GPT
자연어 데이터만의 특징
-
Tabular Dataset : 각각의 샘플들이 구성하고 있는 features는 독립적
-
이미지 : 이미지 안에 의미있는 정보는 위치에 무관. Convolution 연산은 위치에 무관한 지역적인 정보를 추출하기 좋은 연산
-
자연어 데이터(문장)의 경우, 문장을 구성하고 있는 단어들의 위치가 변해서는 안됨. 단어들 간의 관계가 중요하고 하나의 단어만 바뀌거나 추가되어도 전혀 다른 의미(context)를 가질 수 있음
-
GPT를 구성하고 있는 모델은 Transformer에서 가져온 것이다.
-
Bert, GPT의 경우 특히 자연어 데이터에 특화된 프레임 워크이다. 자연어 데이터는 단어와 단어들 사이의 순서와 관계가 중요하다. 문장이 갖고 있는 문맥을 알고리즘이 이해할 수 있게 하는 것이 어렵다.
자연어 데이터의 토큰화(문장을 의미있는 단위로 쪼개는 것)
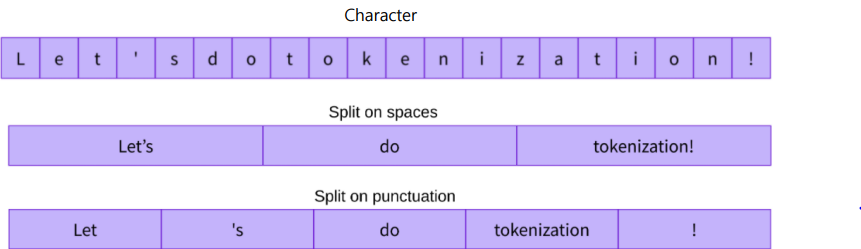
자연어 데이터의 토큰화
-
Character :
- A → 1, B → 2, ... 문장의 시계열 길이가 너무 늘어남
- 각각의 문자는 의미를 가지고 있지 않음 → 결국 단어로 표현을 해야 함 -
Word :
- 경우의 수가 너무 많음
- 특히 사전에 없는 단어가 생길 위험 -
Hugging face와 같은 대중적인 공유 라이브러리가 존재하기 전까지 연구자들이 각각 토큰화를 임의로 진행했음. 이에 따라서 모델을 다운받아 실행시킬 경우 전혀 다른 결과가 나타남. 즉, 자연어에서의 토큰처리 과정에 대해 아는 것이 중요
자연어 처리 Task
- 하나의 문장을 여러 개로 나누고 나눈 토큰들의 결합분포로 문장에 대해서 확률을 계산



자연어 처리 metric
- BLEU(Bilingual evaluation understudy)
- based on n-gram based precision (한번에 단어를 몇 개를 볼 것인가..)
- A measure of fluency rather than semantic similarity between two sentences - Rouge (Recall Oriented Understudy of Gisting Evaluation)
- METEOR (Metric for Evaluation of Translation with Explicit ORdering)
- Text metrics
- Human based measures
- Success@k = % image sentence pairs for which at least on relevant result is found in the top-k list
- R-precision = average % of relevant items in ther top-k list
자연어 처리 기존 연구
-
어떠한 한 문장을 분류하거나 혹은 이 문장을 내포하고 있는 어떤 벡터로 표현하고 싶다. 기존의 이미지나 Tabular 데이터와는 다르게 각각의 순서가 매우 중요하다.
-
문장의 문맥을 하나의 벡터로 표현하기 위해서 인코딩
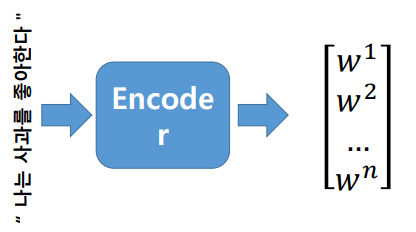
-
문맥을 알아내는 Encoder를 학습했다면 다양한 Task에 적용이 가능
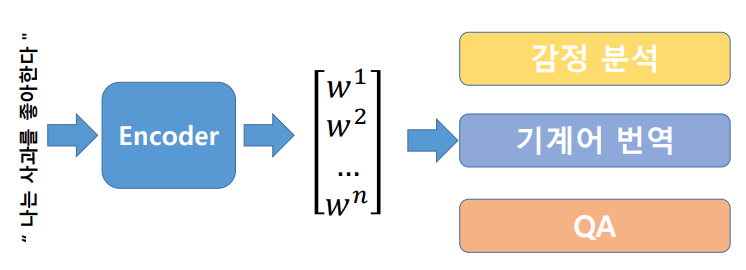
-
문장은 순서를 가지고 있으니, 문장의 처음부터 끝까지 순서대로 입력을 받아서 최종적으로 벡터를 생성
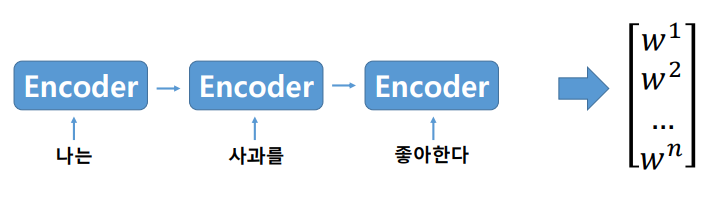
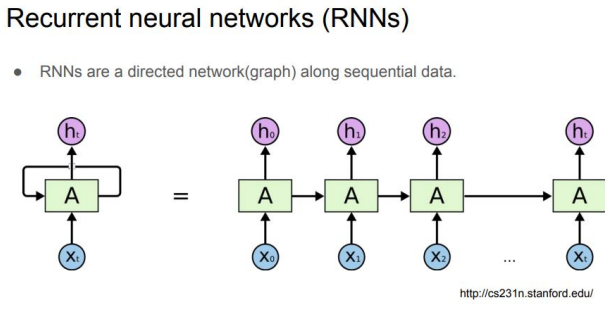
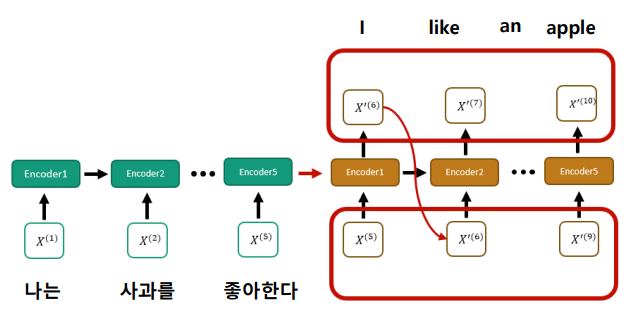
- 자연어 데이터의 순차적인 특성을 고려하는 기존 연구들. 문장마다의 중요도를 계산하여 attention 모듈을 생각해 냄.

선형대수 기초
https://ko.wikipedia.org/wiki/%EB%82%B4%EC%A0%81_%EA%B3%B5%EA%B0%84

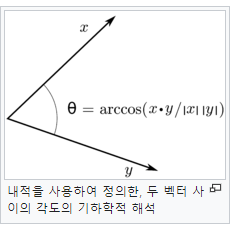
-
Cos 유사도와 벡터의 관계(Cos 유사도가 벡터의 내적과 유사)
-
벡터의 내적과 거리의 관계, KL divergence
-
Softmax
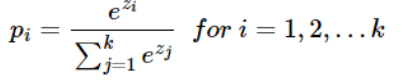
너무너무 어렵다 ㅠㅠ...
💻 출처 : 제로베이스 데이터 취업 스쿨
