📂 Prolog
머신러닝 과정을 마치고 시작하게 된 딥러닝 강의 무려 업스테이지에서 출간한 강의를 듣게 되었다. 내용은 두 챕터로 나뉘어져 있었고 첫번째 파트인 Deeplearning과 두번째 파트인 Pytorch에 대해 2주간의 커리큘럼을 통해 기본적인 내용을 미리 알고 세부적인 내용은 경진대회나 팀별 프로젝트를 통해 내용을 받아들이는 커리큘럼을 진행하고 있다.
딥러닝 기초를 배우게 된 강의는 다음과 같다. Upstage의 현직자분들께서 직접 강의를 올려주셨고 운영측 모두가 내용이 완벽하다고 입모아서 언급하고 있다. 실시간 강의를 접하고 싶었지만 그렇지 못해 매우 아쉬웠다.
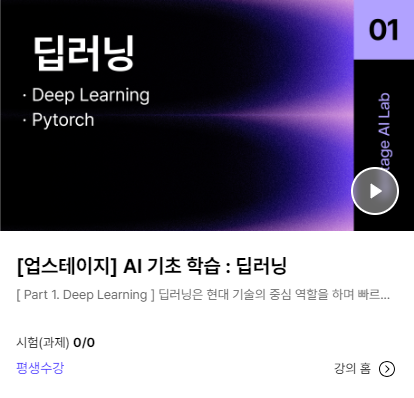
딥러닝 발전 5단계
딥러닝의 전체적인 발전 과정을 총 5단계로 나누게 되는 과정에 대한 내용이다. 아래의 그림처럼 다섯 단계로 분류가 되며 단계별로 딥러닝이 진화되어 왔다.
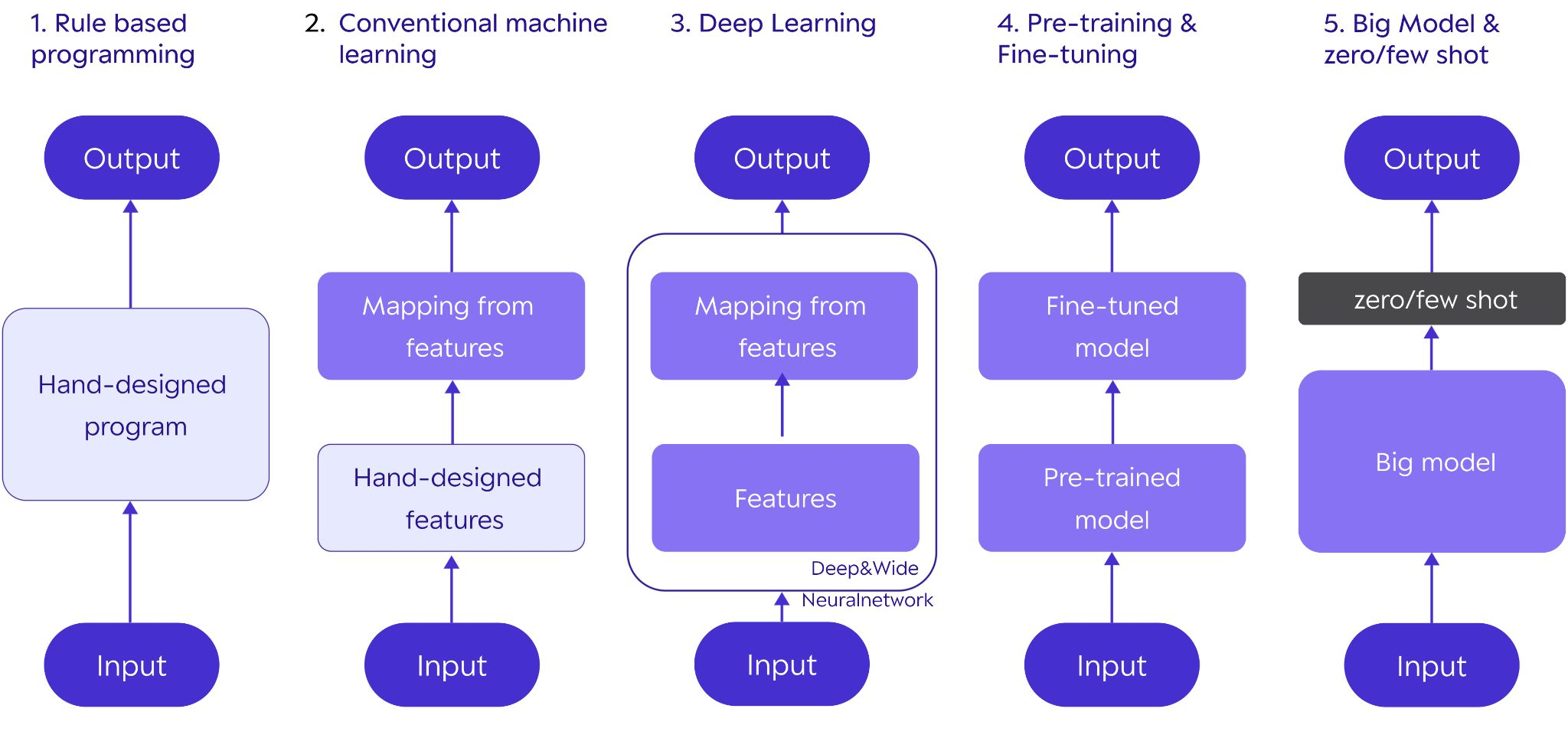
1단계: Rule Based Programming
규칙 기반 프로그래밍이라고 하며 다음과 같이 사람이 직접 고안하면서 분류 알고리즘을 만든다. 다음과 같은 방식을 SW1.0방식이라고도 부른다. 아래의 이미지는 이미지 데이터를 직접 분류하는 알고리즘을 만드는 예시이다.
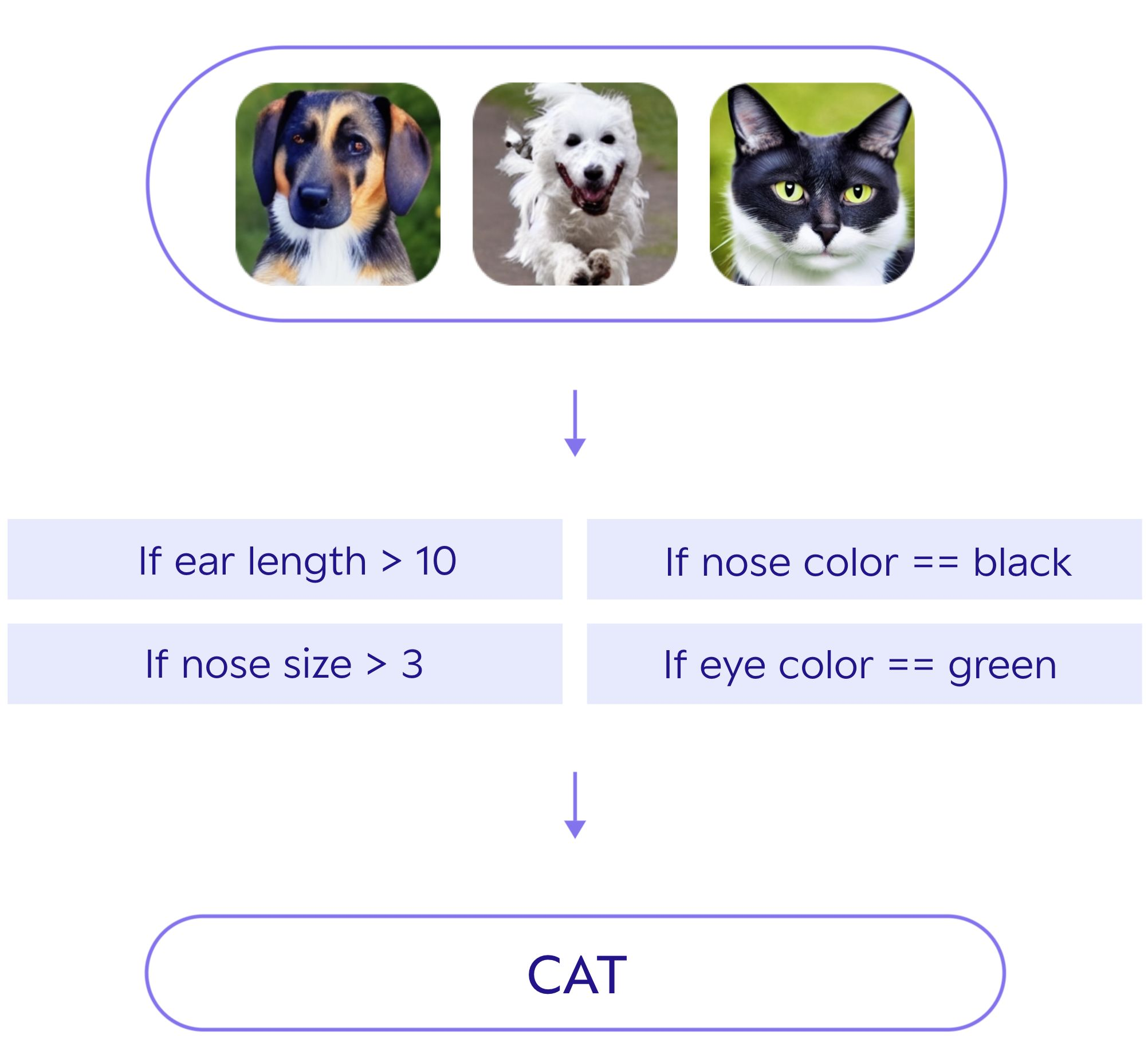
2단계: Conventional Machine Learning
이번 단계에서도 특징값을 뽑는 방식은 사람이 직접 고안한다. 하지만 특징값을 활용해 이미지를 판별하는 알고리즘은 기계가 스스로 고안하는 방식을 2단계 SW방식이라 한다. 아래의 이미지는 이번 단계의 예시를 나타낸다. SW1.0과 추후 나올 내용의 SW2.0방식의 하이브리드 형태를 가지므로 SW1.5단계라고도 한다.
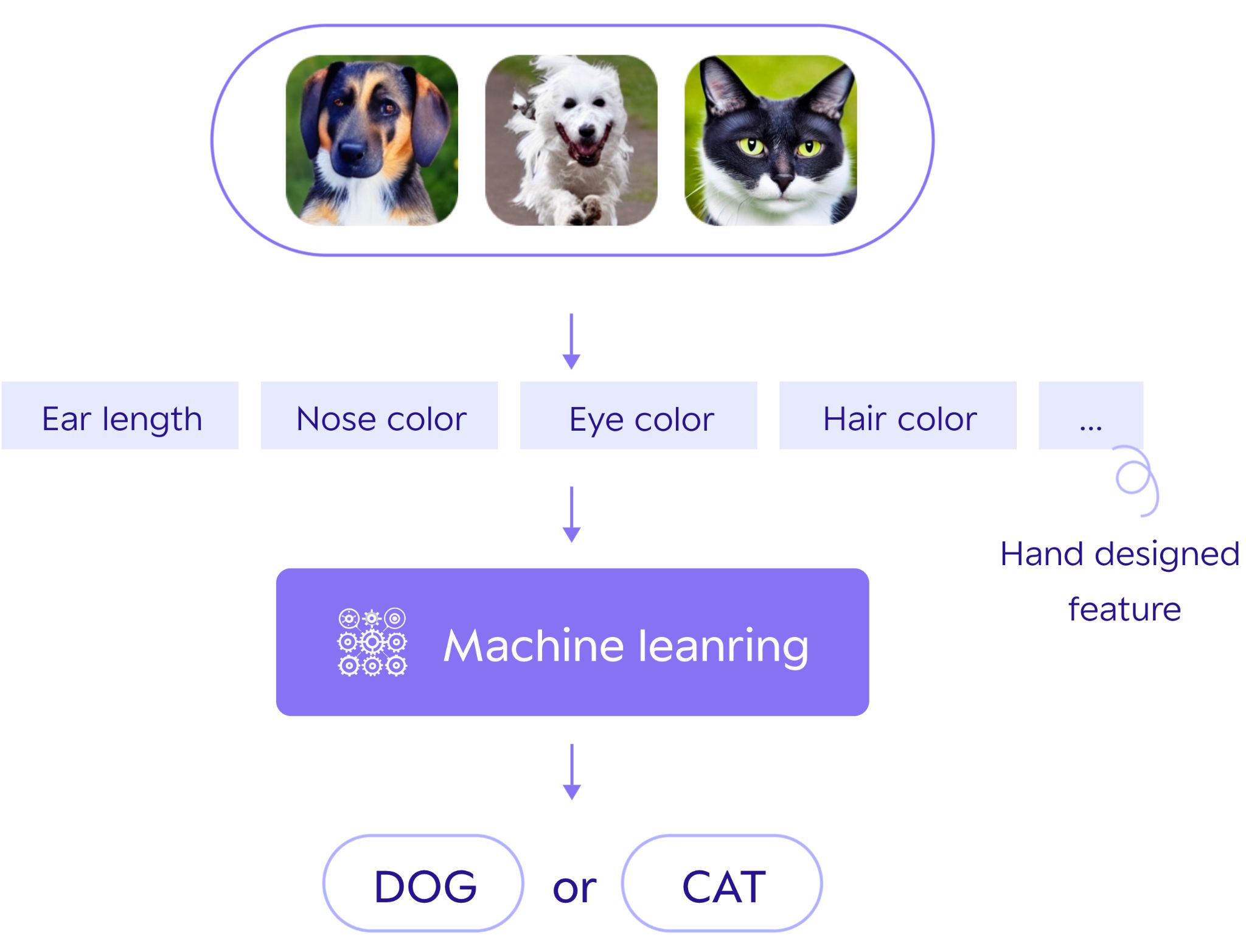
여기서 머신러닝 동작법에 대해 확인할 수 있는데 과정은 다음과 같다.
- 학습 데이터 준비
1-1. 이미지 수집
1-2. 특징 정의
1-3. 학습 데이터 생성- 모델 학습

Try & Error 방식
머신러닝 방법에서 작동하는 최적의 연산 집합을 찾아내는 과정을 나타내는 방식이다. 이는 Try과정과 Error계산 과정을 진행하게 되며 가장 성능이 좋은 결과를 도출하여 추후 테스트 데이터 또는 실제 데이터가 들어왔을 때 Best Model을 활용하여 예측을 진행하게끔 한다.
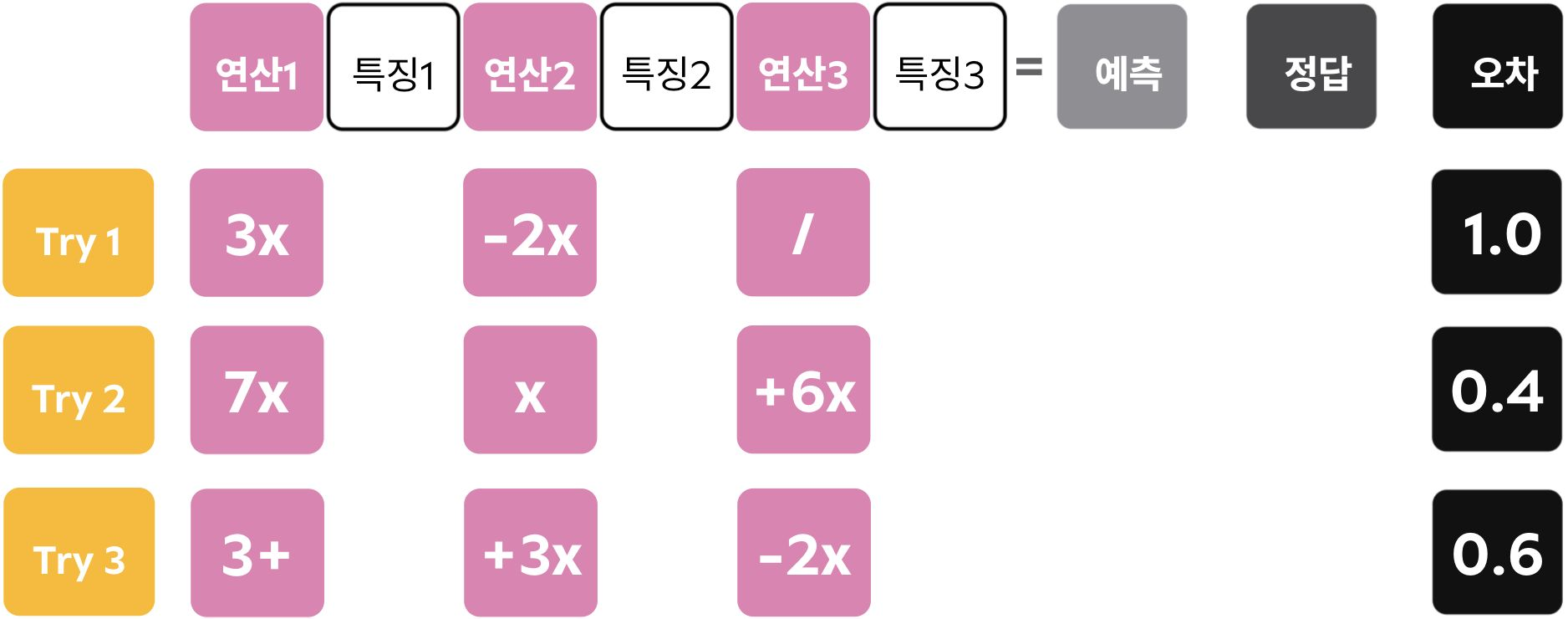
각각의 연산 방법으로 다음과 같이 값을 예측해낸다. 연산 방법은 무작위로 나타나며 다양한 방법으로 진행된다.
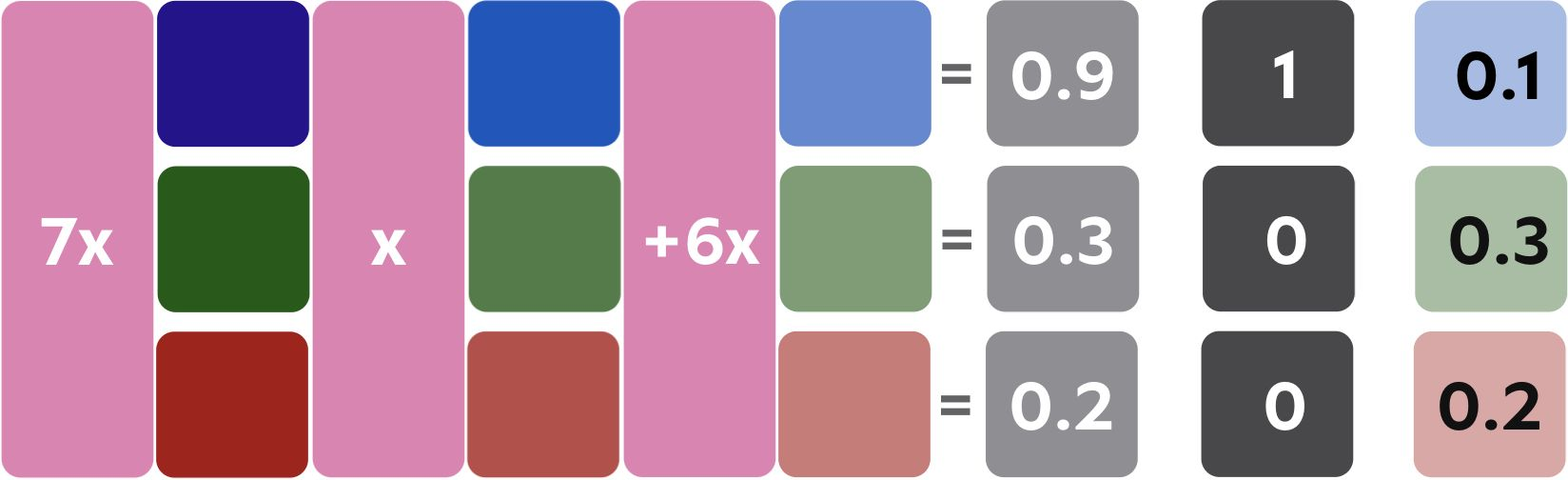
예측값과 실제로 가지는 값을 비교하여 Error이 얼마나 차이나는지 비교할 수 있다. 이중 Error이 가장 작은 연산 방법을 선택하여 Best Model로 만들어낸다. 또한 최적의 연산 집합을 저장하여 추후 test set이나 산출되는 case를 대입하여 생성한 모델에 대입하여 예측 결과를 만들어준다.
여기서 Try중 오차가 제일 작은 값을 가지는 모델을 다음과 같이 부르기도 한다.
- 최적의 모델
- 학습 완료 모델
- 추론시 사용되는 모델(서비스 사용시)
3단계: Deep Learning
기존의 SW1.5보다 업그레이드 된 3단계 방법은 사람이 직접 하던 특징을 정의하던 구간을 제외시키면서 기계가 직접 특징을 뽑아내고 그 특징에 대해 학습하여 분류 또는 회귀나 여러 생성을 도모하는 단계를 나타낸다. SW2.0이라고도 하며 이 시점부터 딥러닝이라 분류하기도 한다. 사람은 단순하게 이미지를 수집하고 학습 데이터를 생성하면 나머지는 딥러닝 모델이 전부 알아서 부여한다.
아래의 이미지에서 위는 머신러닝, 아래는 딥러닝 과정에서 사람이 이행하는 과정을 나타낸다.
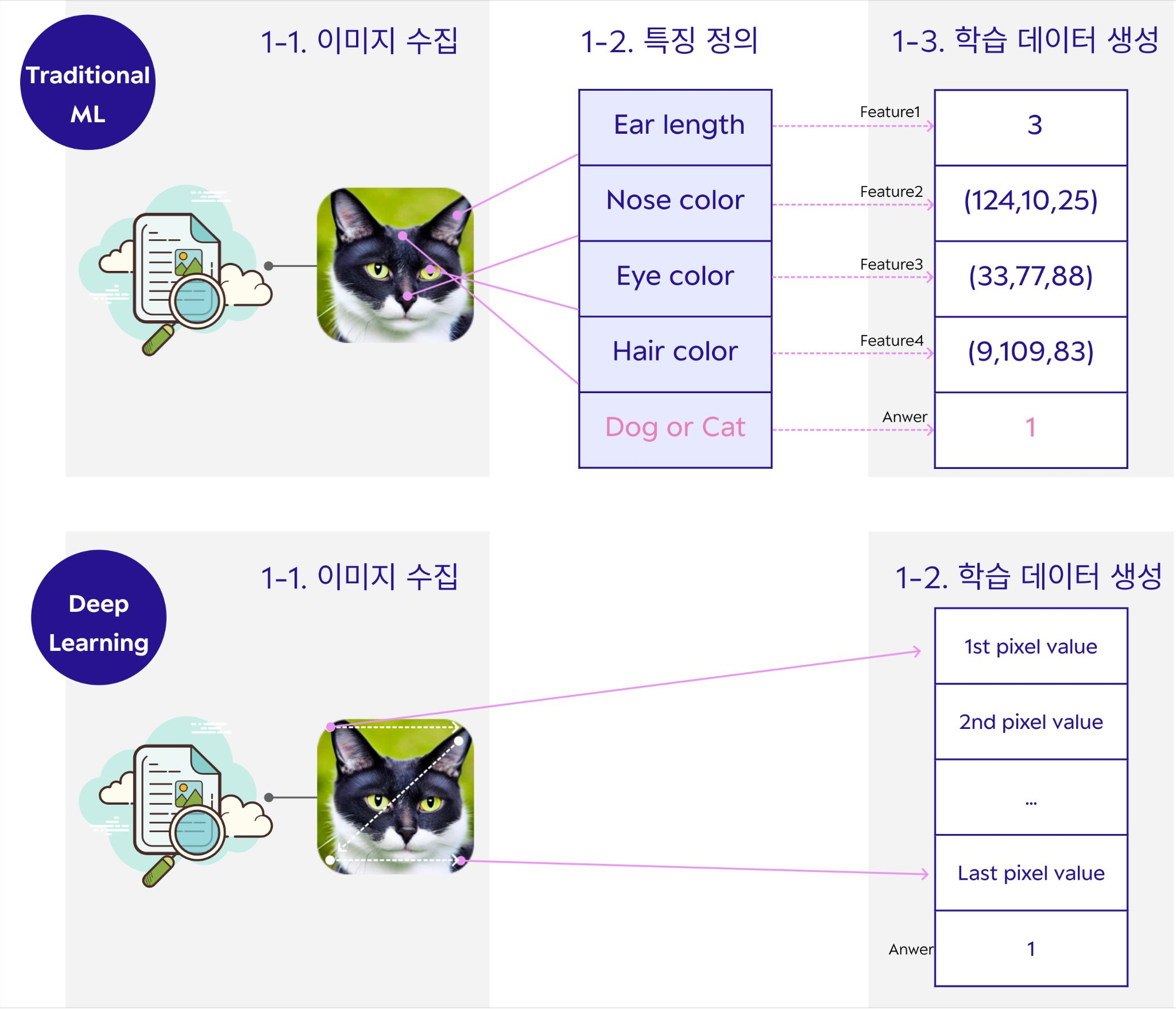
이 딥러닝의 특징은 다음과 같다.
- 출력을 계산하기 위해 모든 연산들을 기계가 고안
- 자유도가 너무 높아 연산들의 구조를 잡고 사용
- 특징 정의 과정이 빠지게 됨
또한 텍스트 데이터에서는 토큰화라는 것을 진행하는데 토큰화의 의미는 다음과 같다.
- 의미분석에 용이한 단위인 토큰으로 쪼개는 과정 (text 딥러닝 준비 과정)
4단계: Pre-training & Fine-tuning
3단계의 딥러닝에서는 다음과 같은 문제점이 존재하였다.
- 분류 대상 또는 Task가 바뀔때 마다 새로운 모델이 필요
따라서 새로운 모델을 불러오지 않고 미리 대규모 데이터를 학습시켜 해당 관련 모델이 필요할 때 마다 불러와서 활용할 수 있는 Pre-training model을 불러와 원하는 분류나 회귀를 진행시킬 수 있는 방식을 활용하였다.
아래의 이미지는 많은 동물을 미리 학습시켜 현재 필요한 CAT vs DOG를 분류하는 모델을 만들기 위해 아래의 두 Layer만을 별도로 학습시켜 두 class만으로 분류하는 모델을 생성하는 예시를 보여주고 있다.
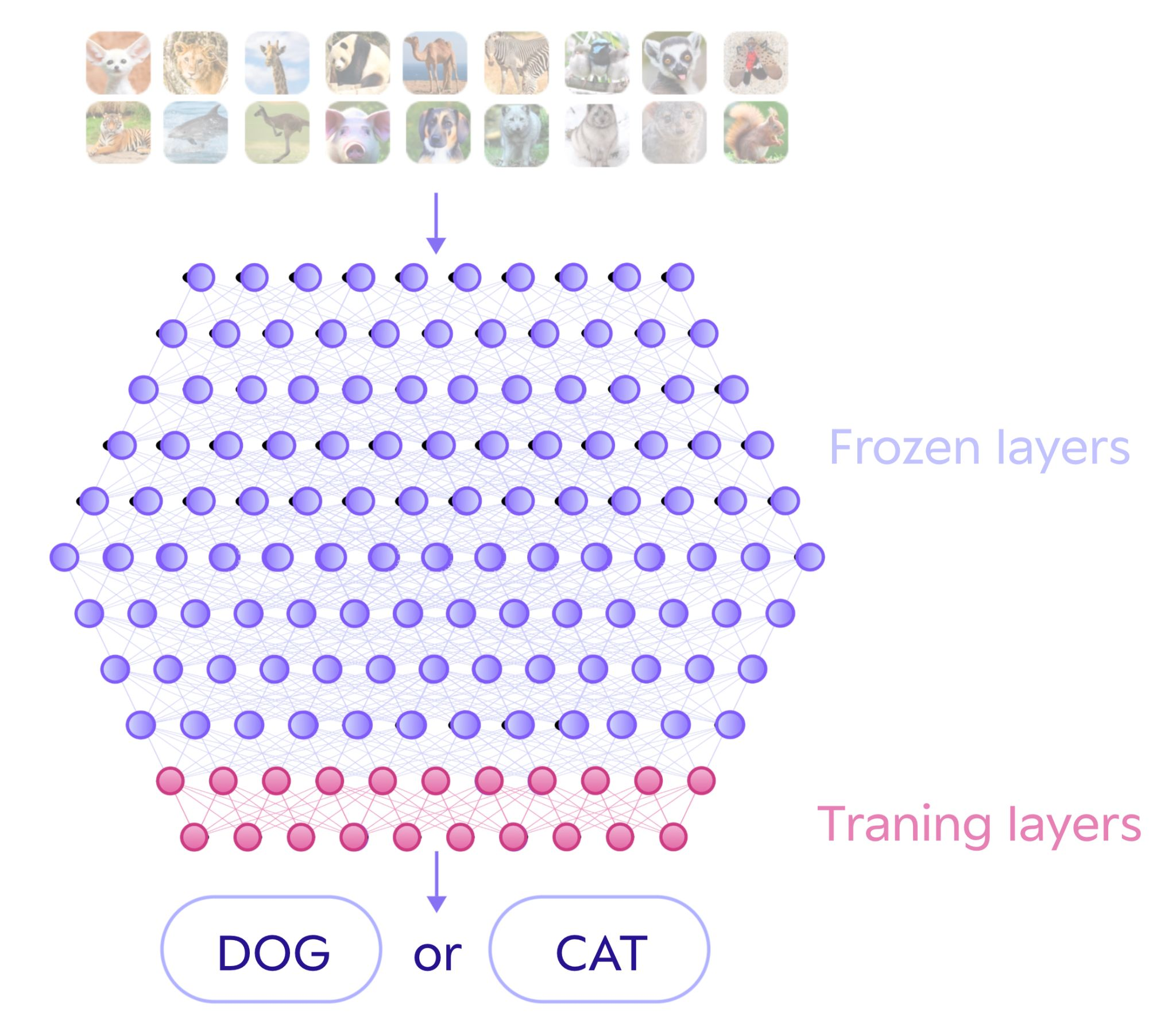
텍스트 데이터 관점에서 보기로 하자. GPT1을 예시로 들어 과정을 살펴보기로 한다.
Pre-training
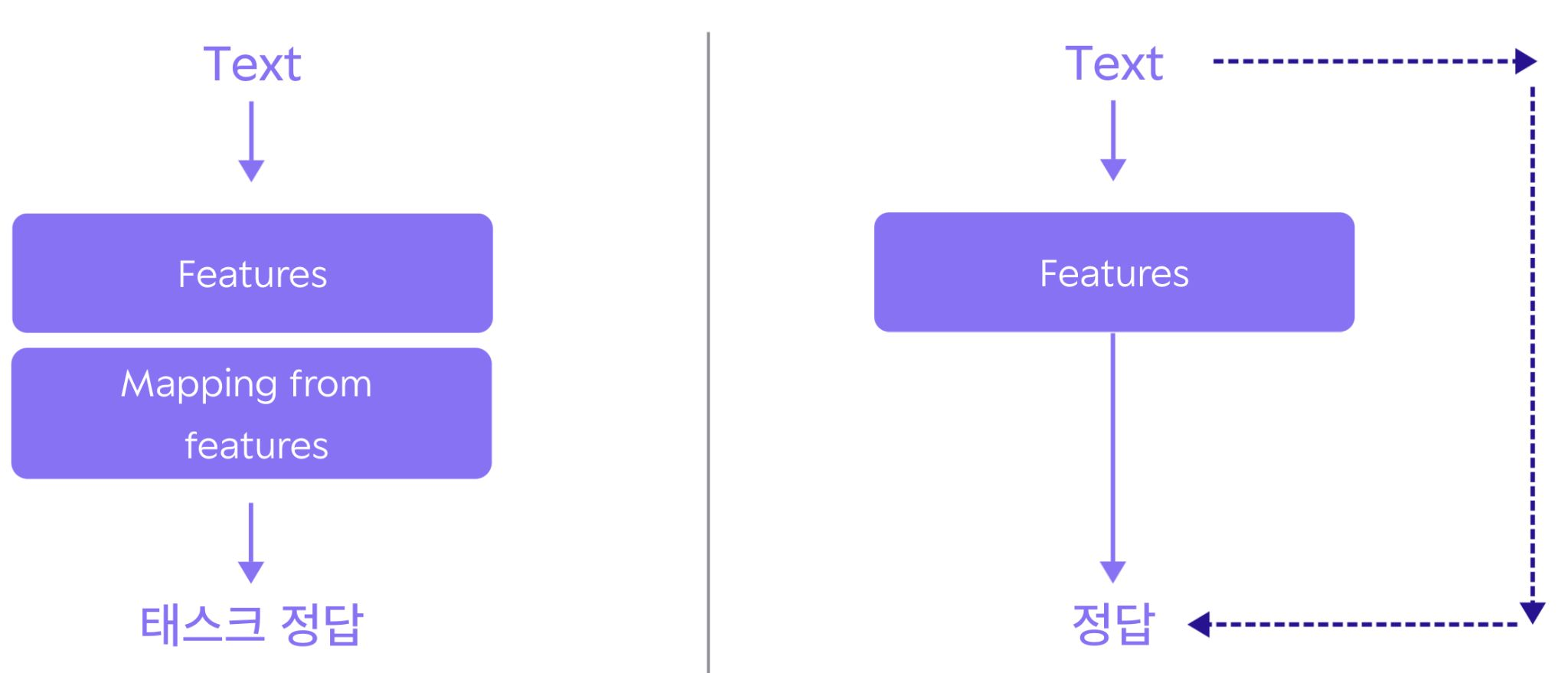
인터넷 상의 수많은 데이터를 활용하려면 태스크 정답을 세팅하는 작업이 없어야 훨씬 효율적으로 운영할 수 있다. 따라서 입력 텍스트에서 정답을 만들어 내는 방식으로 활용한다. 이를 다른말로
Un-supervised pre-training 이나 Self-supervised pre-training 부르기도 한다.
Fine-tuning
미세 조정은 다음과 같은 특징으로 진행된다.
- Feature의 특징은 이미 충분히 학습되어있다고 가정하고 진행
- 원하는 클래스만을 활용하여 mapping을 진행
기존에 학습되어 있는 Features를 불러와 mapping을 시키고 진행하기 때문에 전체적으로 이 과정을 보게되면 Transfer Learning을 진행한다고 생각하면 된다.
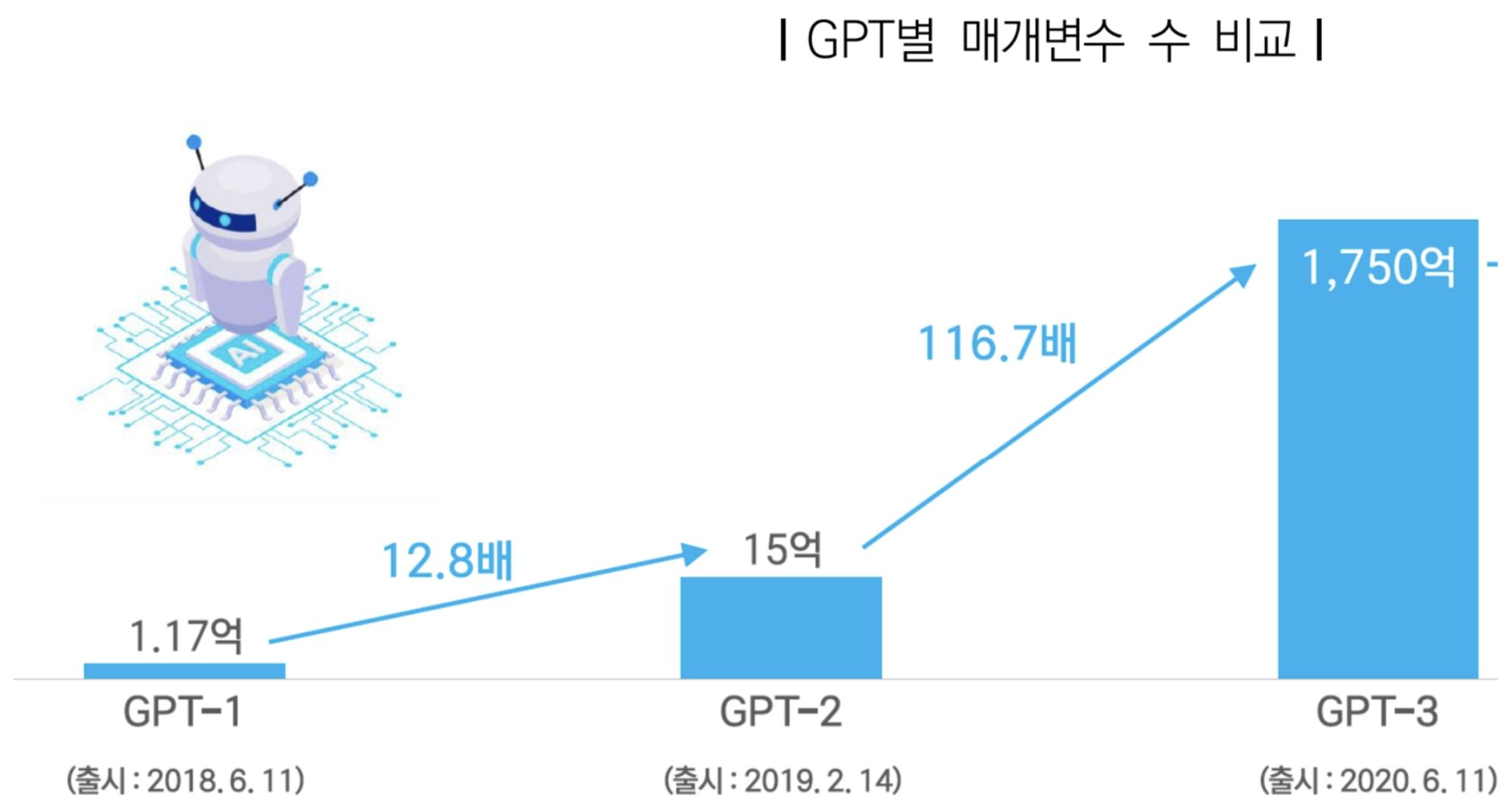
또한 기존의 사전 학습 데이터의 사이즈를 증가시키면 성능이 크게 올라간다. 아래의 이미지는 GPT의 매개 변수 개수의 증가를 보여준다. 이에 따라 학습 시키는 데이터의 양도 커지면서 받아드릴 수 있는 값의 경우도 많아지며 원하는 의도대로 결과를 만들어줄 가능성이 매우 커진다. 이로 인해서 필요한 기능을 구현하기 위해 적용해야할 데이터의 수가 매우 적어지며 개발 속도 또한 빨라진다.
5단계: Big Model & Zero/Few shot
4단계에서 진행하던 Task별로 사전 학습된 모델 조차 필요없고 추가 데이터도 필요 없는 단계를 의미한다. 이는 SW3.0이라고도 부른다. 따라서 거대한 모델만이 존재하고 별도로 mapping하는 과정 조차 필요하지 않게 된다.
5단계에서는 in-context learning을 진행하는데 이는 학습을 하는 것은 아니다. 단순히 input에서 예시를 0개 에서 여러개를 포함해 태스크를 알려주며 지시사항을 부여한다. 그러면 자동적으로 모델에서 원하는 결과를 만들어준다. 이는 현재 text 데이터 한정으로 만들어졌으며 대표적인 도구로 ChapGPT3가 있다.
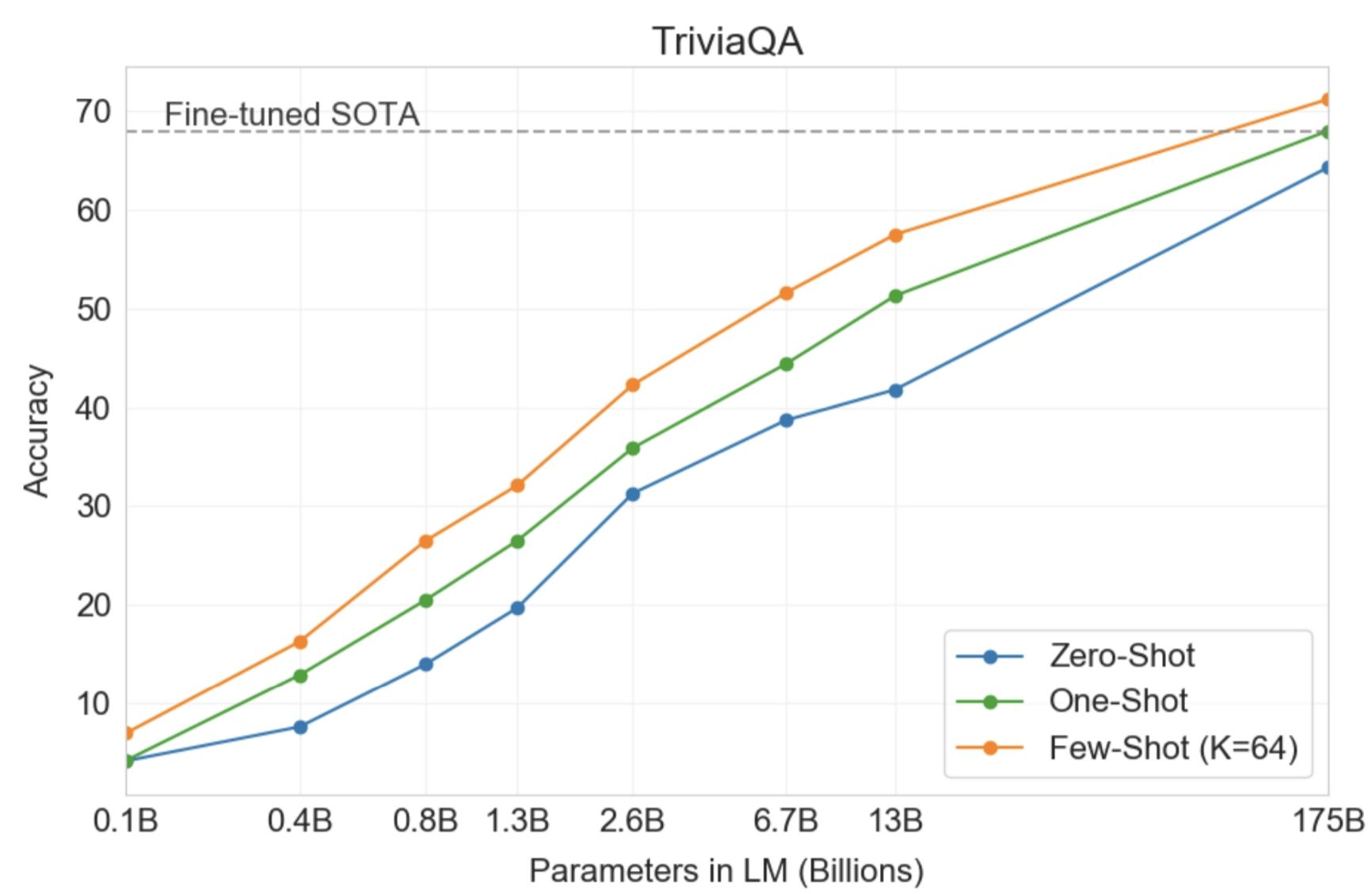
위의 그래프는 태스크의 개수에 따라 얼마나 결과를 정확하게 내주는지에 대해 비교한 것이다. 예제가 많으면 많을수록 성능이 좋아지며 원하는 결과를 불러올 수 있다.
❓고찰
평소에 딥러닝에 대해 모델의 예시와 사용방법, loss, 여러 기능과 같이 상세 내용중 일부만을 배웠다면 이번 강의는 딥러닝이 실제로 어디부터 어디까지 포함되는 영역이며 어떻게 발전해왔나를 확실하게 잡고갈 수 있도록 유도해주는 강의였다. 괜히 상세 내용중 일부만 알고 이를 적용하려고 하면 아무것도 못했던 경우가 많았다. 따라서 딥러닝에 대해 제대로 배웠다라는 느낌을 받았던 적이 없었는데 이번 기회를 통해서 나름의 딥러닝의 큰 틀을 가지고 갈 수 있게 되는 계기가 되었다.
나처럼 애매하게 알고 있거나 딥러닝을 시작하는 사람이라면 다음 강의를 듣고 확실하게 큰 틀을 만들어 둔 다음 하나씩 채워가는 과정을 진행하면 매우 좋을것같다.
그래도 나름 머신러닝을 실전 대회나 논문 작성시 활용했던 경험이 있었던지라 이해하는데 어렵지 않았다. 추가적으로 이론에 대한 내용을 깊이 알고 있으면 앞으로 새로운 모델이 빠르게 생성되더라도 금방 이해하고 나만의 방법으로 적용할 수 있는 시작점이 될 수 있을 것 같다.
