[230131] 멋쟁이사자처럼 AI SCHOOL 8기 '서울시 코로나 데이터 EDA(2)_박조은강사님' 복습
멋사 AI SCHOOL 8기
📝Today I learned
🚀 TIL 목차 🚀
- EDA
1) 두 개의 변수에 대한 빈도수 구하기
2) Boolean Indexing으로 특정 조건 값 찾기
3) pivot_table
4) group by
.
서울시 코로나 현황 데이터 EDA(2)
.
EDA
1. 두 개의 변수에 대한 빈도수 구하기
🔹 pd.crosstab()
pd.crosstab(index=df["연도"], columns=df["퇴원현황"])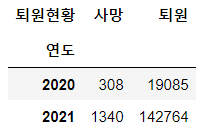
🔹 전치행렬을 사용해야하는 경우
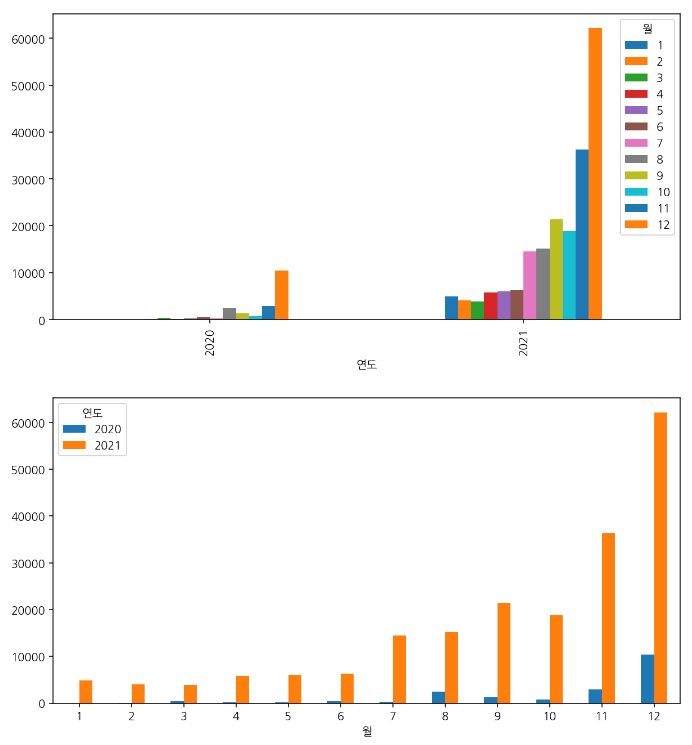
ym = pd.crosstab(df["연도"], df["월"])
display(ym.plot.bar(figsize=(10,5)))
display(ym.T.plot.bar(figsize=(10,5), rot=0)) : '월'을 기준으로 2020년과 2021년의 확진자수를 확인하고 싶다면 .T를 활용해 전치행렬로 만들어주면 된다.
: 아니면 처음부터 ym = pd.crosstab(df["월"], df["연도"])로 코드를 짜거나
🔹 normalize 기준 변경
# '연도'를 기준으로 각 '요일'이 차지하는 비율 구하기
pd.crosstab(index=df["연도"], columns=df["요일"], normalize='index')*100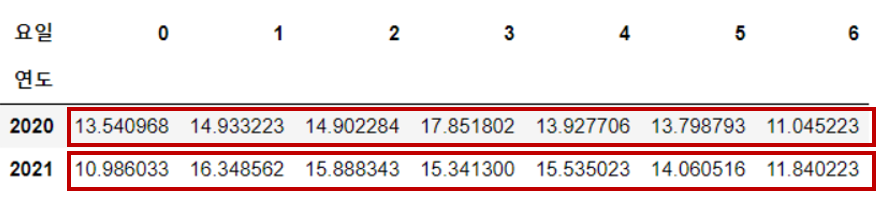
# '요일'을 기준으로 각 '연도'가 차지하는 비율 구하기
pd.crosstab(index=df["연도"], columns=df["요일"], normalize='columns')*100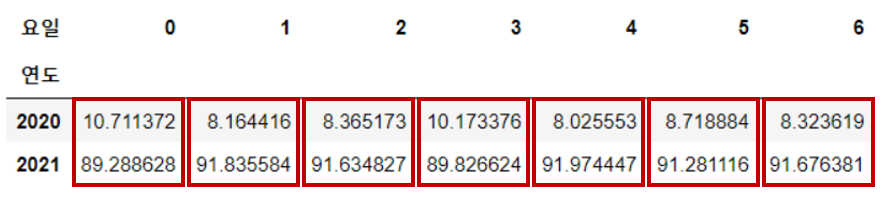
🔹 style.background_gradient()
: 높은 수치일수록 색이 진해지므로 한눈에 데이터를 파악하기 용이함
gu_ym = pd.crosstab(df["거주구"], df["연도월"])
gu_ym.style.background_gradient()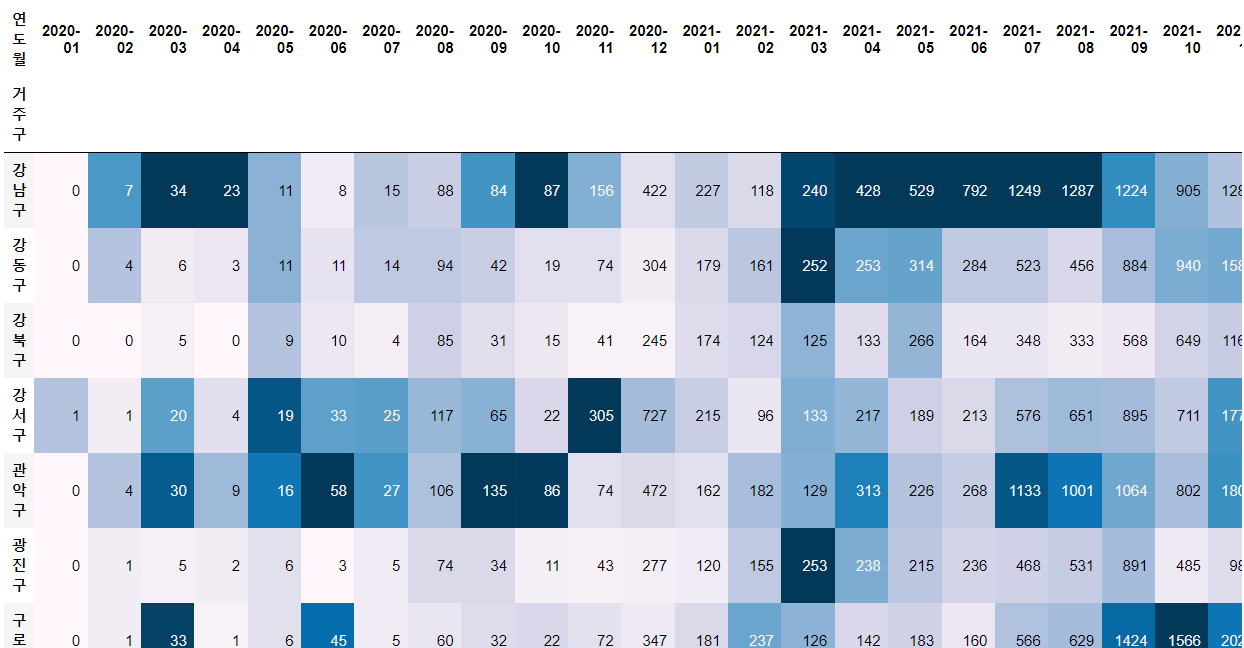
.
2. Boolean Indexing으로 특정 조건 값 찾기
🔹 .loc[조건, 열]
: 조건에 대해 True인 값만 가져옴. 지정된 열을 표현함.
: and, or 사용 불가. -> &, | 로 대신 사용
# '거주구'가 '강남구'이고 '요일명'이 '일'인 데이터만 가져옴
# '거주구', '요일명' 컬럼을 가져옴
df.loc[(df["거주구"]=="강남구") & (df["요일명"]=="일"), ["거주구", "요일명"]]🔹 str.contains() 🌟🌟🌟
: 데이터프레임에서 특정 영단어를 찾고 싶은 경우
: 소문자와 대문자가 구분되므로 일단 모두 대문자로 만들고 새로운 컬럼에 담기
: 대문자 영단어가 담긴 새로운 컬럼에서 대문자로 인덱싱하고 원래 영단어가 있던 컬럼값을 추출
: => 소문자 누락없이 모든 영단어 데이터 추출 가능!
#대상 컬럼의 모든 문자열을 대문자로 만들고 새로운 컬럼에 담기
df["접촉력_대문자"] = df["접촉력"].str.upper()
# 대문자 영단어가 담긴 새로운 컬럼에서 대문자로 인덱싱하고 원래 영단어가 있던 컬럼값을 추출
df.loc[df["접촉력_대문자"].str.contains("PC"), "접촉력"].value_counts()
🔹 isin()
: 리스트, 딕셔너리 등에 담긴 값과 일치하는 값 추출
# "거주구"가 "강남구", "서초구", "송파구" 인 데이터만 찾기
# loc를 통해 해당 조건의 "접촉력" 컬럼만 가져오기
df.loc[df["거주구"].isin(["강남구", "서초구", "송파구"]), "접촉력"].value_counts()
# 위와 똑같은 과정을 str.contains()로 표현하기
df.loc[df["거주구"].str.contains("강남|서초|송파"), ["거주구"]].value_counts()🌟 str.contains()와 isin()의 차이
-
str.contains : 찾으려는 문자열을 포함만 해도 반환 가능(Series에서만 사용 가능)
-
isin : 찾으려는 문자열과 정확히 일치해야 반환 가능(df에서도 사용 가능)
🔹 다른 칼럼 기준으로 새로운 칼럼값 생성
# "접촉력" 컬럼에서 "해외유입"인 데이터에 대해 "해외유입" 변수 만들기
df["해외유입"] = df["접촉력"] == "해외유입"
# "국내해외"라는 컬럼을 새로 만들건데
# "해외유입" 컬럼이 "해외"이면 True, "국내"이면 False 값을 넣음
df.loc[df["해외유입"], "국내해외"] = "해외" # True
df.loc[~df["해외유입"], "국내해외"] = "국내" # False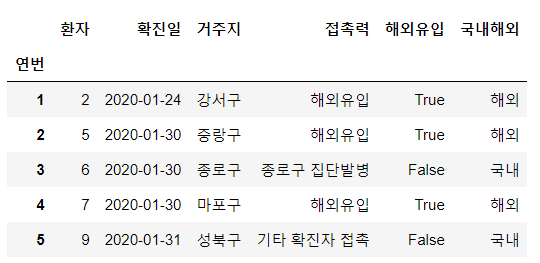
# 시각화 데이터 내림차순으로 정렬하기
gu_abr = pd.crosstab(df["거주구"], df["국내해외"])
gu_abr[["국내", "해외"]].sort_values("해외", ascending=False).plot.bar(subplots=True);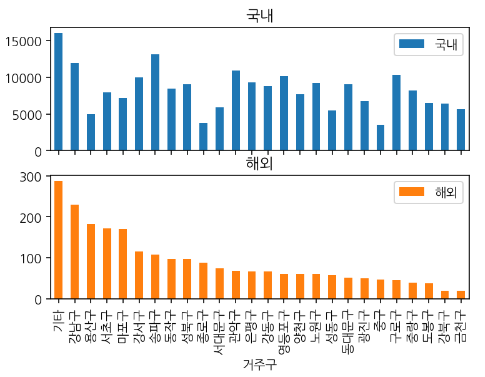
.
3. pivot_table
🌟pivot과 pivot_table
-
공통점 : index, columns, values 를 공통적으로 사용할 수 있음
-
차이점 : pivot 은 형태 변환만 제공하고 pivot_table 은 연산을 함께 제공. groupby() 를 사용하기 쉽게 엑셀에서 사용하는 용어로 만들어 놓은 것이 pivot_table().
🔹 pivot_table()
# 거주구별 해외유입 여부에 따른 빈도수 구하기
pd.pivot_table(data=df, index="거주구", columns="국내해외", values="환자", aggfunc="count")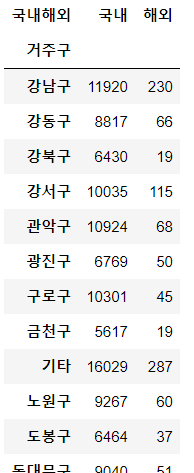
🌟 values로 지정할 컬럼 고르기
: 유니크하고 결측치도 없는 것으로 지정하면 됨
🔹 style.bar()
# 거주구에 따른 요일별 확진자 빈도수
weekday_list=list("월화수목금토일")
df_gu_weekday = pd.pivot_table(data=df, index="거주구", columns="요일명", values="환자", aggfunc="count")
df_gu_weekday[weekday_list].style.bar()
.
4. group by
🔹 group by()
# "거주구", "국내해외" 으로 그룹화 하여 "환자" 컬럼으로 빈도수 구하기
df.groupby(["거주구", "국내해외"])["환자"].count() # df.groupby(["거주구", "국내해외"]).count()["환자"]과 똑같음
🔹 .unstack()
# "거주구", "국내해외" 으로 그룹화 하여 "환자" 컬럼으로 빈도수 구하고
# 마지막 인덱스("국내해외")를 컬럼으로 만들기
gu_os = df.groupby(by=["거주구", "국내해외"])["환자"].count()
gu_os.unstack()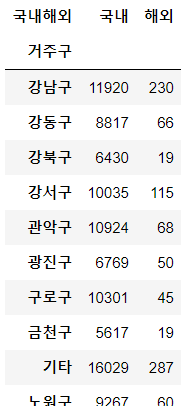
❗이것만은 외우고 자자 Top 3
📌 데이터프레임에서 특정 영단어를 찾고 싶은 경우🌟🌟🌟
: 소문자와 대문자가 구분되므로 일단 모두 대문자로 만들고 새로운 컬럼에 담기
: 대문자 영단어가 담긴 새로운 컬럼에서 대문자로 인덱싱하고 원래 영단어가 있던 컬럼값을 추출
=> 소문자 누락없이 모든 영단어 데이터 추출 가능!
📌 crosstab(), pivot_table(), groupby()로 갈수록 어렵지만 그만큼 자유도가 높아져 제대로 익히면 구하고자 하는 값을 대부분 구할 수 있다.
📌 pivot 은 형태 변환만 제공하고 pivot_table 은 연산을 함께 제공한다.
🌟데일리 피드백
1. 오늘의 칭찬&반성
칭찬 : 이모지 응원 요정으로 활약한 것. pivot_table에서 values값 지정할 때 어떤 컬럼으로 선정해야하는지 질문한 것.
반성 : 오후 시간에 잠깐 졸았다... 내일은 커피 마셔야지..
2. 내가 부족한 부분
현실 데이터를 가지고 응용하는 것
3. 내일의 목표
시간이 부족해 못 끝낸 오늘 복습 + 내일 복습까지 무사히 마무리하기
