블로그 초반에 서 언급한듯이 내가 몰랐던점 이나 새로 알게된 사실에 대해서만 포스팅 할 예정이다.
@Query
-
레퍼지토리에 쿼리문을 직접 작성하며 직접 db에서 데이터를 가져온다.
-
결과를 반환하는 반환 타입에는 크게 List , Optional , 단독엔티티 가 있다.
-
보통은 엔티티에서 나온값을 엔티티에 넣어서 바로 반환하지는 않고 dto에 넣어서 반환한다. 그 이유는 엔티티로 그대로 반환하고 나중에 엔티티가 변경이 되면 api 컨디션도 다바뀌어서 에러를 유발하기 때문!
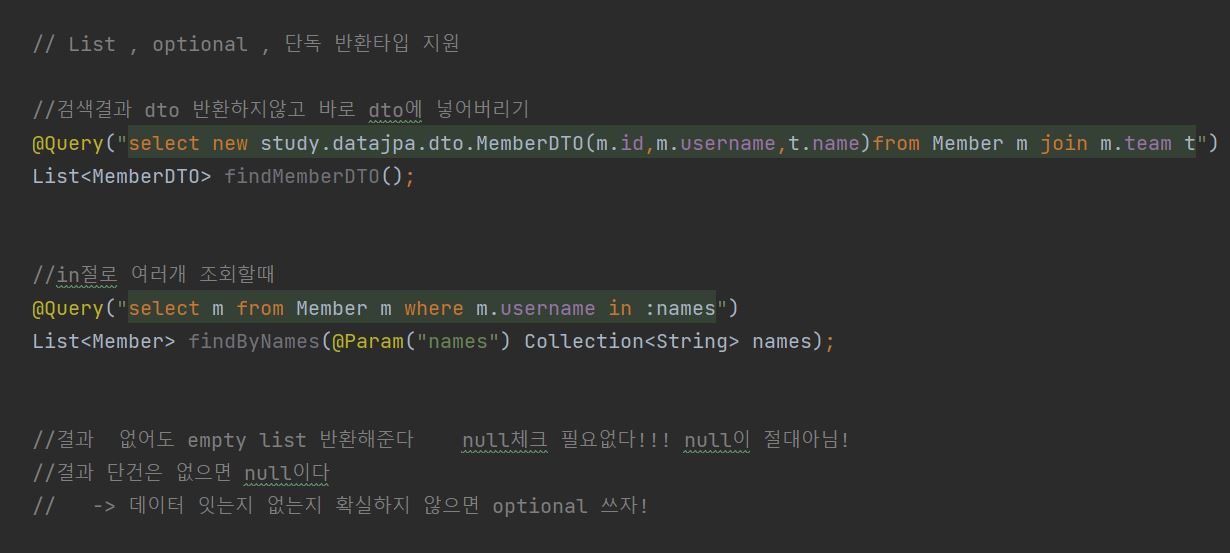
위에 사진은 내가 @Query 을 두번쨰 공부하면서 새로 알게된 사실이다.
1. 쿼리문에서 바로 dto로 넣어서 반환할 수 있다.(dto위치 자세히 적기)
2. collection 타입으로 in절 지원 (여러 조건을 한번에 조회) 할수 있다.
결과가 없으면?????????
1. collection = 빈컬렉션 반환 (null체크 필요없다)
2. 단건 = null
페이징처리
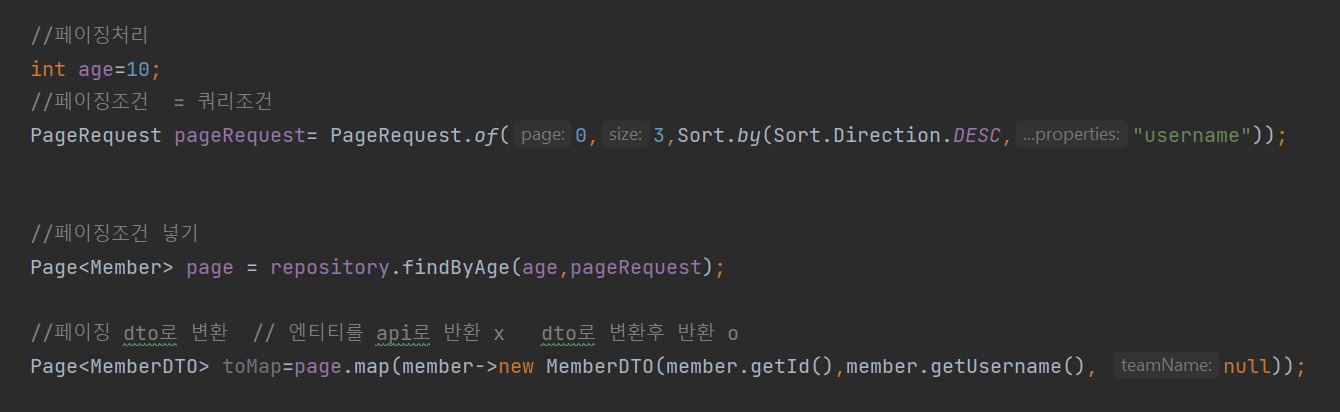
반환타입 page
-
기본적으로 pageable 인터페이스를 구현한 pageRequest 를 사용한다.
-
반환 타입으로는 보통 page,이지만 slice, List 도 가능하다.
-
@Query + pageable
-
페이징조건 만들기 ->조건사용해서 데이터추출-> dto로 바로 변환가능(map)
-
count쿼리까지 같이 가져온다. (join문 테이블(카운트 쿼리)도 가져온다)
-
위에랑 이유가 같다 . 엔티티를 바로 반환 x dto로 변환 반환 o
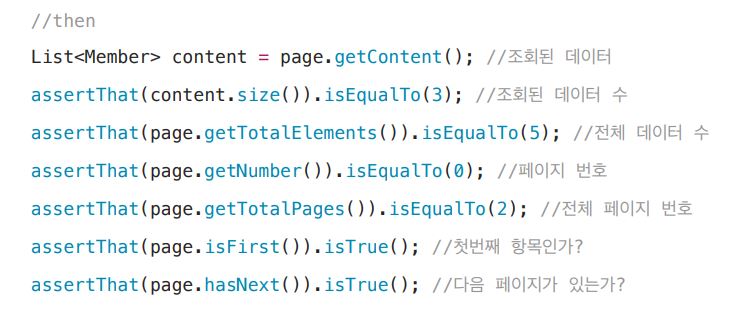
- 반환타입 page 면 조회된 데이터, 조회된 데이터수, 전체 데이터수, 페이지번호 등등 다양한 메서드 제공
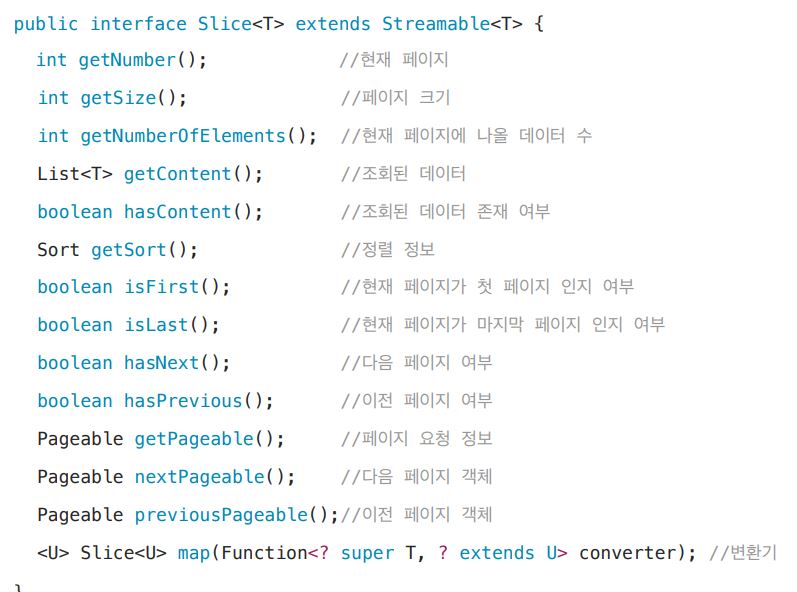
반환 타입 slice
토탈페이지를 page처럼 가져오는게 아니라 다음페이지가 있어 없어? 리미트 1+
반환타입 List
- 페이징이고 뭐고 그냥 결과만 뽑을때 사용
★count 쿼리 분리 ★

page( count o)
slice (count x)
List( count x)
-
데이터는 left join, 카운트는 left join 안해도됨
-> page 는 카운트쿼리까지 가져오므로 간단한건 괜찮은데 join이 많으면 카운트쿼리 또한 join을 다해서 가져온다 = 성능저하-> 사실 카운트쿼리는 join이 필요없다 어자피 옆에 붙는 테이블(조인이)없어도 개수는 같기때문에 join이 많으면 카운트쿼리는 때야 성능향샹
전체 카운트 쿼리는 매우 무겁다
pageable 넣기
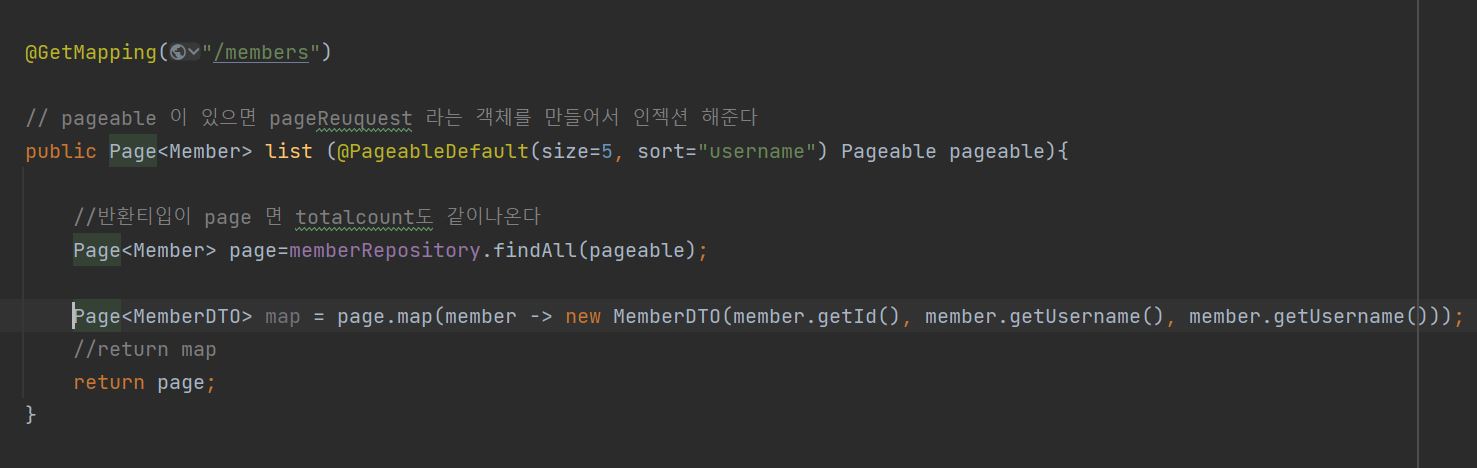
- pageRequest로 설정할수도 있고 파라미터로 pageable을 넣을수 있다.

- yml 로 디폴트 값을 설정 할수도 있고

- 애노테이션으로 기본 디폴트값을 설정할수도 있다.
