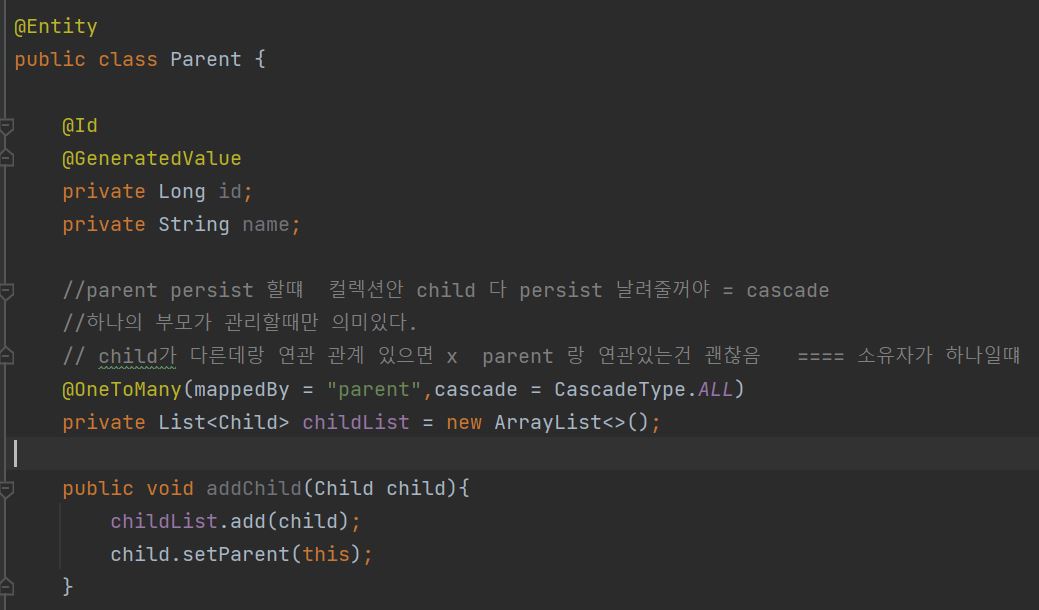
caseCade를 안쓰면 부모 persist 한번, child persist 한번 두번 날려줘야 한다casCade를 쓰면 ->말 그대로 부모 엔티티를 저장할떄 자식 엔티티도 함께 저장=>특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들도 싶을
16.프록시
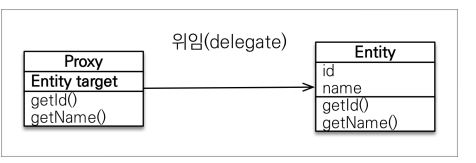
프록시는 실제 클래스를 상속 받아서 만들어 진다실제 클래스와 겉 모양이 같다프록시 객체는 실제 객체의 참조(target)를 보관한다.프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드 호출Member -> Team 있다고 가정해보면 Team 클래스를 부를 떄까지는
17.영속성 컨텍스트

JPA를 써봤지만 내부구조가 어떻게 돌아가는지에 대해 잘 몰라 이번시간에 학습을 해보자! 기본적으로 JPA 는 요청 리퀘스트가 오면 EntityManagerFactory 에서 EntityManager 을 생성해 EM이 DB에서 값을 거내오는 방식이다. 그럼 영속성
18.연관관계 맵핑 V2
저번에 작성했던 연관관계 맵핑 부분에 대해 다시복습도하고 좀 더내용을 추가 하였다.이런식으로 연관관계를 만들어준다. 중요한점은 객체와 테이블의 연관관계의 차이점을 아는것이 가장 중요하다.객체연관관계를 설정 해준다. (참조 대신에 외래키를 그대로 사용)이러한 방식을 데이
19.프록시 V2
기존 프록시 학습에대해 내용을 추가 하였다em.find() 는 실제 객체를 불러오고 em.getReference() 는 프록시(가짜객체)를 불러온다맵핑이 잘돼잇는 상태에서 find()를 사용하면 jpa는 연관된 객체까지 다 select 해온다. (JPA 가 알아서 J
20.즉시로딩 vs 지연로딩
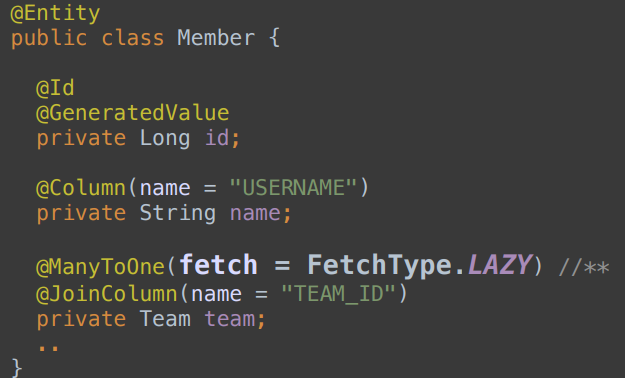
테이블을 만들다보면 맵핑관계에 대해 고민하게 됀다.이 테이블들은 서로 연관이 있지만 같이 사용되지 않을때와 같이 자주 사용될때같이 자주사용하지 않는데 맵핑으로 인해 A라는 테이블을 불러올떄마다 B라는 테이블을 자동으로 불러오면 그만큼 쿼리가 나가니 성능이 저하 된다.연
21.Cascade/고아객체 V2
caseCade를 안쓰면 부모 persist 한번, child persist 한번 두번 날려줘야 한다casCade를 쓰면 ->말 그대로 부모 엔티티를 저장할떄 자식 엔티티도 함께 저장=>특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들도 싶을
22.기본값 타입
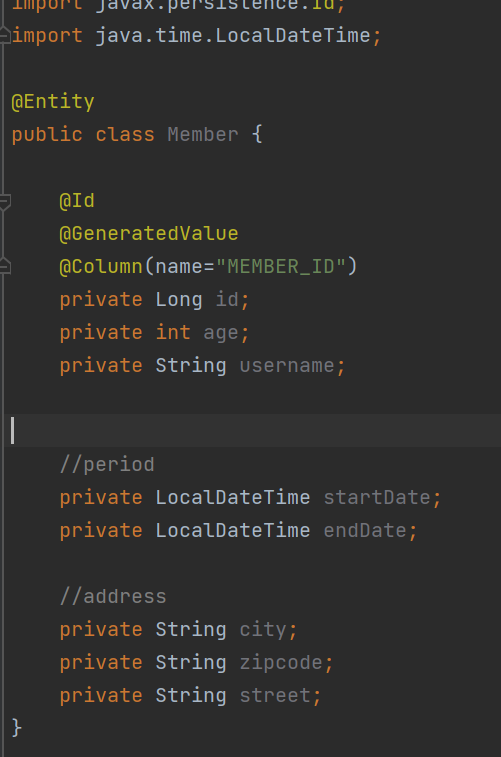
1\. 엔티티타입2\. 값타입@Entity로 정의하는 객체데이터가 변해도 식별자로 지속해서 추적가능\-> pk만 있으면 해당 정보가 바뀌어도 구별 할수 있다int, Integer, String 처럼 단순히 값으로 사용하는 자바 기본 타입식별자가 없고(pk) 값만 있으므
23.값 타입과 불변 객체
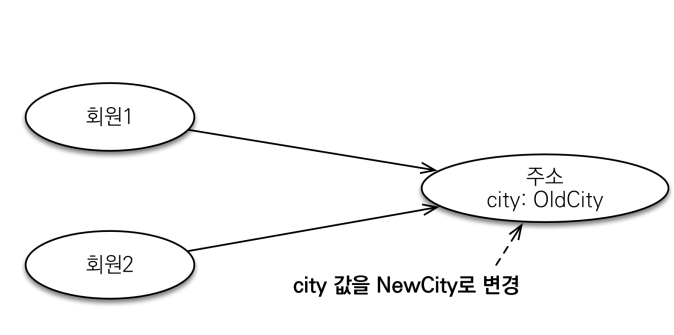
저번시간에 임베디드 타입 에 대해 배웠다.임베디드 타입의 장점을 알아봤으니 단점을 알아보자임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 사이드 이펙트가 발생해 위험하다공통점을 묶어 같은 클래스 안에 있으니 한 쪽에서 값을 바꾸면 다른 한쪽도 바뀌는 현상이 발생
24.값 타입 컬렉션

값 타입 컬렉션이란?? 값 타입을 컬렉션에 담아서 쓸때 사용하는 것 값 타입이 하나일때는 그냥 컬럼으로 DB에 넣으면 되지만 컬렉션 을 DB에 어떻게 넣을까??라는 것에대한 해결책 별도의 테이블을 만들어야한다 값 타입 컬렉션 특징 식별자 ID 같은 PK가 있으면
25.JPQL with Errors...
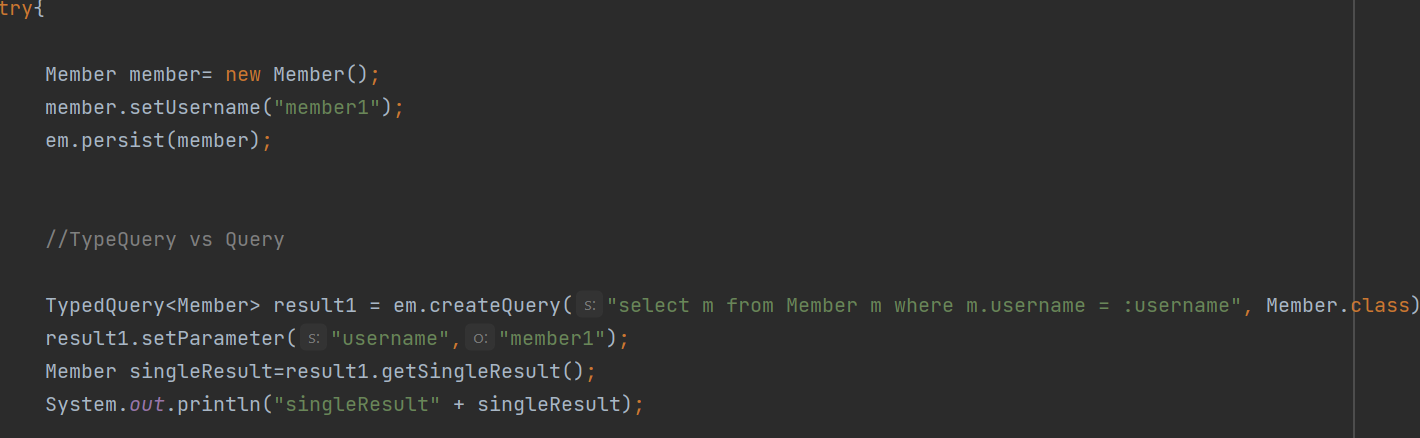
JPA 에서 지금까지 조회를 할떄 find() 을 이용해 간단한 검색만 해왔다. 하지만 조금더* 복잡하고 디테일하게 쿼리*를 어떻게 작성할까??? 예를들어 Member중 age가 20이상인 회원을 검색한다면? JPQL 검색을 할떄 테이블이 아닌 엔티티 객체를 대상
26.JPQL PART 2
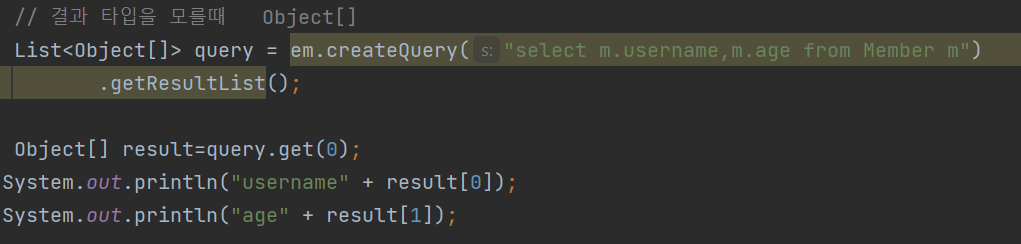
SELECT 절에 조회할 대상을 지정하는 것SELECT m FROM Member m -> 엔티티 프로젝션SELECT m.team FROM Member m -> 엔티티 프로젝션SELECT m.address FROM Member m -> 임베디드 타입 프로젝션SELECT
27.JPQL- part3(경로표현식/fetch join)

단일 값 연관 필드 \-@ManyToOne , @OneToOne, 대상이 엔티티\-묵시적 내부조인 (inner join) 발생, 탐색 가능\-여기서 탐색이란 m.team.getName() 이런식으로 더 들어갈수 있다는 의미이다컬렉션 값 연관 필드\-@OnetToMan
28.JPQL part4
JPQL 엔티티 직접 사용 엔티티 직접사용 기본키값 JPQL에서 엔티티를 직접 사용하면 SQL에서** 해당 엔티티의 기 본 키 값을 사용** 무슨 말인지 헷갈리니 직접 코딩 해보자! 쿼리문이 where m -> where m.id 로 변환되서 실행되었다. m
29.SpringDataJPA (cheat sheet)

공부순서 JPA 학습 전 SpringDataJPA 먼저 학습을 한 사람으로써 사용도중 이해가 되자 않는 부분과 어려운점이 많았다. 그래서 기초부터 다시 하자라는 의미로 최근까지 내 글목록 에서 볼수있듯이 JPA를 학습하고 SpringDataJPA 를 다시 학습해 요점만
30.JPA / SpringDataJPA/Hibernate
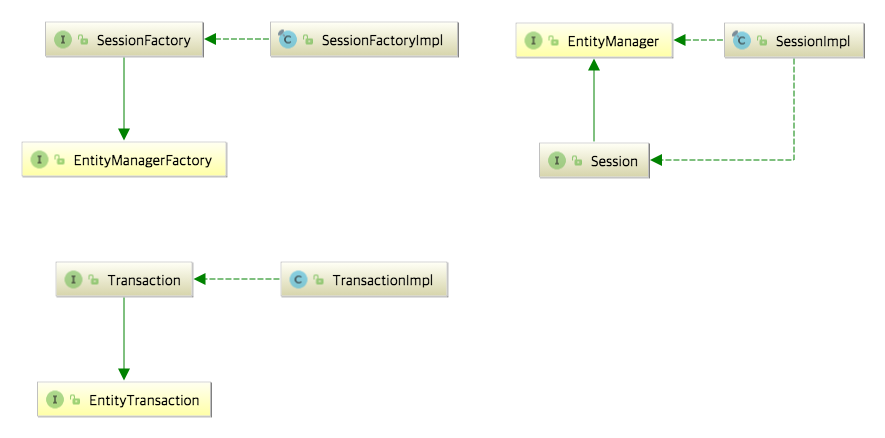
사용을 하면서 정확하게 모르는것같아 좋은 글이 있어서 포스팅한다. Spring 프레임워크는 어플리케이션을 개발할 때 필요한 수많은 강력하고 편리한 기능을 제공해준다. 하지만 많은 기술이 존재하는 만큼 Spring 프레임워크를 처음 사용하는 사람이 Spring 프레임워크
31.nullable=false VS notNull

개인 프로젝트를 하던도중 문득 사용하던 애노테이션에 가지는 비슷한 기능인것 같은데 라는 생각에 차이점에 궁금해서 알아봤다.우선 @Column(nullable = false)을 사용할 때와 마찬가지로 @NotNull 역시 테이블 생성시 NOT NULL DDL이 입력된