Distributed Computing for Data Mining
Large-scale Computing은 여러가지 문제를 가지고 있다.
- Computation의 분배가 적절히 이루어지지 않으면 업무의 효율이 떨어질 수 있다.
- 분산한 프로그램들을 코딩하는 것이 어렵다. (개발이 편해야 한다)
- 기계적인 결함이 발생할 수 있다.
네트워크를 통해서 데이터를 주고 받으면 문제가 발생한다.
idea:
- 각 컴퓨터들에게 데이터가 아닌 계산을 준다.
- 똑같은 파일을 여러곳에 복사해서 저장을 해둔다.
- 하둡
일부 노드가 고장났을때, 데이터를 어떻게 아무 문제 없이 저장할 수 있을까?
idea: 파일을 분산 저장하는 시스템을 사용하자
파일의 크기가 크고, 업데이트가 적은 데이터에 사용한다.
Distributed File System(분산 파일 시스템)
chunks(덩어리)들로 나눠져서 파일이 저장된다.
chunk servers: 데이터의 덩어리들을 담고 있는 서버
master node: 각 chunk가 어디에 있는 지 나타내는 메타데이터
- chunk server 하나가 무너져도 나머지 서버들 중에서 중복되어 저장된 정보들이 있어서
데이터가 무너지지 않고 유지된다
MapReduce
1) 쉬운 병렬화 작업 가능
2) 하드웨어나 소프트웨어에 대한 유지보수에 신경을 쓸필요 없다.
3) 빅데이터에 대해서 쉽게 관리 가능하다.
4) 여러개의 맵리듀스가 동신에 병렬적으로 사용 가능하다.
개요
1) Map: 사용자가 쓴 map function을 이용한다.
2) Group by key: map에서 결과로 나온 키값쌍을 모아서 셔플한다.
3) Reduce: 사용자가 쓴 reduce function으로 그룹화된 키값쌍에 적용한다.
장점
1) 입력데이터를 적절하게 분할할 수 있다.
2) 프로그램을 균등하게 일을 처리하도록 스케쥴링해준다.
3) 그룹화키 단계가 자동적으로 수행된다.(bottleneck이 발생함)
4) 머신이 망가져도 처리해준다.
단점
MapReduce를 여러번 하게 되면 내부의 map-group by key-reduce 사이클을 반복해야 한다.
(오버헤드가 많아짐)
퍼포먼스상의 병목현상이 생길 수 있다.
-> 커다란 어플리케이션에 잘 어울리지 않는다.
Data-Flow Systems
Mapreduce => map-> reduce로 구성된다.
일반적인 데이터플로우 시스템은 일반화되어서 자유로움
Spark
MapReduce의 확장버전
가장 인기있는 Data-Flow Systems
MapReduce모델에 국한되지 않고 다양한 모델이 있음
RDD(Resilient Distributed Dataset): 회복력이 있는 분산된 데이터셋
장점
1. 빠르게 데이터를 공유함(디스크에 쓰지 않고 캐시에서 가져옴)
2. DAGs(Directed Acyclic Graph): 데이터를 한방향으로 흐르게 하여 recovery를 쉽게함
방향성이 있고 사이클이 없다.
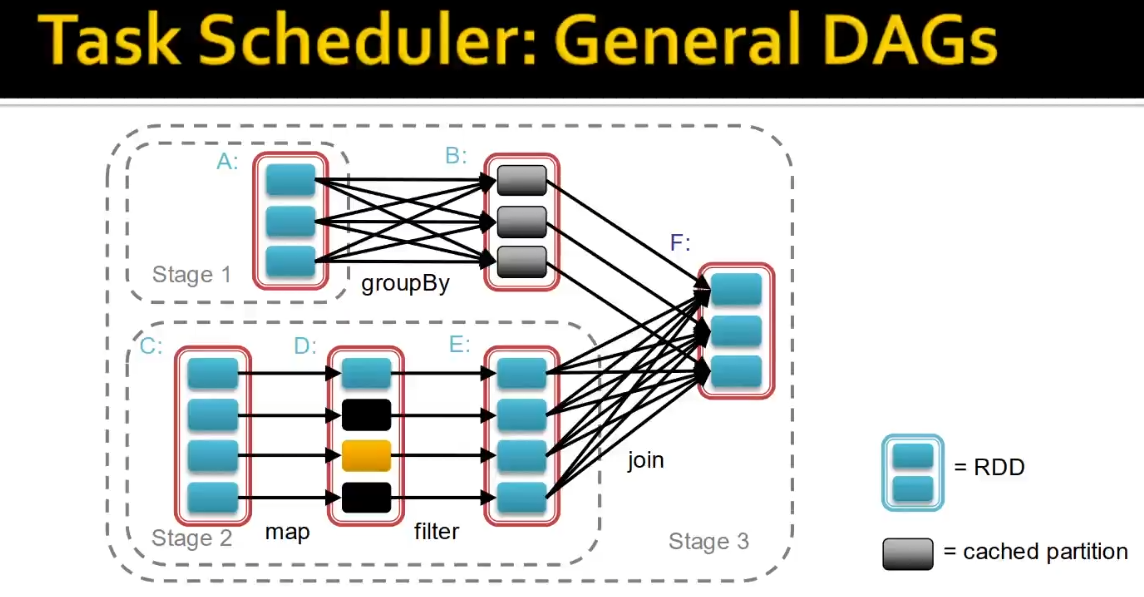
3. 더 풍부한 함수를 제공한다.
RDD
mapreduce의 키-값 쌍을 일반화한 형태 / 여러가지 값들을 받아드림
가급적 메모리 상태에서 작업하려고함(디스크에 쓰지 않으려고 함)
1) Transformation : RDD에 operation을 적용하여, 또 다른 RDD를 만들어냄
deterministic한 operation을 주로 사용함
(map, filter, join, union, intersection, distinct
Lazy evaluation: action전까지 절대로 계산을 하지않음
2) Action: 값을 도출해냄
count, collect, reduce, save
이때 실제로 평가를 하고 값이 취함
DataFrame
이름과 열로 되어있는 relation table형태이다
Dataset
데이터프래임을 좀더 확장한 형태
두개 모두 RDD로 변환가능하다.
Spark vs Hadoop MapReduce
spark이 일반적으로 빠르다.
하지만 엄청나게 많은 메모리를 사용한다. 메모리가 크지 않으면 성능이 저하됨
적은 양의 데이터 일수록 하둡이 유리하다.
프로그래머 입장에서는spark이 훨씬 쉽다