연관규칙
일종의 조건문
a가 있다면 b가 있을 확률이 높다
여기서 중대하거나 재미있는 규칙들에만 관심을 가질 것이다.
Confidence(신뢰도, 확신)
confidence가 높다고 해서 우리가 관심을 가지는 조건은 아니다
필요조건일 뿐이다
Interest(흥미)
흥미로운 규칙은 적어도 0.5이상이 되어야 한다.
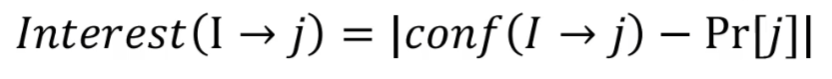
Mining Association Rules
Step1: Find all frequent itemsets
Step2: Rule generation
Step3: output the rules above the confidence threshold
Compacting the Output
Maximal(자신 보다 자세하지 않고 threshold를 넘으면 만족)
Closed(자신 보다 자세한 것의 support가 자신보다 작아야 만족)
Find Frequent Itemsets Algorithm
main-memory bottleneck
뭐든 페어에 대한 저장공간이 필요해서 메모리에 문제가 생김
find frequent pairs
가장 간단한 itemsets 물론 하나 짜리도 있지만 이것은 연관규칙을 찾을 수는 없음\
Naive Algorithm
일일이 다 세는 알고리즘 많은 메모리가 필요하다. 아예 관련없는 것도 저장하는 단점이 있음
진짜로 등장하는 것만 저장하는 접근방식 카운트를 저장한다.
그러면 하나의 메모리가 커져서 불리 할 수 있음
개발자로 공부하며 느낀 여러가지 경험들