학습 방식에 의한 구분

AI는 다음 그림과 같이 영역별로 종류가 나뉘게 된다. 처음으로 학습 방식에 의한 구분을 알아보고자 한다.
구분의 기준
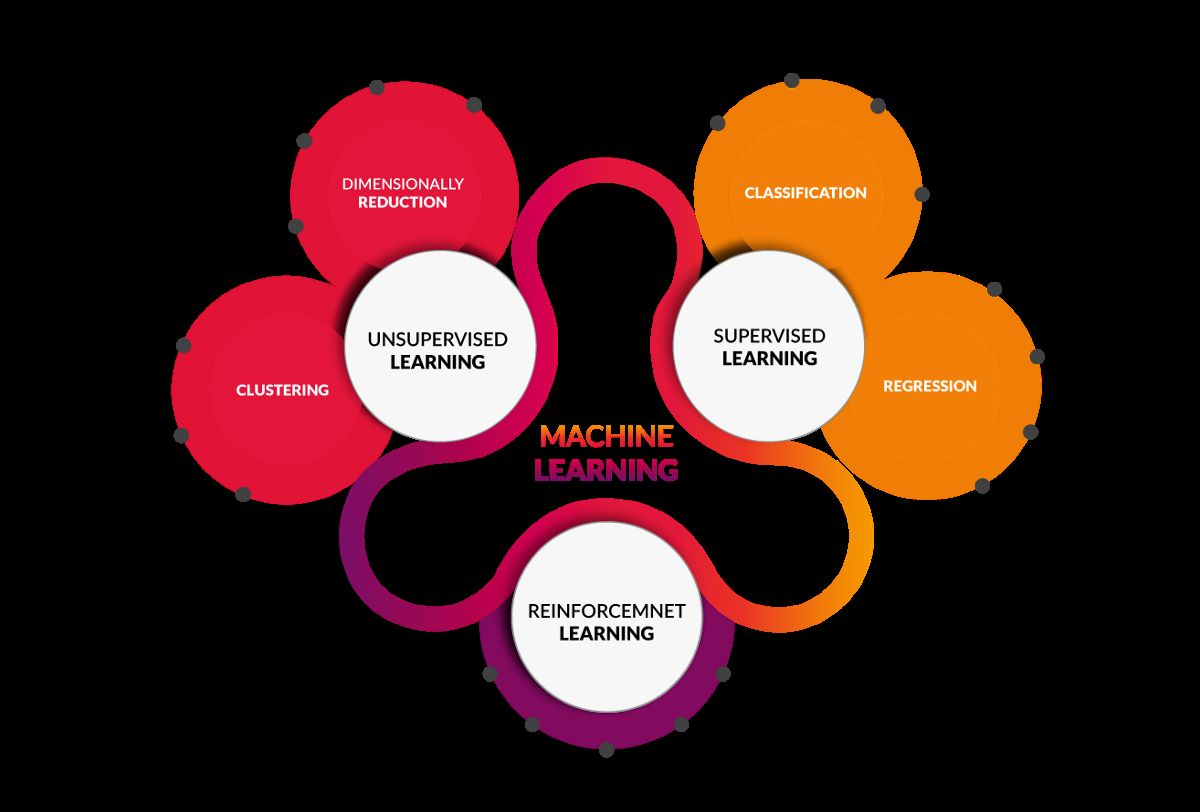
그림에서 보이는 것 처럼 총 세가지 형태로 구분 할 수 있다. 각각 데이터의 형태와 원하는 것을 얻기위한 목적에 따라서 구분지어진다. 기본적으로 다음과 같은 정보로 구분된다.
지도 학습
- 라벨링이 존재하는 데이터
- 직접 피드백이 가능한 학습 방법
비지도 학습
- 라벨링이 존재하지 않은 데이터
- 피드백이 존재하지 않은 학습 방법
- 숨은 구조를 찾는 학습 방법
강화 학습
- 라벨링이 존재하지 않은 데이터
- 피드백의 속도가 느림
- 결과에 따른 보상이 동반되는 학습 방법
지도학습
특정 입력에 대한 정답을 알려주는 방식으로 학습하는 지도학습 방법은 다음과 같은 방법으로 나뉘어진다.
- 분류: 기정의된 클래스들 중 입력이 어느 클래스에 해당하는지 맞추는 태스크
- 회귀: 입력 데이터에 대한 실수 혹은 실수의 집합을 (벡터) 출력으로 맵핑해주는 (Mapping) 태스크
또한 동시에 진행하는 경우도 존재한다. 예를들어 다음과 같이 이미지 내의 음식들 종류와 위치를 동시에 찾아야 하는 경우를 말하는데 이를 Objective Detection이라 부른다.

음식의 종류를 맞출 때 분류를 적용하며 해당 음식이 위치하는 박스의 좌표를 추정할 때 회귀를 활용한다.
이러한 지도학습을 활용할 때 데이터의 품질에 따라 모델의 성능이 좌지우지된다고 한다. 즉 라벨링 노이즈가 작을 수록 모델의 성능이 좋아진다.
라벨링 노이즈
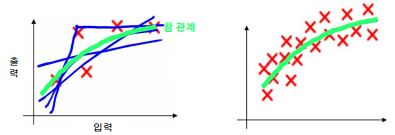
다음 그림을 확인했을 때 양쪽 그림 모두 노이즈가 존재하는 데이터가 과반수 이상이 존재한다. 그러나 왼쪽 그래프가 오른쪽 그래프에 비해 관측되는 데이터가 훨씬 적다. 따라서 참 관계의 선을 이탈할 가능성이 매우 높다. 또한 적은 데이터로 추정하게 되면 일반화 시키기에 매우 어려운 결과를 가져올 수 있다. 반면 오른쪽 그래프는 많은 데이터를 활용하여 참 관계의 선을 따라가고 있는 것을 확인할 수 있는데 이로써 데이터가 많을수록 나타나는 직선의 참 관계에 더 가까운 선을 찾을 수 있다.
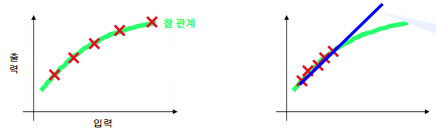
또한 데이터가 적어도 clean한 경우 적합이 잘 되는 경우도 있는데 다음 두 그래프와 같은 경우이다. 그러나 두 그래프의 차이는 왼쪽 그래프와 같은 경우 참 관계의 선에서 고루 퍼져있는 모형인 반면 오른쪽 그림은 왼쪽 아래의 참 관계에 치우쳐진 경우이다. 참 관계를 예측하지 못하고 파란색 직선처럼 점점 이탈하게 되는 결과를 초래할 수 있다. 따라서 데이터가 고루 퍼져있으면서 정확한 위치에 있는 경우가 좋은 모델을 확보하기 쉽다. 이를 Robust라고 하기도 한다.
비지도 학습
특정 입력에 대한 정답을 알지 않고 학습시키는 방식으로 비지도학습의 대표적인 예로 다음과 같은 방법이 있다.
- 클러스터링: 데이터를 비슷한 특징끼리 군집화
- 차원축소: N차원 입력을 N>n차원 출력으로 변경하는 태스크
클러스터링
클러스터링은 다음과 같이 작동한다.
- 임의의 k개의 점을 지정하고 클래스를 부여한다.
- 나머지 점들을 가장 가까운 클래스로 포함하여 중심점의 클래스를 부여
- 클래스별 중심점 재 계산후 각 점들의 변화가 없을 때 까지 적용
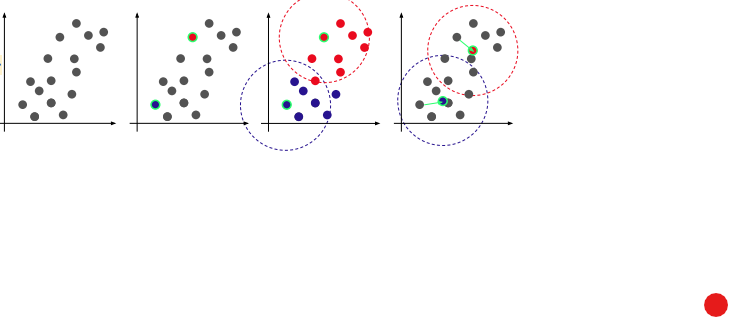
다음과 같은 클러스터링 방법에서 중심점의 클래스를 평균으로 부여할 때 k-means 클러스터링 방법이라 한다.
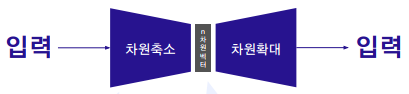
차원 축소
차원 축소는 세 가지 이유를 통해 각각 진행한다.
- 정보 압축 (자원 절약): 이미지/비디오/오디오 압축
- 정보 시각화: 사람이 눈으로 확인할 수 있는 것은 3차원 까지
- 정보 특징: 중요한 특징을 추출하여 분석에 사용
또한 노이즈가 포함된 이미지를 차원 축소 방법으로 축소 시킨다음 주요 정보만을 캐치하여 차원 확대를 통해 노이즈가 지워진 이미지 사진을 가져오게 하는 방법또한 포함된다. 이 기능을 하는 모델을 오토인코더(Auto-Encoder)이라 부른다.
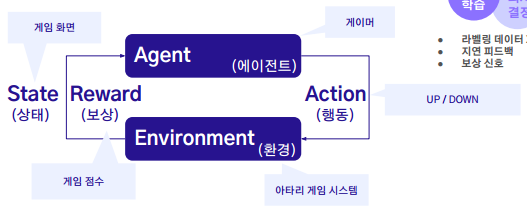
강화학습
주어진 환경에서 더 높은 보상을 위해 최적의 행동을 취하는 정책을 학습하는 모형으로 에이전트 (Agent), 보상 (Reward), 행동 (Action), 환경 (Environment)의 네가지 요소로 구성되어 있다.

또한 다음은 각 구성요소의 예시를 적용한 것이다.
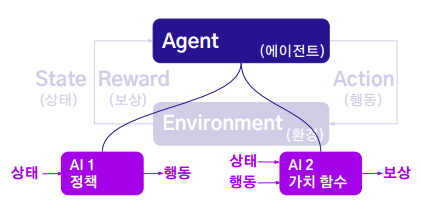
이중 Agent요소는 두가지 종류가 존재한다. 하나는 상태를 받아들여 어떠한 행동을 하는지에 대한 에이전트이며 나머지 하나는 상태, 행동 두가지를 받아들여 가치를 매기고 보상을 반환하는 에이전트이다.
데이터 형식에 의한 구분
다음으로 데이터 형식에 의한 구분이다. 데이터는 크게 정형데이터와 비정형데이터로 나눌 수 있다.
정형 데이터
구조화된 정보로 저장되어 있는 데이터를 말하며 흔히 csv파일로 이루어진 데이터를 가리킨다. 이는 지도학습을 주로 수행하며 데이터 정형화를 통해 처리를 진행하기도 한다.
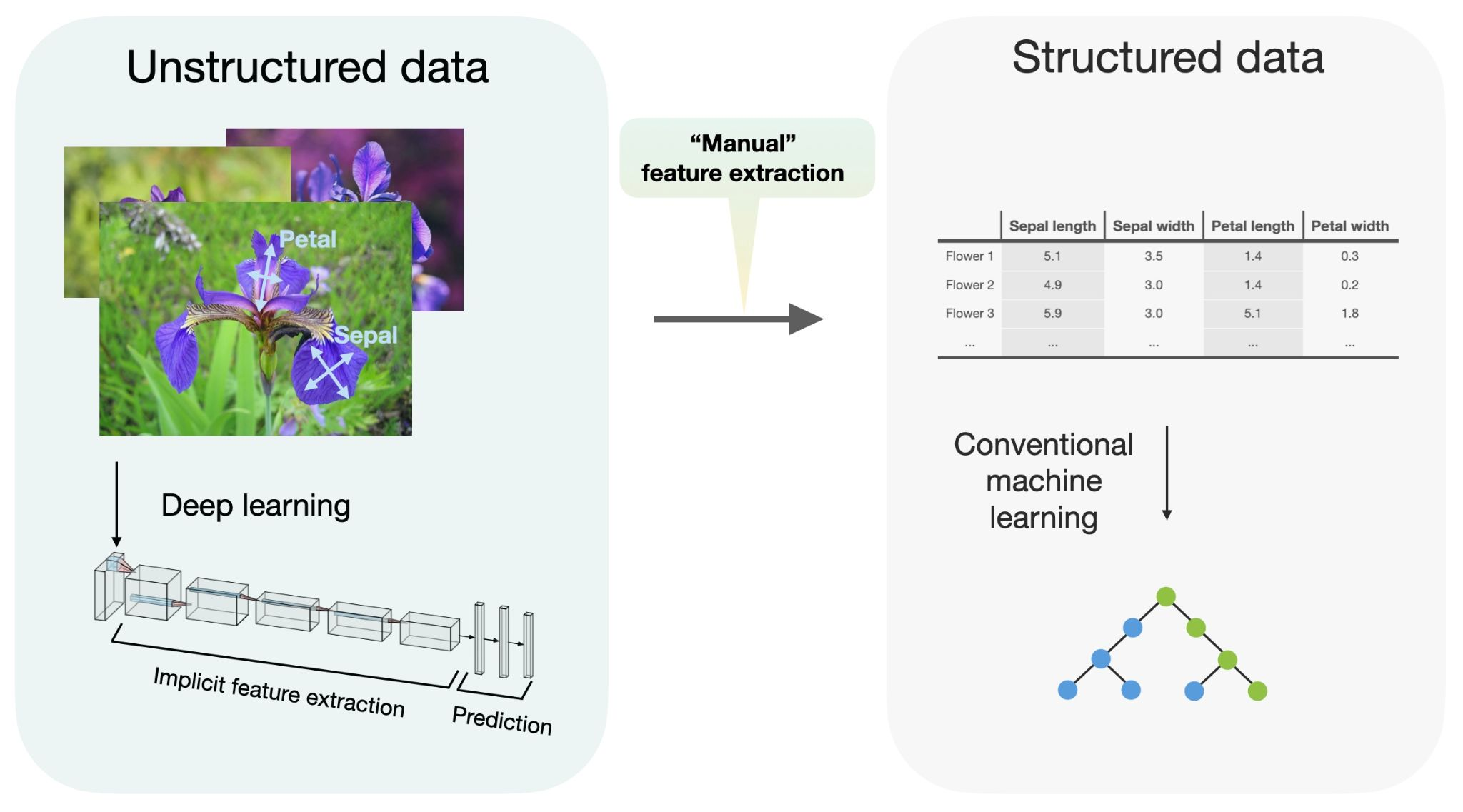
비정형 데이터
비정형 데이터에는 이미지/동영상, 텍스트, 음성으로 나누어 확인할 수 있다.
CV
입력으로 이미지나 동영상 데이터를 받는 AI를 말하며 ChatGPT 이전에는 가장 많이 상품화된 AI 기술이었으며, 딥러닝 기술을 선도하였다. CV를 활용해서 적용할 수 있는 task는 다음과 같다.

NLP
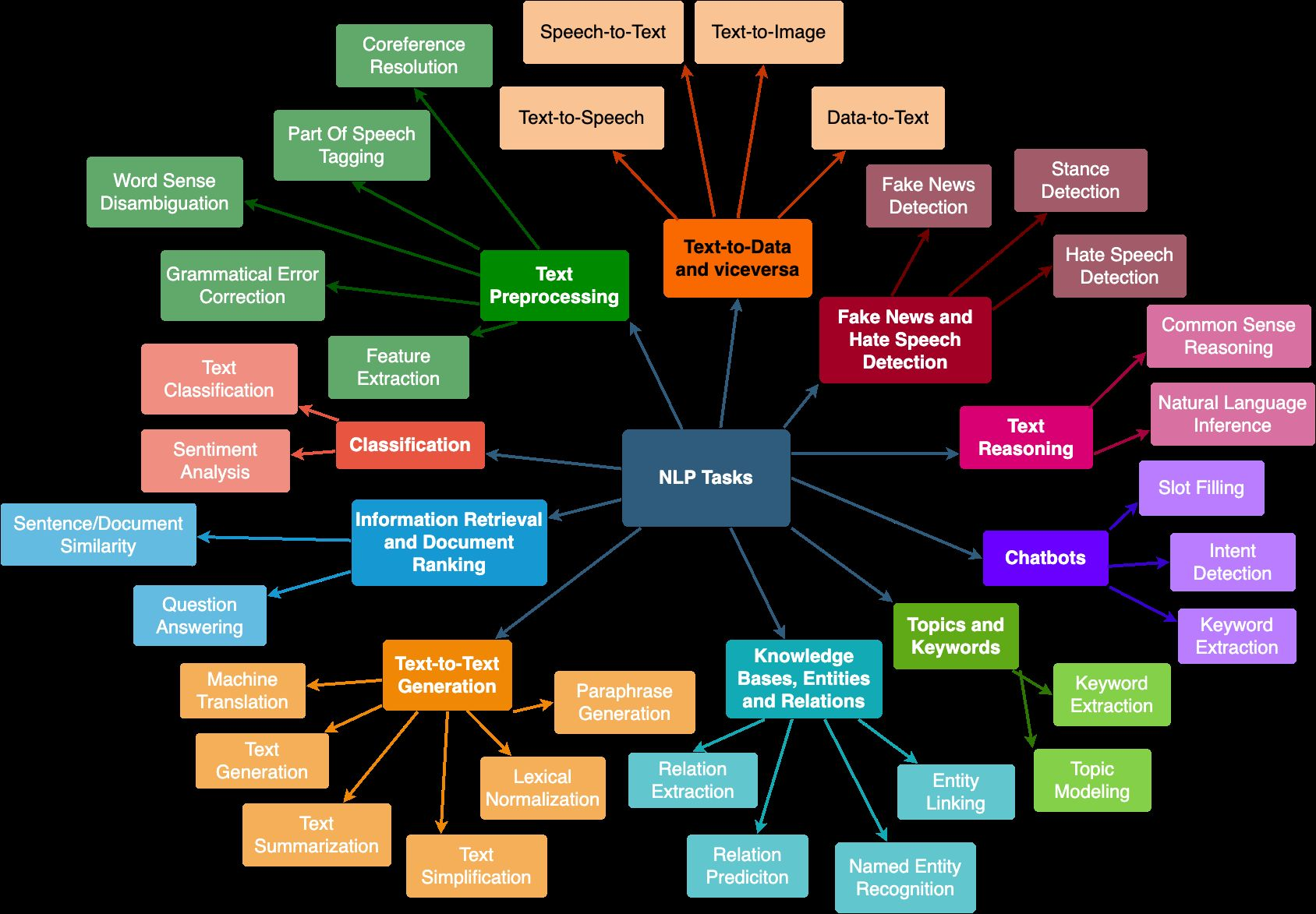
입력으로 텍스트 데이터를 받는 AI이며 ChatGPT 이후 자연어 처리 관련 서비스/제품 들이 기하급수적으로 증가하고 있는 추세이다. 현재, 딥러닝 기술을 선도하고 있다. NLP를 활용하여 적용 할 수 있는 task는 다음과 같다.

또한 대형 모델인 LLM모델도 NLP의 한 종류이다.
음성
입/출력으로 음성 데이터가 활용되는 AI이며 음성 인식은 출력이 텍스트 이므로 자연어 처리와 함께 사용되는 경우가 많다. 음성을 활용해서 적용할 수 있는 task는 다음과 같다.

또한 텍스트로 시작해서 음성으로 출력을 하는 경우가 있다.

따라서 한 종류의 데이터라도 다른 영역과 혼합되어 적용되는 경우도 존재한다.
태스크 종류에 의한 구분
비정형 데이터와 정보의 입출력 관계에 따라 인식 혹은 생성으로 구분된다. 특징은 다음과 같다.
- 인식: 비정형 데이터 입력에 정보가 출력
- 생성: 출력이 비정형 데이터이며 의도된 정보를 입력으로 넣어줄 수도 있고, 비정형 데이터를 입력으로 주면서 간접적으로 의도를 줄 수도 있다.

그렇다면 인식과 생성중 어느게 더 어려운지에 대해 궁금할 수 있다. 결과부터 이야기하면 생성이 인식보다 더 어렵게 느껴지고 있다고 한다.
생성 모델의 역사
2014년에 만들어진 GAN(Generative Adversarial Network)에 의해 이미지 생성이 가능하게 되었다.
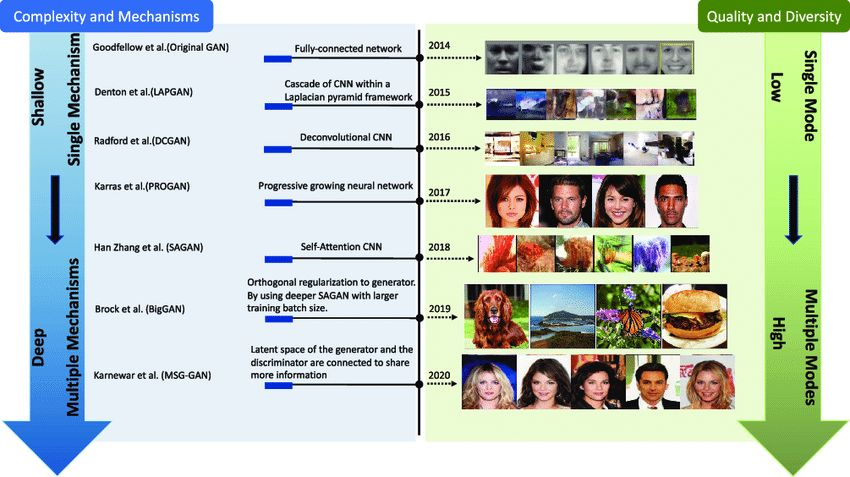
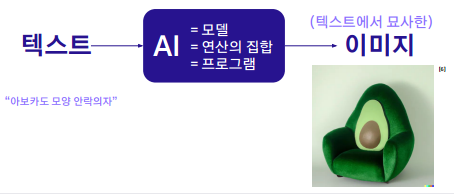
이 영역에서 OpenAI에서 2021년도에 공개한 DALL-E가 대표적모델로 통제력 달성은 결국 입력을 텍스트로 받아서 해결하는 모델이 만들어졌다.
또한 2023년도에 StabilityAI의 Stable Diffusion이 상업적으로도 이용가능하면서 오픈소스여서 관련 산업이 급격히 성장하였고 동년도에 OpenAI에서 내놓은 ChatGPT가 모든 것을 다 변화시켰다고 한다.
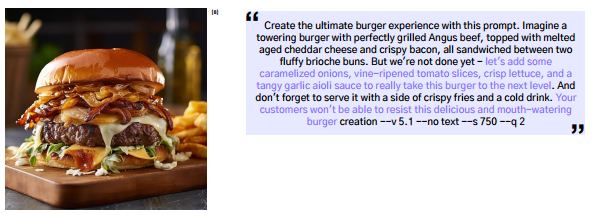
구체적인 정보를 줄 수록 퀄리티 높은 이미지를 가져올 수 있다.
❓고찰
실질적으로 아는 내용도 많았고 어느정도 받아들이기 쉬운 정보도 많이 있었다. 기존에 배웠던 내용을 기반으로 어떤 모델이 어느 파트에 적용되고 있는지 감을 잡을 수 있었으며 앞으로 어떠한 내용을 상세하게 배우게 될지 기대가 되기도 한다.
아마 워밍업으로 듣는 부분이라는 생각이 많이 들지만 이렇게 큰 틀을 확보하고 그 안의 내용을 구체적으로 들어가는 수업이 많지 않을것이다. 이 기회를 놓치지 말고 잘 정리하여 CV부터 RS까지 모든 내용을 구체적으로 알진 못하더라도 보고 insight라도 가져갈 수 있는 수준까지 적합할 수 있으면 매우 좋을것 같다.
