
Arxiv 2025. [Paper] [Project Page]
Zeyu Zhang, Yiran Wang, Wei Mao, Danning Li, Rui Zhao, Biao Wu, Zirui Song, Bohan Zhuang, Ian Reid, Richard Hartley
[Paper Review Video]
기존 conditional motion generation의 두 가지 한계
- Condition에 따라 중요한 프레임 및 body part를 선정하는 메커니즘 부족
- 여러 modal을 통합하는 능력 부족
제안한 방법론
- Attention 기반 mask modeling
- Text, music을 함께 입력으로 받는 모델 구조 제안
- Text-Music-Dance (TMD) dataset
- 2,153개의 text/music/dance pair 보유 - AIST++의 2배 크기
- HumanML3D 벤치마크에서 FID 성능 1위 기록
1. Introduction
기존 t2m 모델의 주요 한계
- Maksed autoregressive model을 활용한 모션 생성 → diffusion model보다 효율적인 생성
- 다만 주어진 condition을 기반으로 모션 시퀀스에서 중요한 frame이나 body part를 고르는 능력은 부족함
- 텍스트, 음악 등 멀티모달 데이터를 입력으로 받는 모션 생성
- 텍스트 → 모션, 음악 → 모션은 가능하지만 텍스트 & 음악 → 모션은 불가능
- ex) 텍스트를 통한 music-to-dance 미세 조정
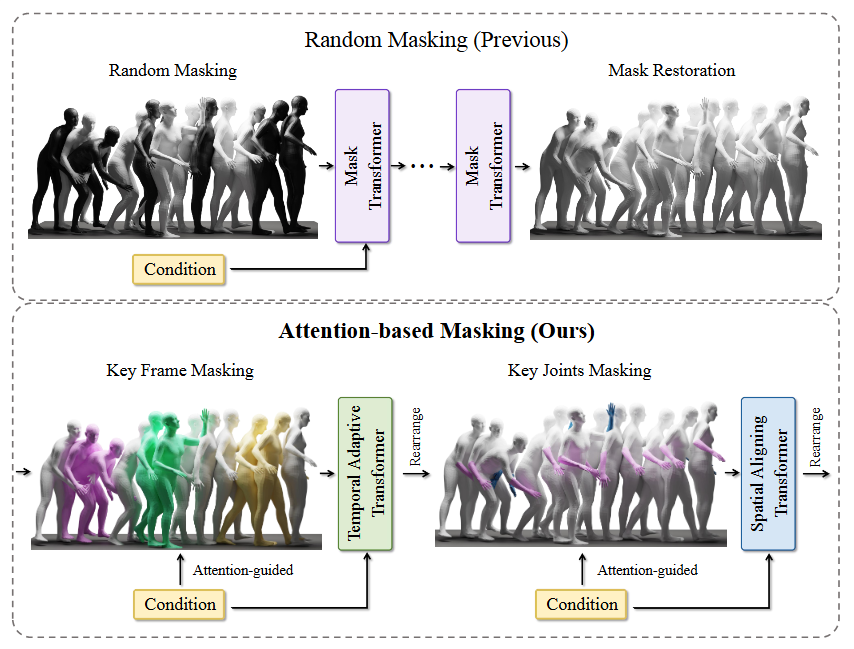
방법론
- Conditional masking across spatial and temporal dimensions
- 주어진 condition에 따라 결정된 키프레임과 action에 모델이 집중할 수 있게 됨
- 이때 condition을 text와 music 등 멀티모달로 받게 됨
- 멀티모달 condition을 동시에 받을 수 있는 아키텍쳐 제안
- Temporal / spatial 측면에서 모달을 정렬
- Temporal → 서로 다른 모달을 time-sensitive하게 정렬
- Spatial → action query를 특정 body part에 매핑하고, 이를 댄스 스타일에 맞는 음악 장르와 정렬
- 음악-텍스트-동작 쌍으로 구성된 새로운 motion dataset 제안
- Multi-modal motion generation 자체가 많이 연구된 분야가 아니기에 데이터셋이 부족했음
Contributions
- 멀티모달 condition을 입력으로 받아 controllable한 모션 생성이 가능한 프레임워크 제안
- Attention 기반 mask modeling 기법을 통한 키 프레임 및 액션 선택 방식
- Text-Music-Dance (TMD) dataset 제안 → AIST++의 2배 크기
2. Method
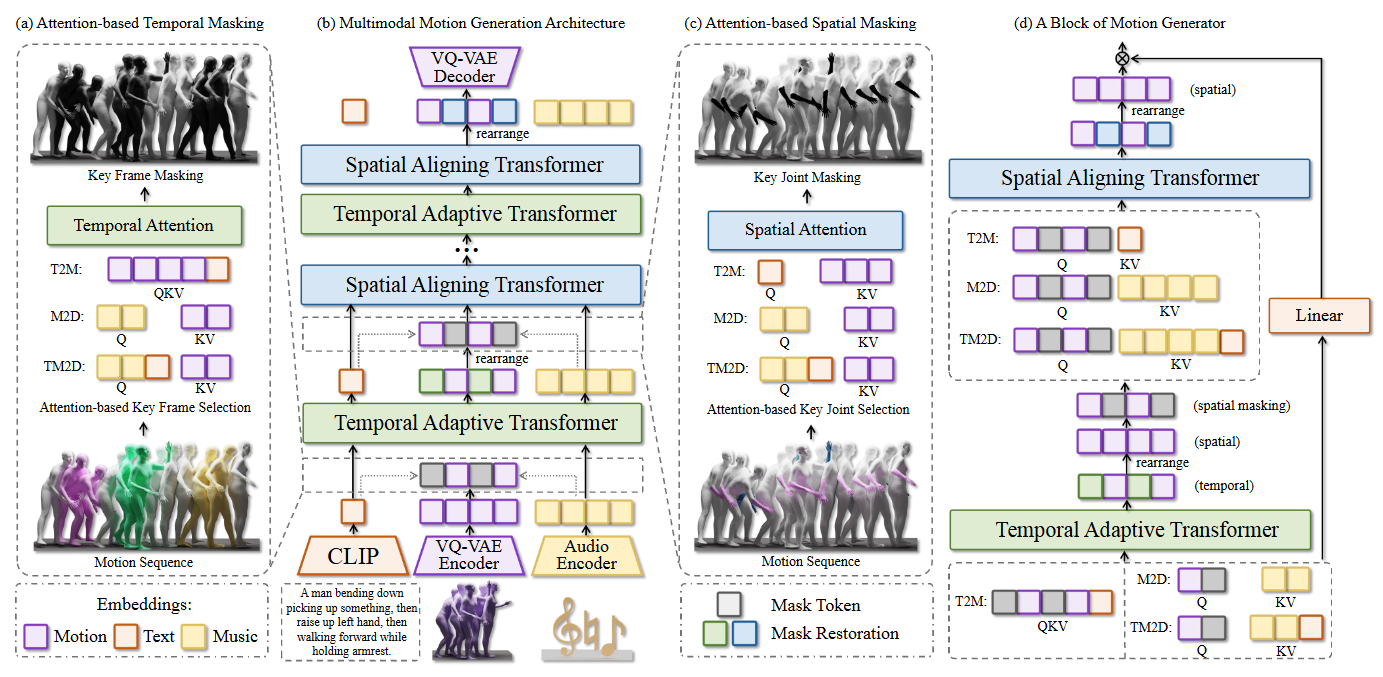
주요 특징
- Input: Text & Music
- Input embedding은 masking과 motion generation에서 guide로 사용됨
- Text embedding은 CLIP, music embedding은 audio encoder 사용 (Transformer Encoder를 사용한 것으로 보임)
- Attention-based masking
- Spatial & temporal dimension을 기준으로 attention score를 계산하여 높은 score를 갖는 part (body part 아님)를 masking gudiance로 사용
- 이렇게 마스킹된 토큰들은 masked transformer의 입력으로 들어가 mask 예측에 사용됨
- 기존 논문들에서 사용하던 masked transformer를 변형하여 Temporal Adaptive Transformer (TAT) & Spatial Aligning Transformer (SAT)로 활용
2-1. 아키텍쳐
Attention-based Masking
- 주어진 condition을 기반으로 모션 시퀀스에서 key frame (temporal)과 key actions (spatial)을 선택하고, 이를 masking에 사용하는 것
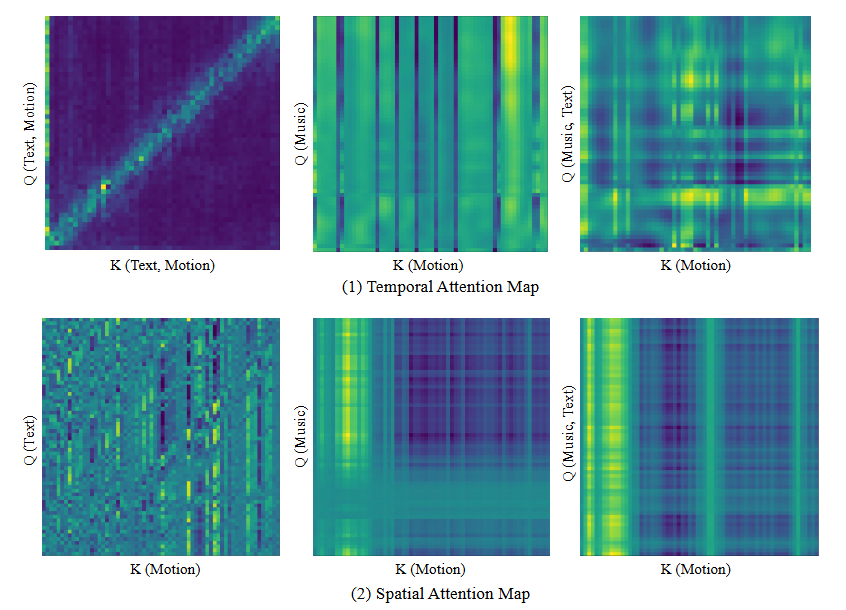
- Query == input condition, Key == output motion.
- 하이라이트된 부분은 high attention score를 갖는 영역임
- 모델이 attention map에서 하이라이트된 부분에 집중한다는 것을 뜻함
- ex) temporal → 모션의 이 프레임은 음악의 어느 부분에 집중해서 만든거고, 이 부분은 텍스트의 이 토큰에 집중해서 만들고, 등등..
- ex) spatial → 텍스트의 “right hand” 부분을 보니, right hand에 집중해서 모션을 만들어야겠군. 음악의 이 부분은 왼팔을 더 써서 만들어야겠군. 등..
- 이는 attention-based temporal & spatial masking에 활용됨
(알고리즘 설명)
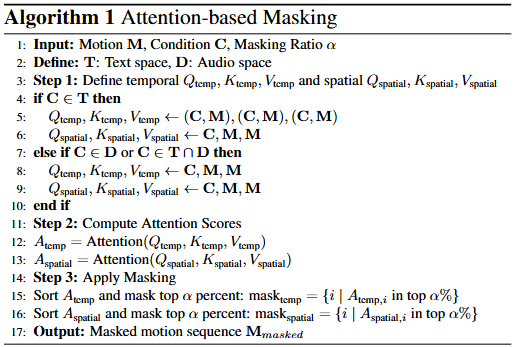
- Input: motion, condition (text, music, text&music), masking ratio
- Step 1: Temporal query & key & value, spatial query & key & value 정의
- Condition이 text라면 (text2motion)
- (Temporal) query & key & value = (text, motion)
- QKV
- (Spatial) query = text, key & value = motion
- Q, KV
- (Temporal) query & key & value = (text, motion)
- Condition이 music or text & music이라면 (music2dance, text&music2dance)
- (Temporal) query = condition, key & value = motion
- (Spatial) query = condition, key & value = motion
- Condition이 text라면 (text2motion)
- Step 2: attention score 계산
- Step 3: masking 적용
- Attention score에 따라 mask 내림차순 정렬 및 상위 a% 마스킹
- “Condition과 관련이 가장 깊은 중요한 모션을 마스킹”
- Output: masking이 적용된 모션 시퀀스
Temporal Adaptive Transformer (TAT)
- 모션의 temporal tokens를 temporal condition과 정렬하는 역할
- 모션의 키 프레임을 텍스트의 키워드, 혹은 음악의 핵심 비트와 맞춤
(알고리즘 설명)

-
Input: motion, condition, mask ratio
-
Step 1: attention-based masking 적용
-
Step 2: query, key, value 정의
- Condition이 text라면 (text2motion)
- Query & key & value = (text, masked motion)
- Condition이 audio or text & audio라면 (music2dance, text&music2dance)
- Query = masked motion, key & value = condition
- Condition이 text라면 (text2motion)
-
Step 3: attention score 계산
- Attention을 통한 masked frame 복원
-
Output: 복원된 모션 시퀀스
-
두 가지 경우
- Condition이 text일 경우 → input sequence에 CLIP token을 포함함. QKV로 구성되어 self-attention 수행
- 그 외에는 모션을 Q, condition을 KV로 사용하여 cross-attention 수행
- Q는 transformer decoder의 input, KV는 encoder에서 넘어옴
Spatial Aligning Transformer (SAT)
- Condition 및 모션에 대한 임베딩을 재배치하여 “관절에 따른 모션” 정보로 변환
- TAT를 통과한 모션 데이터는 (frames, joints)처럼 “시간에 따른 각 관절의 모션”으로 이루어져 있음
- 이를 변형하여 spatial information에 더욱 집중할 수 있도록 rearrange
(알고리즘 설명)

-
Input: motion, condition, mask ratio
-
Step 1: attention-based masking 적용
-
Step 2: Q, K, V 정의
- Q: masked motion
- KV: condition
-
Step 3: attention score 계산 및 마스크 복원
-
Output: 마스크가 복원된 모션 시퀀스
-
Attention-based masking을 통해 각 프레임마다 key action (= 특정 body part의 모션)이 마스킹됨
-
각 프레임 별 spatial pose를 spatial condition과 정렬하는 것은 특히 text2motion에서 중요함
- Text에서 특정 키워드는 특정 body part를 설명하기 때문 (”raise right hand” 등)
- Music2dance의 경우 각 audio frame의 스펙트럼 정보는 그 음악의 장르를 나타냄
3. Experiments
3.1. 데이터셋 & evaluation metrics
TMD 데이터셋
- 2,153 개의 text/music/motion pair 보유
- Motion-X 데이터셋으로부터 dance motion과 이에 대응하는 text annotation을 추출
- Music의 경우 Stable Audio Open이라는 text-to-audio 툴을 이용하여 motion-text pair에 대응하는 음악을 생성하고, 생성된 음악은 전문가 평가를 통해 신뢰성 확보
Public Benchmarks - HumanML3D / KIT-ML로 t2m 평가
- AIST++로 music2dance 평가
Evaluation Metrics - Text to Motion
- FID & R-precision: 생성된 모션의 realism과 robustness를 측정
- MultiModal Distance (MM Distance): 모션과 텍스트의 정렬을 측정
- Diversity: motion feature의 다양성 측정
- MultiModality: 동일한 텍스트에 대해 얼마나 다양한 모션이 생성되는지 측정
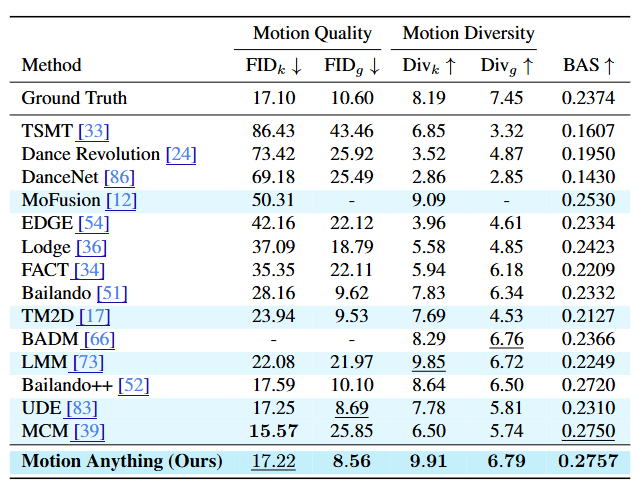
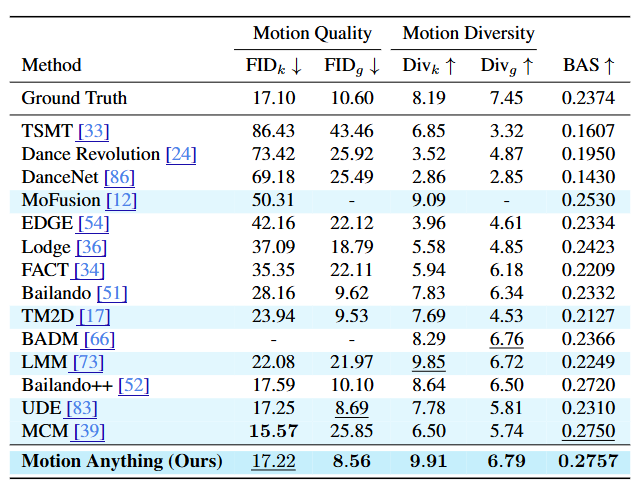
- Music to Dance
- AIST++의 metric 사용 → quality, diversity, music-motion alignment를 측정
- Quality - 생성된 dance와 모션 feature (kinetic & geometric) 사이의 FID 측정
- Diversity - AIST++에서의 평균 feature distance
- Music-motion alignment - Beat Align Score (BAS) 측정
- Music beat와 이에 가장 가까운 dance beat 사이의 평균 temporal distance
3.2. Experimental Results
Text to Motion & Music to Dance 정량 평가 결과
모션 시각화 결과
 <Text to Motion 시각화 결과>
<Text to Motion 시각화 결과>
 <Music to Dance 시각화 결과>
<Music to Dance 시각화 결과>
