
Supervised Learning
supervised learning (지도학습)이란 기계, 즉 학습 알고리즘에게 정답 (labeled data)을 알려주고 학습시키는 것을 말합니다.
이후 학습된 알고리즘에 새로운 input을 집어넣었을 때 얼마나 정확한 답을 예측 predict하는지 확인합니다.
간단하게 예를 들어볼까요?
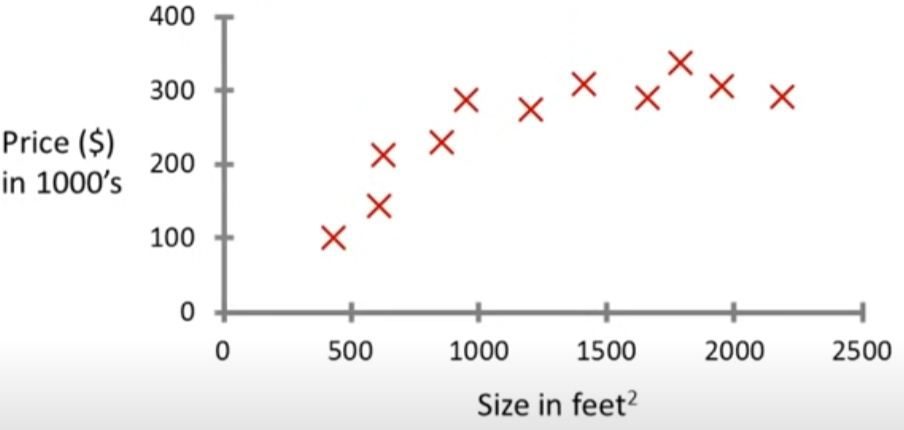
위 그래프에서 가로축은 주택의 면적, 세로축은 주택의 가격을 뜻하며, 이러한 값을 다른 말로는 특징 feature이라고 합니다. 각각의 X는 실제 주택의 값을 담고 있는 labeled data이며, 이처럼 데이터를 모아놓은 집합을 데이터셋 dataset이라고 합니다.
이때 머신러닝 알고리즘은 주어진 데이터셋을 토대로 해당 데이터셋을 가장 잘 표현하는 함수를 찾아내고, 이 함수에 새로운 input을 넣어서 output을 예측하게 됩니다.
ex. 면적이 750인 집이 있을 때, 이 집의 가격은 대략 얼마인가?
다만, 알고리즘이 예측하는 함수의 형태는 1차 함수, 2차 함수 등 다양합니다. 고차원의 함수를 사용할수록 데이터셋을 정확히 표현할 수는 있지만, 새로운 input에 대해 정확한 output을 예측하지 못할 수도 있습니다. 이처럼 학습을 과도하게 해서 실제 데이터에 대한 오차가 증가하는 현상을 오버피팅 overfitting이라고 합니다.
Regression
위의 주택 가격 예시와 같은 학습 문제를 회귀 문제 regression problem라고 합니다.
Regression
"Predict continuous valued output (ex. price)"
⇒ 연속적인 값에 대한 예측
 (출처 : 위키백과)
(출처 : 위키백과)
Classification
또다른 예시를 살펴볼까요?
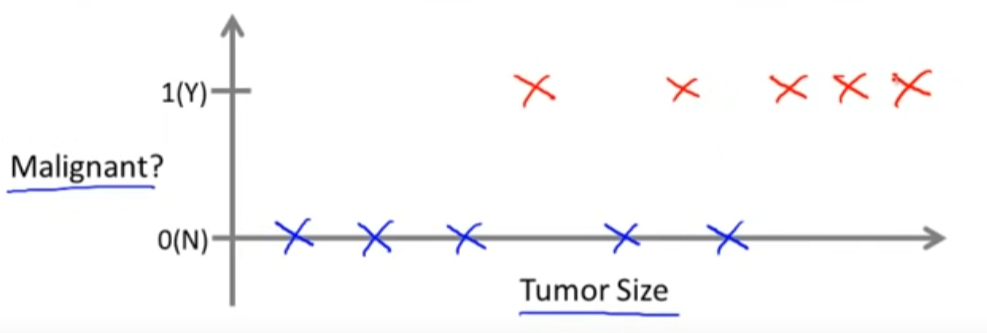
종양 (tumor)의 크기를 통해 암의 진행 정도 (초기 or 말기)를 예측하는 학습 모델이 있다고 가정합시다. 마찬가지로 X는 학습을 위해 주어지는 labeled data이며, 빨간색 X는 말기 암에 대한 데이터 (1)이고, 파란색 X는 초기 암에 대한 데이터입니다.
주어진 데이터셋으로 학습시킨 모델에 새로운 input을 넣게 되면, 해당 종양이 말기 암일 확률을 예측하여 output으로 내보냅니다.
이러한 형태의 학습 문제를 분류 문제 classification problem이라고 합니다.
Classification
"Predict discrete valued output (0 or 1)"
이때 discrete하다는 말은 continuous와 반대되는 말로, 0 또는 1과 같이 하나의 값으로 딱 떨어진다는 것을 의미합니다.
다만 꼭 0, 1처럼 2개의 output으로만 예측하지 않고, 2개 이상의 output을 예측하는 문제 또한 classification이라고 볼 수 있습니다.
ex. 암 초기 / 1기 / 2기 / 3기 / 말기
2개 이상의 feature를 사용하는 classification
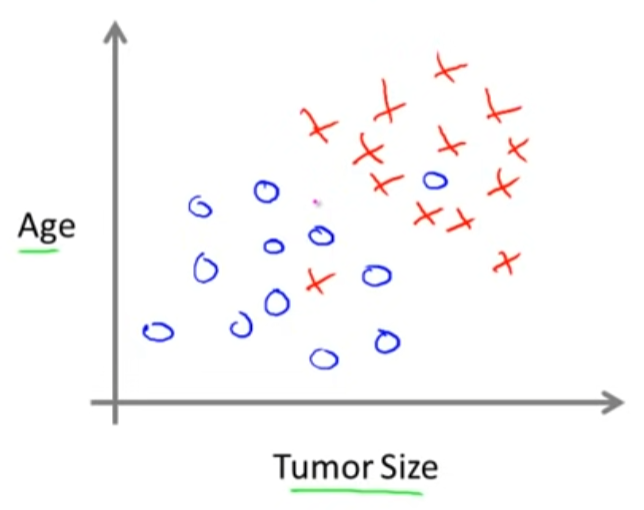
위 예시에서는 종양의 크기, 환자의 나이라는 2개의 feature를 사용하여 classification을 수행합니다.
(1개의 feature를 사용하는 경우 흔히 x축을 feature, y축을 예측값으로 사용했지만, 2개의 feature를 사용하는 위 예시에서는 두 개의 축이 모두 feature를 나타냅니다.)
이때 학습 알고리즘은 주어진 데이터셋을 분석하여 데이터들을 구분할 수 있는 하나의 직선을 찾아냅니다.
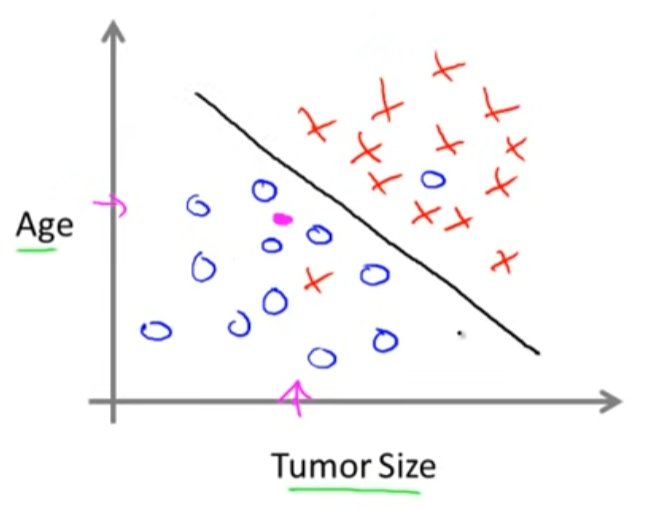
직선을 기준으로 왼쪽에는 파란색 데이터가, 오른쪽에는 빨간색 데이터가 많이 분포하고 있는 모습을 볼 수 있습니다.
이론상으로는 무한히 많은 feature를 사용한 예측도 가능합니다. 하지만 이 모든 feature들을 저장하고 관리하는 일은 결코 쉬운 일이 아닙니다.
이를 처리하기 위해 SVM (Support Vector Machine)이라는 알고리즘이 등장했습니다. SVM을 사용하면 수많은 feature를 효율적으로 관리할 수 있습니다.
Unsupervised Learning
unsupervised learning은 데이터의 label이 정해져있지 않은, 즉 정답이 없는 데이터셋을 통해 학습을 수행합니다.
따라서 supervised learning처럼 "각 데이터가 정확히 무엇을 나타낸다!"라고 단정지을 수 없으며, 전체 데이터셋의 구조 structure를 정의할 수 있습니다.
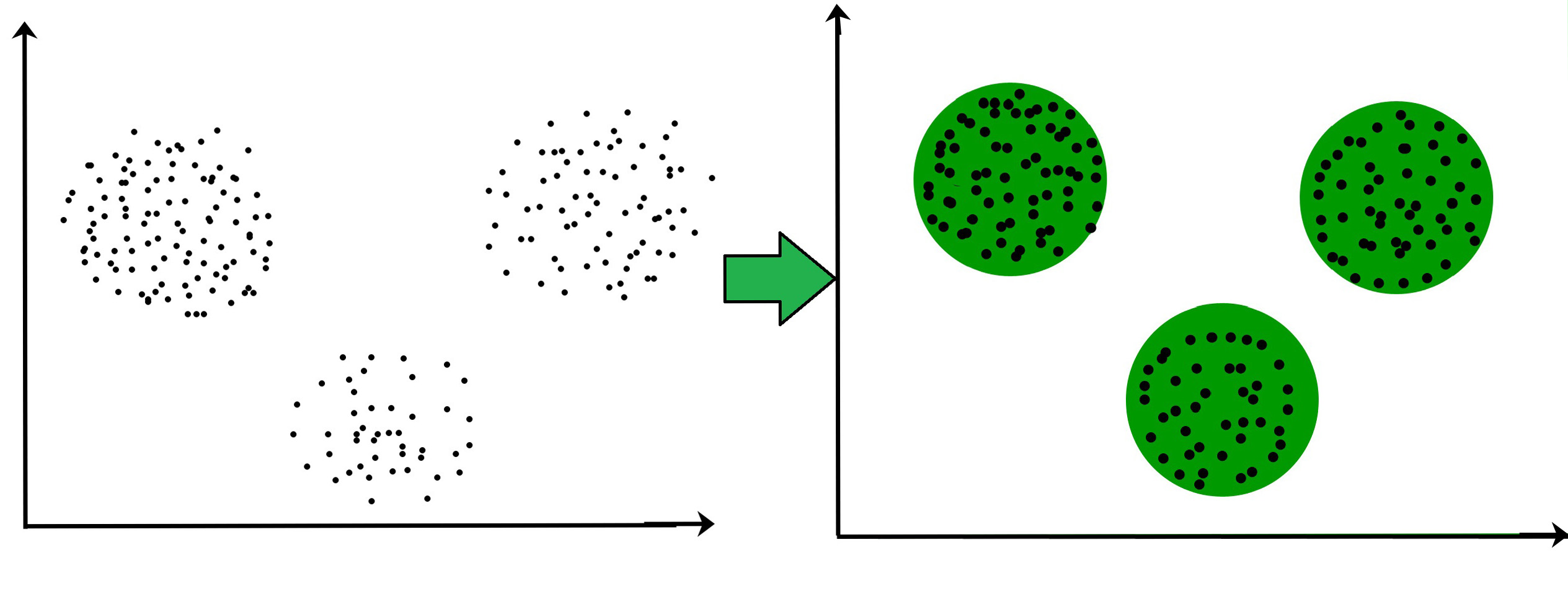
이처럼 학습 데이터들을 여러 개의 군집 cluster으로 나누는 학습 문제를 군집화 문제 clustering problem라고 합니다.
Examples of Unsupervised Learning (== Clustering)
군집화의 사용 예시로는 구글 뉴스가 있습니다.
구글은 수천, 수만 개의 기사를 확인하여 자동으로 동일한 주제에 대한 기사들을 하나의 그룹으로 묶어서 표시합니다.
또다른 유명한 사용 예시로는 칵테일 파티 문제 cocktail party problem가 있습니다.
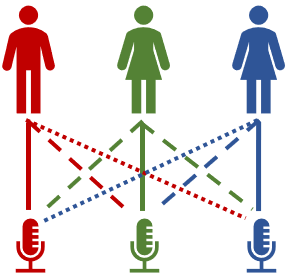
칵테일 파티 문제에서는 여러 명의 화자가 마이크 앞에서 말하는 상황을 가정합니다.
그런데 각 마이크와 화자 사이의 거리가 서로 다르기 때문에 한 마이크에 여러 명의 목소리가 녹음되었더라도 그 음량은 차이가 날 것입니다.
이러한 차이를 분석하여 unsupervised learning을 수행하면, 여러 명의 목소리가 합쳐져 있던 오디오를 각 화자에 대한 음성 데이터로 분리할 수 있게 됩니다.
ex. 음악이 흘러나오는 공간에서 말하는 음성 데이터를 -> 목소리 데이터와 음악 데이터로 분리함
Reference
