[전체 논문 리뷰]Attention Is All You Need
*본 템플릿은 DSBA 연구실 이유경 박사과정의 템플릿을 토대로 하고 있습니다.
1. 논문이 다루는 Task
- Task: Recurrent와 Convolution을 배제한 Attention 메커니즘 모델 Transformer
이전의 시퀀스 변형 모델은 RNN과 CNN을 기반으로 인코더와 디코더를 포함한다. Attention 모델에서 인코더와 디코더를 연결하는 역할을 했다. 논문에서는 RNN과 CNN을 배제한 어텐션 기반의 트랜스포머를 제안했다.
💡 상세 설명 :-
batch 안의 데이터는 sequence length가 유사한 문장 쌍으로 결정한다.
-
문장의 시작에토큰, 끝에 토큰을 추가한다.
-
학습에서 source 문장은 encorder의 입력, target 문장은 decorder의 입력이다.
-
batch에서 가장 긴 sequence의 길이를 기준으로 패딩한다.
-
source의 batch 중 최대 문장 길이와 target의 batch 중 최대 문장 길이가 다를 수 있다.
WMT 2014 English-German dataset 450만 문장 쌍
- byte-pair encoding 사전은 37000 토큰
Input: English
input size: (batch size, source_max_len) = (batch 내의 문장의 수, source batch 내의 최대 문장 길이)
'''
input = ['<sos>','a', 'man', 'standing', 'at', 'a', 'urinal', 'with', 'a', 'coffee', 'cup', '.', '<eos>', '<pad>', '<pad>']
'''- Output: German output size: (batch size, target_max_len) = (batch 내의 문장의 수, target batch 내의 최대 문장 길이)
'''
output = ['<sos>', 'ein', 'mann', ',', 'der', 'mit', 'einer', 'tasse', 'kaffee', 'an', 'einem', 'urinal', 'steht', '.', '<eos>', '<pad>', '<pad>']
'''- WMT 2014 English-French dataset 3600만 문장 쌍 32000개의 word-piece vocabulary
- Input: English
input size: (batch size, source_max_len) = (batch 내의 문장의 수, source batch 내의 최대 문장 길이) - Output: French (batch size, max_len) output size: (batch size, target_max_len) = (batch 내의 문장의 수, target batch 내의 최대 문장 길이)
training batch는 25000개의 소스 토큰과 25000개의 타켓 토큰이 포함되었다.
2. 기존 연구 한계
1️⃣ 시퀀스구조의 한계
병렬적인 학습 어려움
RNN(LSTM, GRU)은 특히 시퀀스 모델링과 기계번역에 많이 사용했다. 순환 모델은 입력과 출력 시퀀스의 위치에 따라서 계산을 수행한다. 현재의 포지션 t에서 입력으로 이전 히든 스테이트ht-1에서 입력을 받아서 현재 히든 스테이트 ht를 생성한다. 이러한 순차적인 시퀀스의 특징은 훈련에서 일괄처리가 제한되고 병렬적인 학습이 어렵다. 논문은 어텐션 메커니즘에 주목했다. 기존의 시퀀스 모델은 어텐션 메커니즘을 적용하여 입력과 출력 시퀀스의 거리와 상관없이 데이터를 전달하였다. 대부분의 어텐션은 시퀀스 모델과 함께 쓰였고 논문에서는 시퀀스 모델과 어텐션을 분리하여 병렬적인 훈련이 가능하고 입력과 출력의 거리가 먼 경우에도 종속성을 모델링했다.
2️⃣ CNN 구조의 한계
시퀀셜 연산을 줄이기 위한 CNN 기반의 모델 Extended Neural GPU, ConvS2S, ByteNet이 있다. 입력과 출력을 hidden representation을 병렬로 계산한다. 이 모델들은 입력과 출력 위치에 따라서 연산 횟수가 ConvS2S는 선형적으로 ByteNet은 로그로 늘어난다. 따라서 입력과 출력의 거리가 멀어질수록 종속성을 학습하기 어렵다. 트랜스포머는 연산을 상수까지 낮추지만 averaging attention-weighted positions으로 성능이 떨어질 수 있다. 이는 멀티헤드 어텐션으로 극복했다.
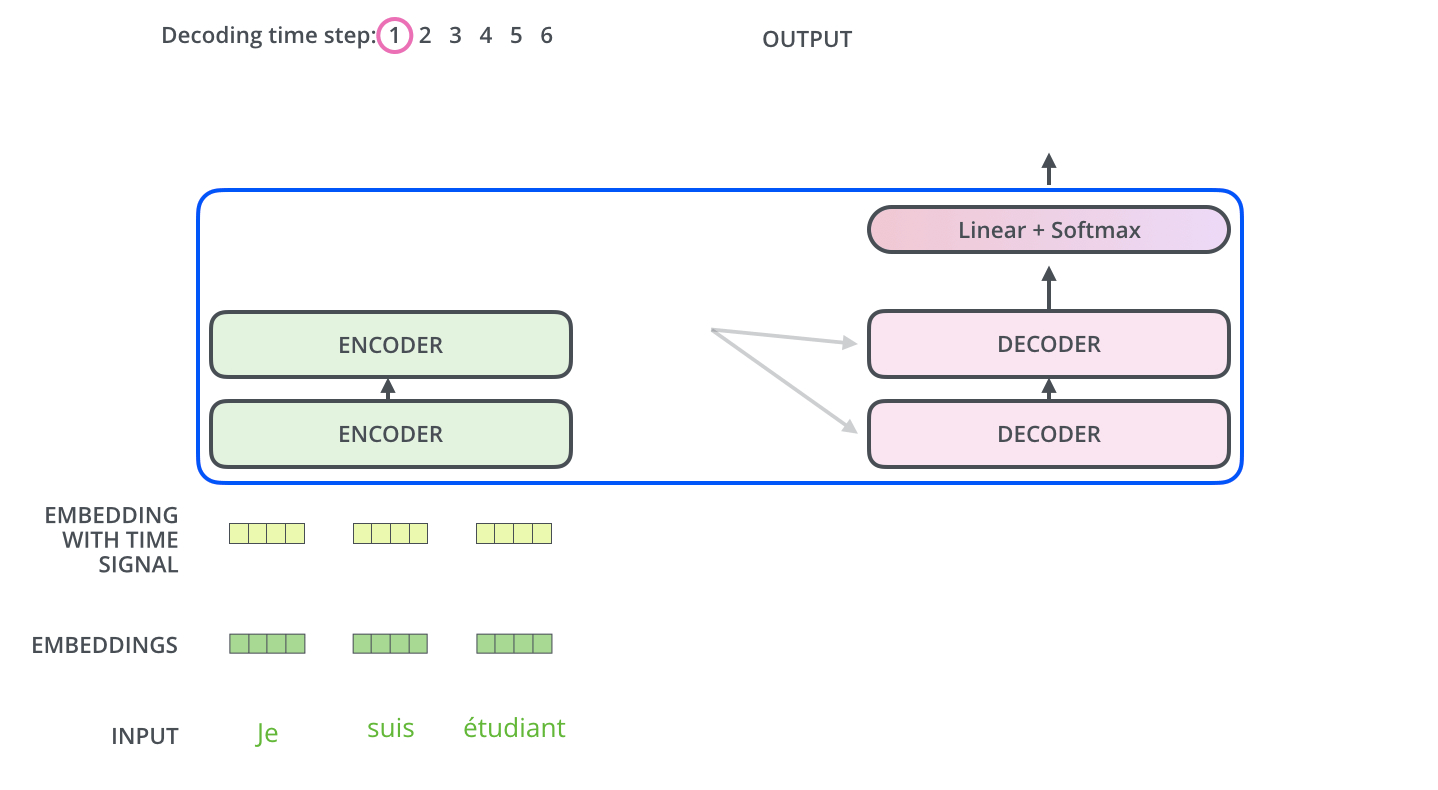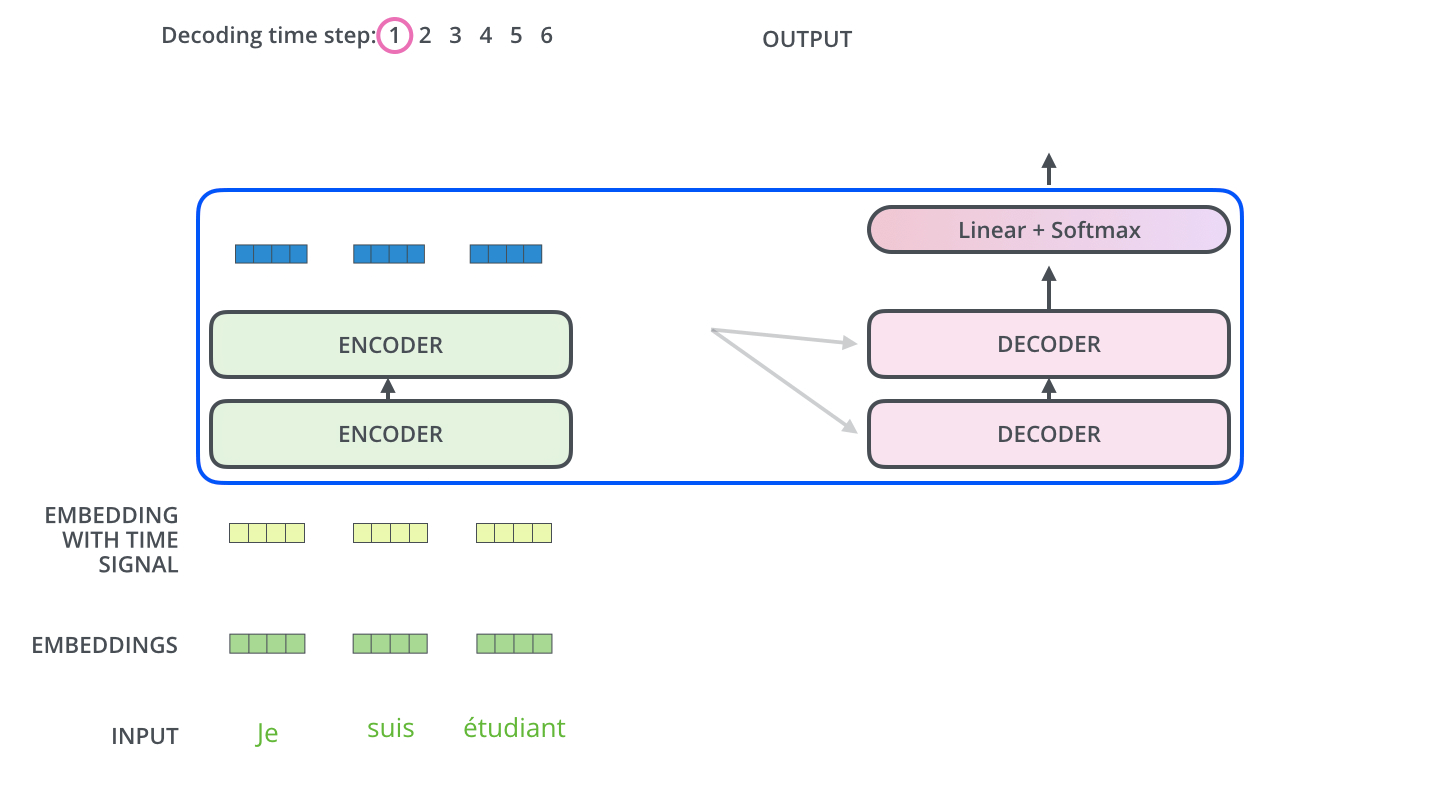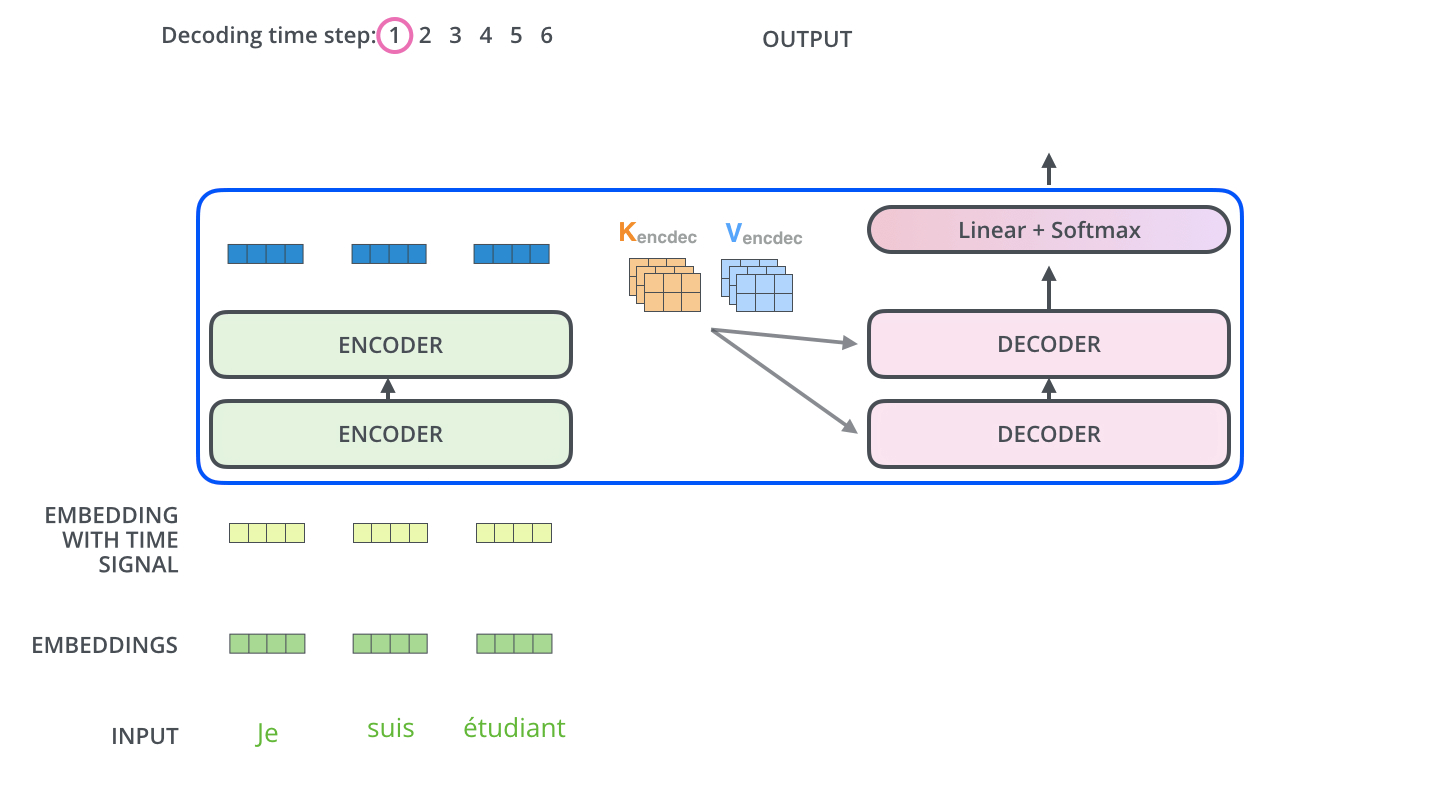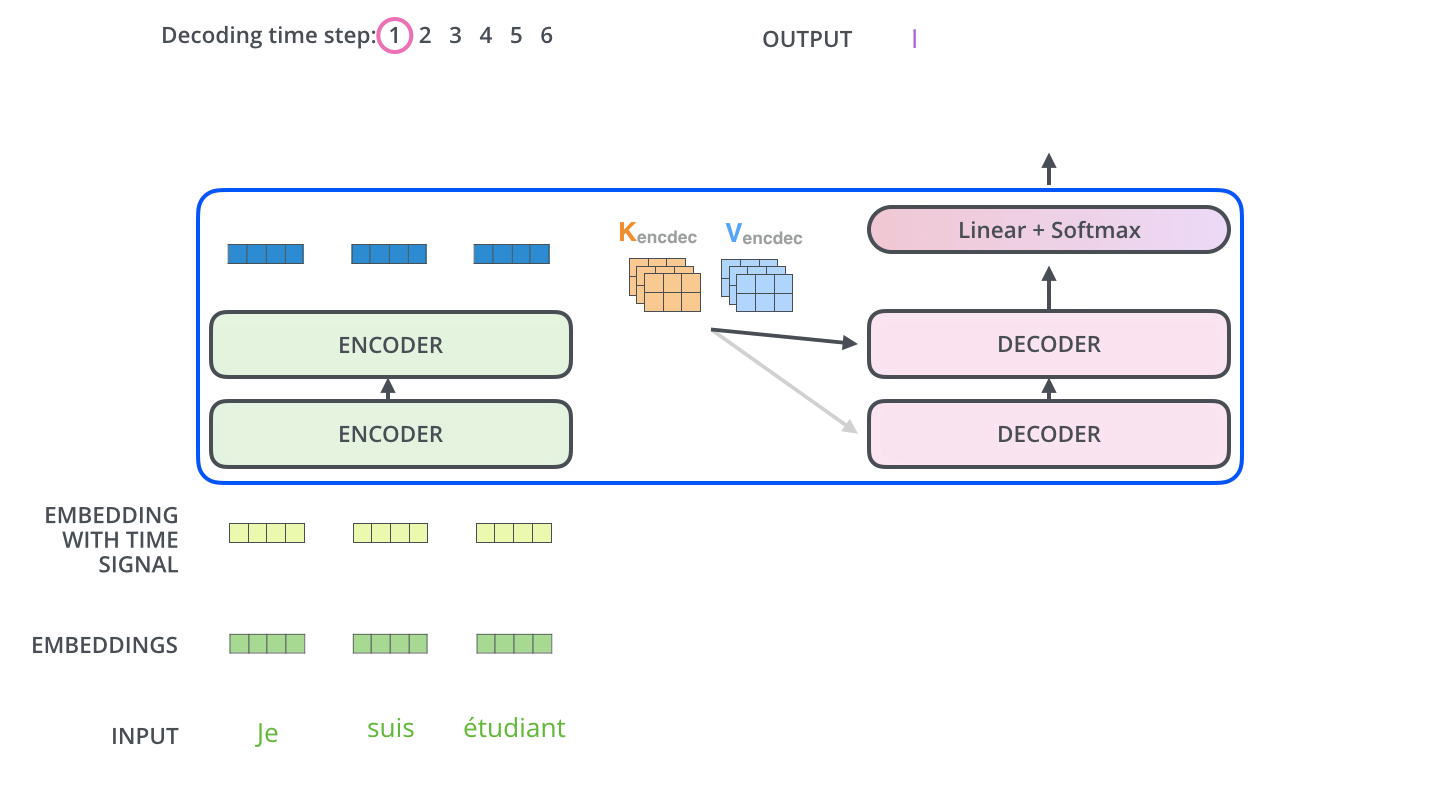
3. 제안 방법론:
Model Architecture
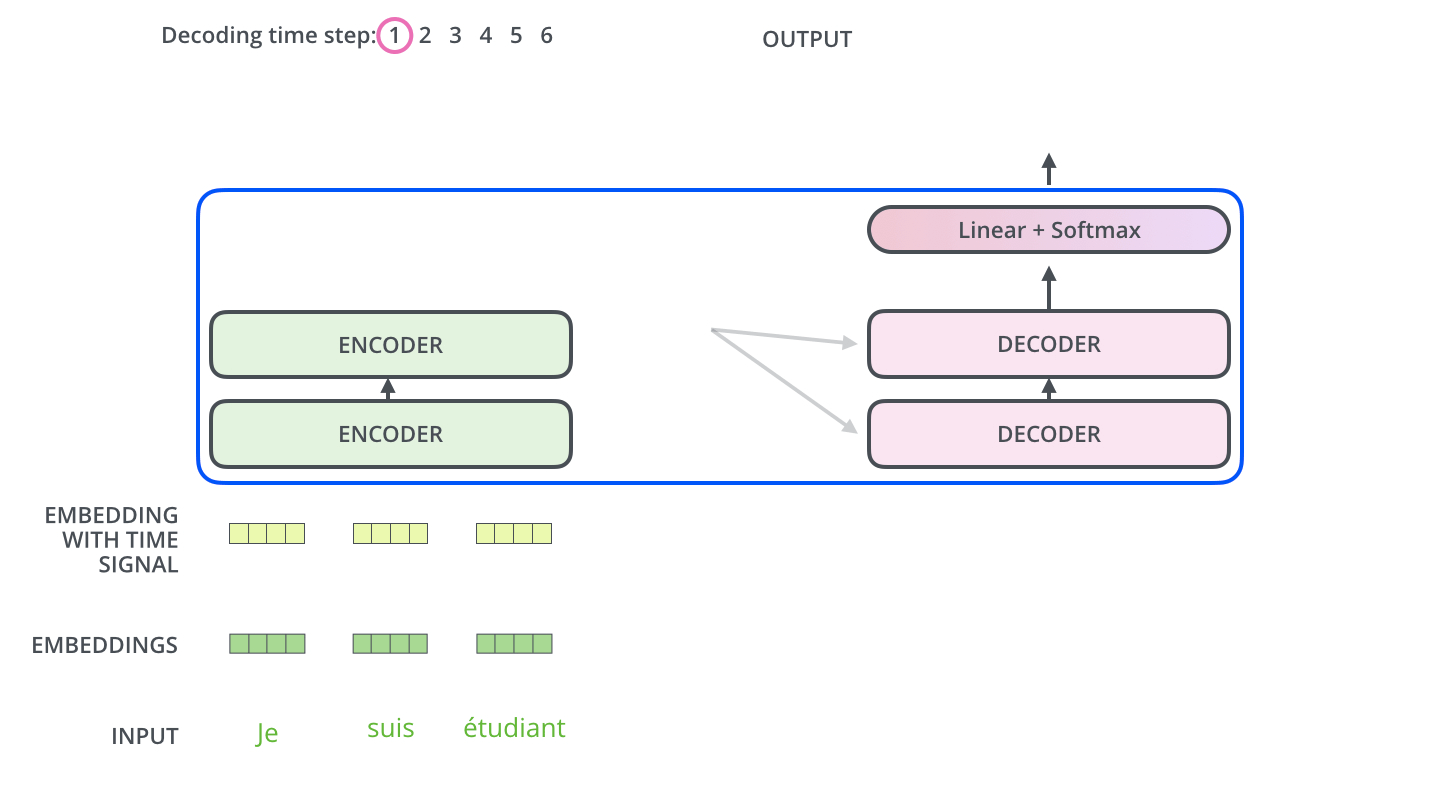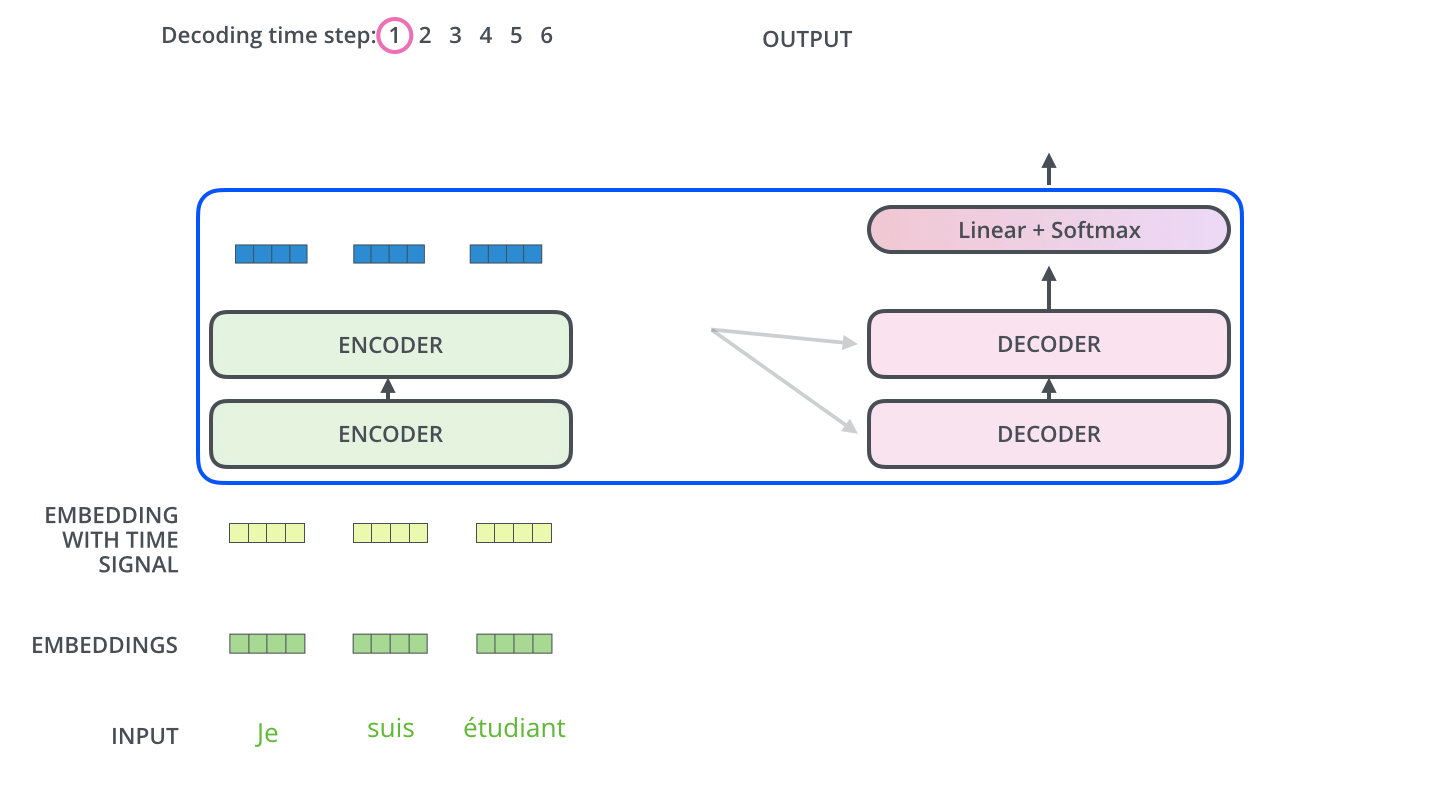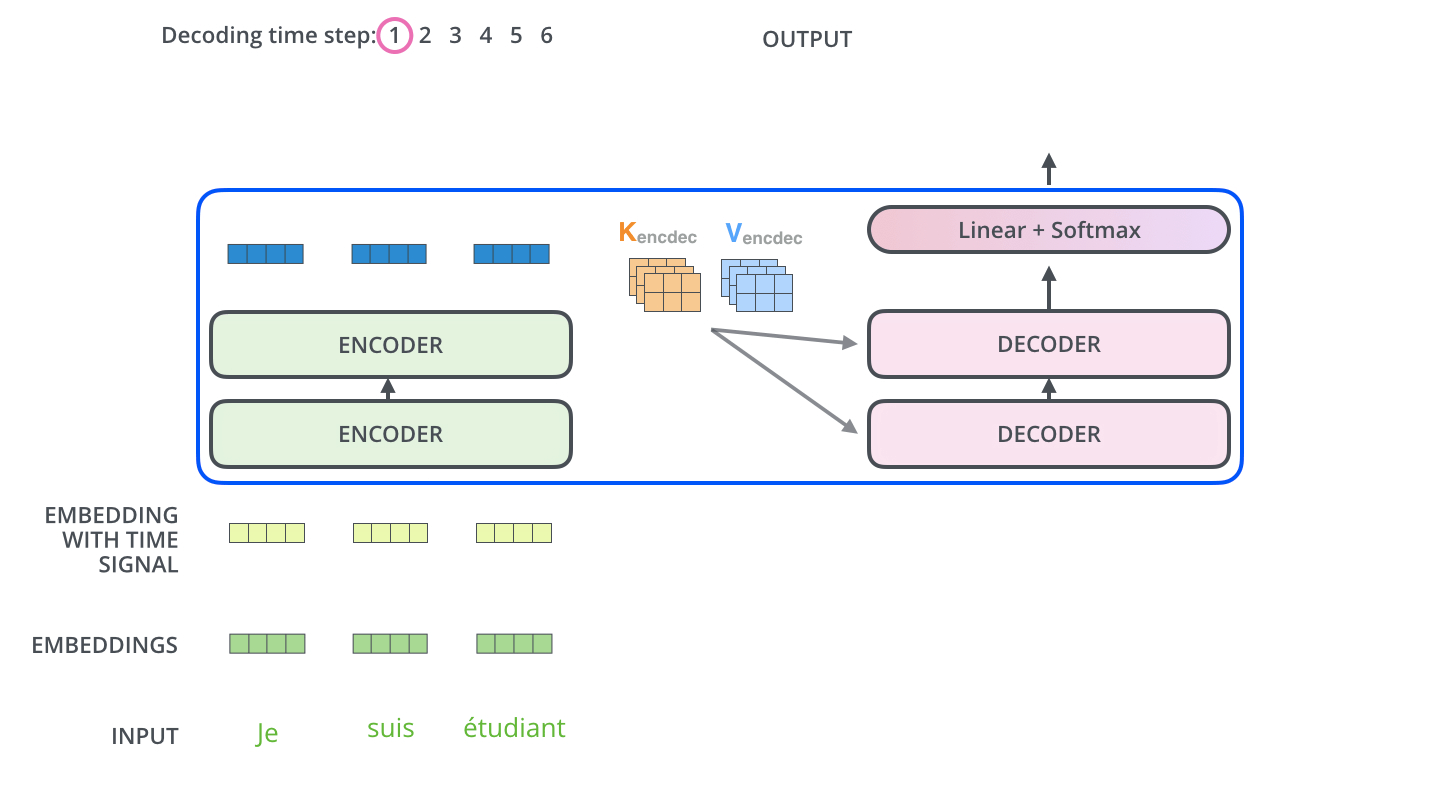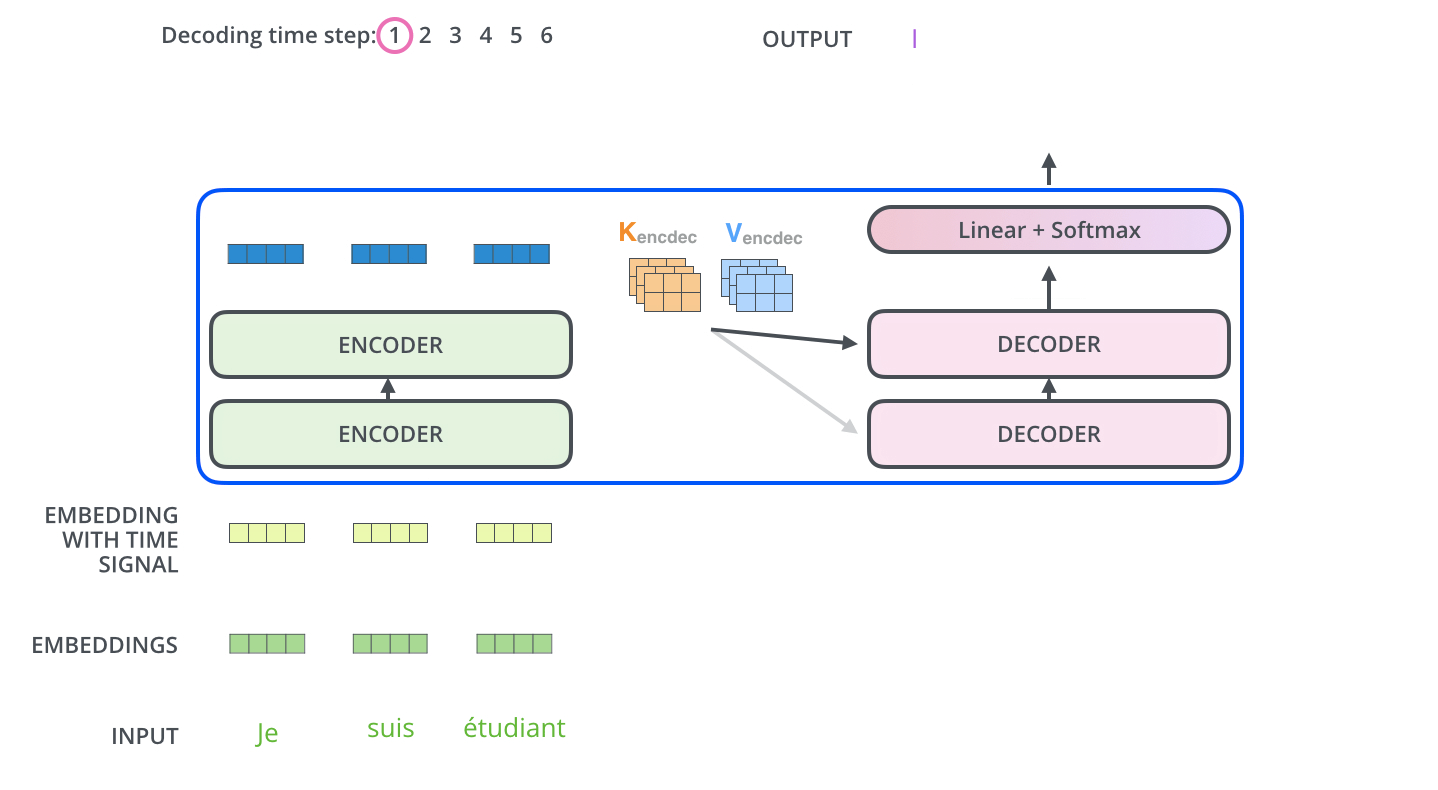
다른 시퀀스 변환 모델(Sequence Transduction Model)과 마찬가지로 Transformer도 Encoder-Decoder 구조를 따른다.
Encoder
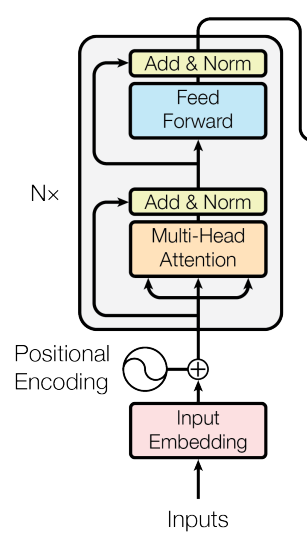
개의 동일한 레이어로 구성된다. 각 레이어는 두 개의 서브레이어(sub-layers)를 갖는데, 각각은 self-attention mechanism과 position-wise fully connected feed-forward network 레이어이다. 각 서브레이어는 잔차연결(residual connection)이 적용되어 있고, 이후 레이어 정규화(layer normalization)를 적용한다. 즉, 각 서브레이어의 출력은 이다. 함수는 서브레이어 이내에서 이루어지는 연산(Multi-Head Attention이나 Feed Forward)를 의미한다. 임베딩을 포함한 모든 서브레이어의 출력 차원은 이다.
Decoder
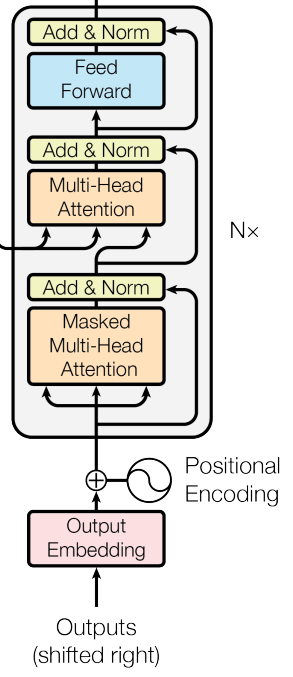
중앙에 위치한 세 번째 서브레이어가 존재한다는 것 외에는 잔차 연결, 레이어 정규화 등 인코더의 구조와 거의 유사하다. 이 서브레이어는 인코더층의 출력에 대한 멀티헤드 어텐션 연산을 수행한다. 디코더 층의 셀프 어텐션 서브레이어에는 마스킹이 적용되어 있다는 점이 또다른 차이점이다. 번째 position을 예측할 때, 이전의 출력만 참고할 수 있게 하는 역할을 위해서 구현하였다.
Attention and Scaled Dot-Product Attention
Attention 연산은 다음과 같이 정의된다.
특별히 논문의 attention 연산을 Scaled Dot-Product Attention이라고 부른다. Query와 Key는 차원을 갖고, Value의 차원은 이다. 각 query는 모든 keys와 내적을 수행하고, 로 나눈 후 softmax 함수를 적용한다. 이 결과는 각 value에 대한 weight에 해당한다.
흔히 사용되는 attention은 additive와 dot-product attention의 두 가지가 있다. 후자는 scaling factor만 제외하고는 논문의 연산과 동일하다. 이론적인 복잡도는 두 방법이 동일하지만, 실제 사용 시는 dot-product 연산이 훨씬 빠르고 공간 효율성이 우수하다.
논문에서 명시되지는 않았지만, BLAS, cuBLAS, MKL 등의 라이브러리가 행렬 곱셈을 최적화해준다고 한다.
의 값이 작으면 두 메커니즘의 성능은 유사한, 의 값이 커질수록 additive 메커니즘이 scaling factor를 사용하지 않는 dot-product의 성능을 능가한다. 내적의 값이 커질수록 softmax 연산의 결과가 극단적으로 작은 gradients를 갖게 하기 때문인데, 이런 효과를 상쇄하기 위해서 scaling factor를 사용한다.
Position-wise Feed Forward Networks
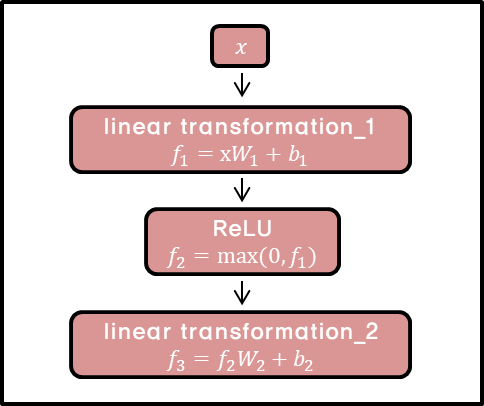
위 그림은 encoder와 decoder의 Feed Forward Layer의 구조를 나타낸 그림이다.
입력의 위치마다 개별적으로 적용되므로 position-wise이고, 같은 layer에서는 같은 W와 b의 파라미터 값을 공유하지만, layer별로 파라미터의 값이 달라진다.
Multi-head-attention

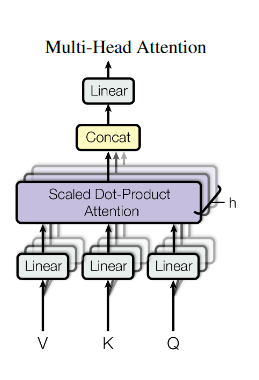
- Multi head attention은 Single attention보다 성능이 높다고 입증 되어있다.
- 기존의 Q,K,V를 각각 다르게 학습된 선형 레이어를 통하여 투영하는 것이다. 이럴 경우 최종 차원은 d_{v} 차원의 결과값이 나오게 된다. 이때 Head의 개수 만큼 차원이 나오면 이를 마지막 차원을 기준으로 concat 시킨다. 이때 단순히 옆으로 붙힌 벡터가 됨으로 이를 다시 정렬해주는 과정을 거치기 위해 최종적으로 선형 레이어에 투영시켜 정렬하는 과정을 거친다.
기존의 Single attention은 모델의 모든 위치에 대해 평균을 내야 함으로 시퀀스 내의 다른부분을 구별하는 능력이 감소하게 되는데 이를 여러 Head로 나누어 진행함으로써 서로 다른 하위 집합에 초점을 맞추어 토큰관 의 관계를 좀 더 다양하게 볼 수 있다. - 현 논문에서는 8개의 Head를 사용하며 로 진행된다.
- 이로써 8개의 attention map과 8개의 각각의 attention 레이어를 통과한 벡터가 나오게 된다.
- 이때 논문에서는 각 헤드마다 축소된 차원으로 인해 실제 총 계산 비용은 Single attention과 유사하다고 주장한다.
[batch_size,seq_len,hdim] ->
[batch_size,num_head,seq_len,(num_head//hdim)] -> 각 헤드마다 attention 수행
[batch_size,seq_len,num_head * (num_head//hdim)] ->
[batch_size,seq_len,hdim]
Embedding and Softmax
다른 sequence 변환 모델들과 같이 transformer 또한 input과 output의 토큰들을 embedding하는 과정을 거친다. 또한 decoder의 마지막 부분에서 attention layer의 출력을 선형 변환한 후, softmax 함수를 적용해 다음 토큰을 추정한다.
이 때 softmax 함수를 취하기 전 선형 변환에서 사용되는 가중치 행렬과 embedding layer의 가중치 행렬은 서로 값을 공유한다.
Positional Encoding
transformer는 recurrnt 모델이나 convolution 모델이 아니기 때문에 sequence의 위치 정보를 이용하기 위해서는 sequence의 토큰에 위치에 대한 정보를 주입해야한다. 이를 위해 본 연구에서는 아래와 같은 positional encoding 값을 embedding vector에 더해주었다.
위 수식에서 pos는 토큰의 위치이고, i는 차원을 의미한다.
는 의 선형 변환으로 나타낼 수 있기 때문에 모델이 두 토큰간에 상대적인 위치 정보를 쉽게 학습할 수 있다.
학습된 positional embedding을 사용하는 것과 위 방식처럼 sinusoidal 방식을 사용하는 것이 거의 비슷한 결과가 나오는 점과 학습시 주어졌던 가장 긴 길이의 문장보다 더 긴 문장이 inference 시 주어질 경우 문제가 될 수 있기 때문에 본 연구에서는 정적인 값을 embedding vector에 더해주는 sinusoidal version을 채택했다.
✨Contribution
- 논문에서 처음으로 RNN구조의 인코더-디코더 모델이 아닌 multi-headed self attention이라는 attention구조로한 sequence transduction model인 Transformer 모델을 제안하였다.
- 제안된 Transformer모델은 CNN, RNN을 베이스로한 모델보다 속도가 빠르고 적은 Training Cost가 들며, WMT 2014 English-to-German 그리고 WMT 2014 English-to-French Task의 SOTA를 달성할 정도로 성능의 우수성을 입증하였다.
4. 실험 및 결과
Dataset
- WMT 2014 English-German 데이터셋
- 450만개의 문장쌍 포함
- 인코딩 방식 : BPE ( Byte Pair Encoding) - source-target에서 공유된 37000 token
- WMT English-French 데이터셋
- 3600만개의 문장쌍
- 인코딩 방식 : 32000 word-piece token
- Training Batch : 25000개의 source token + 25000개의 target token으로 이루어짐
Training Details
1️⃣ Hardware and Schedule
-
GPU : NVDIA P100 GPU 8개
- Base model(Paper에서 서술된 파라미터 사용) :
- 각 training step = 0.4초
- 100000 step / 12시간 학습
- Big model ( table 3 참고)
- 각 training step = 1.0 초
- 300000 step / 3.5 days 학습
2️⃣ Optimizer
- Base model(Paper에서 서술된 파라미터 사용) :
-
Adam Otimizer 사용 - β1 = 0.9, β2 = 0.98 and ε = 10−9
- learning rate은 다음 공식에 따라 바꿔가며 활용
- learning rate은 다음 공식에 따라 바꿔가며 활용
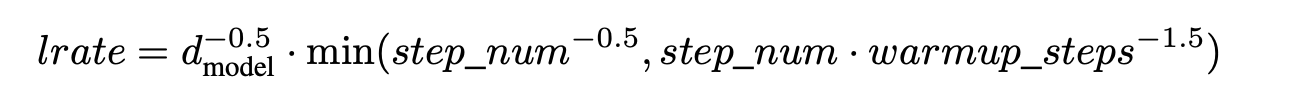
s까지 비례하여 선형적으로 증가, 이후에 step_number에 역제곱근에 비례하여 감소
s = 4000으로 설정
3️⃣ Regularization
- 3가지 종류의 Regularization을 적용함 ( Residual Dropout 2개, Label smoothing 1개
- Residual Dropout ()
- sub layer의 output에 적용(output이 다음 sub layer의 input과 normalize되기전에)
- Embedding의 합과 positional embedding에 dropout 적용
- Label smoothing ()
- perplexity를 증가시키지만 정확도와 BLEU Score를 개선함
- Residual Dropout ()
Result
1️⃣ Machine Trainslation
- Base model : 단일 모델로 마지막 5개의 checkpoint의 평균을 이용하였다
(각, checkpoints는 10분의 간격으로 기록)
- Big model : 마지막 20개의 checkpoint의 평균을 이용함
- 기타 세부 사항 :
- beam search 활용(beam_size=4), length penalty = 0.6
- 모든 hyperparmeter는 dev set으로 선택함
- output_length ≤ input_length+ 50
- WMT 2014 English-to-German Translation :
- Transformer(Big) 모델이 기존의 SOTA 모델의 BLEU점수를 +2.0넘어서는 새로운 SOTA BLEU Score 28.4점을 달성함 (3.5일/ 8개의 P100 GPU로 학습)
- Base model도 다른 기존에 발표된 모델과 앙상블된 모델들보다도 높은 성능을 자랑하며 적은 양의 훈련 cost가 들었음.
- WMT 2014 English-to-French Translation :
- Transformer(Big)은 기존의 모든 모델들을 넘어선 SOTA BLEU Score 41.0점을 달성했고, 동시에 Training Cost는 1/4 정도 보다 적게 활용하였음.
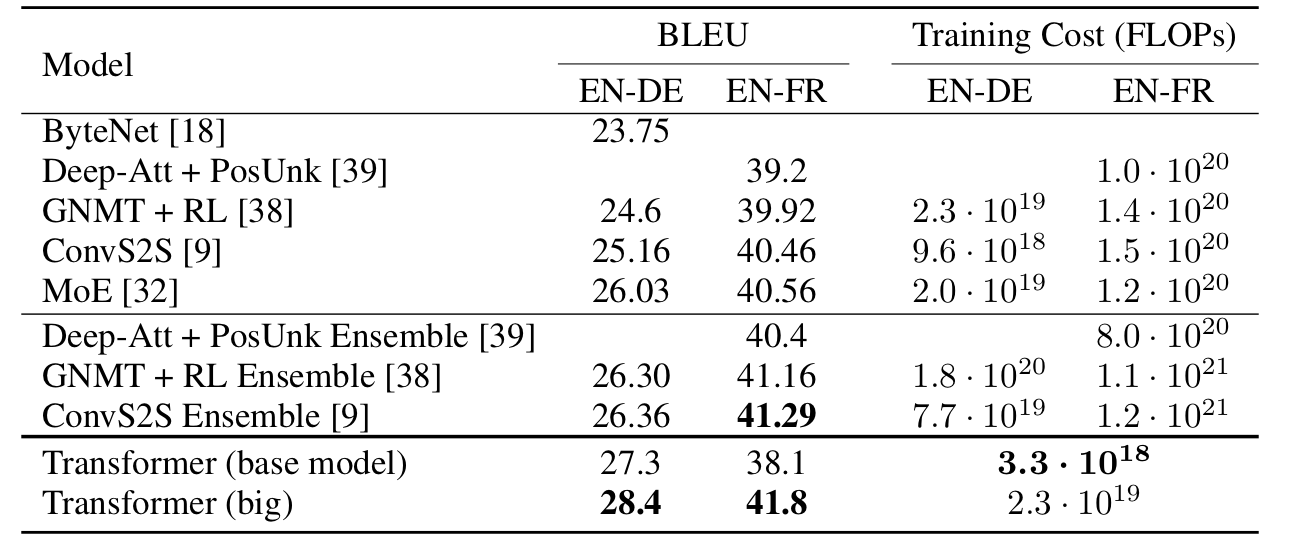
- 성능 요약표 : Training Cost는 floating points의 연산량을 추정하여 비교하였다.(Training Time, GPU 사용갯수 등 고려)2️⃣ Model Variations
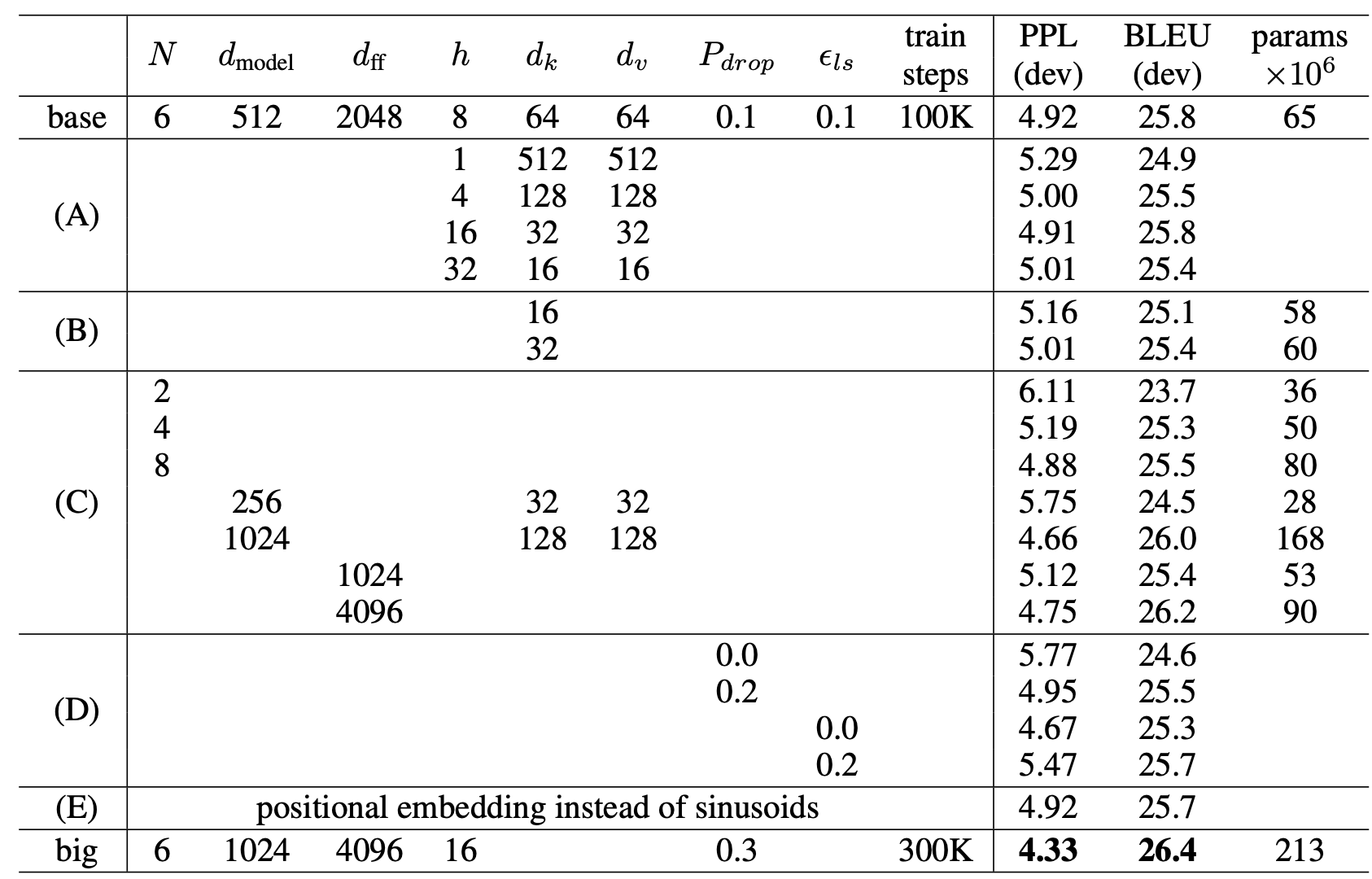
- Transformer의 구성요소를 평가하기 위해서 base model을 변형시켜가며 학습하여 성능을 평가함
- attention heads, attention keys, value dimension 등의 숫자를 변형하여 계산함.
- English-to-German development set, newstest2013으로 성능 평가를 진행
- beam search 사용, checkpoints의 평균은 사용하지 않음
- Single attention이 best보다 0.9점 낮음, 하지만 너무 많은 heads도 성능을 떨어뜨림
- attention key size를 낮추면 성능이 떨어지는 것을 확인함(B)
- dot product 보다 더 정교한 compatibility function을 사용하면 더 효과적일 것이라고 추측함
- 더 큰 모델에서 더 좋은 성능을 보인다.[(C)확인 가능]
- Dropout이 overfitting을 줄여준다.[(D)확인 가능]
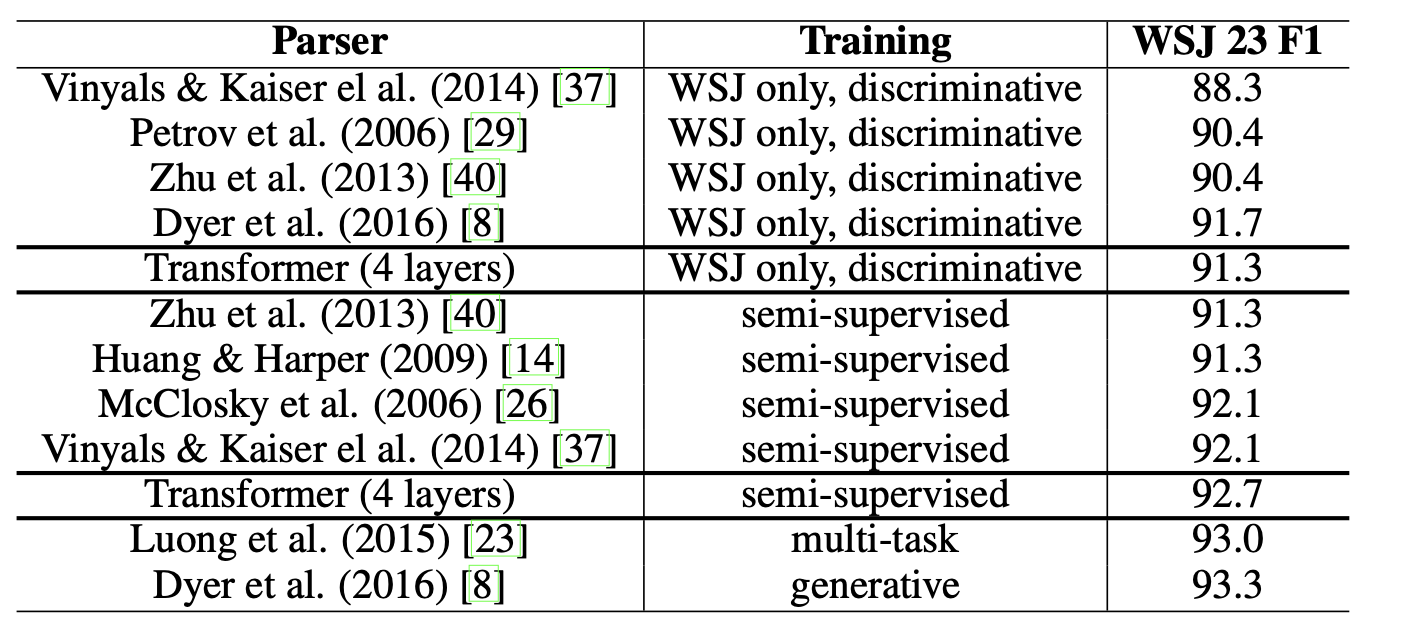
3️⃣ English Constituency Parsing
- English Consituency Parsing : sentence를 sub-phrase를 구조적으로 나눠가면서 분석하는 것
- Model : 4-layer transformer,
- Dataset :
- Wall Street Journal (WSJ) portion of the Penn Treebank
- 40000개의 학습 문장 활용
- 16000개의 토큰
- BerkleyParser corpora (semi-suprevised setting)
- 1700만개 학습 문장 활용
- 32000개의 토큰ㅐ
- Wall Street Journal (WSJ) portion of the Penn Treebank
- output length ≤ input length + 300
- dropout, beamsize 설정을 위해 실험 진행, 나머지 하이퍼파라미터는 그전 모델과 동일
- beam search 사용 ( beam size = 21, = 0.3
- Transfor mer가 매우 좋은 성능을 보이는 것을 확인할 수 있음.