JPA Repository
-Spring Data Jpa가 개발에 필요한것은 두종류의 코드로 가능하다
1.엔티티 객체들을 처리하는 기능을 가진 Repository
2. jpa를 통해 관리하게 되는 객체를 위한 엔티티 클래스
즉, 쉽게 요약해서 말하자면 엔티티 클래스를 만들고(DB에서 TABLE) 그걸 JPA로 컨트룰 한다고 생각하면 된다.
백문이 불여일견이라 실습을 통해 알아보자
실습-엔티티 클래스 만들기
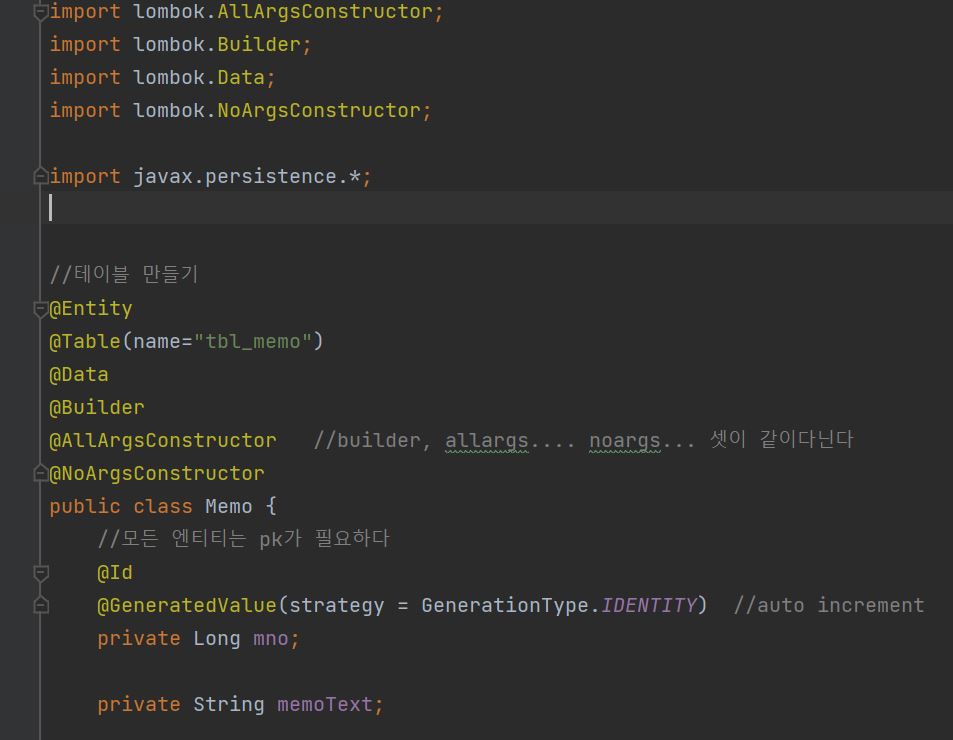
엔티티 클래스를 만들어준다. 마치 DB TABLE과 같은 구조로 작성을 해준다.
여기서 잠깐! 수많은 애노테이션(Annotation) 을 알아보자!
@Entity
-해당 클래스가 엔티티를 위한 클래스이며 해당 클래스의 인스턴스들이 jpa로 관리되는 엔티티 객체임을 나타낸다.
@Table
-데이터베이스상에서 엔티티 클래스를 어떠한 테이블로 생설할것인지에 대한 정보를 담기 위한 애노테이션이다.
@Id와 @GerneratedValue
-@ id 는 PK 를 지정할떄 쓰고 @GerneratedValue는 my sql에서 autoincrement 와 같은 자동으로 생성되는 번호를 사용하기 위해서 사용된다.
1.@GernetatedValue(strategy=Generation.type.AUTO)
=JPA 구현체가 생성 방식을 결정
2.@GernetatedValue(strategy=Generation.type.IDENTITY)
=사용하는 데이터베이스가 키 생성을 결정, MY SQL이나 MARIA DB의 경우 auto increment 방식 이용
3.@GernetatedValue(strategy=Generation.type.SEQUENCE)
=데이터 베이스의 sequence 를 이용해서 키를 생성.@SequenceGernator와 같이 사용
4.@GernetatedValue(strategy=Generation.type.TABLE)
=키 생성 전용 테이블을 생성해서 키 생성,@Table Gernator와 함께 사용
@Column
@column(columnDefinition="varchar(255) default 'yes')
-데이터베이스의 컬럼에 필요한 정보를 제공한다.
@ArgsConstructor
-매개변수 생성자
@noArgsConstructor
-일반 생성자
※@Builder 를 이용하기위해서는 _@ArgsConstructor, @noArgsConstructor 를 항상 같이 처리해야 컴파일 에러가 발생하지 않는다.
※@column과 반대로 db테이블 컬럼으로 생성되지 않는 필드는 @transient 애노테이션을 적용한다
JPA를 위한 스프링 부트 설정
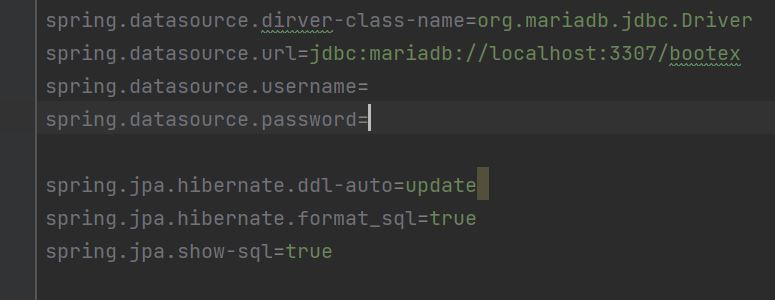
spring.jpa.hibernate.ddl-auto=update
= 프로젝트 실행 시에 자동으로 DDL(create,alter,drop 등) 을 생성 할 것인지를 결정하는 설정이다
(설정값은 create,updarte,create-drop,validate가 있다)
spring.jpa.hibernate.format_sql=true
=실제 jpa의 구현체인 Hibernate가 동작하면서 발생하는 SQL을 포맷팅햇 출력해준다.
spring.jpa.show-sql=true
=JPA 처리 시에 발생하는 SQL을 보여줄 것인지를 결정한다
※위 3가지 항목을 추가하면 후 프로젝트 실행시에 db에 어떤 테이블이 생성되는지 로그를 통해 확인 가능하다
JPA Repository

-특별한 경우가 아니라면 JPARepostiory 를 이용하는것이 무난하다.

-JpaRepostiroy 는 인터페이스고, spring data jap는 이를 상속하는 인터페이스를 선언하는 것만으로도 모든 처리가 끝난다.
※JpaRepository 를 사용할떄는 <엔티티의 타입정보,@ID의 타입> 을 설정 해야만 한다.
-이처럼 Spring Data Jpa는 인터페이스 선언만으로도 자동으로 스프링으 빈 으로 등록 된다.
JPA 대표적 기본 기능
1.INSERT 작업= save(엔티티객체)
2.SELECT 작업=findById(키 타입,) getOne(키타입)
3.update 작업= save(엔티티객체)
4.delete 작업= deleteById(키 타입) delete(엔티티 객체)
-신기하게도 1번과 3번은 메서드가 동일하다. 이는 JPA 의 구현체가 메모리상에서 객체를 비교하고 없다면 INSERT , 존재한다면 UPDATE를 동작 시키기 떄문이다.
테스트 코드를 작성해보자!
등록

@autowired
=생성자나 메서드에 의존 객체를 주입할 필요가 있을 때, 타입에 따라 알아서 주입해준다(의존성 주입)
코드설명
stream을 사용해 100개의 새로운 Memo 객체를 생성 하고 MemoRepository 를 이용해 insert한다.
조회(detail)
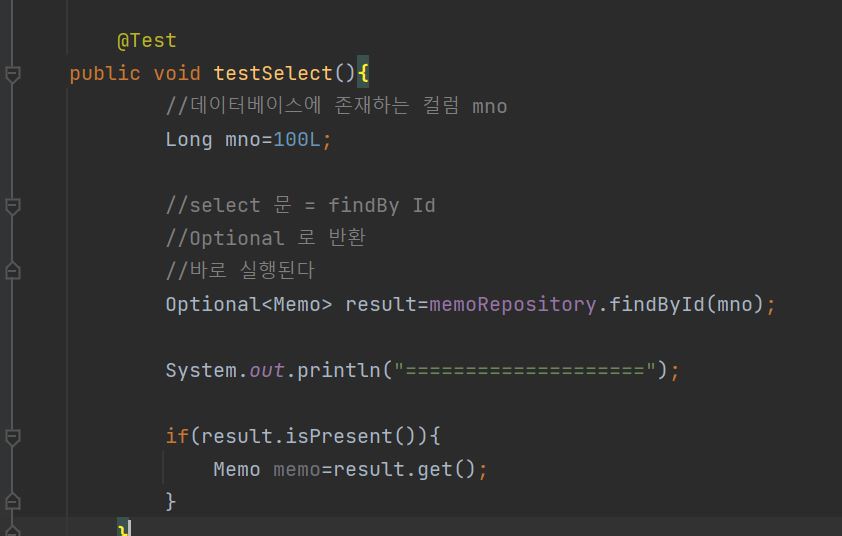
코드설명
-findById를 통해 엔티티 객체를 조회할수 있다.(getOne 은 depreacated 되버렸다.)
-findById 는 optional 타입으로 반환된다
수정
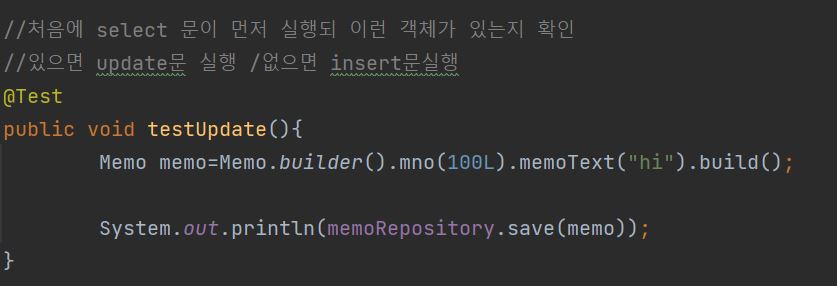
코드설명
-코드를 보면 100개의 객체를 만들고 save를 해 저장을 하는것이 보인다.
-JPA는 엔티티 객체들을 메모리상에 보관하려고 하기 떄문에 특정한 엔티티 객체가 존재하는지 확인하는 SELECT가 먼저 실행되고 해당 @Id를 가진 객체가 있다면 update 그렇지 않다면 INSERT 를 실 행한다.
삭제
-삭제 작업도 수정과 동일한 개념이 적용된다.
-삭제하려는 번호(mno)의 엔티티 객체가 있는지 확인하고 이를 삭제한다.
-리턴타입은 void이고 ,해당 데이터가 존재하지 않으면 Empty Result Access Exception 발생
