
AI 서비스 개발 기초
소프트웨어 엔지니어링
모듈성
모듈 : 고유한 목적, 기능을 가지는 단위
각 모듈이 서로 영향을 주지 않고 쉽게 교체가능하게끔 독립적으로 설계하는 것을 의미한다.
(함수의 집합 == 모듈)
응집도
응집도 : 시스템의 모듈 구성 요소가 목적을 달성하기 위해 관련되어 있는 정도
각 모듈내의 함수가 서로 엮여서 동작한다. 각 모듈의 구성요소가 목적을 달성하기 위한 정도
결합도
결합도 : 모듈들의 상호 의존성
각 모듈들의 상호 의존성을 나타낸다.
소프트웨어 지향성
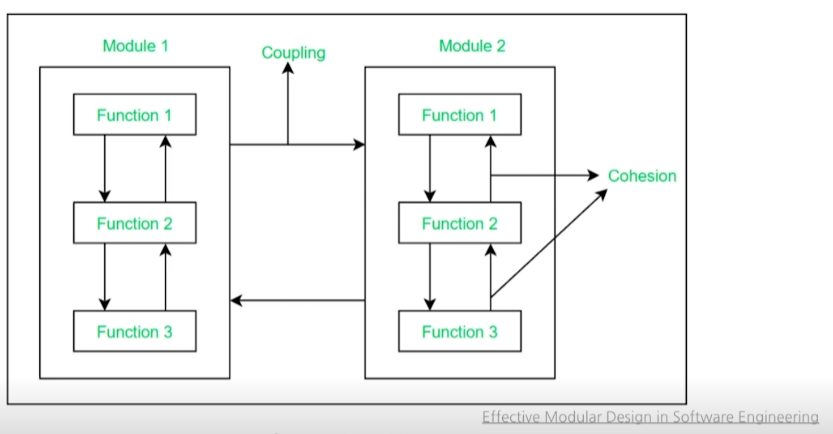
응집도 ↑ 모듈성 ↓ 소프트웨어를 지향한다.
테스팅 종류
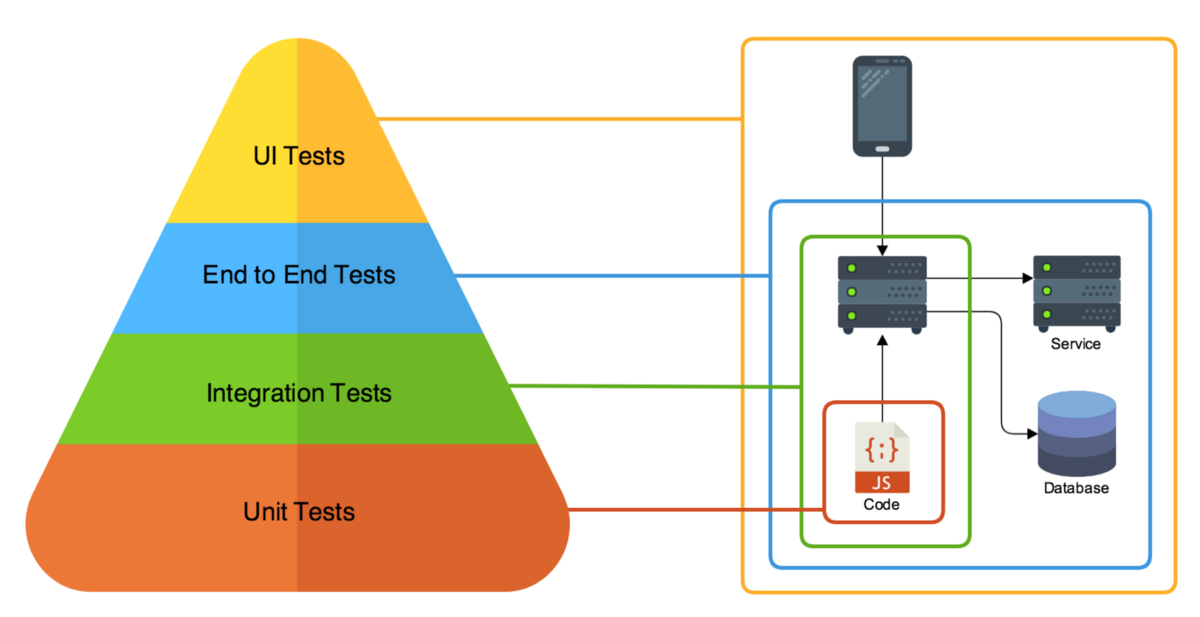
Unit Test : 개별 단위 테스트
Integration Test : 다른 단위, 구성요소 동작 테스트
End to End Test : 처음부터 끝까지 모두 테스트
Performance Test : 성능 부하 테스트
Docker
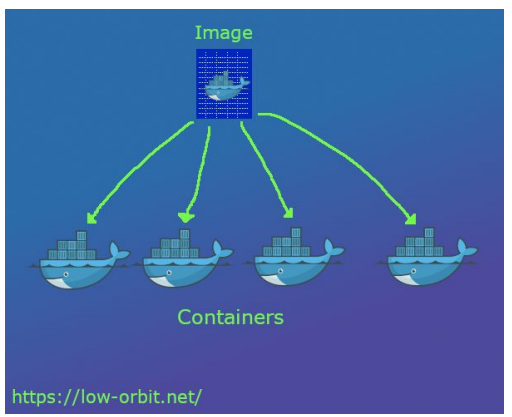
가상화
가상화 : 개발을 진행한 환경과 서비스의 환경이 다를 경우 OS등이 다르기 때문에 동일한 서버 셋팅이 필요함
Docker 등장 전
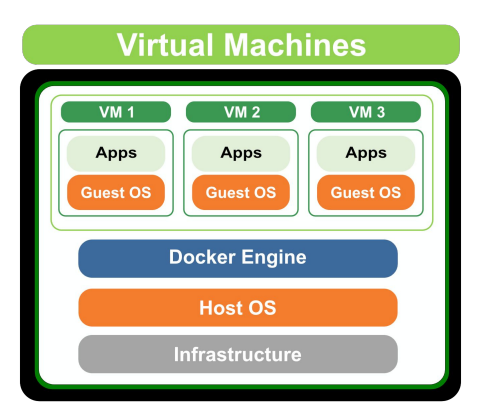
Virtural Machine : Docker 등장전에는 주로 가상화 기술로 VM을 사용하였다.
OS위에 새로운 OS를 실행시킴으로써 굉장히 무겁데 되었다.
Container : VM의 무거움을 덜어주면서 가상화를 프로세스의 개념으로 만들어 주었다.
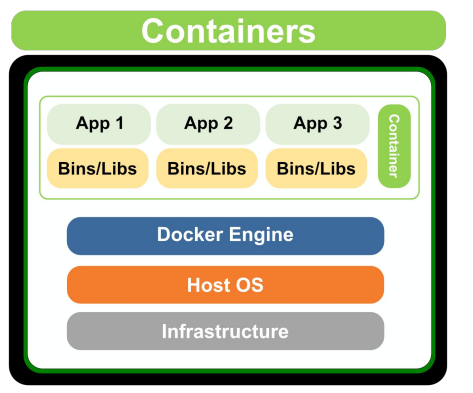
Docker
Docker의 장점으로는 언제 어디서나 OS의 상관없이 다른 사람이 만든 소프트웨어를 바로 사용할 수 있다.
Docker Image : Read Only로써 일종의 템플릿이다(iso파일과 유사).
Docker Container : Write로써 Docker Image를 활용하는 것으로 일종의 인스턴이스이다.
- Docker 이미지 다운로드 : docker pull “이미지이름:태그”
- Docker 이미지 확인 : docker images
- Docker 이미지 실행 : docker run “이미지이름:태그”
- Docker 컨테이너 목록 확인 : docker ps
- Docker 컨테이너 진입 : docker exec -it "컨테이너 ID"
- Docker 컨테이너 중지 :docker stop "컨테이너 ID"
- Docker 컨테이너 삭제 : docker rm "컨테이너 ID"
Docker Image 만들기
Dockerfile 만들기
- FROM : 베이스 이미지 지정
- COPY : 로컬에 있는 파일들을 컨테이너 내부로 복사
- WORKDIR : RUN,CMD등을 실행할 컨테이너 내의 디렉토리 지정
- RUN : RUN으로 실행할 리눅스 명령어들을 지정
- CMD : 이미지 실행 시 바로 실행할 명령어 지정
FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-runtime COPY . /temp WORKDIR /temp ENV PYTHONPATH=/temp ENV PYTHONUNBUFFERED=1 RUN pip install pip==23.0.1 && \ pip install poetry==1.2.1 && \ poetry export -o requirements.txt && \ pip install -r requirements.txt CMD ["python", "main.py"]
- Docker 이미지 빌드 : docker build “Dockerfile이 위치한 경로” -t “이미지이름:태그"
- Docker 이미지 실행 : docker run "이미지 이름:태그"
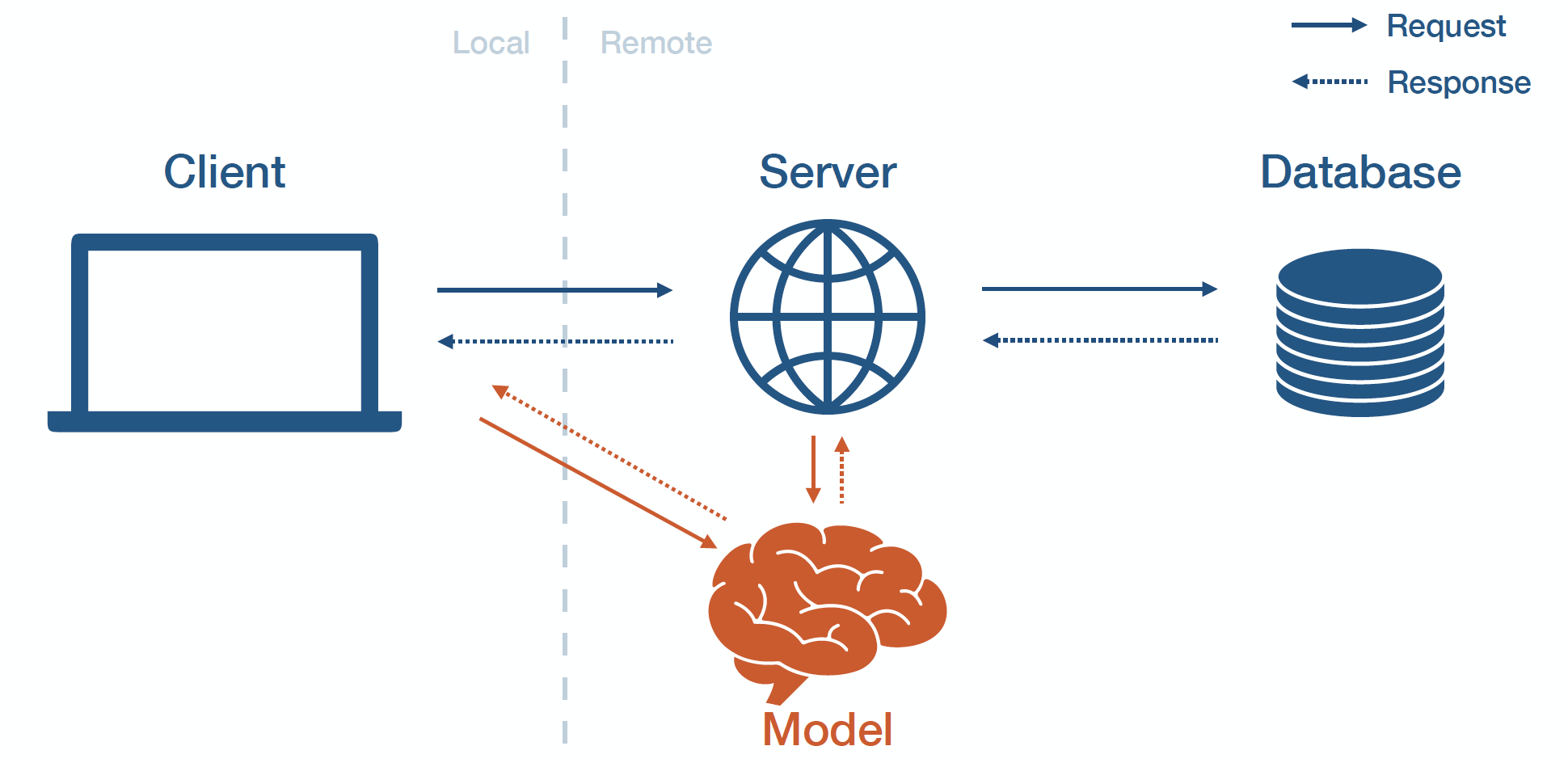
Model Serving
머신러닝 모델을 개발하고 웹이나 앱에 배포하는 작업
Oneline Serving
서버를 통하여 INPUT을 제공하며 서버에 Request할 경우 Respones하는 서버 시간이 굉장히 중요하게 되며 지연시간을 최소화시키는 것이 중요하다
이때 각종 API(FastAPI)나 Cloud(AWS),Serving 라이브러리(BentoML)가 들어가게 된다.

Batch Serving
특정 시간에 반복해서 실행하는 것으로 예로 30분에 1번씩 하루에 한번씩 실행해서 결과를 반환한다.
예) 멜론차트
웹 서비스 형태 - Streamlit
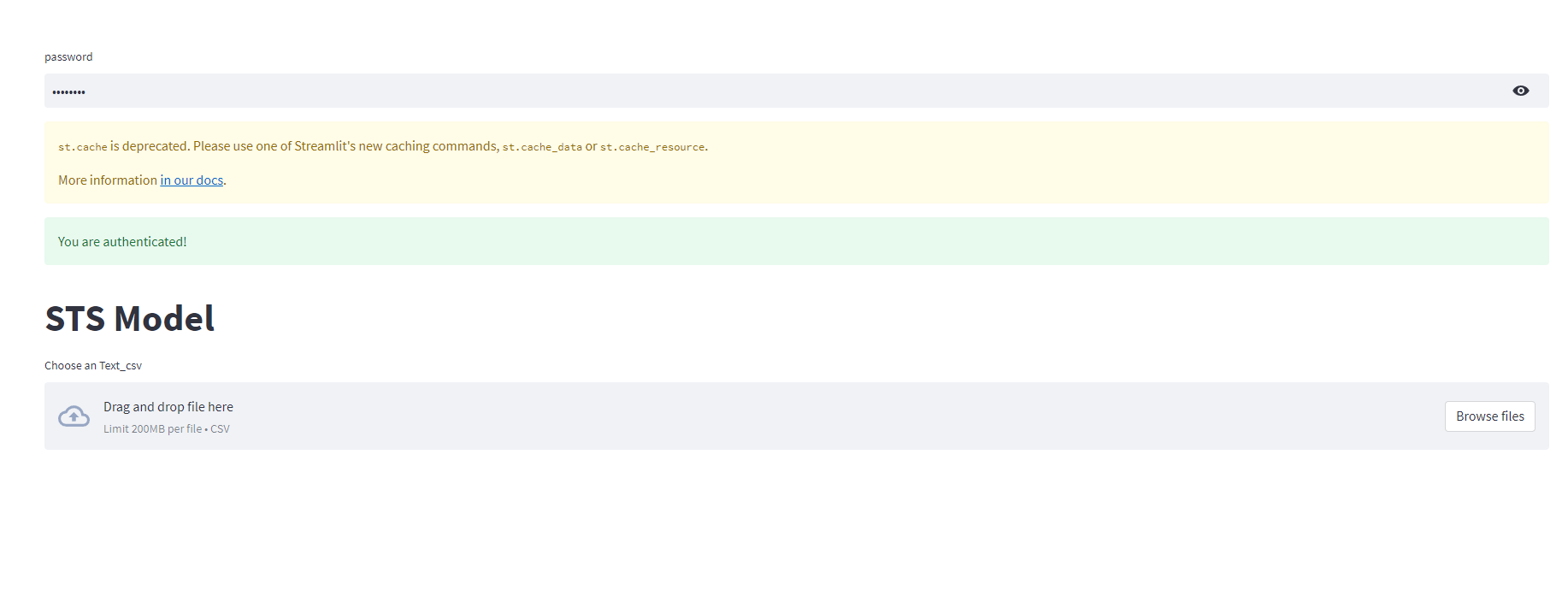
파이썬으로 작성되며 백엔드 및 HTTP 요청 구현을 하지 않아도 작동된다.
다양한 Component를 제공해 UI를 구성할수 있다.
DataFrame, Chart, Button등 기본적인 지원도 포함된다.
예시 코드 bert로 회기문제 풀기
app.py
#app.py
import pandas as pd
import streamlit as st
import yaml
from predict import load_model, get_prediction # , get_prediction
from confirm_button_hack import cache_on_button_press
# SETTING PAGE CONFIG TO WIDE MODE
st.set_page_config(layout="wide")
root_password = 'password'
def main():
st.title("STS Model")
with open("config.yaml") as f:
config = yaml.load(f, Loader=yaml.FullLoader)
model = load_model()
model.eval()
uploaded_file = st.file_uploader("Choose an Text_csv", type=["csv"])
if uploaded_file:
#text_bytes = uploaded_file.getvalue()
#image = Image.open(io.BytesIO(image_bytes))
text = pd.read_csv(uploaded_file)
st.write(text)
st.write("Predict")
score = get_prediction(model, text)
st.write(score)
@cache_on_button_press('Authenticate')
def authenticate(password) -> bool:
print(type(password))
return password == root_password
root_password = 'password'
password = st.text_input('password', type="password")
if authenticate(password):
st.success('You are authenticated!')
main()
else:
st.error('The password is invalid.')
confirm_botton_hack.py
import streamlit as st
import collections
import functools
import inspect
import textwrap
def cache_on_button_press(label, **cache_kwargs):
"""Function decorator to memoize function executions.
Parameters
----------
label : str
The label for the button to display prior to running the cached funnction.
cache_kwargs : Dict[Any, Any]
Additional parameters (such as show_spinner) to pass into the underlying @st.cache decorator.
Example
-------
This show how you could write a username/password tester:
>>> @cache_on_button_press('Authenticate')
... def authenticate(username, password):
... return username == "buddha" and password == "s4msara"
...
... username = st.text_input('username')
... password = st.text_input('password')
...
... if authenticate(username, password):
... st.success('Logged in.')
... else:
... st.error('Incorrect username or password')
"""
internal_cache_kwargs = dict(cache_kwargs)
internal_cache_kwargs['allow_output_mutation'] = True
internal_cache_kwargs['show_spinner'] = False
def function_decorator(func):
@functools.wraps(func)
def wrapped_func(*args, **kwargs):
@st.cache(**internal_cache_kwargs)
def get_cache_entry(func, args, kwargs):
class ButtonCacheEntry:
def __init__(self):
self.evaluated = False
self.return_value = None
def evaluate(self):
self.evaluated = True
self.return_value = func(*args, **kwargs)
return ButtonCacheEntry()
cache_entry = get_cache_entry(func, args, kwargs)
if not cache_entry.evaluated:
if st.button(label):
cache_entry.evaluate()
else:
raise st.script_runner.StopException
return cache_entry.return_value
return wrapped_func
return function_decoratorpredict.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import AutoModelForSequenceClassification
from dataset import CustomDataset
def load_model():
model = AutoModelForSequenceClassification.from_pretrained(
'kykim/electra-kor-base', num_labels=1, ignore_mismatched_sizes=True)
return model
def get_prediction(model,csv):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
test_text_dataset = CustomDataset(
data_file=csv,
state="test",
text_columns=["sentence_1", "sentence_2"],
target_columns=None,
delete_columns=None,
max_length=256,
model_name="kykim/electra-kor-base",
)
test_dataloader = DataLoader(
dataset=test_text_dataset,
batch_size=4,
num_workers=0,
shuffle=False,
drop_last=False,
)
score = []
model.to(device)
model.eval()
with torch.no_grad():
for batch_id, x in enumerate(tqdm(test_dataloader)):
y_pred = model(x["input_ids"].to(device))
logits = y_pred.logits
y_pred = logits.detach().cpu().numpy()
score.extend(y_pred)
score = list(float(i) for i in score)
# output = pd.read_csv(config["data_folder"]["submission"])
# output["target"] = score
# output.to_csv(f"./output/{model_name}.csv", index=False)
return score
dataset.py
import pandas as pd
import torch
from tqdm.auto import tqdm
from transformers import AutoTokenizer
class CustomDataset(torch.utils.data.Dataset):
def __init__(
self,
data_file,
state,
text_columns,
target_columns=None,
delete_columns=None,
max_length=512,
model_name="klue/roberta-small",
):
self.state = state
#self.data = pd.read_csv(data_file)
self.data = data_file
self.text_columns = text_columns
self.delete_columns = delete_columns if delete_columns is not None else []
self.max_length = max_length
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
if self.state == "test":
self.inputs = self.preprocessing(self.data)
else:
self.target_columns = target_columns if target_columns is not None else []
self.inputs, self.targets = self.preprocessing(self.data)
def __getitem__(self, idx):
if self.state == "test":
return {"input_ids": torch.tensor(self.inputs[idx])}
else:
if len(self.targets) == 0:
return torch.tensor(self.inputs[idx])
else:
return {
"input_ids": torch.tensor(self.inputs[idx]),
"labels": torch.tensor(self.targets[idx]),
}
def __len__(self):
return len(self.inputs)
def tokenizing(self, dataframe):
data = []
for _, item in tqdm(
dataframe.iterrows(), desc="Tokenizing", total=len(dataframe)
):
text = "[SEP]".join(
[item[text_column] for text_column in self.text_columns]
)
outputs = self.tokenizer(
text,
add_special_tokens=True,
padding="max_length",
truncation=True,
max_length=self.max_length,
)
data.append(outputs["input_ids"])
return data
def preprocessing(self, data):
inputs = self.tokenizing(data)
if self.state == "test":
return inputs
else:
try:
targets = data[self.target_columns].values.tolist()
except:
targets = []
return inputs, targets
실행 결과

주간 회고
대회가 끝나고 모델 서빙에 대해 쉬면서 배운것 같다. 최종프로젝트에는 내가 직접 백엔드나 프론트를 구현하진않을것같지만 기본적이고 기초적인 모델 서빙에 대해 배울 수 있었다. 또한 글에는 포함되지 않지만 모듈화와 서빙에 대해 추가적으로 배울 수 있었으며 직접 간단한 서빙을 해봄으로써 배울점이 많은 것 같다. 리서치 말고 엔지니어링 쪽도 재밌어 보인다. 이번 한주동안은 대회 종료 후 쉬면서 했기때문에 어느정도 힐링이었던 주가 된거 같다 다음 관계분석 대회때 다시 돌아도록 하겠다.
