
본 포스트는 Introduction to Direct3D 12를 발췌하여 번역 및 정리한 포스트입니다.
DirectX 11 프로그래밍에 대한 기본적인 개념을 이해하셔야 내용을 조금 더 쉽게 이해할 수 있습니다.
Introduction to Direct3D 12
“DirectX 12는 마이크로소프트에서 발표한 DirectX API의 최신 버전으로, DirectX의 그래픽스 API인 Direct3D 12가 포함되어있다.”
Direct3D 12 (약칭 D3D12)는 이전 버전보다 훨씬 좋은 성능을 보장함.
- 스레드를 효율적으로 사용할 수 있는 low-level control을 제공
- command list를 통해 여러 스레드를 사용할 수 있음
- 이는 곧 CPU/GPU 동기화와 메모리 관리를 개발자가 직접 해야 한다는 것을 의미함
또한 Direct3D에서는 미리 컴파일된 pipeline state object (PSO)와 command list (이들을 bundle이라고 한다.)를 통해 CPU 오버헤드를 최소화함.
초기화 (initialization) 단계에서는 vertex shader, pixel shader와 같은 shader를 포함하는 PSO와 기타 pipeline state (blending, rasterizer, primitive topology 등)을 생성함.
이 때문에 D3D11에서처럼 런타임에 파이프라인의 상태를 바꾸기 위해 드라이버에 접근하여 pipeline state를 만들 필요가 없어짐. 그 대신 PSO를 사용하여 draw 함수를 호출할 때 PSO가 파이프라인을 사용함으로써 pipeline state을 만들 때의 오버헤드를 줄일 수 있음.
초기화 단계에서 명령들을 생성해서 bundle로 재사용할 수 있도록 함.
Direct3D의 또다른 장점은 API 호출 횟수가 매우 적다는 것
- MSDN에 따르면 약 200회의 API 호출이 발생한다고 함. (심지어 그중 3분의 1만 복잡한 작업에 쓰임)
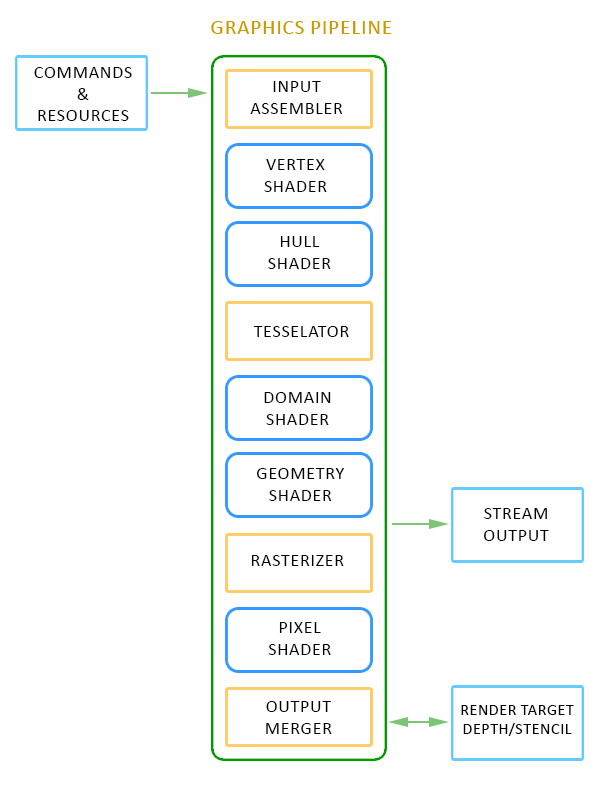
Overview of the Graphics Pipeline
D3D11의 렌더링 파이프라인을 간단하게 리뷰해보자!
그래픽스 파이프라인은 Stage라고도 부르는데, 그래픽스 하드웨어 위에서 동작하는 일련의 과정을 의미함.
파이프라인에 데이터를 통과시키면 최종적으로 3D scene을 나타내는 2D 이미지를 얻게 됨.
이 뿐만 아니라 stream output 단계에서 처리된 geometry를 스티리밍할 수도 있음.
파이프라인의 단계는 configured stage와 programmed stage로 나뉨.
- configured stage → fixed function으로, 수정이 불가능함
- programmed stage → 프로그래밍 가능한 영역
- "(vertex, hull, domain, geometry, pixel) shader"들은 프로그래밍 가능하며, High Level Shading Language (HLSL)로 프로그래밍함
Compute Shader
Compute shader (dispatch pipeline)은 매우 빠른 연산에 사용되는데, GPU를 일종의 병렬 프로세서로 사용하여 CPU 성능을 높임
→ 따라서 그래픽스와는 관련이 없는 부분
Compute shader pipeline을 사용하면 collision detection과 같은 비싼 연산을 비교적 정확하게 수행할 수 있음
Input Assembler (IA) Stage
IA를 구성하여 삼각형, 직선, 점과 같은 primitive를 생성하도록 하는 단계
Primitive는 vertex & index buffer를 통해 얻어짐
개발자는 IA에 input layout을 넘겨줘서 정점 데이터를 읽어들이도록 함
primitive 생성이 끝나면 파이프라인의 다른 단계에 primitive들을 넘겨줌
{primitive id, instance id, vertex id, etc}의 형태로 primitive를 정의함 → 이러한 값들을 Sematic이라고 함
- input layout 사용 예시)
D3D12_INPUT_ELEMENT_DESC layout[] =
{
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_PER_VERTEX_DATA, 0 },
};이렇게 선언된 input layout은 IA에 다음과 같은 사실을 알려줌:
- vertex buffer에 있는 각 vertex는 하나의 element만 갖고 있어~
- 근데 이거는 vertex shader의 “POSITION” 파라미터에 바운딩되어야 해~
- 0번째 byte부터 시작하구요~
- 각각 32bit짜리 R, G, B float 값을 갖습니다~
Vertex Shader (VS) Stage
프로그래밍 가능한 stage.
transformation / scalig / lighting / displacement mapping (텍스처 매핑)와 같은 작업을 수행함
vertex를 수정할 일이 없더라도 파이프라인이 돌아가려면 VS는 무조건 구현되어 있어야 함
float4 main(float4 pos : POSITION) : SV_POSITION
{
return pos;
}VS는 단순히 input으로 들어온 position을 리턴함
POSITION → Semantic. vertex (input) layout을 생성할 때 vertex의 position 값을 지정하기 위해 POSITION이라는 이름을 명시하며, 이는 VS의 파라미터로 전달됨 (물론 다른 이름을 쓸수도 있음. 개발자 맘대로)
Hull Shader (HS) Stage
Tessellation Stage의 세 단계 중 하나 (hull shader → tessellator → domain shader)
Tessellation
모델의 디테일을 높이기 위해 primitive를 매우 많은 조각들로 나누는 작업 (그것도 엄청 빨리)
새로 만들어진 primitive를 화면에 display하기 전에 GPU에 빠르게 만들어놓기 때문에 메모리가 불필요하며, 따라서 CPU를 이용하는 것보다 시간을 단축할 수 있음
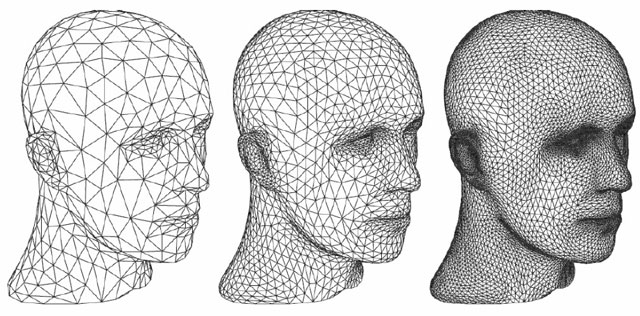
hull shader가 하는 일은 “primitive의 어디에, 어떻게 vertex를 추가할지 계산”하는 일임. 그런 다음 이 정보를 tessellator stage와 domain shader stage에 넘겨줌
Tessellator Stage (TS)
fixed function → 프로그래밍 필요 없음
HS가 넘겨준 정보를 바탕으로 실제로 primitive를 나누는 작업을 수행하고, output을 domain shader에 넘겨줌
Domain Shader (DS) Stage
HS가 넘겨준 vertex의 position 정보와 TS에서 만든 vertex를 바탕으로 vertex에 대한 transform을 수행함
why? TS까지만 수행하면 vertex가 삼각형 (or 선) 중앙에 만들어지는데, 이렇게만 해서는 디테일을 살릴 수 없기 때문. 따라서 중앙에 있는 vertex를 살짝씩 움직여서 디테일을 살림
그 결과로 나오는 vertex들을 geometry shader stage에 넘겨줌
Geometry Shader (GS) Stage
vertex와 edge-adjacent primitive에 대한 정보를 input으로 받음
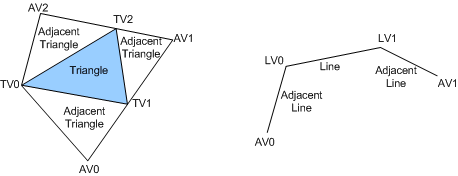
edge-adjacent primitive : 각 edge와 인접해있는 primitive
GS의 장점 → VS에서는 하지 못하는 primitive 생성 / 삭제가 가능함
ex. 점 하나를 사각형 (quad)이나 삼각형으로 바꿀 수 있음 → 입자 엔진에 적합
이 단계에서 나오는 데이터는 바로 rasterizer stage에 넘겨줄 수도 있고, stream output을 통해 메모리에 있는 vertex buffer로 전달할 수도 있음
Stream Output (SO) Stage
GS (없으면 VS) 단계에서 정점 데이터를 얻어서 메모리에 전달하고, 전달된 데이터는 vertex buffer에 저장됨
리스트의 형태로 정점 데이터를 전달하며, 완성되지 않은 primitive는 절대 전달되지 않고 제거됨
완성되지 않은 primitive? → 2개의 정점만 있는 삼각형, 1개의 정점만 있는 선 등등
Rasterizer Stage (RS)
이전 단계에서 넘어온 벡터 정보 (shape, primitive)를 받아서 각 primitive에 대해 per-vertex value를 보간 (interpolate)하여 픽셀로 변환함
clipping도 수행함
clipping : 스크린 바깥에 있는 primitive를 자르는 작업. 뷰포트 viewport에 의해 결정됨
Pixel Shader (PS) Stage
화면 안에 보일 픽셀에 대해 lighting과 같은 연산 / 수정을 수행함 (per-pixel)
RS에서는 각 픽셀 당 한번씩 PS를 호출함
기본적으로는 VS와 비슷하게 하나의 pixel을 받아서 하나의 pixel을 리턴하는 1:1 매핑 구조임
PS의 역할은 각 pixel fragment의 최종 색상을 결정하는 것.
pixel fragment : 화면에 그려질 잠재적인 픽셀
예를 들어 단색 원 뒤에 단색 사각형이 있다고 가정하자. 원과 사각형을 구성하는 픽셀들이 pixel fragment임
아직까지는 모든 픽셀이 화면에 그려질 수 있지만, output merger stage에 도달해서 화면에 그려질 픽셀의 최종 색상을 결정하게 되면 각 픽셀의 depth value를 고려하게 됨 → 원의 depth value가 사각형의 depth value보다 작으므로 원에 있는 픽셀만 그려질 것
PS의 output은 4D 색상값임
float4 main() : SV_TARGET
{
return float4(1.0f, 1.0f, 1.0f, 1.0f); // white
}Output Merger (OM) Stage
pixel fragment와 depth/stencil buffer를 받아서 실제로 그려질 픽셀 (render target에 저장됨)을 결정함
기타 설정에 따라 blending을 적용하기도 함 (blend model과 blend factor는 직접 지정해야 함)
render target은 Texture2D 자원으로써, 디바이스의 인터페이스에 따라 OM과 결합함
render target을 통해 scene이 렌더링을 끝내면, swapchain에 있는 결과를 화면에 display할 수 있게 됨
Overview of how Direct3D 12 works
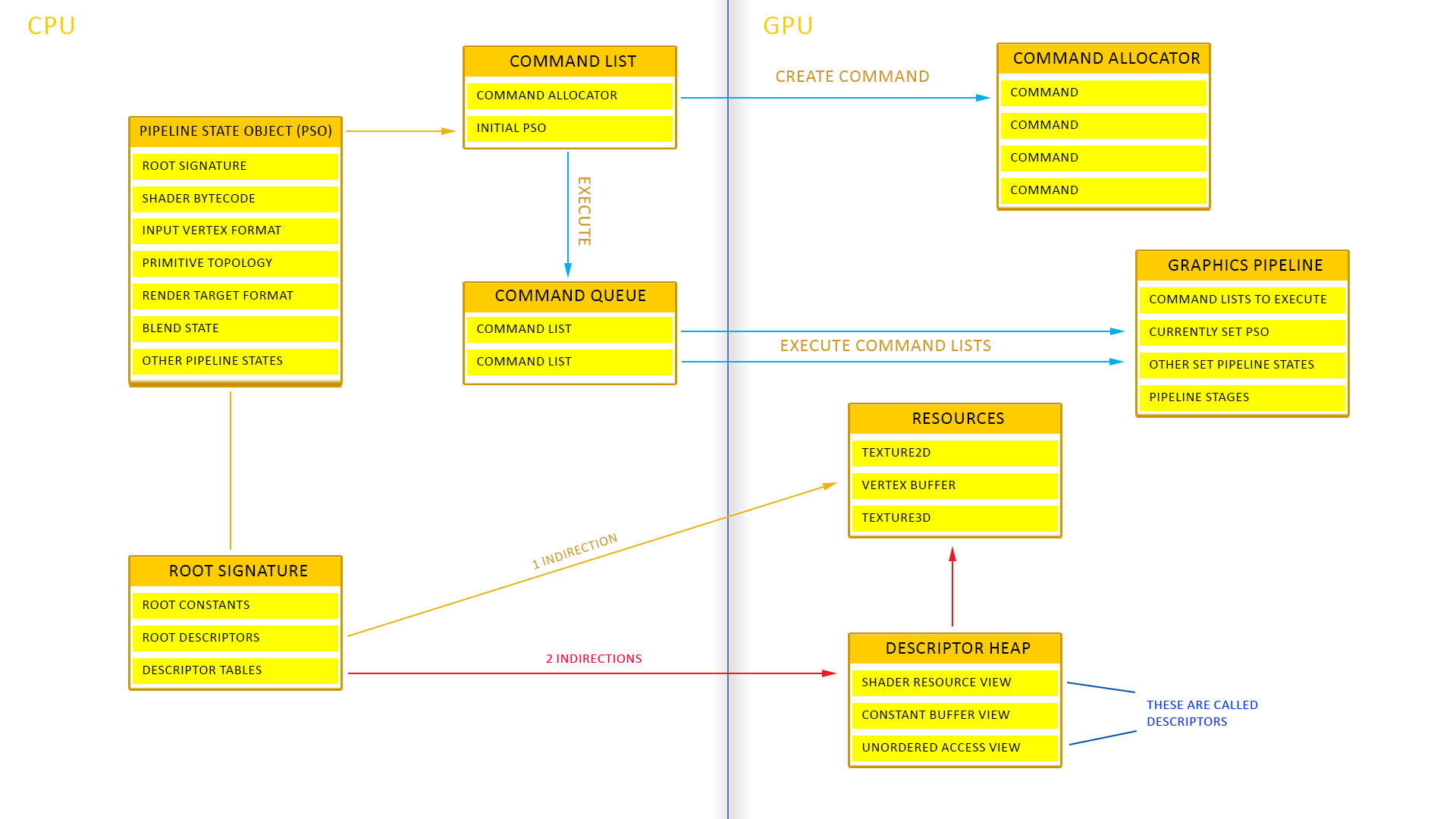
Pipeline State Object (PSO)
PSO는 ID3D12PipelineState 인터페이스로 표현되며, CreateGraphicsPipelineState()를 통해 생성할 수 있음
그런 다음 PSO를 설정하려면 command list의 SetPipelineState()를 호출하면 됨
PSO는 direct3d 12의 성능 향상의 핵심임
PSO는 초기화 단계에서 여러 개 만들어지는데, PSO 생성 이후 command list로 이들을 설정하는 작업은 매우 적은 CPU 오버헤드를 가짐 ← command list로 넘어가서 설정하기 전까지 이미 모든 PSO가 만들어지고, GPU가 PSO를 설정하려면 그냥 포인터만 넘겨주면 되기 때문
따라서 PSO의 생성 개수 제한은 없다고 볼 수 있음
PSO를 생성할 때 반드시 D3D12_GRAPHICS_PIPELINE_STATE_DESC를 채워주어야 함. 이 structure를 통해 PSO 설정 시 파이프라인의 state를 결정할 수 있음
대부분의 state는 PSO에서 설정할 수 있지만, 몇몇 state는 command list에서 설정해주어야 함
PSO에서 설정할 수 있는 state:
- vertex, pixel, domain, hull, geometry shader에 대한 bytecode (
D3D12_SHADER_BYTECODE) - stream output 버퍼 (
D3D12_STREAM_OUTPUT_DESC) - blend state (
D3D12_BLEND_DESC) - rasterizer state (
D3D12_RASTERIZER_DESC) - depth/stencil state (
D3D12_DEPTH_STENCIL_DESC) - input layout (
D3D12_INPUT_LAYOUT_DESC) - primitive topology (
D3D12_PRIMITIVE_TOPOLOGY_TYPE) - render target의 개수
- render target view의 format (
DXGI_FORMAT) - depth stencil view의 format (
DXGI_FORMAT) - sample description (
DXGI_SAMPLE_DESC)
command list에서 설정하는 state:
- resource binding (vertex buffer, index buffer, stream output target, render target, descriptor heap 등)
- viewport
- scissor rectangle
- blend factor
- depth/stencil reference value
- primitive topology order & adjacency type
PSO에서 설정한 state는 command list나 bundle에 상속되지 않음. command list와 bundle에서 생성하는 pipeline은 command list와 bundle 생성 시 함께 설정됨
PSO에서 설정하지 않은 state 역시 command list에 상속되지 않는데, bundle의 경우 PSO에서 설정하지 않은 모든 state를 상속함
bundle이 메소드 호출로 state를 변경하면, 해당 state는 bundle 실행이 완료된 후에도 계속해서 command list로 남음
command list와 bundle에서 설정하는 (PSO에서 설정하지 않는) 기본 state:
- 0으로 설정된 viewport
- 0으로 설정된 scissor rectangle
- 0으로 설정된 blend factor
- 0으로 설정된 depth/stencil reference value
ClearState 메소드를 사용하여 command list로 생성한 state를 default로 되돌릴 수 있음. 해당 메소드를 bundle에서 사용하면 command list의 close() 함수가 E_FAIL을 리턴할 것임
command list에서 설정한 resource binding은 command list에서 실행하는 bundle에 상속됨
bundle에서 설정한 resource binding은 bundle 실행이 끝날 때 호출하는 command list가 설정함
Device
디바이스는 ID3D12Device 인터페이스로 표현하며, command list, PSO, root signature, command allocator, command queue, fence, resource, descriptor & descriptor heap을 생성할 때 사용하는 가상 어댑터임
보통 컴퓨터에는 한 개 이상의 GPU가 존재하기 때문에 DXGI factory를 사용하여 디바이스를 나열하고, 소프트웨어 장치가 아닌 feature level 11 디바이스를 찾게 됨
Direct3D의 가장 큰 특징은 멀티스레드 어플리케이션과 호환이 잘 된다는 점임
사용하고자 하는 어댑터의 index를 찾으면 D3D12CreateDevice() 메소드를 통해 디바이스를 생성할 수 있음
Command List (CL)
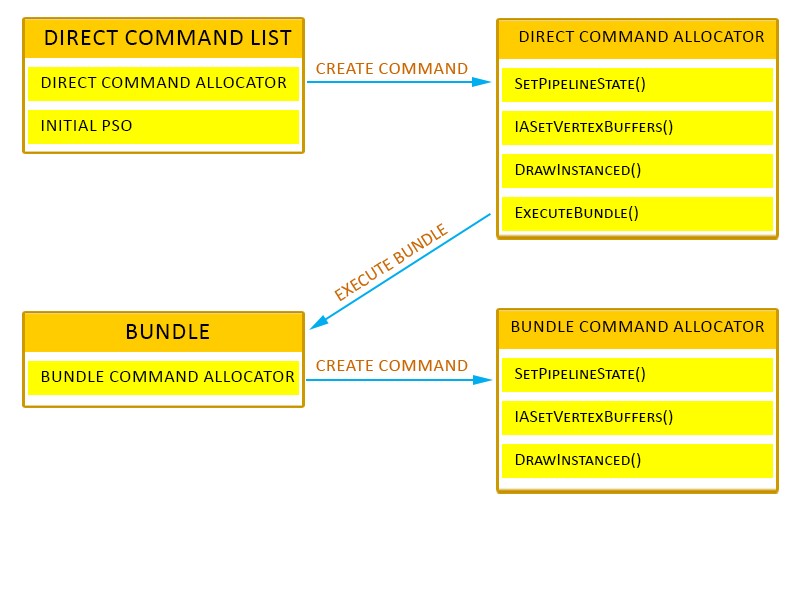
command list는 ID3D12CommandList 인터페이스로 표현하며, 디바이스의 CreateCommandList() 메소드를 통해 생성됨
command list는 GPU에서 실행하고자 하는 command를 할당 (allocate)하기 위해 사용함
command의 예시:
- pipeline state 설정
- 자원 설정
- resource state 전이 (resource barrier)
- vertex / index buffer 설정
- draw
- render target 초기화
- render target view (RTV) 설정
- bundle (command의 묶음) 실행
- 기타 등등
command list는 GPU에 command를 저장하는 command allocator와 연결됨
command list를 처음 생성하면 D3D12_COMMAND_LIST_TYPE 플래그를 통해 command list의 종류를 명시해야 하며, 연결된 command allocator를 제공해야 함
4가지 타입 → direct, bundle, compute, copy
direct command list는 GPU가 실행할 수 있는 타입으로, direct command allocator와 연결되어야 함 (D3D12_COMMAND_LIST_TYPE_DIRECT)
command list를 recording state로 설정하려면 Reset() 메소드를 호출하여 command allocator와 PSO를 넘겨주어야 함
PSO의 인자로 NULL값을 전달하는 것도 가능하며, 그렇게 하면 pipeline state를 default로 설정함
command list를 모두 채웠으면 close() 메소드를 통해 command list의 상태를 not recording으로 바꿔주어야 함. 그러고 나면 command queue를 사용하여 command list를 실행할 수 있는 상태가 됨
GPU가 종료되지 않았더라도 command list를 실행하자 마자 reset할 수 있음 (GPU에서 실행되는 명령은 execute()를 호출하자마자 command allocator에 저장됨) → 이를 통해 command list에 할당된 메모리를 재사용할 수 있음 (CPU 측면)
Bundle
command list와 마찬가지로 ID3D12CommandList 인터페이스로 표현함
다만 bundle을 생성할 때는 D3D12_COMMAND_LIST_TYPE_DIRECT 플래그가 아닌 D3D12_COMMAND_LIST_TYPE_BUNDLE 플래그를 사용한다는 점이 다름 (생성 자체는 CreateCommandList() 메소드 호출로 동일함)
bundle은 자주 재사용하는 command의 모음이며, 여러 command를 포함하는 대부분의 CPU 작업이 bundle을 생성할 때 끝나기 때문에 아주 유용함
또한 bundle은 direct command list에서만 실행할 수 있으며, direct command list는 command queue에서만 실행할 수 있다는 점 외에는 command list와 거의 비슷함
command list는 재사용이 가능하지만, GPU는 command list에서 command를 다시 호출하기 전에 command list 실행을 끝내야 함. 실제로 scene은 프레임마다 바뀌기 때문에 command list 역시 프레임마다 바뀌며, 따라서 command list를 재사용할 가능성은 거의 없음
command queue에서 직접 bundle을 실행하는 것은 불가능하며, direct command list의 ExecuteBundle() 메소드를 호출하여 실행해야만 함
또한 bundle은 direct command list를 호출해서 설정한 pipeline state를 상속하지 않음
Command Queue (CQ)
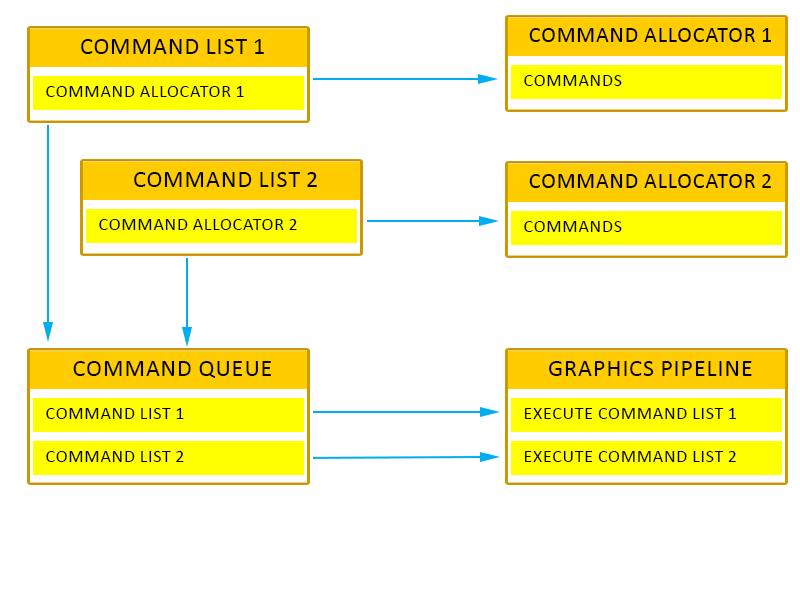
ID3D12CommandQueue 인터페이스로 표현하며, 디바이스의 CreateCommandQueue() 메소드로 생성함
GPU에서 실행할 command list를 전달하기 위해 사용하며, resource tile mapping을 업데이트하기 위해 사용하기도 함
Command Allocator (CA)
ID3D12CommandAllocator 인터페이스로 표현하며, 디바이스의 CreateCommandAllocator() 메소드로 생성함
command list와 bundle의 command가 저장되는 GPU 메모리를 표현함
command list 실행이 끝나면 command allocator에서 reset() 메소드를 통해 메모리를 해제할 수 있음
command queue 호출이 실행된 직후 reset()*을 호출하더라도 command allocator와 연결된 command list는 반드시 GPU에서 실행이 끝나야 함 (그렇지 않으면 fail) ← GPU가 메모리에 저장된 command allocator의 명령들을 실행하고 있을 수도 있기 때문
이때 CPU-GPU 동기화를 위해 fence를 사용함 → command allocator에서 reset()을 호출하기 전에 fence를 확인하여 command allocator와 연결된 command list의 실행이 끝났다는걸 명확히 해야 함
command allocator와 연결된 command list는 하나만 recording state가 될 수 있음. 즉, command list를 채워나가는 각 스레드마다 최소 하나 이상의 command allocator와 command list가 필요하다는 뜻
Resources
자원이란 scene을 구성하는 데 필요한 데이터들을 의미함 → geometry, 텍스쳐, 셰이더 데이터와 같이 그래픽스 파이프라인에서 접근할 수 있는 데이터를 저장하는 메모리 청크
resource type이란 자원에 포함된 데이터의 type을 의미함
resource type의 종류:
Texture1DTexture1DArrayTexture2DTexture2DArrayTexture2DMSTexture2DMSArrayTexture3D- buffers (
ID3D12Resource)
resource references / views:
- Constant buffer view (CBV)
- Unordered access view (UAV)
- Shader resource view (SRV)
- Samplers
- Render Target View (RTV)
- Depth Stencil View (DSV)
- Index Buffer View (IBV)
- Vertex Buffer View (VBV)
- Stream Output View (SOV)
Descriptor (Resource View)
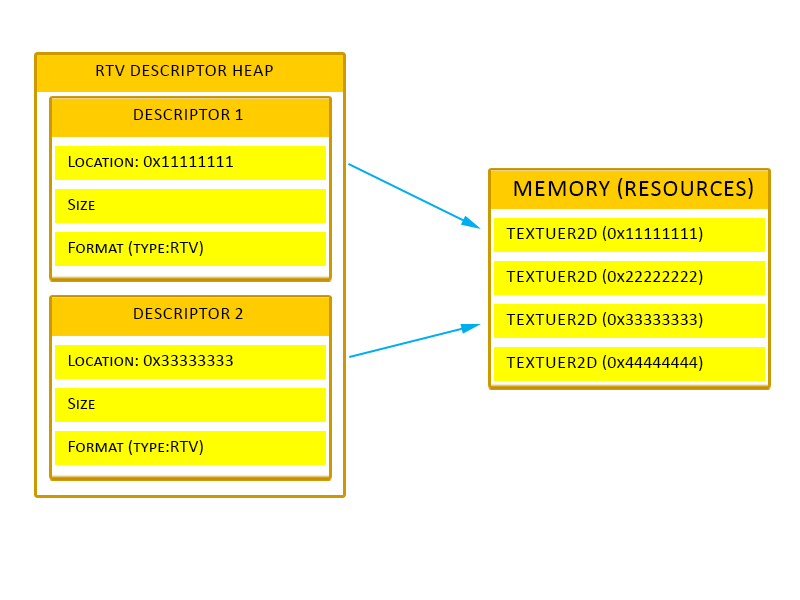
자원을 어디서 찾아야 하는지와 자원에 들어있는 데이터를 해석하는 방법을 셰이더에게 전달하는 구조
D3D11의 resource view와 유사함
동일한 자원에 대해 여러 descriptor를 만드는 것이 가능함 → 렌더링 파이프라인의 각 단계에서 descriptor를 서로 다르게 사용하기 때문
render target view (RTV)를 생성하여 자원을 파이프라인의 output buffer처럼 사용하는 것도 가능함
descriptor는 descriptor heap에만 위치할 수 있으며, 이 외에 descriptor를 메모리에 저장하는 방식은 존재하지 않음
Descriptor Table (DT)
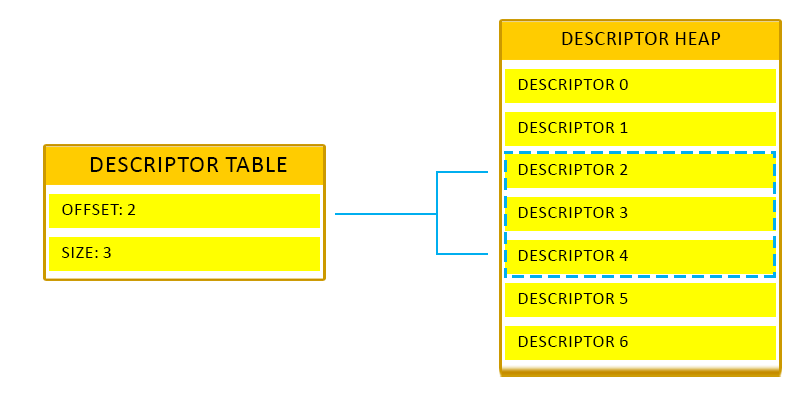
descriptor heap에 있는 descriptor에 대한 배열. 모든 DT는 offset과 length를 가짐
셰이더에서는 root signature의 descriptor table을 통해 descriptor heap에 있는 descriptor에 접근할 수 있음 (index로)
descriptor heap에는 CBV, UAV, SRV, Sampler 등이 저장되며, 셰이더에서 descriptor에 대한 참조가 가능함
RTV, DSV, IBV, VBV, SOV는 descriptor table을 참조하지 않고 파이프라인에 직접 연결됨 (MSDN 문서에서도 정확하게 언급하지 않은걸로 보아 애매한 내용인듯)
Descriptor Heap (DH)
ID3D12DescriptorHeap 인터페이스로 표현하며 ID3D12Device::CreateDescriptorHeap() 메소드로 생성함
DH는 descriptor에 대한 리스트로, descriptor가 저장된 메모리 청크를 의미함
sampler는 동일한 DH에 자원으로 들어갈 수 없음
DH는 shader visible과 non-shader visible로 나뉨
- shader visible DH : 셰이더에서 접근 가능한 descriptor로 이루어진 DH
- CBV, UAV, SRV, sampler descriptor가 들어갈 수 있음
- non-shader visible DH : 셰이더가 참조할 수 없는 descriptor로 이루어진 DH
- RTV, DSV, IBV, VBV, SOV
normal map은 sampler, shader visible, non-shader visible resource에 대한 DH로 이루어짐
(이 튜토리얼에서는 RTV를 저장하는 DH만 구현할 예정)
DH는 DT를 필요할 때마다 정의해야 하기 때문에 충분한 공간이 필요하며, 이를 위해 파이프라인의 상태가 변할 때 descriptor space를 재사용할 수 있음
D3D12에서는 command list에서 DH를 여러 번 변경하는 것이 가능함
bundle은 SetDescriptorHeaps를 한 번만 호출할 수 있으며, SetDescriptorHeaps로 설정된 DH는 반드시 bundle을 호출한 command list가 설정한 DH와 정확히 일치해야 함
Root Signature (RS)

셰이더에서 접근할 데이터 (자원)을 정의함
RS는 함수의 파라미터 리스트와 비슷함 (함수 == 셰이더, 파라미터 리스트 == 셰이더가 접근할 데이터의 type)
RS는 root constant, root descriptor, descriptor table을 포함하고 있음 → 모두 RS의 root parameter가 될 수 있음
어플리케이션에서 수정할 수 있는 root parameter의 실제 데이터를 root argument라고 함
RS의 최대 size는 항상 64 DWORD임
- root constant
- 32-bit value (1 DWORD)
- RS에 직접 저장됨
- RS에 대한 메모리는 제한이 있기 때문에 자주 변하는 상수 값을 저장해야 함
- 셰이더의 접근에 아무런 cost도 없기 때문에 빠르게 접근할 수 있음
- root descriptor
- 셰이더가 가장 자주 접근하는 inlined descriptor
- 64-bit 가상 address (2 DWORD)
- CBV, raw SRV & UAV만 사용할 수 있으며, Texture2D SRV와 같이 복잡한 type은 사용할 수 없음
- 셰이더가 참조할 때 한 번의 redirection이 이루어짐
- descriptor table
- DH에 대한 offset과 length가 저장되어있음
- 32-bit (1 DWORD)
Resource Barrier
자원이나 subresource의 상태 또는 용법을 바꾸기 위해 사용함
멀티스레드에 유용함 → 여러 스레드 간 동기화를 지원
resource barrier의 세 가지 종류:
- transition barrier
- aliasing barrier
- unordered access view (UAV) barrier
Fence and Fence Event
GPU가 현재 사용하고 있는 내용을 수정하거나 삭제하지 않도록 하기 위해 fence가 필요함
fence와 fence event는 command queue 실행에서 GPU가 어디에 위치하는지를 알려줌
command list를 채운 다음 command queue를 실행할 때 시그널을 보내서 commannd list가 fence value를 특정 값으로 설정하도록 함 → 설정된 fence value가 원하는 값이 맞는지 확인
올바른 값이라면 명령 실행이 완료되어 command list와 command queue를 리셋할 수 있고 command list를 다시 채울 수 있다는 뜻이고, 그렇지 않다면 fence event를 생성해서 GPU가 해당 event를 내보낼 때까지 기다려야 함
fence는 ID3D12Fence 인터페이스로 표현되고, fence event는 핸들 HANDLE임
ID3D12Device::CreateFence()를 통해 디바이스가 fence를 생성하며, CreateEvent()를 통해 fence event를 생성함
Overview of Application Flow Control for Direct3D 12
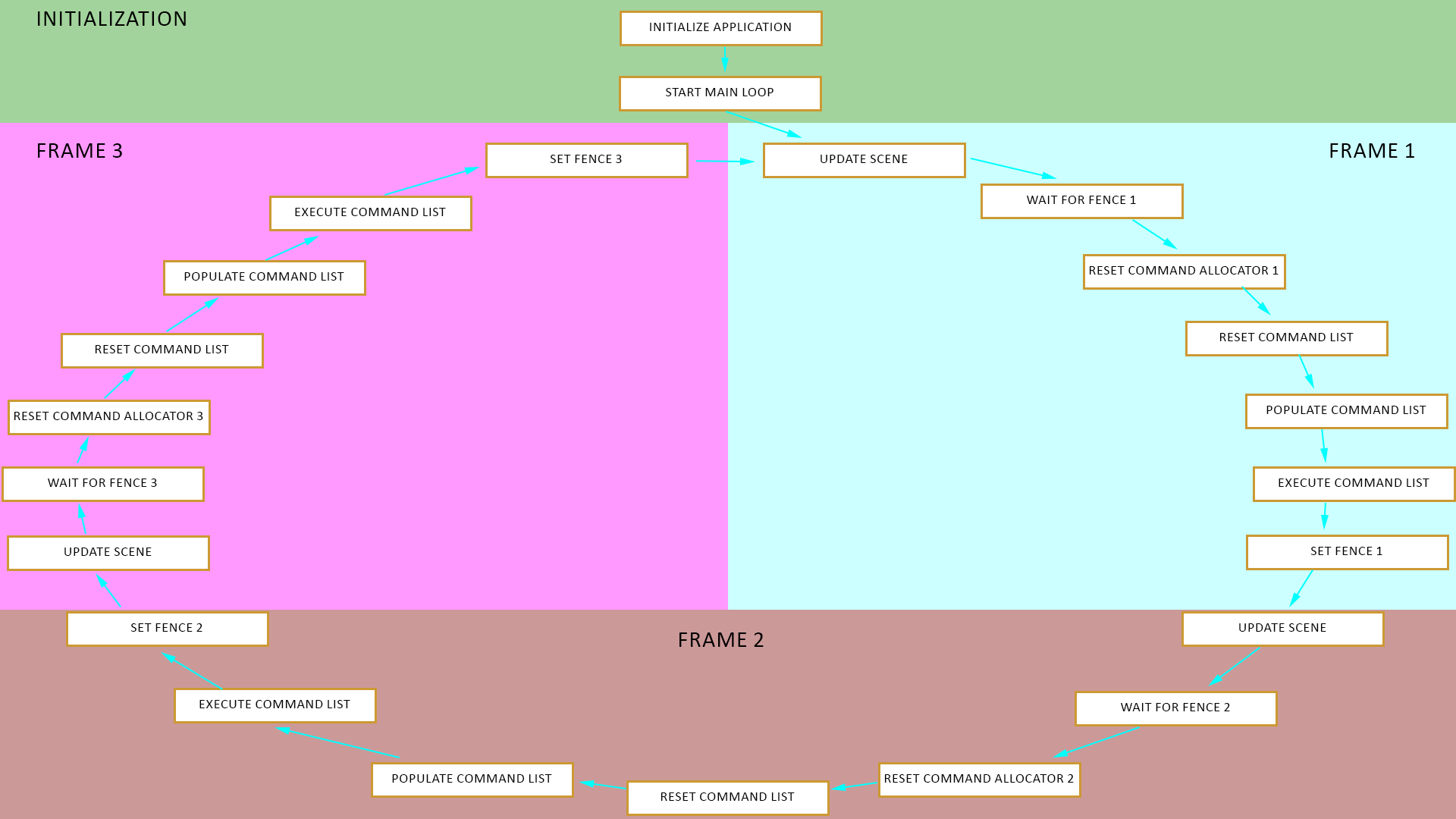
(Direct3D 12의 lifecycle)
- 초기화
- 메인 루프 시작
- (새로운 scene이 만들어졌을 경우) scene 설정
- 게임 로직 업데이트
- (필요하면) 자원 로드/해제
- GPU 작업이 끝날 때까지 대기
- command allocator & command list 리셋
- command list 채우기
- (멀티스레드인 경우) command list thread가 끝날 때까지 대기
- command list 실행
- 3으로 되돌아감
- Initialize Application
- 파일이나 데이터베이스로부터 세팅을 불러옴
- 다른 세팅은 없는지 확인
- 업데이트 체크
- 메모리 요구사항 확인
- 라이센스 확인 (시험판인지, 데모 버전인지, 아니면 해적판인지?)
- window 생성
- 스크립팅 엔진 초기화
- 리소스 매니저 설정
- 오디오 시스템 설정
- 네트워킹 설정
- 컨트롤러 설정
- Direct3D 초기화
- descriptor heap 설정
- command list 설정
- RTV 설정
- command allocator 설정
- PSO 설정 (전부 다)
- root signature 설정 (역시 전부 다)
- Start Main Loop
메인 루프를 시작함. 윈도우 메시지를 확인하고 별다른 메시지가 없으면 게임을 계속해서 업데이트하면 됨
- Setup Scene
당연하게도 메인 루프 안에서 이뤄지는 작업임
- scene에 상주하는 자원을 불러옴 (scene이 바뀌거나 플레이어가 나갈 때까지 없어지지 않는 것들)
- ex) 텍스쳐, 지형, 텍스트 등
- 초기 자원을 불러옴 (scene에 곧바로 필요한 자원)
- scene이 작을 경우 위처럼 불러올 수도 있음
- 초기 뷰포트, view, projection matrix와 함께 카메라 설정
- scene에 상주하는 command bundle 설정
- Update game logic
게임의 심장이라고 할 수 있는 부분.
- AI 업데이트
- 네트워크 또는 사용자의 인풋 확인
- scene에 있는 object 업데이트 (position, 애니메이션 등)
- Load/Release resource
리소스 매니저를 구현했다면 여기서 쓰자!
scene에 object가 추가됐는데 이전에 불러온 적 없는 텍스쳐가 있다? 이 단계에서 불러옴.
scene에서 object가 제거될 때 텍스쳐를 unload하는 것도 여기서 함.
- Wait for GPU
command list가 실행되는 동안 관련된 command allocator는 리셋이 불가능함 → 따라서 대부분 최소 2 ~ 3개의 command allocator를 사용하는 double / triple buffering을 수행하게 될 것임
즉, 각 프레임마다 command allocator를 리셋하기 전에 GPU가 관련된 command list 실행을 끝냈는지 확인해야 하는데, 이를 위해 fence와 fence event를 사용함
간단하게 설명하자면 프레임 f에서 command list를 실행할 때, 동시에 GPU가 프레임 f + 1을 끝내기를 기다리고 있는 것임
triple buffering의 경우 형태는 다음과 같음:
- GPU가 프레임 1을 끝내기를 기다림
- 프레임 1 렌더링
- GPU가 프레임 2를 끝내기를 기다림
- 프레임 2 렌더링
- GPU가 프레임 3를 끝내기를 기다림
- 프레임 3 렌더링
- GPU가 프레임 1을 끝내기를 기다림
- 프레임 1 렌더링
- Reset command allocator and command list
GPU 대기까지 끝났으면 command list를 리셋할 수 있음
물론 이전 프레임에서 변한 게 없으면 command list를 리셋할 필요는 없는데, 그런 일은 거의 없음
자주 사용되는 command들이 있다면 bundle에 넣고 command list 위에서 실행시킴
- Populate command list
GPU가 수행해야 하는 작업들이 대부분임 (자원 바인딩, 텍스쳐, descriptor 생성, 파이프라인 상태 설정, resource barrier, fence value 설정 등)
- Wait for command list threads
멀티스레드인 경우 command list를 서로 다른 스레드에서 채워나갈 수 있음
다만 한 번에 한 스레드만 command list에 접근할 수 있으므로 각 스레드는 command list와 fence, fence event, command allocator를 각자 갖고 있어야 함
command queue를 통해 command list를 실행하는 execute를 호출하면 메인 스레드는 command list를 사용하는 스레드가 command list를 다 채울 때까지 기다릴 것임
- Execute command lists
command queue에서 ExecuteCommandLists()를 호출하여 scene을 렌더링하는 단계!
