역전파
파라미터를 일일이 계산하는 것은 시간과 비용이 많이 들어가는 방법이다. 편미분을 개수만큼 진행해야 하기 때문이다.
따라서 이를 보완하기 위해 역전파가 등장했다.
계산 그래프
일련의 연산 과정을 하나의 방향 그래프로 나타낸 것이다. 아래의 그림과 같이 구성을 이룬다.
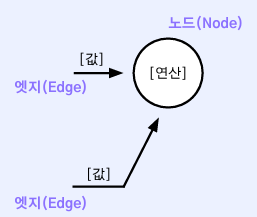
구조
구조는 다음과 같이 이루어진다.
- 노드(node): 하나의 연산을 의미
- 엣지(edge): 노드(연산)에 필요한 입력값을 의미
사용하는 이유
계산 그래프를 사용하게 되면 편미분 계산이 가능하며 중간 결과를 보관할 수 있다. 이를 통해 다음과 같은 이점을 가지게 된다.
- 복잡한 문제를 단순화
- 각 변수에 대한 미분을 효율적으로 계산
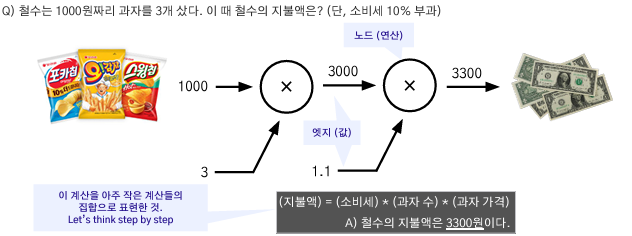
아래의 그림에서 계산 그래프의 예제를 확인할 수 있다.
연쇄 법칙
다음 수식은 우리가 흔히 알고 있는 연쇄법칙이다.
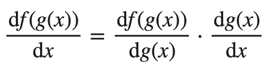
뉴럴넷과의 연관성
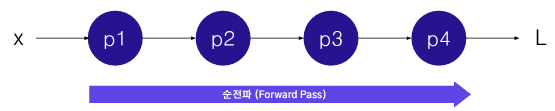
4개의 노드로 구성된 간단한 뉴럴넷을 예제로 들었을 때 다음과 같은 특징이 있다.
x에 대해 손실함수 계산 가능
각각의 파라미터를 업데이트 하기 위해 편미분을 구해야함
모든 파라미터에 대해 편미분을 적용해야하지만 연쇄법칙으로 그 과정을 일부 줄일 수 있음
또한 x 에서 L까지 방향대로 수식을 계산하여 구하는 것이 순전파, 반대로 L부터 시작해서 x에 가까운 노드까지 구하는 방식이 역전파이다.
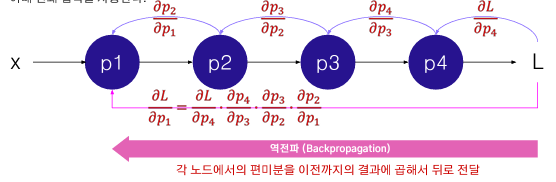
역전파 알고리즘
신경망의 추론 방향과 반대되는 방향으로 순차적으로 오차에 의한 편미분을 수행하여 각 레이어의 파라미터를 업데이트하는 과정을 역전파 알고리즘이라 한다.
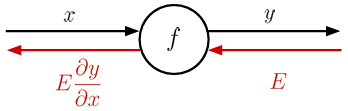
다음과 같이 순전파 방향으로 계산을 진행하고 역전파 방향으로 파라미터를 구하는 방식으로 작동한다. 이때 노드의 종류는 다음과 같이 두가지를 예시로 들 수 있는데, 역전파를 통해 파라미터를 구하기 위해 다음과 같은 방법으로 파라미터를 업데이트 한다.
- 곱셈 노드: 다른 엣지의 값을 곱해서 넘어감
- 덧셈 노드: 그대로 넘어감
파라미터 업데이트
파라미터는 다음과 같은 방법을 통해 업데이트 된다.
- 순전파 방향으로 Loss 계산고 예측을 진행
- 역전파를 통해 편미분 계산
- 각 파라미터에 learning rate를 곱하여 감산해주기
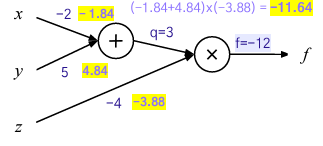
예시를 통해 learning rate까지 도입하였을 때 다음과 같이 과정을 진행시킨다.
손실 함수의 기본 가정
손실함수를 들어가기에 앞서 다음과 같이 Notation을 정의하고 진행하기로 한다.
활성화 함수 입력: z
활성화 함수 출력: a
delta: error
j: 뉴런
l: layer
Loss에 대하 가정
Loss에 대한 가정은 다음과 같다.
- 학습 데이터 샘플에 대한 신경망의 총 손실은 각 데이터 샘플에 대한 손실과 같다.
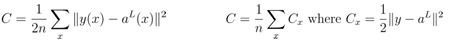
이를 통해서 다음과 같이 편미분을 계산할 수 있다.

여기서 w와 b에 대해서 어떤 차이가 있는지 궁금할 것이다. w는 weight를 나타내며 b는 bias를 나타낸다.
- 각 학습 데이터 샘플에 대한 손실은 a^L에 대한 함수이다.
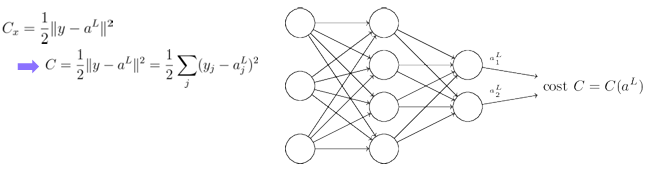
비용 함수는 설계하기 나름이다. 중간 레이어의 출력 값으로도 비용 함수를 계산할 수도 있지만, 최종 출력에 대한 함수로만 정의해야 역전파를 활용 가능하다.
역전파의 기본 방정식
for the error in the output layer, 𝜹^L

다음과 같이 수식이 표현되며 이 식을 전개할 수 있다. 또한 행렬로 계산할 수도 있는데 결과적으로 간단하게 표현하면 다음과 같다.

for the error in the l-th layer in terms of the error in the next layer (l+1), 𝜹^𝒍 ↔ 𝜹^(l+1)
마지막 layer가 아닌 다른 hidden layer에서 계산되는 계산식은 다음과 같다.

이것 또한 행렬로 나타내면 다음 그림과 같다.
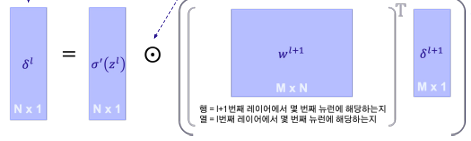

for the rate of change of the cost with respect to any (bias/weight) in the network
위의 노드에서 구했던 방식 처럼 각각의 weight, bias를 구하려면 다음과 같은 식을 얻을 수 있다.

위가 bias, 아래가 weight를 나타낸다.
여기서 얻을 수 있는 insight는 다음과 같다.
- Low-activation neurons
- 만일 뉴런 a가 활성화된 정도가 작다면,관련 가중치의 변화가 비용 함수 C의 변화에거의 영향을 주지 않는다.
- 마찬가지로, 가중치 또한 천천히 학습된다. (즉, C의 기울기도 가중치에 영향을 주지 않는다.)
- Saturated neurons
- 출력층에서의 출력값이 거의 0 또는 1인 경우,관련 뉴런의 가중치 및 편향는 느리게 학습된다.
- 이는 이미 잘 맞추는 문제는 더 이상 풀지 않는 것과 유사하다.
Summary
역전파의 파라미터를 구하는 방식을 다음과 같이 한눈에 요약할 수 있다.

또한 각 layer의 역전파 알고리즘은 다음과 같은 과정으로 계산된다.

마지막으로 bias, weight 또한 다음과 같이 계산된다.

🤔고찰
역전파 알고리즘은 기존에 한번 공부해본 적이 있었다. 편미분을 번거롭게 해야하는 경사하강법의 단점을 보완한 방법이라 외우고 있었다. 따라서 처음에 순방향으로 진행하고 역방향으로 역산하는 과정은 이미 알고 있었지만 체인 룰을 통해 파라미터가 전달된다는 방식으로 외우기 보다 이전 레이어로 진행할 때 이미 구해져있었던 현재 레이어의 값을 대입하는 방식으로 잘못 알고 있었다. 이번 기회를 통해 바로잡을 수 있었던 좋은 기회를 가지게 되었고 아직까진 딥러닝 모델에 어떻게 적용되는지 실감이 나지 않지만 곧 활용해보다 보면 감이 올것이라 생각이 든다.
