퍼셉트론의 개요
퍼셉트론의 구조
퍼셉트론은 1957년 코넬 항공 연구소의 프랑크 로젠블라트에 의해 고안된 가장 간단한 형태의 Feed-Foward 네트워크라 한다. 입력 신호를 받아 수식을 계산하여 결과를 출력해주는 방식으로 진행된다. 흔히 사람의 뇌에는 뉴런이 존재하는데 모형 자체가 이 뉴럴과 비슷한 모양을 가지고 있기 때문에 인공 뉴런이라 부르기도 하며 지식을 학습하는 방법 또한 비슷한 내용을 가지고 있다.
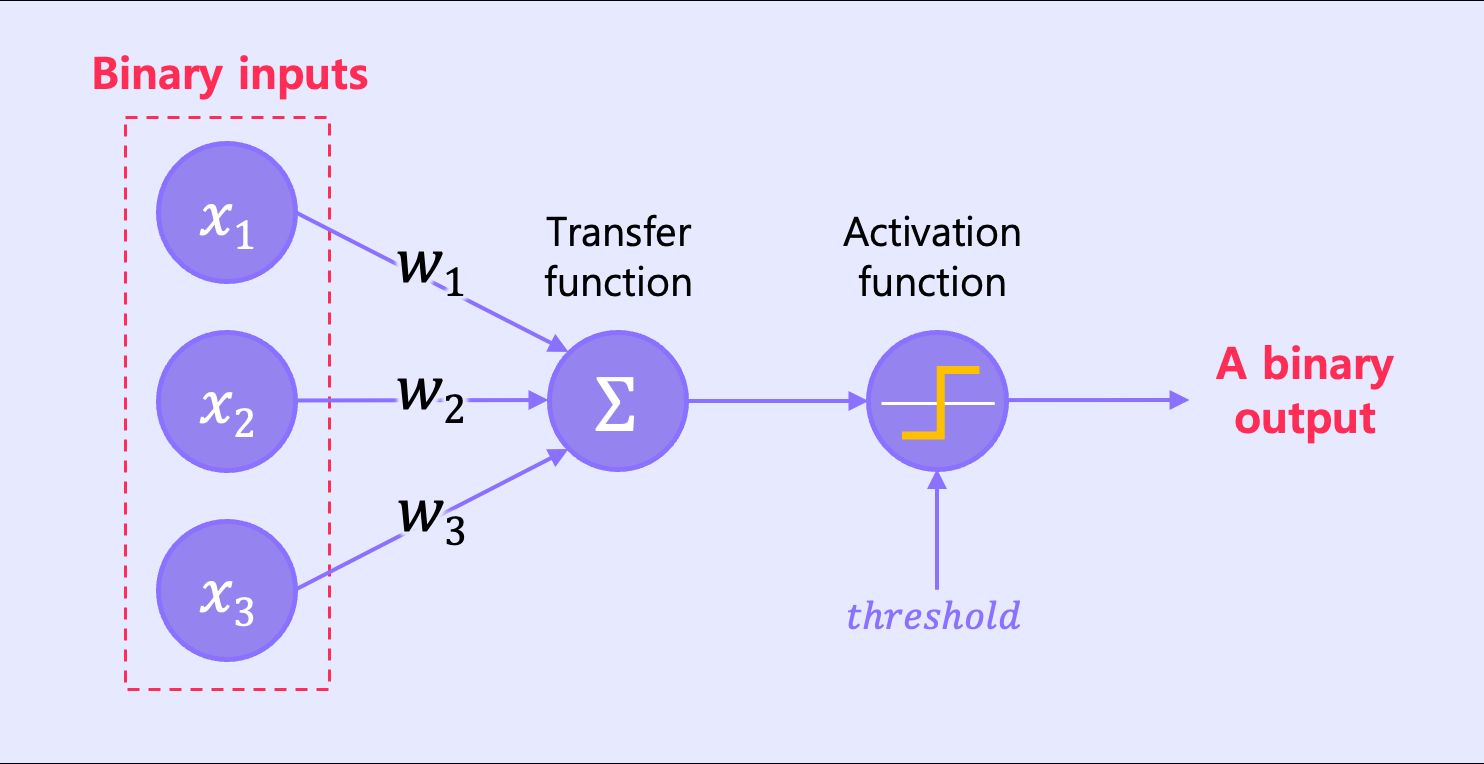
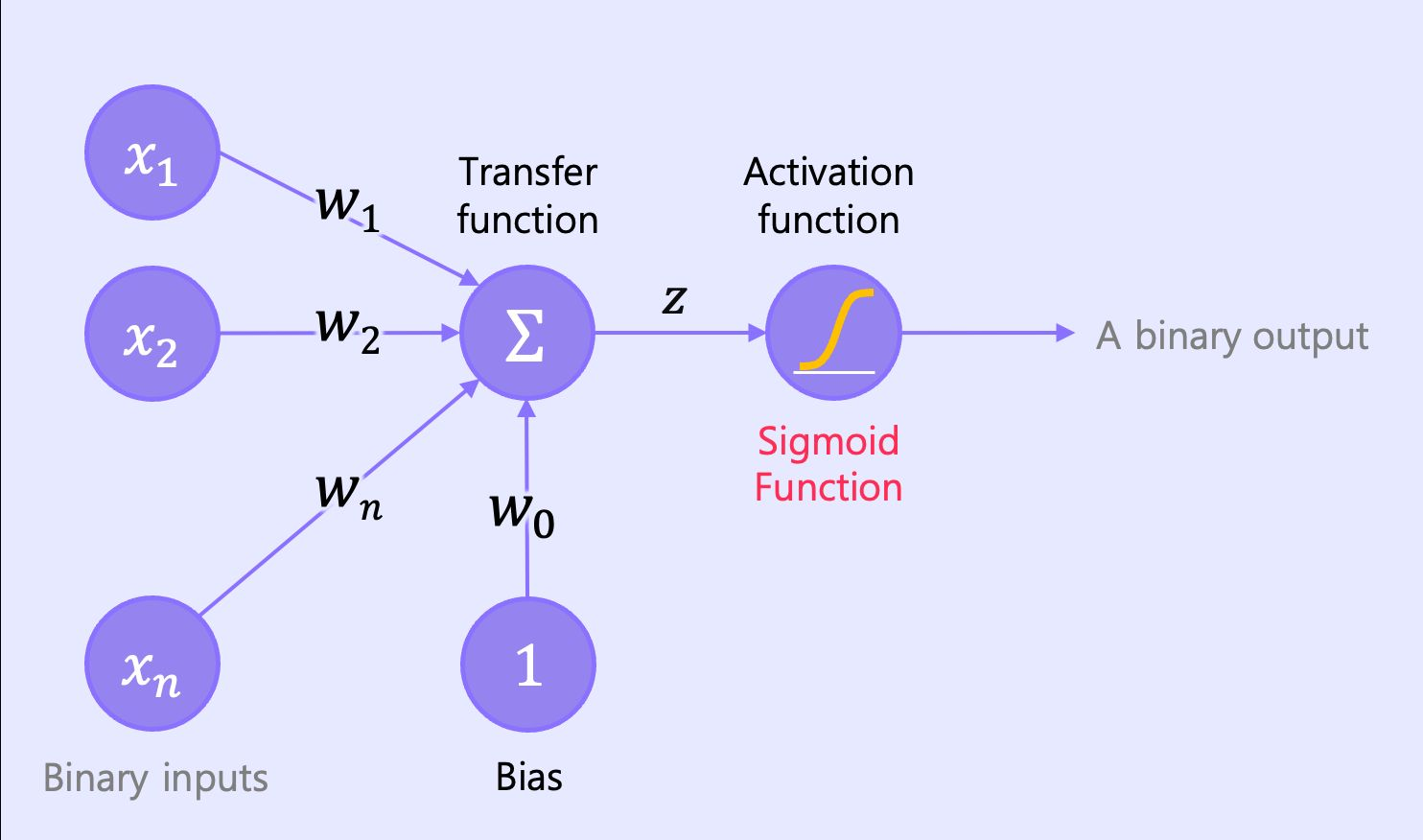
다음 그림은 단일 퍼셉트론의 구조이다.
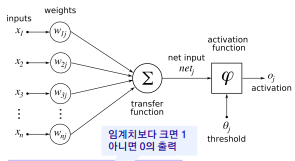
구조를 수식으로 풀어 쓰게 되면 다음과 같은 수식을 가지는 것을 확인할 수 있다. 이렇게 선형 관계를 표현하기도 하며 현재 예시로는 Binary input을 통한 Binary Output을 배출하는 과정을 나타낸다.
여기에서 퍼셉트론이 선택될 확률을 높이기 위해서 편향을 추가하는 경우가 있다. 현재 한개의 퍼셉트론을 보이지만 많은 퍼셉트론을 활용하게 되면 분명 더 중요하게 생각되는 퍼셉트론이 존재할 것이다. 이럴때 활성화가 더 활발하게 될 수 있기 위해 편향에 대한 가중치를 부여해준다.
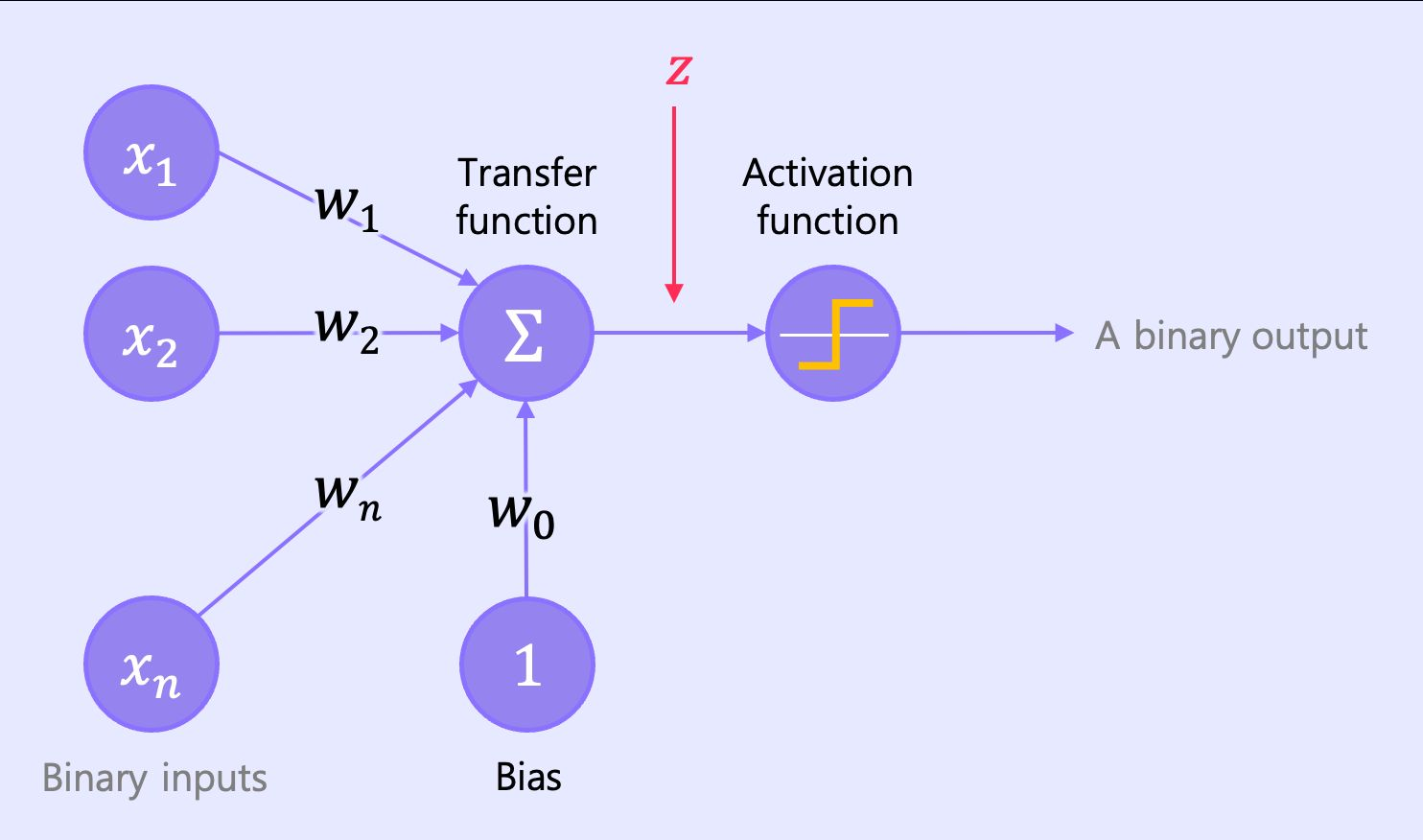
또한 가중치와 편향에 대해 다음과 같이 경우에 따라서 세가지로 표현하기도 한다.
- “w⋅x가 (T-wo) 보다 큰가?”
- “w⋅x가 b보다 큰가?” (b = T-wo)
- “w⋅x+b가 0보다 큰가?” (b = wo-T)
퍼셉트론의 원리
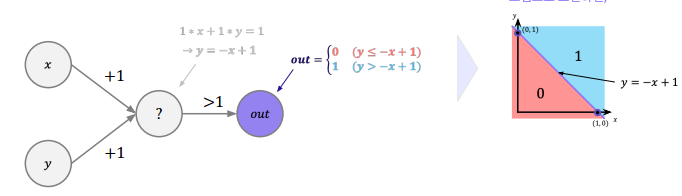
퍼셉트론은 다음과 같이 x, y를 input으로 받는 예시를 통해 기하학적 원리를 파악할 수 있다. 각각 x와 y를 대입하게 되면 가중치에 의해 보여지는 수식을 가지게되고 out은 x와 y간의 범위를 통해 오른쪽의 그림의 영역에 맞게 값을 가질 수 있게된다. 모형은 마치 직선을 통해 영역을 선형 분리한 모습과 같다.
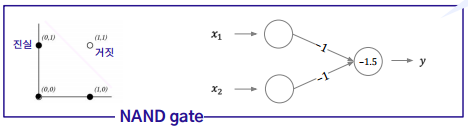
퍼셉트론이 각광 받은 이유는 선형 분리 가능성 덕분에 AND, OR, NAND 등의 로직을 구현할 수 있게 되었다.이중 NAND gate는 “universal for computation”으로 알려져 있고, 이는 어떤 모델이든 NAND gate의 조합으로 표현 가능하다.
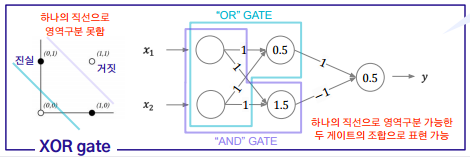
XOR 논리 게이트는 하나의 퍼셉트론으로는 구현이 불가능함을 1969년 Minsky가 “Perceptron”을 통해 증명하였다. 그러나 여러 층의 퍼셉트론을 활용하면 분리가 가능하며, 이를 다층 퍼셉트론의 비선형 분리 가능성이라고 한다. 즉 퍼셉트론들의 조합으로 어떠한 연산이든, 어떠한 입출력 관계든지 표현이 가능하다.
다층 퍼셉트론
퍼셉트론을 사용하지 않더라도 Multiple Layer Networks가 아닌 MLP로 불리기도 한다.
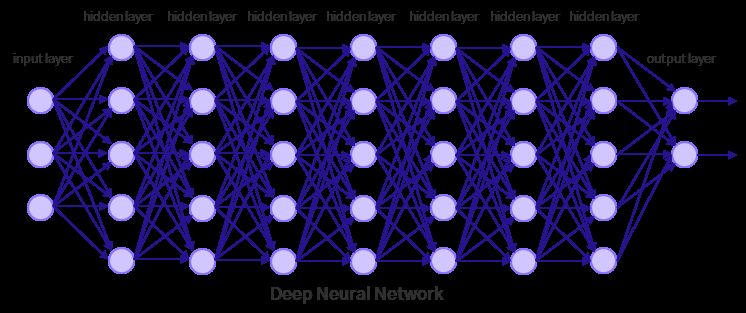
위의 그림처럼 특정한 노드 하나를 뽑았을 때 특정 노드의 이전층과 다음층에 있는 노드에 대해 모두 연결이 되어있는 형태를 말한다. 따라서 모두 연결되어 있기 때문에 Fully-Connected Layers(FCs)의 동의어로 사용된다.
활성화 함수 (Activation Function)
활성화 함수가 없게 되면 단순한 선형 모형을 활용하는 것처럼 층에 대한 의미가 존재하지 않는다. 또한 비선형으로 구분하는 것이 선형으로 구분하는 것 보다 성능이 좋을때가 많기 때문에 사용하게 된다. 아래의 그림에서 설명하는 것 처럼 활성화 함수를 활용하는 이유에 대해 확인할 수 있을 것이다.

활성화 함수의 대표적인 종류로는 다음과 같다.
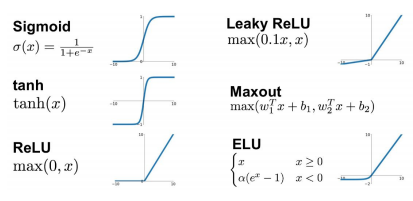
이중 대표적인 시그모이드 함수에 대해 파헤쳐 보면 연산 과정 전체를 미분을 가능하게 하는 함수이기 때문에 자주 활용된다 한다. 이는 추후의 역전파 알고리즘과도 관련이 되어있는 사항이며 미분에 대한 연산을 줄이고 다른 방법을 통해 총 연산 시간을 줄인 것으로 알려져있다.
구조
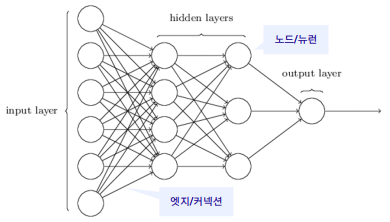
위의 그림처럼 레이어 수가 4인 MLP의 구조는 층, 노드, 엣지로 이루어져있다. 각각 데이터, 함수 + 활성화함수, 가중치를 뜻한다.
경사하강법
배경
미분
변수의 움직임에 따른 함수값의 변화를 측정하는 도구로 최적화에서 제일 많이 사용하는 기법이다. 극한을 통해 정의되며, 직접 구하기 위해서는 ℎ→0 극한을 계산해야 한다.
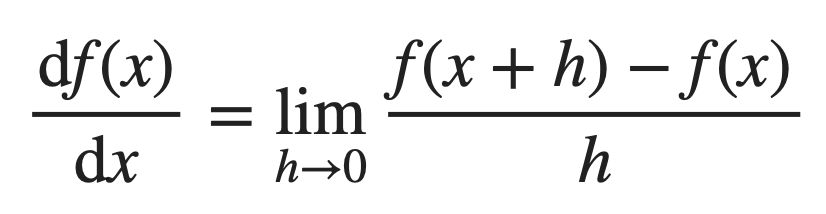
기울기
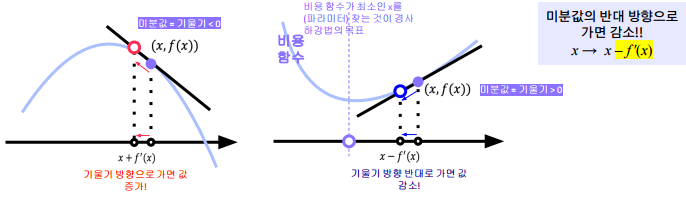
x에서의 미분값은 함수 f 의 주어진 점 (x, f(x)) 에서의 접선의 기울기와 동일하다. 어떤 점에서의 함수의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가 or 감소하는지 알 수 있다.
편미분
벡터를 입력값으로 받는 다변수 함수의 경우, 각 변수에 대해 미분한 편미분을 사용한다. 각 변수에 대한 편미분을 나타낸 그래디언트(gradient) 벡터를 이용하면 마찬가지로 다변수 함수의 기울기를 알 수 있다.
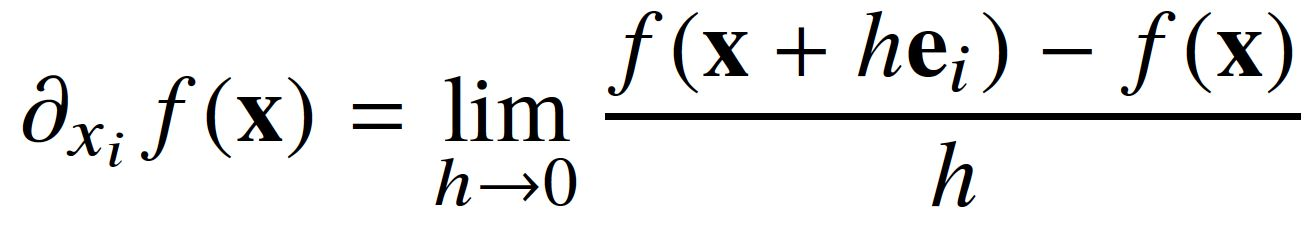
경사하강법
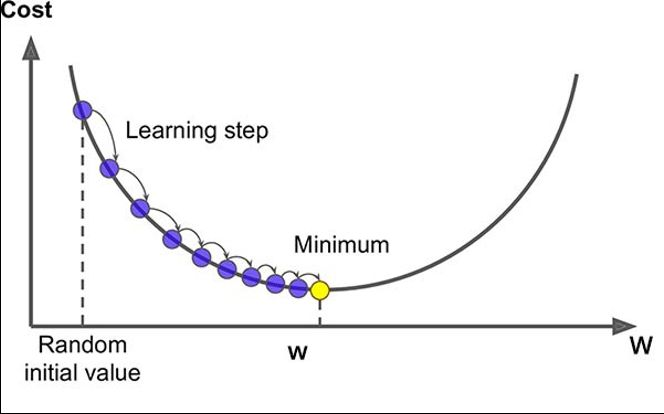
기울기(f'(x))가 감소하는 방향으로 를 움직여서 의 최소값을 찾는 알고리즘
딥러닝에선 손실 함수의 그래디언트(∇L_θ)가 감소하는 방향으로 파라미터 를 움직여
손실 함수의 최소값을 찾는다.
학습 과정은 다음과 같다.
-
- 모델 파라미터 θ ={W,b} 초기화
-
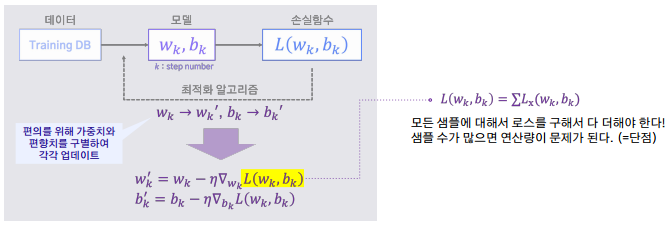
- 전체 학습데이터셋에서의 손실 함수 값을 구하고 미분을 통해 이를 최소화하는 모델 파라미터 W,b를 찾는다.
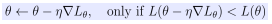
- 전체 학습데이터셋에서의 손실 함수 값을 구하고 미분을 통해 이를 최소화하는 모델 파라미터 W,b를 찾는다.
-
- 2를 반복하다가 종료 조건이 충족되면 학습 끝!
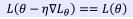
- 2를 반복하다가 종료 조건이 충족되면 학습 끝!
그러나 이런 경사하강법에도 한계가 존재한다. 다음 그림에서 명확하게 볼 수 있다.
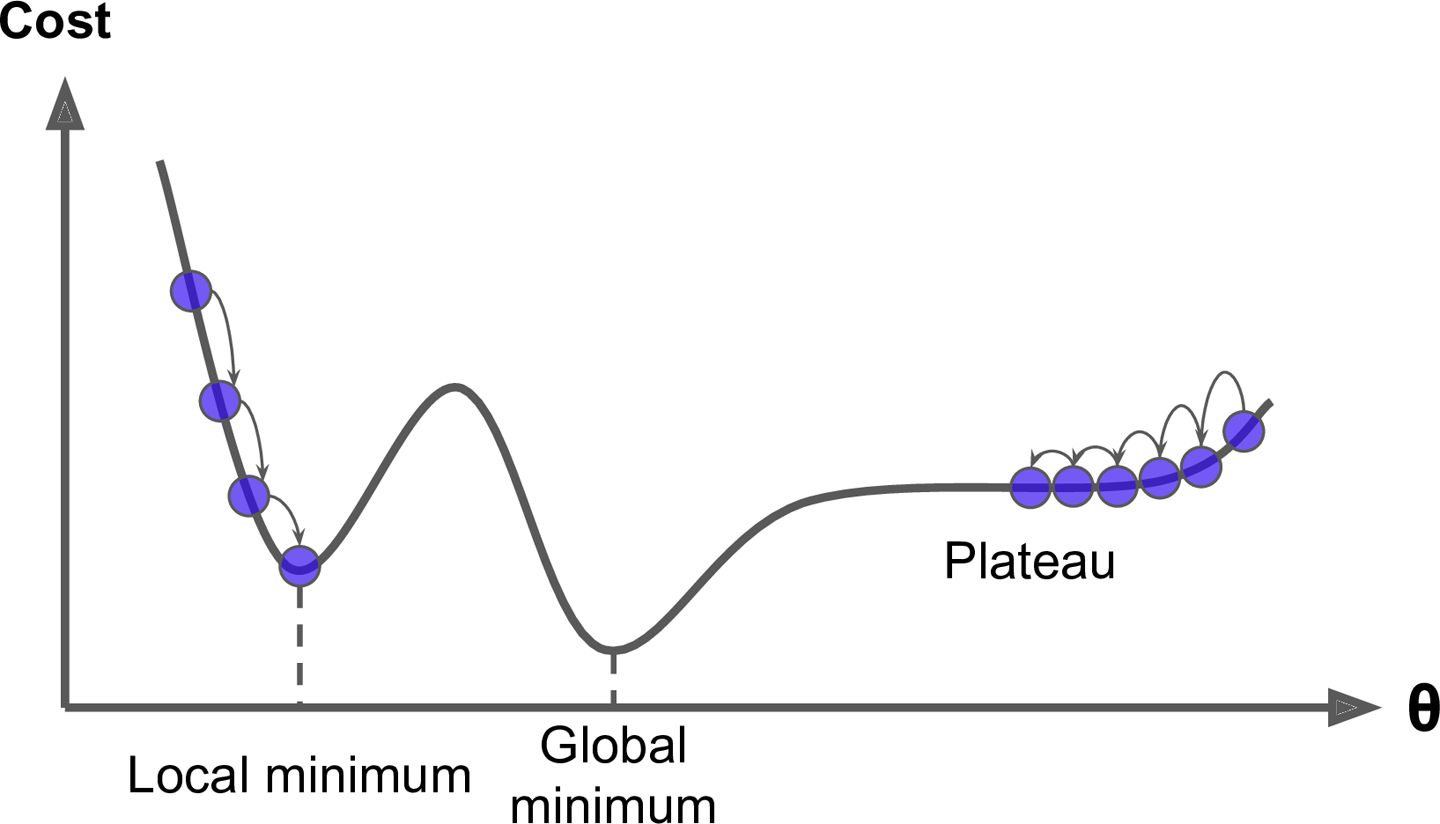
두 경우 모두 최적의 파라미터를 찾다가 원하는 곳에서 멈추지 못하고 다른 곳에서 멈춰있는 경우를 발견할 수 있을 것이다. 이에 대한 해결책으로 다음과 같이 세가지 방법을 활용할 수 있다.
- ① 파라미터 초기화를 굉장히 잘한다. (여러 초기화 기법, pretraining)
- ② 모델 구조를 바꿔서 그래프 모양을 바꾼다.
- ③ Learning Step을 바꾼다.
현실적으로 ①, ②번은 쉽지 않은 방법이다. 실제로 내가 제대로 된 모형을 알고 있으면 가능하지만 알지 못하는 경우에는 어느것이 맞는지도 모를 수 있기 때문이다.
따라서 ③번 방법을 활용하는 것을 목표로 한다.
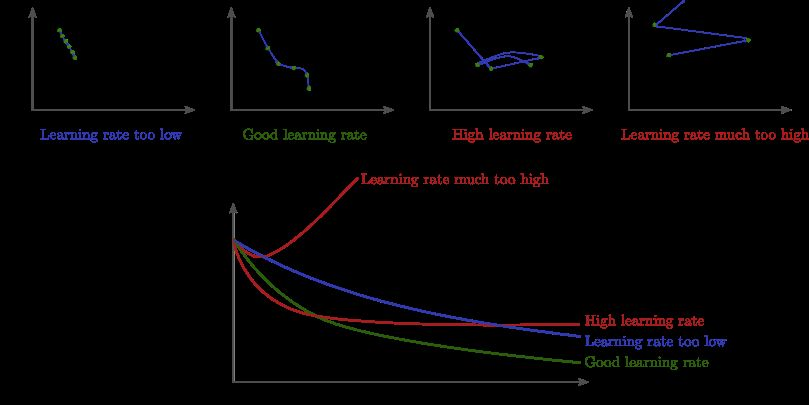
각 그림은 Learning Rate를 조절한 그래프이다. 너무 적게 움직이거나 너무 많이 움직여도 극소점을 찾아가지 못한다. 따라서 파라미터를 조절하듯 적절한 Learning Rate를 찾아야 한다.
또한 경사하강법은 모든 경우에 대해 연산을 모두 적용해야 하는 탓에 시간과 비용 면에서 오래 걸린다는 단점이 있다. 샘플수가 점점 늘어날 수록 연산량이 기하급수적으로 늘어나기 때문이다.
확률적 경사 하강법
모든 데이터를 사용해서 구한 경사를 통해 파라미터를 한 번 업데이트 하는 대신, 데이터 한 개 또는 일부를 활용하여 구한 경사로 여러 번 업데이트를 진행하는 경사 하강법을 보강하기 위해 만들어진 방법이다. 이 방법은 다음과 같은 특징을 가지고있다.
- SGD를 통해 한 번의 학습을 하는 데에 사용되는 데이터 샘플의 집합을 ‘미니 배치(mini-batch)’ 혹은 간단히 ‘배치(batch)’라고 부른다.
- 손실 함수의 크기를 1/m로 스케일하는 과정은 학습 데이터의 크기가 실시간으로 바뀌는 환경에서 특히나 잘 작동한다.
- m=1인 환경을 ‘온라인 학습(online/incremental learning)’이라고 부른다.
이 방법은 볼록하지 않은 목적식을 가진 경우, SGD가 GD보다 실증적으로 더 낫다고 검증되었다. SGD는 학습에 활용하는 데이터 샘플이 매번 달라짐에 따라 손실 함수의 형태가 약간씩 바뀐다고 볼 수 있으며, 이를 통해 local minima에 빠지는 것을 방지하여 최적해에 도달할 가능성을 높이는 방법으로 이해할 수 있다.
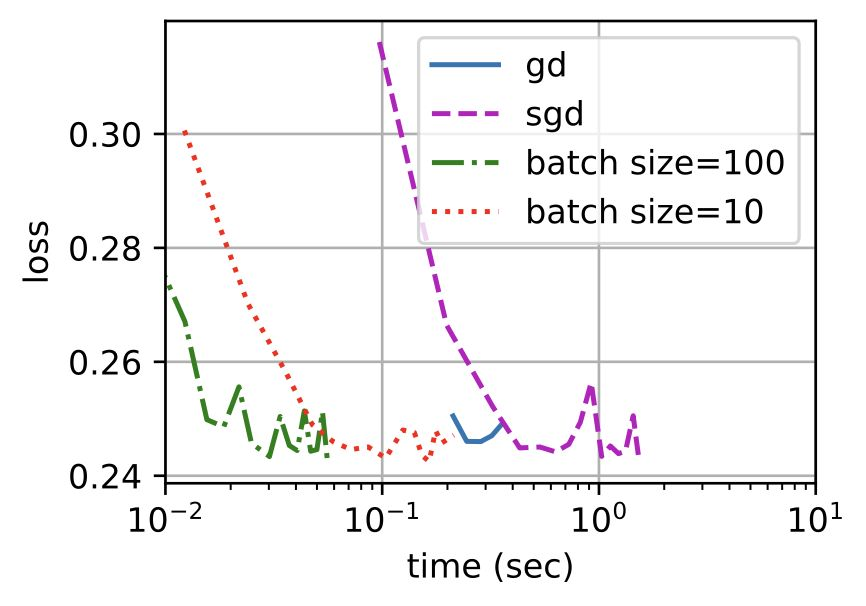
또한 데이터의 일부를 가지고 그래디언트 벡터를 계산하고 파라미터를 업데이트하므로 컴퓨터의 메모리 및 연산 자원을 좀 더 효율적으로 활용할 수 있다.
❓고찰
아직까지는 익숙한 내용을 많이 보기 때문에 받아들이기 어려운 내용은 없었다. 앞으로 딥러닝에서 모델이 고도화 될 때 지금 챕터처럼 쉽게 이해하고 사용할 수 있었으면 좋겠다.
딥러닝 개요 부분은 이번 내용보다 더 기초적인 내용으로 이미 알고 있는 내용이 대다수 였으며 더이상의 개념을 공유하는 것은 의미 없다 판단하여 이번 내용을 시작으로 작성하였다.
