Mask man classification - OX분류
from glob import globtrain_raw_0_list = glob('./data/OX_clf/train_raw/O/*')
train_raw_0_list
#!pip install scikit-image#skimage
from skimage.transform import rescale, resize
from skimage import color
from skimage.io import imread, imsave
import matplotlib.pyplot as plt# 어떤 이미지가 있는지 확인
train_raw_0_list = train_raw_0_list[2:]
image = imread(train_raw_0_list[0])
image = color.rgb2gray(image)
plt.imshow(image, cmap='gray')
# resize 시키기
img_resized = resize(image, (28, 28))
print(img_resized.shape)
plt.imshow(img_resized, cmap='gray')
# 저장하기
import numpy as np
imsave('./tmp.png', np.round(img_resized*255).astype(np.uint8))
# img_resized*255 : 0 - 1 사이의 값을 픽셀값으로 복원# 다시 확인
tmp = imread('./tmp.png')
print(tmp.shape)
plt.imshow(tmp, cmap='gray')# 파일이름 추출 연습
train_raw_0_list[0].split('\\')[-1][:-4]# 이미지 resize함수 생성
def img_resize(img):
img = color.rgb2gray(img)
return resize(img, (28, 28))# train_0
from tqdm.notebook import tqdm
def convert_train_0():
train_raw_0_list = glob('./data/OX_clf/train_raw/O/*')
train_raw_0_list = train_raw_0_list[2:]
for each in tqdm(train_raw_0_list):
img = imread(each)
try:
img_resized = img_resize(img)
#print('./data/OX_clf/train/O/' + each.split('\\')[-1][:-4]+'.png')
save_name = './data/OX_clf/train/O/' + each.split('\\')[-1][:-4] + '.png'
imsave(save_name, np.round(img_resized*255).astype(np.uint8))
except:
pass
convert_train_0()# train_X
from tqdm.notebook import tqdm
def convert_train_0():
train_raw_0_list = glob('./data/OX_clf/train_raw/X/*')
#train_raw_0_list = train_raw_0_list[2:]
for each in tqdm(train_raw_0_list):
img = imread(each)
try:
img_resized = img_resize(img)
#print('./data/OX_clf/train/X/' + each.split('\\')[-1][:-4]+'.png')
save_name = './data/OX_clf/train/X/' + each.split('\\')[-1][:-4] + '.png'
imsave(save_name, np.round(img_resized*255).astype(np.uint8))
except:
pass
convert_train_0()# test_O
from tqdm.notebook import tqdm
def convert_test_0():
train_raw_0_list = glob('./data/OX_clf/test_raw/O/*')
#train_raw_0_list = train_raw_0_list[2:]
for each in tqdm(train_raw_0_list):
img = imread(each)
try:
img_resized = img_resize(img)
#print('./data/OX_clf/train/O/' + each.split('\\')[-1][:-4]+'.png')
save_name = './data/OX_clf/test/O/' + each.split('\\')[-1][:-4] + '.png'
imsave(save_name, np.round(img_resized*255).astype(np.uint8))
except:
pass
convert_test_0()# test_X
from tqdm.notebook import tqdm
def convert_test_X():
train_raw_0_list = glob('./data/OX_clf/test_raw/X/*')
#train_raw_0_list = train_raw_0_list[2:]
for each in tqdm(train_raw_0_list):
img = imread(each)
try:
img_resized = img_resize(img)
#print('./data/OX_clf/test/X/' + each.split('\\')[-1][:-4]+'.png')
save_name = './data/OX_clf/test/X/' + each.split('\\')[-1][:-4] + '.png'
imsave(save_name, np.round(img_resized*255).astype(np.uint8))
except:
pass
convert_test_X()# 모듈
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.preprocessing.image import ImageDataGenerator
import keras
np.random.seed(13)# ImageDataGenerator : 폴더로 데이터를 정리했을 때 사용하기 편함 https://srgai.tistory.com/16
train_datagen = ImageDataGenerator(rescale=1/255) # 0 - 1 사이의 값으로 설정
train_generator = train_datagen.flow_from_directory(
'./data/OX_clf/train/',
target_size=(28, 28),
batch_size=3, # 몇 개의 샘플로 가중치를 갱신할 것인지 설정
class_mode='categorical')
test_datagen = ImageDataGenerator(rescale=1/255)
test_generator = test_datagen.flow_from_directory(
'./data/OX_clf/test/',
target_size=(28, 28),
batch_size=3,
class_mode='categorical'
)# 모델 구성
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 3)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))# compile
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# fit
hist = model.fit_generator(
train_generator, steps_per_epoch=15,
epochs=50, validation_data=test_generator, validation_steps=5)# 학습상황 그리기
plt.figure(figsize=(12, 6))
plt.plot(hist.history['loss'], label='loss')
plt.plot(hist.history['val_loss'], label='val_loss')
plt.plot(hist.history['accuracy'], label='accuracy')
plt.plot(hist.history['val_accuracy'], label='val_accuracy')
plt.legend()
plt.show()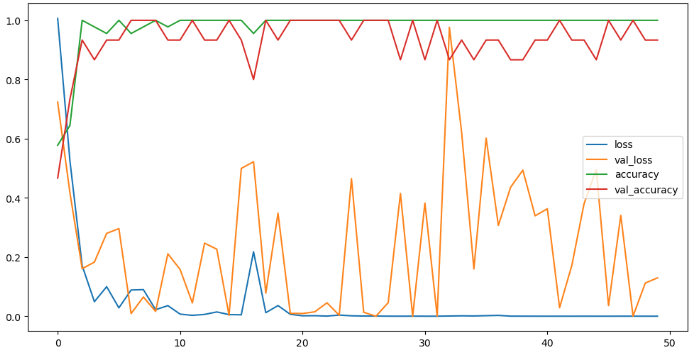
# 테스트 데이터에서 predict 확률
scores = model.evaluate(
test_generator,
steps = 5
)
print('%s : %.2f%%' %(model.metrics_names[1], scores[1]*100))model.predict(test_generator)n = 1
def show_prdiction_result(n):
img = imread(test_generator.filepaths[n])
pred = model.predict(np.expand_dims(color.gray2rgb(img), axis = 0))
title = 'Predict : ' + str(np.argmax(pred))
plt.imshow(img/255, cmap='gray')
plt.title(title)
plt.show()
show_prdiction_result(n)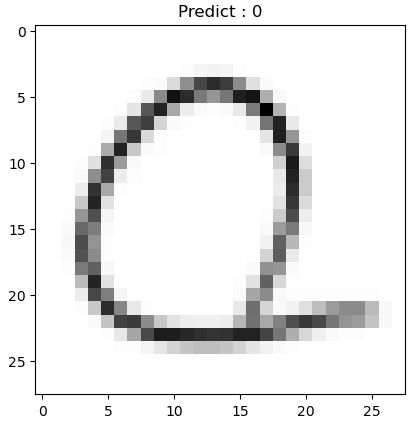
show_prdiction_result(40)
💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅