[230201] 멋쟁이사자처럼 AI SCHOOL 8기 'FinanceDataReader를 통한 종목수익률 비교 EDA_박조은강사님' 복습
멋사 AI SCHOOL 8기
📝Today I learned
🚀 TIL 목차 🚀
1) 데이터 준비
- 라이브러리 불러오기
- 상장종목 목록 가져오기
- 전체 상장종목에서 종목 코드와 종목명만 가져오기
- merge를 통한 시가총액 상위 10개 종목 만들기
- 여러 종목의 종가 수집
- 하나의 데이터프레임으로 합치기
2) 시각화
- 시각화 사전준비
- 여러 종목 주가 추이 시각화
- 2축 그래프 사용하기
- 기간수익률 시각화
- 왜도와 첨도
FinanceDataReader를 통한 종목수익률 비교 EDA
1) 데이터 준비
🔹 라이브러리 불러오기
import pandas as pd # 분석
import numpy as np # 계산
import FinanceDataReader as fdr # 주식데이터 라이브러리- FinanceDataReader: 금융데이터 수집 라이브러리
FinanceDataReader 사용자 안내서
🔹 상장종목 목록 가져오기
: 네이버 증권 웹페이지 스크래핑
# 네이버 증권 웹페이지 중 '편입종목 상위' 링크
url = "https://finance.naver.com/sise/entryJongmok.naver?&page=1"
# 해당 url로 상위 10개 종목 가져오기
df_top10 = pd.read_html(url)[0].dropna()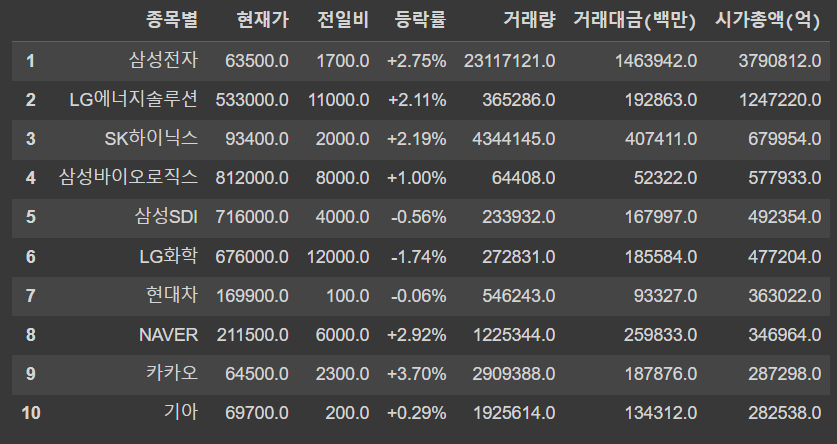
🔹전체 상장종목에서 종목 코드와 종목명만 가져오기
: fdr 라이브러리 활용
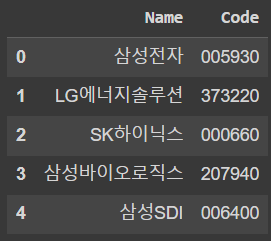
# fdr에서 KRX 정보 중 종목명, 종목코드만 가져오기
df_krx = fdr.StockListing("KRX")[["Name", "Code"]]💡 참고: KRX는 KOSPI,KOSDAQ,KONEX 모두 포함
🔹 merge를 통한 시가총액 상위 10개 종목 만들기
: df_top10은 상위 10개 종목의 데이터
: df_krx는 KRX의 모든 상장종목 중 종목명, 종목코드 데이터
: 이 두 데이터를 종목명을 key값으로 합치는데 merge를 사용
# KRX 모든 상장 종목 Name 컬럼에서 df_top10의 상위 10개 종목 이름과 일치하는 데이터만 가져오기
df_10 = df_top10.merge(df_krx, left_on='종목별', right_on='Name')[['Name', 'Code']]
df_10
# isin을 활용한 방법도 있음
df_krx[df_krx['Name'].isin(df_top10['종목별'])]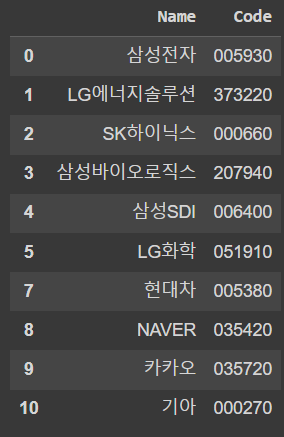
🔹 여러 종목의 종가 수집
# list comprehension을 활용해 여러 종목의 종가를 수집
item_list = [fdr.DataReader(code, start='2022')['Close'] for code in df_10['Code']]
🔹 하나의 데이터프레임으로 합치기
상위 10개 종목의 2022년도부터 지금까지 종가만 수집한 데이터
df = pd.concat(item_list, axis=1)
df.columns = df_10["Name"]
df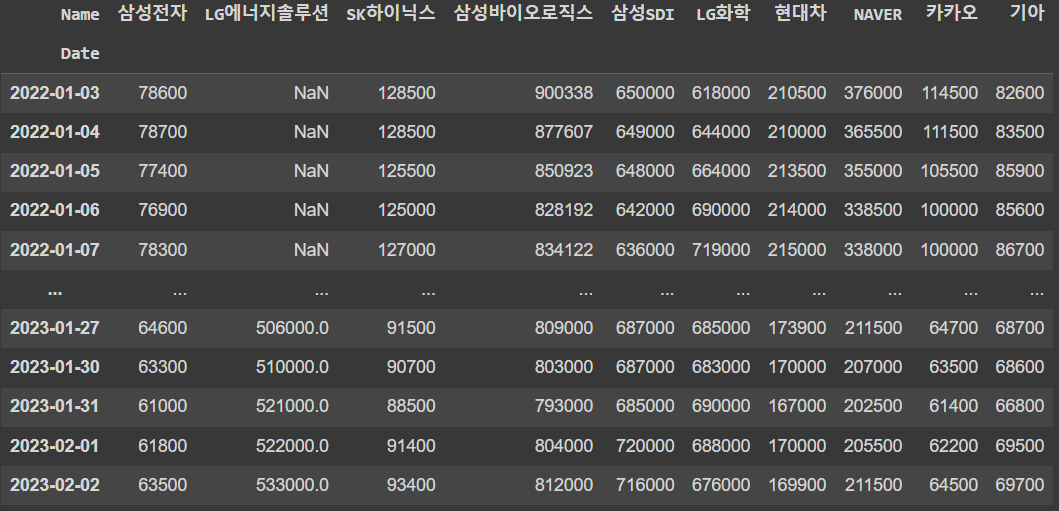
2) 시각화
🔹 시각화 사전준비
# 한글폰트 사용을 위한 라이브러리
# !pip install koreanize-matplotlib
import koreanize_matplotlib
# 그래프 내 글씨를 선명하게 만드는 코드
%config InlineBackend.figure_format = 'retina'
# 다양한 스타일을 제공하는 시각화 라이브러리
import matplotlib.pyplot as plt🌟 matplotlib에서 가장 추천하는 스타일: ggplot, fivethirtyeight
🔹 여러 종목 주가 추이 시각화
# 자동으로 선 그래프를 그려줌, figsize : 시각화 박스 크기, lw : 선 굵기
df.plot(figsize=(10, 5), lw=0.9)
# 범례 위치 설정
plt.legend(bbox_to_anchor=(1, 1))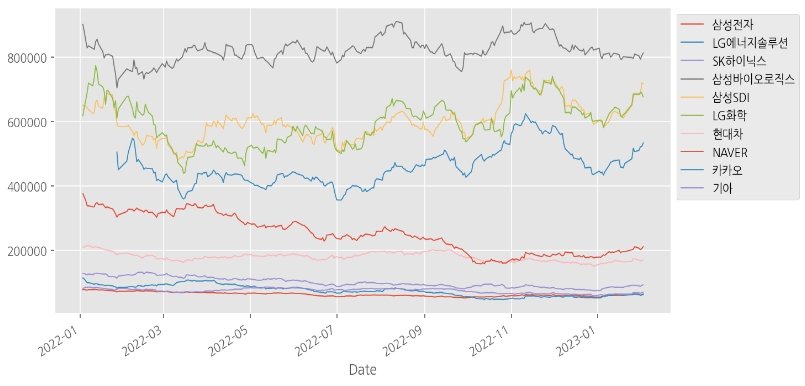
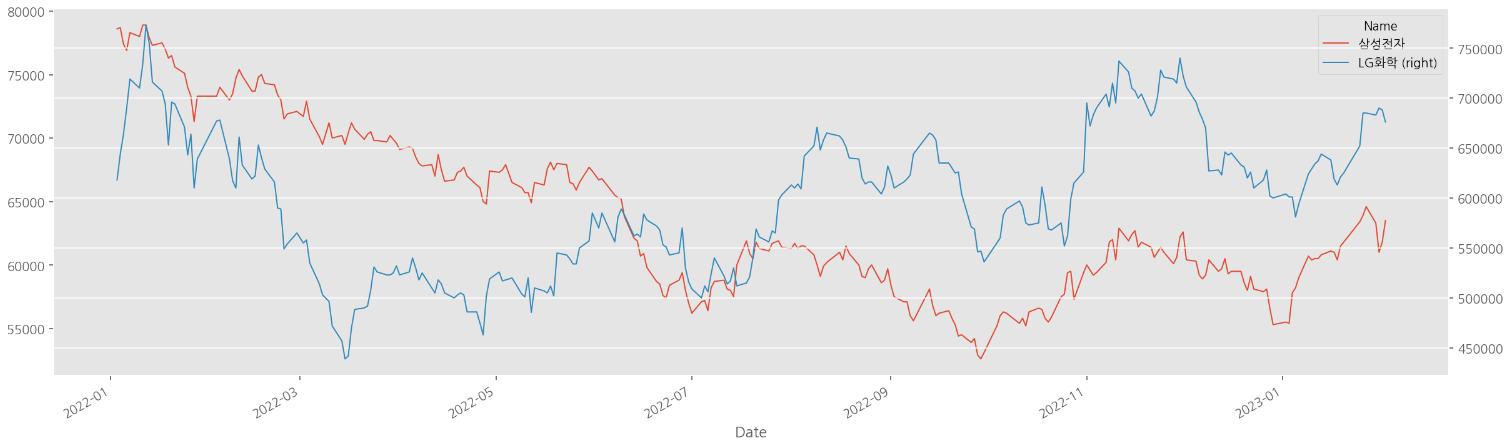
🔹 2축 그래프 사용하기
# 삼성전자와 LG화학 2개 종목을 비교해봄
df[["삼성전자", "LG화학"]].plot(): 두 종목 간 스케일 차이가 심해 삼성전자의 추이를 제대로 확인할 수 없음
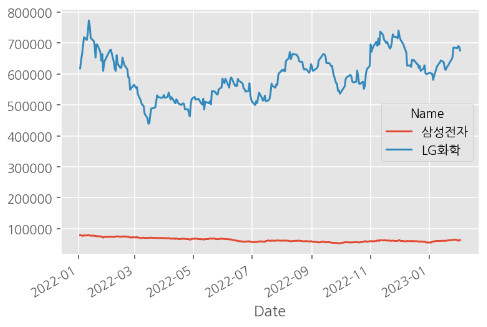
# secondary_y를 사용해 2축 그래프 그리기
df[["삼성전자", "LG화학"]].plot(figsize=(20,6), lw=1, secondary_y="LG화학"): LG화학을 위한 y축을 오른쪽에 추가해 두 종목 모두 추이를 확인할 수 있게 변경
🔹 기간수익률 시각화
: 종목마다 다른 스케일때문에 비교하기 힘듦
: 데이터프레임 기준 첫날 가격을 0으로 맞추고 상대적으로 상승, 하락에 대한 값을 구함
: 이처럼 다른 스케일의 값을 조정할 땐 표준화 혹은 정규화 방법을 이용
📌 표준화
- 데이터가 평균으로부터 얼마나 떨어져있는가
- Z-score = (측정값 - 평균) / 표준편차
📌 정규화
- 데이터의 상대적 크기에 대한 영향을 줄이기 위해 0~1로 변환
- (측정값 - 최소값) / (최대값 - 최소값)
# 전체 데이터프레임 값에 대한 수익률 계산
df_norm = (df / df.iloc[0]) - 1
df_norm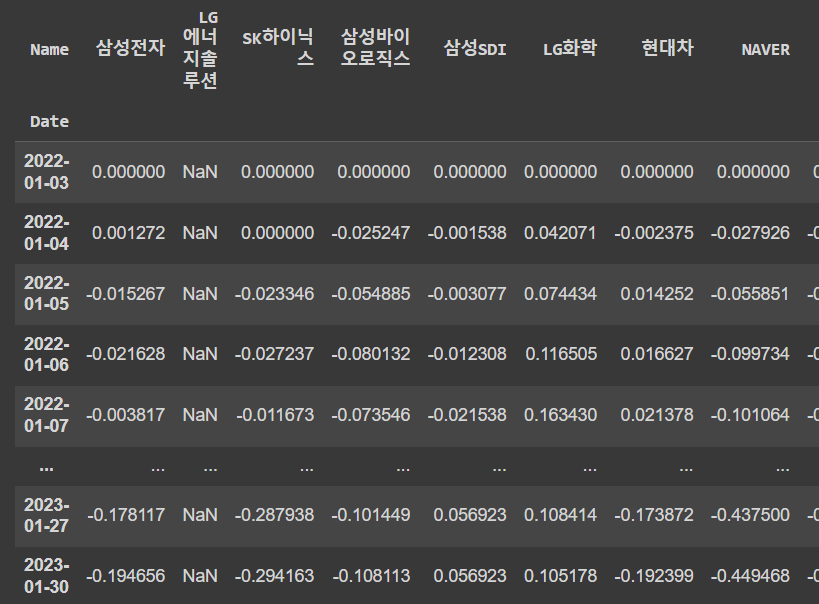
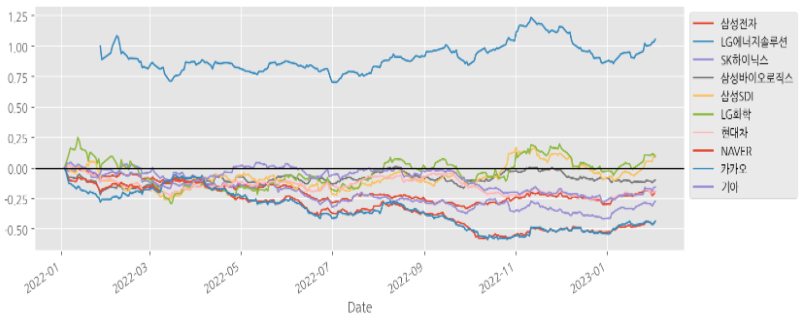
# 전체종목 수익률 시각화(선그래프)
# matplotlib API 활용
plt.plot(df_norm)
# Pandas API 활용
df_norm.plot(figsize=(12, 4))
plt.axhline(0, c='k')
plt.legend(bbox_to_anchor=(1,1))
# 전체종목 수익률 시각화(히스토그램)
df_norm.hist(bins=50, figsize=(20,20));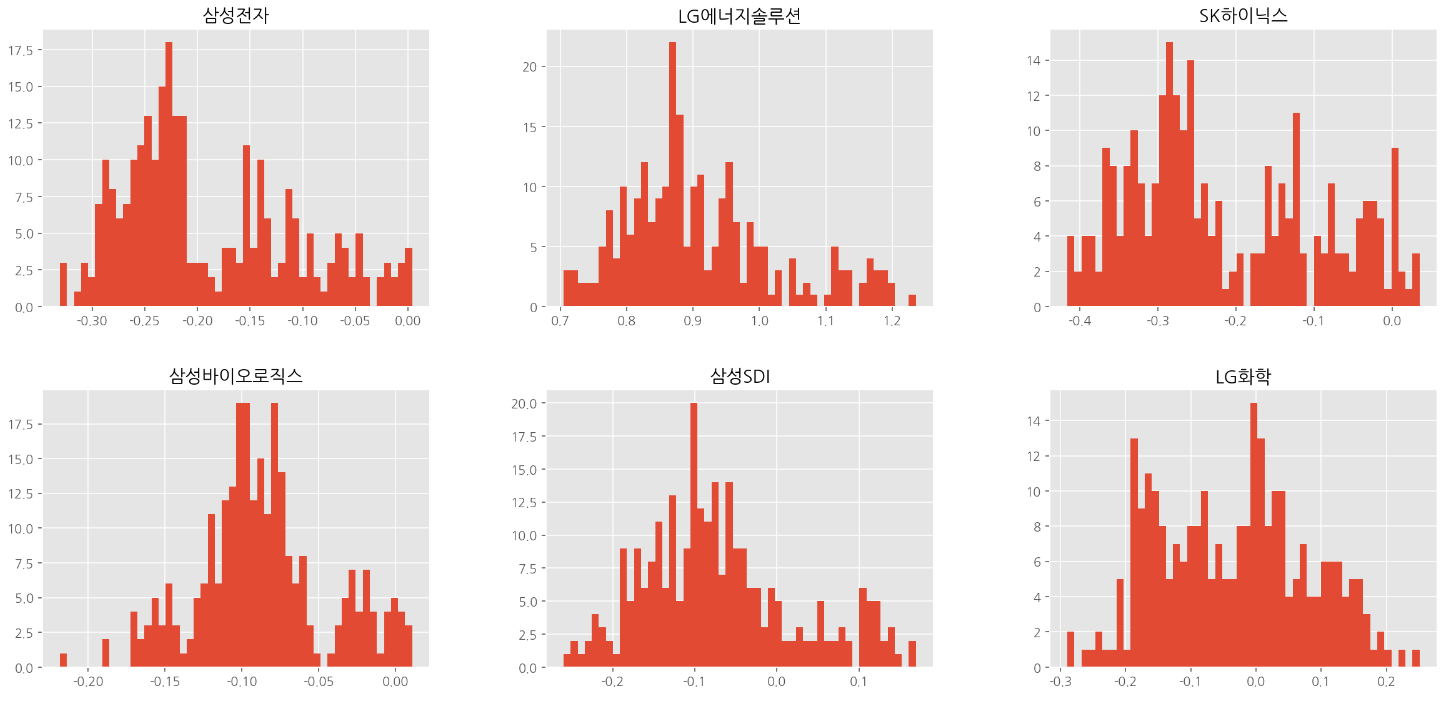
🔹 왜도와 첨도
📌 왜도 : 실수 값 확률 변수의 확률 분포 비대칭성을 나타내는 지표
- Positive Skew : 오른쪽으로 긴 꼬리
- Negative Skew : 왼쪽으로 긴 꼬리
📌 첨도 : 확률분포의 뾰족한 정도를 나타내는 척도
- 작을수록 납작, 높을수록 뾰족
# 수익률의 왜도
df_norm.skew()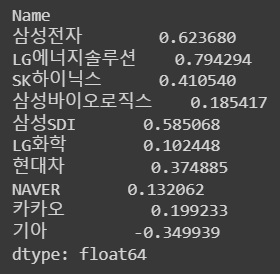
# 수익률의 첨도
df_norm.kurt()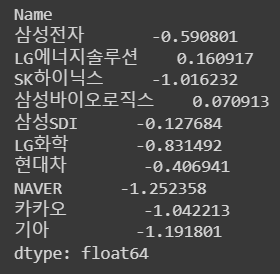
❗이것만은 외우고 자자 Top 3
📌 왜도는 비대칭성을 나타내는 지표, 첨도는 뾰족한 정도
📌 두 데이터 간 스케일 차이가 심할 땐 2축 그래프를 활용하자
📌 가로로 데이터를 병합할 땐 pd.concat(axis=1)
🌟데일리 피드백
1. 오늘의 칭찬&반성
요즘 나의 가장 큰 변화 == 그냥 하는 것. 예전에는 갖은 핑계로 하기 싫은 일을 은근히 미뤘다면 지금은 '그냥 하자!'라는 마음으로 한다. 해버리니까 게임 속 퀘스트를 깨는 것처럼 인생이 더 재밌다. 내가 조금씩 발전하는 느낌이 들어서 하루하루 더 열심히 살아간다. 지금 이 상태가 좋다.
그럼에도 아직 쪼금씩 미루는 일이 생긴다. 밤을 못 새는 체질 탓.. 낮 시간을 더 활용해야겠다.
2. 내가 부족한 부분
반복 연습. 아무리 생각해도 연습이 답이다.
3. 내일의 목표
아직 진행하지 못한 이번주 복습 모두 마무리하기
