빅데이터
1.빅데이터 처리 및 응용
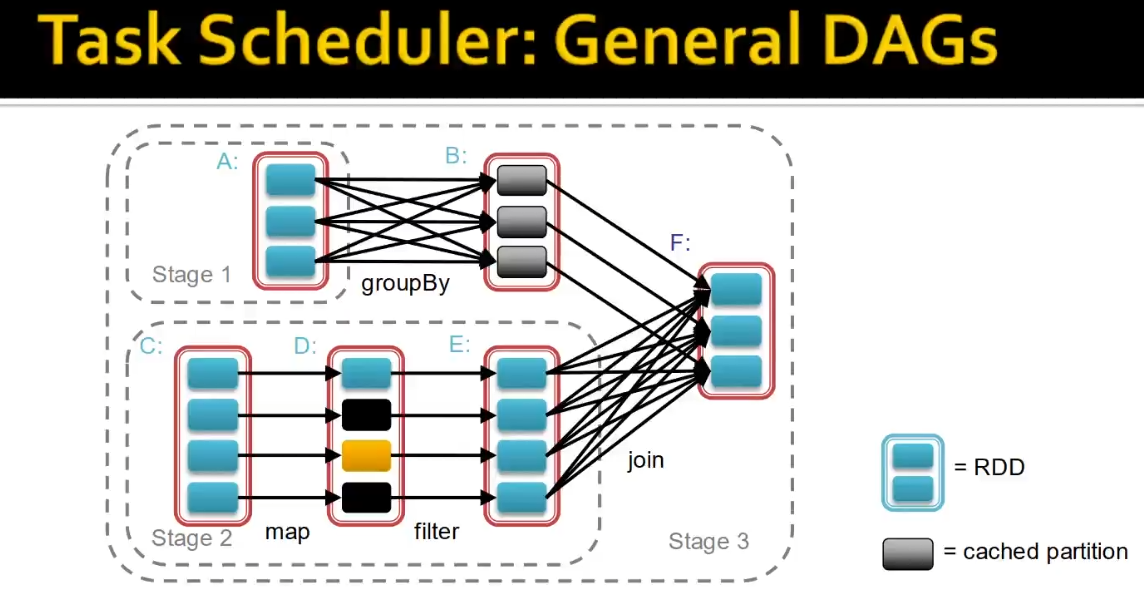
Large-scale Computing은 여러가지 문제를 가지고 있다.Computation의 분배가 적절히 이루어지지 않으면 업무의 효율이 떨어질 수 있다.분산한 프로그램들을 코딩하는 것이 어렵다. (개발이 편해야 한다)기계적인 결함이 발생할 수 있다.네트워크를 통해서
2.빅데이터응용
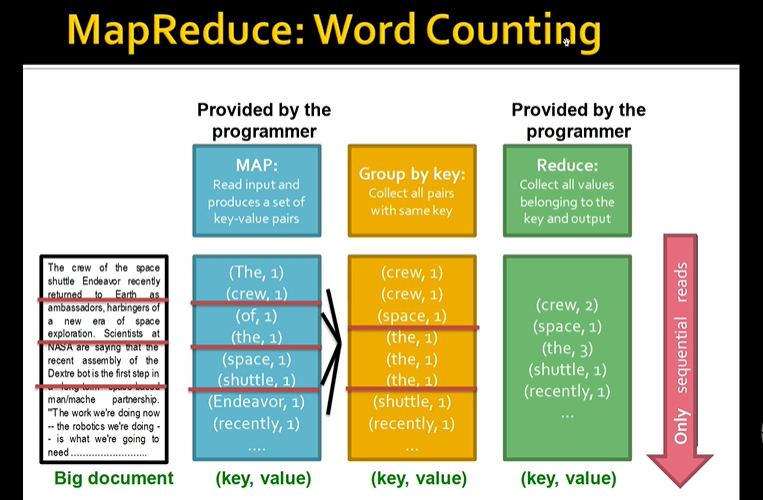
1\. 컴퓨터가 커다란 텍스트 파일을 분할하여 저장하고 있다.2\. 한번 쭉 읽어서 각각의 단어가 한번씩 나왔음을 의미하는 key-value 쌍을 만든다.3\. group by key를 하여 키 값이 같은 것끼리 묶어준다.4\. reduce를 실행하여 키 값이 같은 것
3.Association Rules & Naive Algorithms
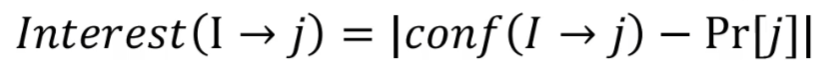
일종의 조건문a가 있다면 b가 있을 확률이 높다여기서 중대하거나 재미있는 규칙들에만 관심을 가질 것이다.$conf(I \\to j) = \\frac{support(I \\cup j)}{support(I)}$confidence가 높다고 해서 우리가 관심을 가지는 조건은
4.Locality Sensitive hashing
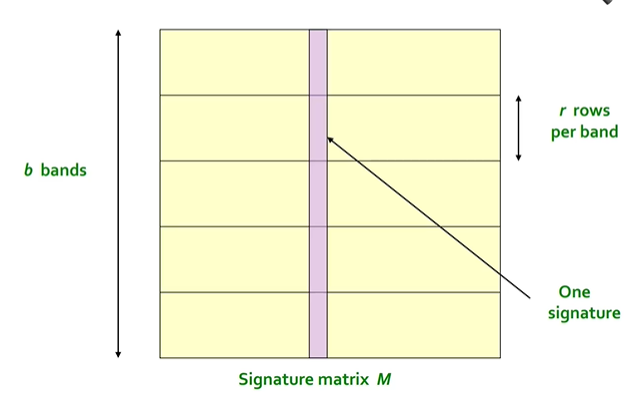
Step 1: Shingling -> Step 2: Min-hashing -> Step 3: Locality Sensitive Hashing목표: 자카드 유사도가 충분히 높은 문서들을 찾는 것아이디어: 시그니쳐들을 해싱함수를 통해서 버킷으로 보낸다 -> 이것을 통해서
5.Clustering

여러개의 데이터 포인트가 주어졌을 때, 몇 개의 정해진 클러스터로 그룹핑해주는 과정같은 클러스터에 속해있는 데이터는 유사한 데이터다른 클러스터에 속해있는 데이터는 유사하지 않은 데이터주로 distance measure를 이용하여 판단한다. (ex: 자카드 distanc