📝Today I learned
🚀 TIL 목차 🚀
- 라이브러리 로드
- 파일 불러오기
- EDA
1) 기본사항 확인
2) 일부 데이터 확인
3) 요약, 기술통계값 확인
4) 결측치 확인
5) 중복값 제거
6) 인덱스 값 설정
7) 날짜 타입으로 변경
8) 파생변수 생성
9) 하나의 변수에 대한 빈도수 구하기
10) 결측값 0으로 변경
11) 누적값 구하기
12) 시각화
서울시 코로나 현황 데이터 EDA
1. 라이브러리 로드
import pandas as pd # 데이터 분석
import numpy as np # 연산
import matplotlib.pyplot as plt # 시각화
import koreanize_matplotlib # 한글 폰트 지원# 그래프에 retina display 적용 (글씨 선명하게 해주는 것)
%config InlineBackend.figure_format = 'retina'.
2. 파일 불러오기
# 파일 목록을 불러오기 위한 라이브러리
from glob import glob
files = glob("data/seoul-covid*.csv")
file_paths = sorted(files)
file_paths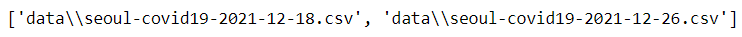
👉 파일을 불러올 때, 파일 이름이 길거나 특수문자 등이 포함되었을 때 직접 타이핑해서 한 글자라도 틀리면 오류가 난다.
이때 glob을 통해 파일 목록을 리스트 형태로 가지고 온다면 타이핑할 필요가 없다.
# 목록의 0번째 인덱스를 파일명으로 그대로 가지고 옴
df_01 = pd.read_csv(file_paths[0]).
3. EDA
🔹 1) 기본사항 확인
: shape, dtypes, columns, index
# 행과 열의 개수
df_01.shape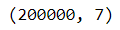
# 모든 컬럼의 데이터 타입
df_01.dtypes
# 모든 컬럼의 이름과 순서
df_01.columns
# 인덱스의 범위(시작, 끝, 간격)
df_01.index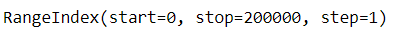
.
🔹 2) 일부 데이터 확인
: head(), tail(), sample()
# 위에서 n개의 데이터만 출력 (Default = 5)
df.head()
# 아래에서 n개의 데이터만 출력 (Default = 5)
df.tail()
# 무작위로 n개의 데이터만 출력 (Default = 1 if `frac` = None)
df.sample().
🔹 3) 요약, 기술통계값 확인
: info(), describe()
# 요약
df.info()
👉 전체데이터개수, 컬럼명, 컬럼 당 대략적인 null값 여부, 데이터타입
# 수치 데이터에 대한 기술통계값
df.describe()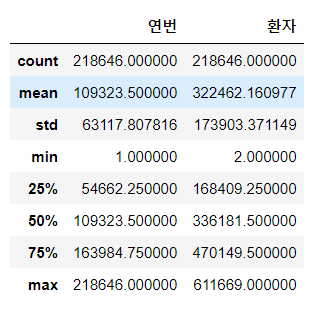
# 문자 데이터에 대한 기술통계값
df.describe(include = 'O')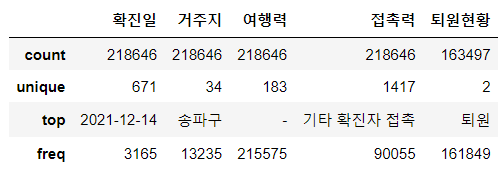
.
🔹 4) 결측치 확인
: isnull()
# null이라면 True, 아니면 False 반환
df.isnull()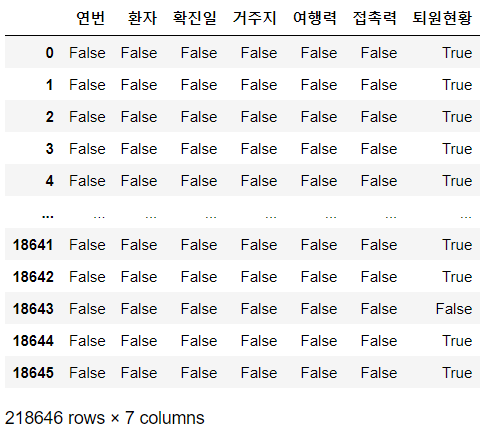
# null 값 합계 반환
df.isnull().sum()
# 결측치의 비율
df.isnull().mean()
.
🔹 5) 중복값 제거
: drop_duplicates()
df = df.drop_duplicates()
df🚨 drop_duplicates()를 적용한 후 다시 df 변수에 담는 것을 잊지 말 것!
(inplace=True는 비추천)
.
🔹 6) 인덱스 값 설정
: 인덱스로 사용할 수 있는 컬럼이 있다면 유일값인지 확인 후 인덱스로 만들기
: nunique(), set_index(), sort_index()
# 전체 df의 행의 개수와 해당 컬럼의 유일값이 일치하는지 확인
display(df.shape)
display(df['연번'].nunique()) # nunique() : 유일값의 개수 출력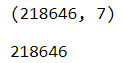
# 해당 컬럼을 인덱스로 만들기
df = df.set_index('연번')
df
# 인덱스값 기준으로 정렬
df = df.sort_index()
df
.
🔹 7) 날짜 타입으로 변경
: pd.to_datetime()
# object를 datetime으로 변경
df['확진일'] = pd.to_datetime(df['확진일']).
🔹 8) 파생변수 생성
🤔 파생변수, 왜 만드나요?
👉 자세히 분류된 기준으로 더 정확하게 분석하기 위해서
#'연도' 칼럼으로 파생변수 만들기
df["연도"] = df['확진일'].dt.year
df["월"] = df['확진일'].dt.month
df["일"] = df['확진일'].dt.day
df["요일"] = df['확진일'].dt.dayofweek
# 확인
df[["확진일", "연도", "월", "일", "요일"]].head()
# 연도-월 파생변수 만들기
df["연도월"] = df["확진일"].astype(str).str[:7]# 요일 한글로 만들기
#find_dayofweek 함수로 요일 숫자를 넘겨주면 요일명을 반환하는 함수
def find_dayofweek(day_no):
dayofweek = "월화수목금토일"
return dayofweek[day_no]# 요일 리스트를 만드는 여러가지 방법
# list comprehension
["월화수목금토일"[x] for x in range(0,7)]
[w for w in "월화수목금토일"]
# 그냥 list
list("월화수목금토일")# 요일 정렬하는 법
w_count = df["요일명"].value_counts()
w_count[list("월화수목금토일")].
🔹 9) 하나의 변수에 대한 빈도수 구하기
: value_counts()
#월별 빈도수 반환
df["월"].value_counts().sort_index()
👉 월별로 표시하면 모든 연도가 월에 포함되니 연도-월별로 분석하는 것이 더 정확
# "연도" 컬럼의 비율 구하기
# normalize : bool, default False
# Return proportions rather than frequencies.
display(df["연도"].value_counts(normalize=True))
display(df["연도"].value_counts(1))
.
🔹 10) 결측값 0으로 변경
: 현업에서 특히 많이 요청하는 것 중 하나!!🌟🌟🌟🌟🌟
: pd.date_range(), fillna(0)
# iloc를 통해 첫 확진일과 마지막 확진일자 찾기
last_day = day_count.index[-1] # day_count.max()
first_day = day_count.index[0] # day_count.min()# pd.date_range로 전체 기간 생성
all_day = pd.date_range(start=first_day, end=last_day)
all_day
# all_day를 데이터프레임으로 변환
df_all_day = all_day.to_frame()
df_all_day
# 결측치 0으로 채우기
df_all_day["확진수"] = df_all_day["확진수"].fillna(0).astype(int)
df_all_day.iloc[:10]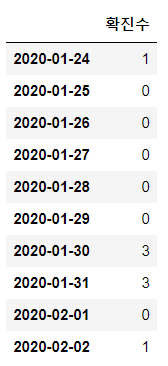
.
🔹 11) 누적값 구하기
: cumsum()
df_all_day["누적확진수"] = df_all_day["확진수"].cumsum()
df_all_day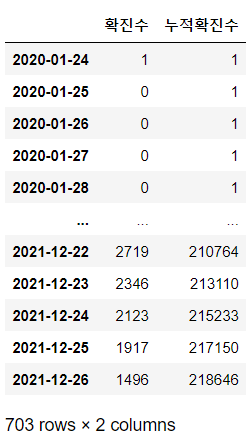
🔹 12) 시각화
# 히스토그램
df.hist(bins=50,figsize=(12,6));
👉 코드 마지막에 세미콜론(;)을 붙이면 로그텍스트를 없앨 수 있음
# plot 활용
year_month = df["연도월"].value_counts().sort_index()
year_month.plot(figsize=(12,5), c='r', marker='o')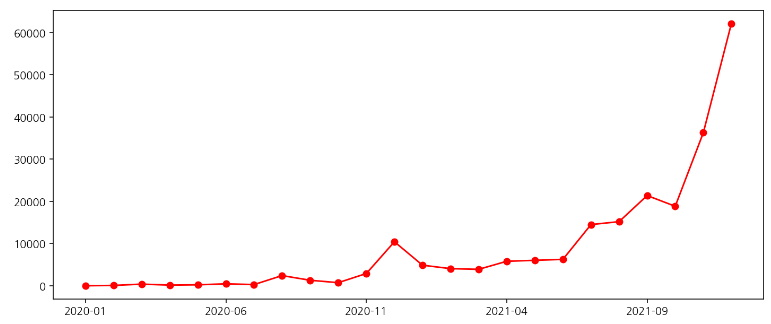
df_all_day.head(10).plot.bar() # plot(kind='bar')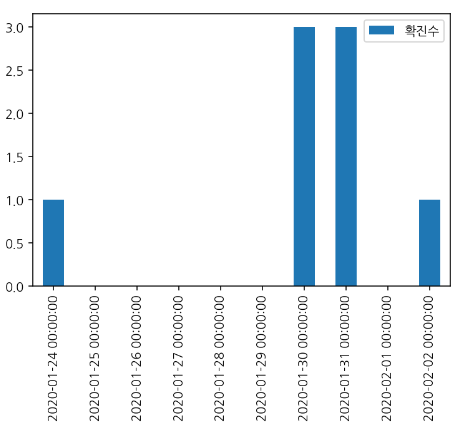
# 그래프 분할
df_all_day.plot.line(figsize=(10,5), subplots=True)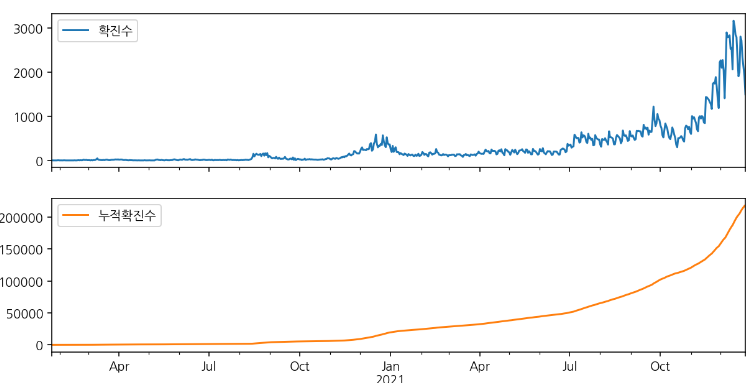
# 2축 그래프
df_all_day.plot.line(figsize=(10,5), secondary_y="누적확진수")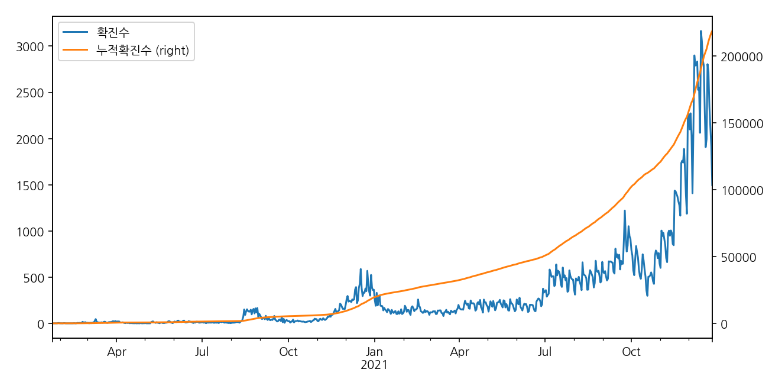
# 기준선 만들기
gu_count.plot.bar(figsize=(15,5))
plt.axhline(5000, c="r", ls=":")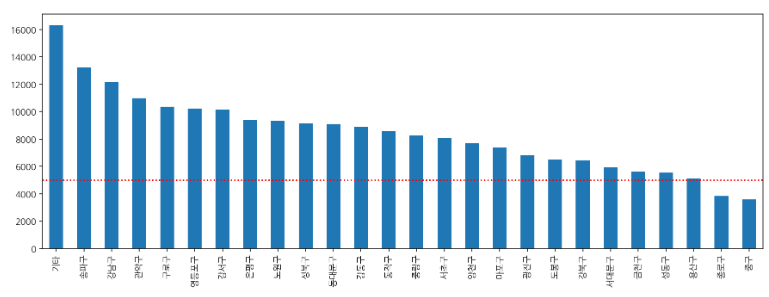
❗이것만은 외우고 자자 Top 3
📌 nunique() : 유일값의 개수 반환
📌 df.isnull().sum() : 컬럼당 null값 개수 반환
📌 pd.date_range(), fillna(0) : 모든 날짜 설정 후 결측치 0으로
🌟데일리 피드백
1. 오늘의 칭찬&반성
나는 정말 데이터 분석을 하고 싶은가.. 의구심이 드는 날이었다. 다른 사람들은 과제든 프로젝트든 즐기면서 하는 것 같은데 나는.. 즐거운 마음이 안 들었다. 나같은 사람은 이 길을 가면 안되는 걸까. 신년 한달동안 정신없이 살다보니 번아웃이 온 걸까. 쉬고 싶다...
2. 내가 부족한 부분
데이터 분석을 즐기는 마음
3. 내일의 목표
EDA 미니플젝 조별 주제 정하기, 운동 및 복습 인증하기
