YOLO
- Classification : 주어진 데이터를 주어진 라벨(클래스)에 의해 분류하는 법을 학습
- Clustering : 주어진 데이터를 데이터의 특징에 의해 스스로를 클래스로 분류
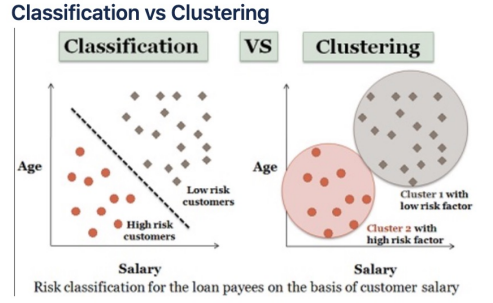
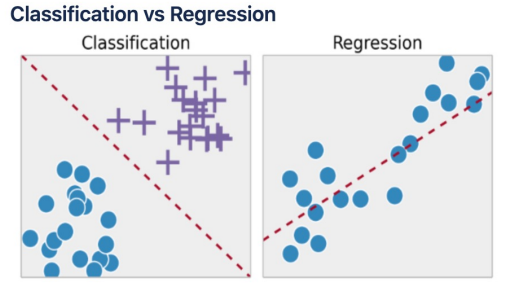
- Classification : 주어진 데이터가 어떤 라벨(클래스)인지 예측하는 것. discrete한 output을 가짐
- Regression : 주어진 데이터의 경향성을 파악하고 함수를 예측하는 것. 연속적인 output을 가짐
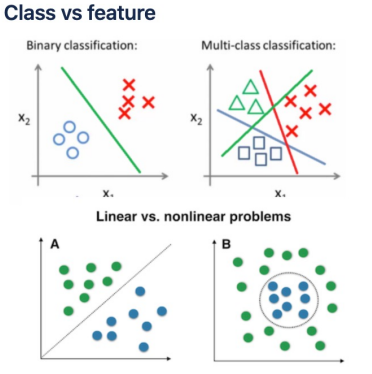
- Class의 수 : Binary class와 multi class의 경우 등. 분류하고자 하는 class에 따라서 다른 접근법 사용
- Data Feature의 특징 : Data의 분포 특성에 따라서 더 적합한 classifier를 사용하는 것이 바람직하다
- 전처리 : data에서 유의미한 특징(feature)들을 뽑아내어 input으로 넣는 과정(머신러닝은 필수)
- End to End : 전처리 과정. feature engineering없이 데이터마 ㄴ넣으면 알아서 학습하여 input을 넣으면 output이 나오는 모델
- CNN
- Feature extraction : 특징을 추출하기 위한 단계 → Receptive field, Convolution filter
- Shift and distortion invariance : Topology 변화에 영향을 받지 않기 위한 단계 → subsampling(max pooling)
- Classification : 분류기 단계 → fully conneted output

- Object Detection = Multi-Labeled Classification + Bounding Box Regression(Localization) : Object Detection = 여러가지 물체에 대한 Classification + 물체의 위치정보를 파악하는 Localization. ex) 자율주행 자동차, Aerial Image 분석, CCTV감시, 스포츠 경기분석, 무인점포, 불량 제품 검출
- 2-Stage Detector : Regional Proposal와 Classification이 순차적으로 이루어짐. ex) R-CNN계열
- 1-Stage Detector : Regional Proposal와 Classification이 동시에 이루어짐. ex) YOLO계열, SSD계열
YOLO
- 초기에 앵커박스(anchor box)를 생성하여 Bounding box를 예측
- 초기 앵커박스 생성 시 해당 박승의 신뢰도(confidence)
- 해당 그리드에 물체가 있을 확률 Pr(Object)과 예측한 박스와 Ground Truth 박스와 겹치는 영역을 비율을 나타내는 IoU를 곱해서 계산
- 각각의 그리드마다 C개의 클래스에 대하여 해당 클래스일 확률을 계산
너무너무 어렵다 ㅠㅠ...
💻 출처 : 제로베이스 데이터 취업 스쿨

#데이터분석 #퍼포먼스마케팅 #데이터 #디지털마케팅