Deep learning Flow
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline데이터 가져오기
- TensorFlow에서 제공하는 MNIST 예제
- 데이터 shape, dtype 확인하기
(train_x, train_y), (test_x, test_y) = tf.keras.datasets.mnist.load_data()print(train_x.shape)
print(train_x.dtype)
print(train_y.shape)
print(train_y.dtype)image = train_x[77]
image.shapeplt.imshow(image, 'gray')
plt.show()
- 훈련용 데이터 넷에 각 숫자의 그림이 몇 개인가?
y_unique, y_counts = np.unique(train_y, return_counts=True) # ★df_view = pd.DataFrame(data={'count':y_counts}, index=y_unique)
df_viewdf_view.sort_values('count')plt.bar(x=y_unique, height=y_counts, color = 'black')
plt.title('label distribution')
plt.show()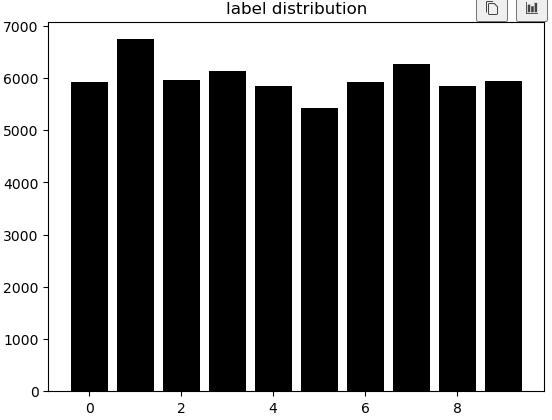
- 이미지 시계 반대 방향으로 90도 회전하고 아래위를 반전시키기
image = tf.constant(image)plt.imshow(image, 'gray')
plt.show()plt.imshow(tf.transpose(image), 'gray')
plt.show()
Preprocessing
-
데이터 검증
-
데이터 중에 학습에 포함 되면 안되는 것이 있는가? ex> 개인정보가 들어있는 데이터, 테스트용 데이터에 들어있는것, 중복되는 데이터
-
학습 의도와 다른 데이터가 있는가? ex> 얼굴을 학습하는데 발 사진이 들어가있진 않은지(가끔은 의도하고 일부러 집어넣는 경우도 있음)
-
라벨이 잘못된 데이터가 있는가? ex> 7인데 1로 라벨링, 고양이 인데 강아지로 라벨링
-
... 등
def validate_pixel_scale(x): return 255 >= x.max() and 0 <= x.min()
validate_train_x = np.array([x for x in train_x if validate_pixel_scale(x)])
validate_train_y = np.array([y for x, y in zip(train_x, train_y) if validate_pixel_scale(x)])
print(validate_train_x.shape)
print(validate_train_y.shape)
- 전처리
- 입력하기 전에 모델링에 적합하게 처리!
- 대표적으로 Scaling, Resizing, label encoding 등이 있다.
- dtype, shape 항상 체크!!
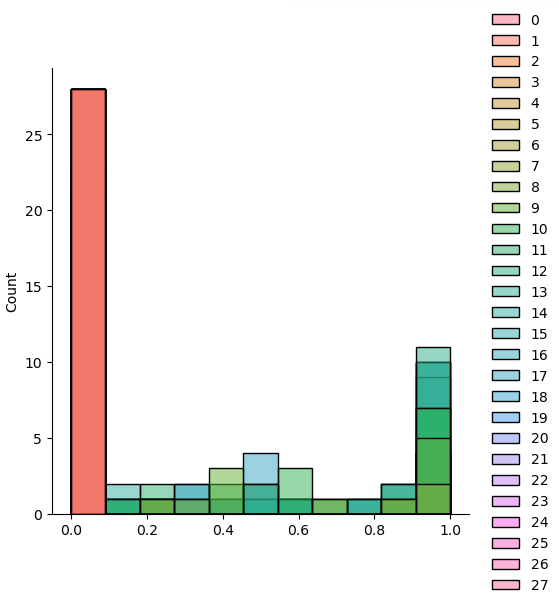
- Scaling
def scale(x):
return (x / 255.0).astype(np.float32)
sample = scale(validate_train_x[777])
sns.displot(sample)
plt.show()
> 
scaled_train_x = np.array([scale(x) for x in validate_train_x])
- Flattening
- 이번에 사용할 모델은 기본적인 Feed-Forward Neural Network
- 1차원 벡터가 Input의 샘플 하나가 된다. (2차원 텐서라는 말)
flatten_train_x = scaled_train_x.reshape((60000, -1))
flatten_train_x
flatten_train_x.shape
- Label encoding
- One-Hot encoding
- `tf.keras.utils.to_categorical` 사용!
tf.keras.utils.to_categorical(5, num_classes=10)
ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validate_train_y])
### 보통은 큰 작업을 하나의 클래스로 만들어서 관리한다.
reshape : https://nov19.tistory.com/101
class DataLoader():
def init(self):
(self.train_x, self.train_y), (self.test_x, self.test_y) = tf.keras.datasets.mnist.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target) if self.validate_pixel_scale(x)])
# scale
scaled_x = np.array([self.scale(x) for x in validated_x])
# flatten
flatten_x = scaled_x.reshape((scaled_x.shape[0], -1))
# label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return flatten_x, ohe_y
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset(self.test_x, self.test_y)mnist_loader = DataLoader()
train_x, train_y = mnist_loader.get_train_dataset()
test_x, test_y = mnist_loader.get_train_dataset()
print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
print(test_y.shape)
<br>
### Modeling
1. 모델 정의
2. 학습 로직 - 비용함수, 학습파라미터 세팅
3. 학습
#### 모델 정의
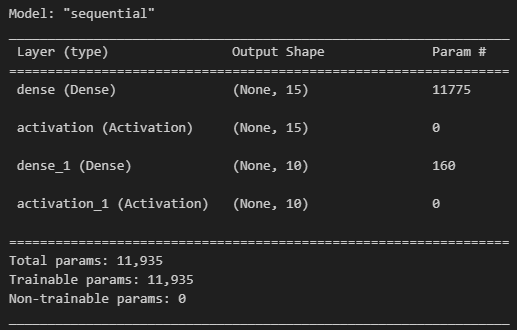
from tensorflow.keras.layers import Dense, Activation
model = tf.keras.Sequential()
model.add(Dense(15, input_dim = 784))
model.add(Activation("sigmoid"))
model.add(Dense(10))
model.add(Activation("softmax"))
model.summary()
> 
#### 학습로직
opt = tf.keras.optimizers.SGD(0.03) # 0.03 = learning rate
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer = opt, loss = loss, metrics= ['accuracy'])
metrics = : 학습 과정에서 모델이 잘 학습하고 있는지, 성능 가늠
#### 학습 실행
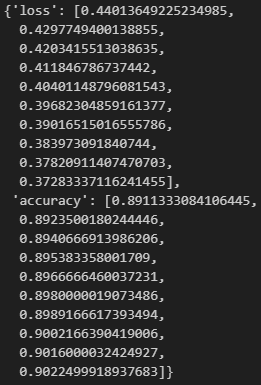
hist = model.fit(train_x, train_y, epochs=10, batch_size=256)
#### Evaluation
- 학습 과정 추적
- Test / 모델 검증
- 후처리
#### 학습 과정 추적
hist.history
> 
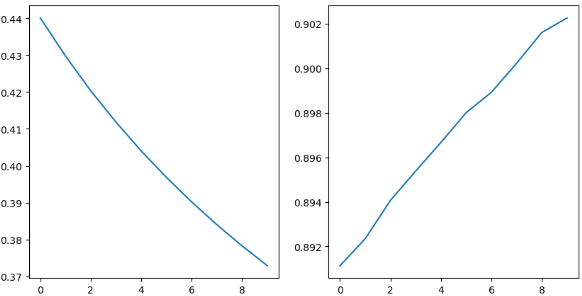
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(hist.history['loss'])
plt.subplot(122)
plt.plot(hist.history['accuracy'])
떨어지거나 올라서 유지되는 구간이 있어야 학습이 잘 된 것, 그렇지 않으면 epoch를 더 늘려보는 것이 좋음
> 
#### 모델 검증
model.evaluate(test_x, test_y)
> 
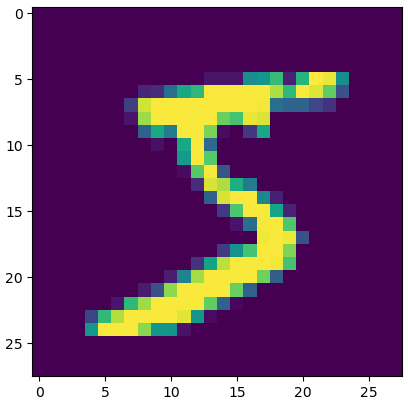
#### 후처리pred = model.predict(test_x[:1])
pred.argmax()
sample_img = test_x[0].reshape((28, 28))*255 # 다시 원래대로
test_y[0]
plt.imshow(sample_img)
plt.show()
> 
> 어렵다...
💻 출처 : 제로베이스 데이터 취업 스쿨