RNN
-
simple RNN : 순환신경망
- 활성화 신호가 입력에서 출력으로 한 방향으로 흐르는 피드포워드 신경망
- 순환 신경망은 뒤쪽으로 연결하는 순환 연결이 있음
- 순서가 있는 데이터를 입력으로 받고
- 변화하느 ㄴ입력에 대한 출력을 얻음 -
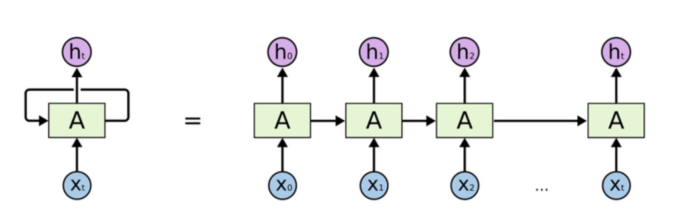
메모리셀 : 순환 뉴런의 출력은 이전 시간의 모든 입력에 대한 함수이므로 이를 메모리 형태라고 말할 수 있음. 타임스텝에 걸쳐서 어떤 상태를 보존하는 신경망의 구성요소를 메모리셀이라고 함
-
sequence-to-sequence 형태 : 주식가격과 같은 시계열 데이터 예측에 사용. 최근 N일치의 주식가격을 주입하면 네트워크는 각 입력값보다 하루 앞선 가격을 출력
# import
import tensorflow as tf
import numpy as np# time stamp 데이터 생성
X = []
Y = []
for i in range(6):
lst = list(range(i, i+4))
X.append(list(map(lambda c: [c/10], lst)))
Y.append((i+4)/10)
X = np.array(X)
Y = np.array(Y)
for i in range(len(X)):
print(X[i], Y[i])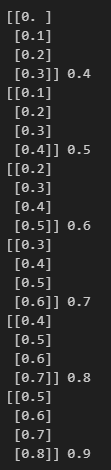
# simple RNN 구성
# input_shape이 4, 1이라는 것 (timesteps가 4, input_dim이 1)
# units : simpleRNN 레이어에 존재하는 뉴런의 수
# return_sequences는 출력으로 시퀀스 전체를 출력할지 여부
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(units = 10, return_sequences = False, input_shape=[4, 1]),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()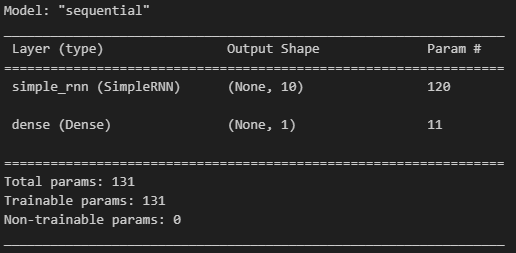
# 학습
model.fit(X, Y, epochs=100, verbose=0)# 예측결과
model.predict(np.array([[[0.6], [0.7], [0.8], [0.9]]]))model.predict(np.array([[[-0.1], [0.0], [0.1], [0.2]]]))# 모델을 복잡하게 생성
# 파라미터 증가
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(units = 10, return_sequences = True, input_shape=[4, 1]),
tf.keras.layers.SimpleRNN(units = 10, return_sequences = True, input_shape=[4, 1]),
tf.keras.layers.SimpleRNN(units = 10, return_sequences = True, input_shape=[4, 1]),
tf.keras.layers.SimpleRNN(units = 10, return_sequences = True, input_shape=[4, 1]),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()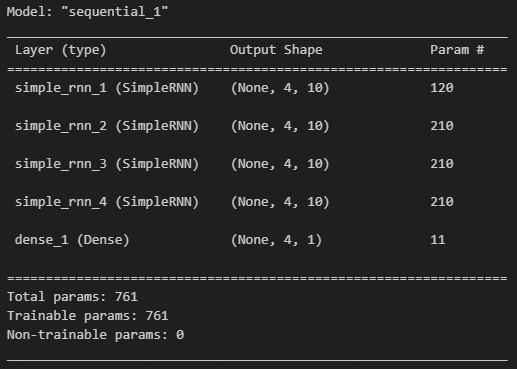
# 다시 훈련
model.fit(X, Y, epochs=100, verbose=1)# 결과
model.predict(np.array([[[0.6], [0.7], [0.8], [0.9]]]))RNN - LSTM
-
simple RNN의 단점 : 입력 데이터가 길어지면 학습 능력이 떨어진다 - Long-Term Dependency 문제. 현재의 답을 얻기 위해 과거의 정보에 의존해야 하는 RNN이지만, 과거 시점이 현재와 너무 멀어지면 문제를 풀기 어렵다.
-
LSTM :
- simple RNN의 장기 의존성 문제를 해결하기 위한 알고리즘
- time step을 가로지르며 셀 상태가 보존
- 모델을 명시적으로 나열한 개념 -
cell-state
# LSTM의 성능을 확인하기 위해 제시한 문제
X = []
Y = []
for i in range(3000):
lst = np.random.rand(100)
idx = np.random.choice(100, 2, replace=False)
zeros = np.zeros(100)
zeros[idx] = 1
X.append(np.array(list(zip(zeros, lst))))
Y.append(np.prod(lst[idx]))
print(X[0], Y[0])# RNN으로 풀기
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(units=30, return_sequences=True, input_shape=[100, 2]),
tf.keras.layers.SimpleRNN(units=30),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()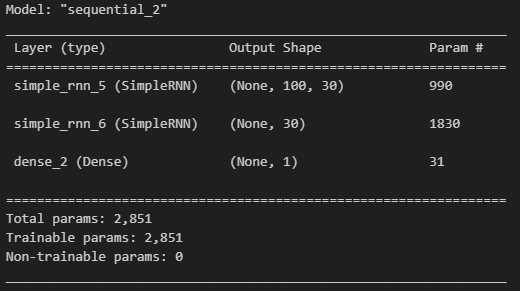
# 훈련
X = np.array(X)
Y = np.array(Y)
history = model.fit(X[:2560], Y[:2560], epochs=100, validation_split=0.2)import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()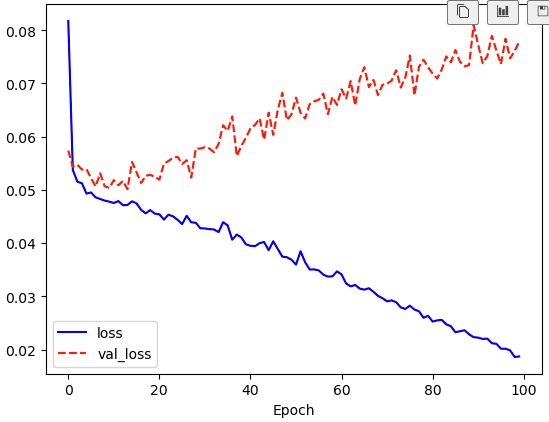
# LSTM
model = tf.keras.Sequential([
tf.keras.layers.LSTM(units=30, return_sequences=True, input_shape=[100, 2]),
tf.keras.layers.LSTM(units=30),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse')
model.summary()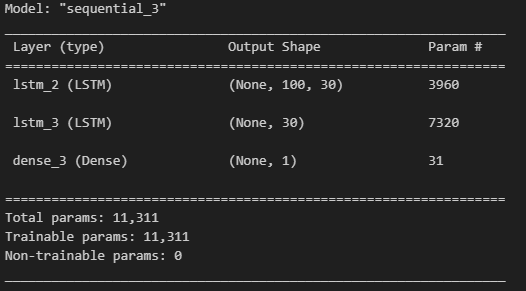
# 동일하게 훈련
X = np.array(X)
Y = np.array(Y)
history = model.fit(X[:2560], Y[:2560], epochs=100, validation_split=0.2)plt.plot(history.history['loss'], 'b-', label='loss')
plt.plot(history.history['val_loss'], 'r--', label='val_loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()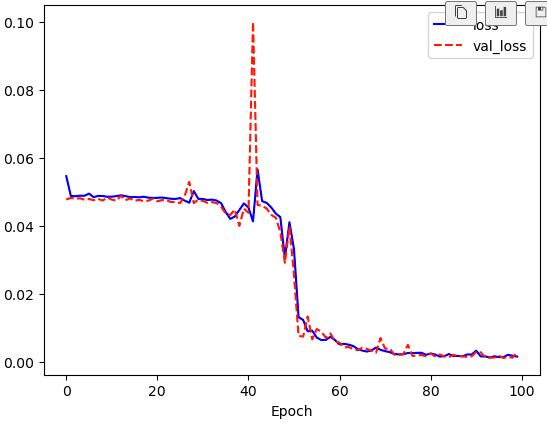
RNN - 감성분석
- 감성분석 (Sentiment Analysis) : 입력된 자연어 안의 주관적 의견, 감정 등을 찾아내는 문제. 이중 문장의 긍정/부정 등을 구분하는 경우가 많음
# 내용 확인
train_text = open('./data/nsmc-master/ratings_train.txt', 'rb').read().decode(encoding='utf-8')
test_text = open('./data/nsmc-master/ratings_test.txt', 'rb').read().decode(encoding='utf-8')
print('Length of text : {} characters' .format(len(train_text)))
print('Length of text : {} characters' .format(len(test_text)))
print()
print(train_text[:300])
train_text[:300]# 줄바꿈
train_text.split('\n')# 탭문자
train_text.split('\n')[:3]# 라벨
train_text.split('\n')[3]train_text.split('\n')[3].split('\t')import numpy as np
train_Y = np.array([[int(row.split('\t')[2])] for row in train_text.split('\n')[1:] if row.count('\t')>0])
test_Y = np.array([[int(row.split('\t')[2])] for row in test_text.split('\n')[1:] if row.count('\t')>0])
print(train_Y.shape, test_Y.shape)
print(train_Y[:5])
- tokenization : 자연어를 처리 가능한 최소의 단위로 나누는 것으로 여기서는 띄어쓰기
- cleaning : 불필요한 기호 제거
import re
def clean_str(string):
string = re.sub(r"[^가-힣A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)s", " \) ", string)
string = re.sub(r"\?", " \?", string)
string = re.sub(r"\s{2,}", " ", string)
string = re.sub(r"\'{2,}", " \'", string)
string = re.sub(r"\'", "", string)
return string.lower()
# 훈련용 데이터 확보
train_text_X = [row.split('\t')[1]
for row in train_text.split('\n')[1:] if row.count('\t') > 0]
train_text_X = [clean_str(sentence) for sentence in train_text_X]
sentences = [sentence.split(' ') for sentence in train_text_X]
for i in range(5):
print(sentences[i])
import matplotlib.pyplot as plt
%matplotlib inline
sentence_len = [len(sentence) for sentence in sentences]
sentence_len.sort()
plt.plot(sentence_len)
plt.show()
print(sum([int(l<=25) for l in sentence_len]))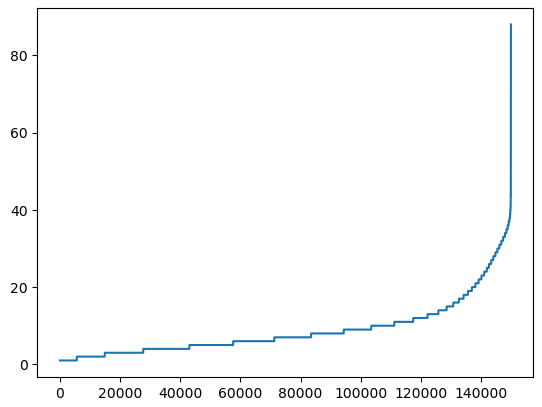
- 데이터 크기 맞추기
- 학습을 위해 네트워크에 입력을 넣을 때 입력 데이터는 그 크기가 같아야 한다
- 여기서는 입력 벡터의 크기를 맞추기 위해 긴 문장은 줄이고, 짧은 문장은 공백으로 채움
- 15만개의 문장 중에 대부분이 40단어 이하로 되어 있음
# 정제
sentences_new = []
for sentence in sentences:
sentences_new.append([word[:5] for word in sentence][:25])
sentences = sentences_new
for i in range(5):
print(sentences[i])
# tokenizing, padding
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words = 20000)
tokenizer.fit_on_texts(sentences)
train_X = tokenizer.texts_to_sequences(sentences)
train_X = pad_sequences(train_X, padding='post')
print(train_X[:5])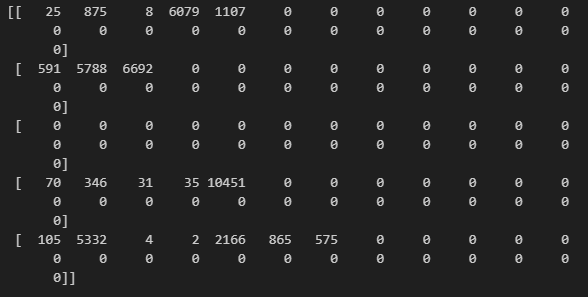
# 모델구성
# 파라미터 수가 굉장히 큼
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Embedding(20000, 300, input_length=25),
tf.keras.layers.LSTM(units=50),
tf.keras.layers.Dense(2, activation='softmax') # 긍정, 부정 두 가지를 보기 위해..
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()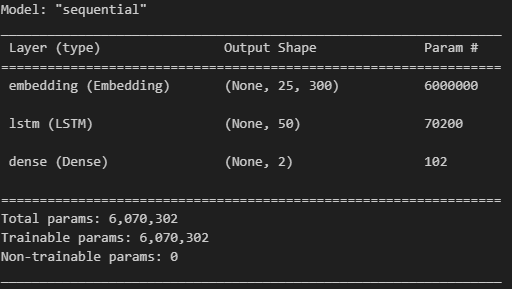
- 임베딩 레이어 (Embedding Layer) :
- 자연어를 수치화된 정보로 바꾸기 위한 레이어
- 자연어는 시간의 흐름에 따라 정보가 연속적으로 이어지는 시퀀스 데이터
- 영어는 문자 단위, 한글은 문자를 넘어 자소 단위로도 쪼개기도 함. 혹은 띄어쓰기나 형태소로 나누기도 함
- 여러 단어를 묶어서 사용하는 n-gram 방식도 있음
- 원핫인코딩까지 포함
# 학습
history = model.fit(train_X, train_Y, epochs=5, batch_size=128, validation_split=0.2)# 테스트
test_sentence = '재미있을 줄 알았는데 완전 실망했다. 너무 졸리고 돈이 아까웠다'
test_sentence = test_sentence.split(' ')
test_sentences = []
now_sentence = []
for word in test_sentence:
now_sentence.append(word)
test_sentence.append(now_sentence[:])
test_X_1 = tokenizer.texts_to_sequences(test_sentences)
test_X_1 = pad_sequences(test_X_1, padding='post', maxlen=25)
prediction = model.predict(test_X_1)
for idx, sentence in enumerate(test_sentences):
print(sentence)
print(prediction[idx])너무너무 어렵다 ㅠㅠ...
💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅