
아래에 정리된 모든 내용은 박해선 저자님의 '혼자 공부하는 머신러닝 + 딥러닝' 책에 담긴 내용입니다.
1. 인공지능과 머신러닝, 딥러닝
본격적인 내용에 들어가기 전에,
인공지능과 머신러닝, 딥러닝이 무엇인지, 각각의 차이점은 무엇인지 알아보자.
인공지능(artificial intelligence)
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터를 만드는 기술
- 강인공지능 / 약인공지능으로 나뉜다
- 강인공지능 (Strong AI) : 사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템 ( = 인공일반지능)
- 약인공지능 (Weak AI) : 특정 분야에서 사람의 일을 도와주는 보조 역할을 하는 컴퓨터 시스템 ( ex. 음성 비서, 자율 주행 자동차, 음악 추천 등)
머신러닝(machine learning)
- 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 인공지능의 하위 분야 중에서 지능을 구현하기 위한 소프트웨어를 담당하는 핵심분야
- 대표적인 머신러닝 라이브러리 :
사이킷런(scikit-learn)- 파이썬 API 사용
딥러닝(deep learning)
- 머신러닝 알고리즘 중 인공 신경망(artificial neural network)을 기반으로 한 알고리즘
이세돌 9단을 이긴 알파고도 딥러닝을 통해 만들어진 인공지능- 대표적인 딥러닝 라이브러리 :
텐서플로(TensorFlow)- 구글,파이토치(PyTorch)- 페이스북- 위 라이브러리들의 공통점 : 인공 신경망 알고리즘을 전문으로 다룸, 파이썬 API 제공
요약
💡 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템인 '인공지능'에서,
💡 '지능'을 구현하기 위한 소프트웨어를 담당하는 분야가 머신러닝이다.
💡 지능을 구현할 때 사용하는 알고리즘은 매우 다양한데, 그중 인공 신경망을 기반으로 하는 방법들을 통칭하여 딥러닝이라고 한다.
2. 코랩과 주피터 노트북
이 책에서는 머신러닝&딥러닝 프로그램을 만들기 위해 구글 코랩(Colab)을 사용한다.
코랩(Colab)

코랩(Colab)은 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스로,
클라우드 기반의 주피터 노트북 개발환경이다.
💡 코랩: 구글이 대화식 프로그래밍 환경인 주피터(Jupyter)를 커스터마이징한 것
코랩으로 머신러닝 프로그램도 만들 수 있으며, 컴퓨터 성능과 상관없이 머신러닝 프로그램을 실습해 볼 수 있다.
구글 계정이 없어도 코랩에 접속할 수 있으나 코드를 실행할 수 없으니 로그인 후 사용하길 권장한다.
(코랩 URL: https://colab.research.google.com/?hl=ko)
코랩 URL에 접속할면 위 화면이 뜬다.
이 페이지를 노트북 혹은 코랩 노트북이라 한다.
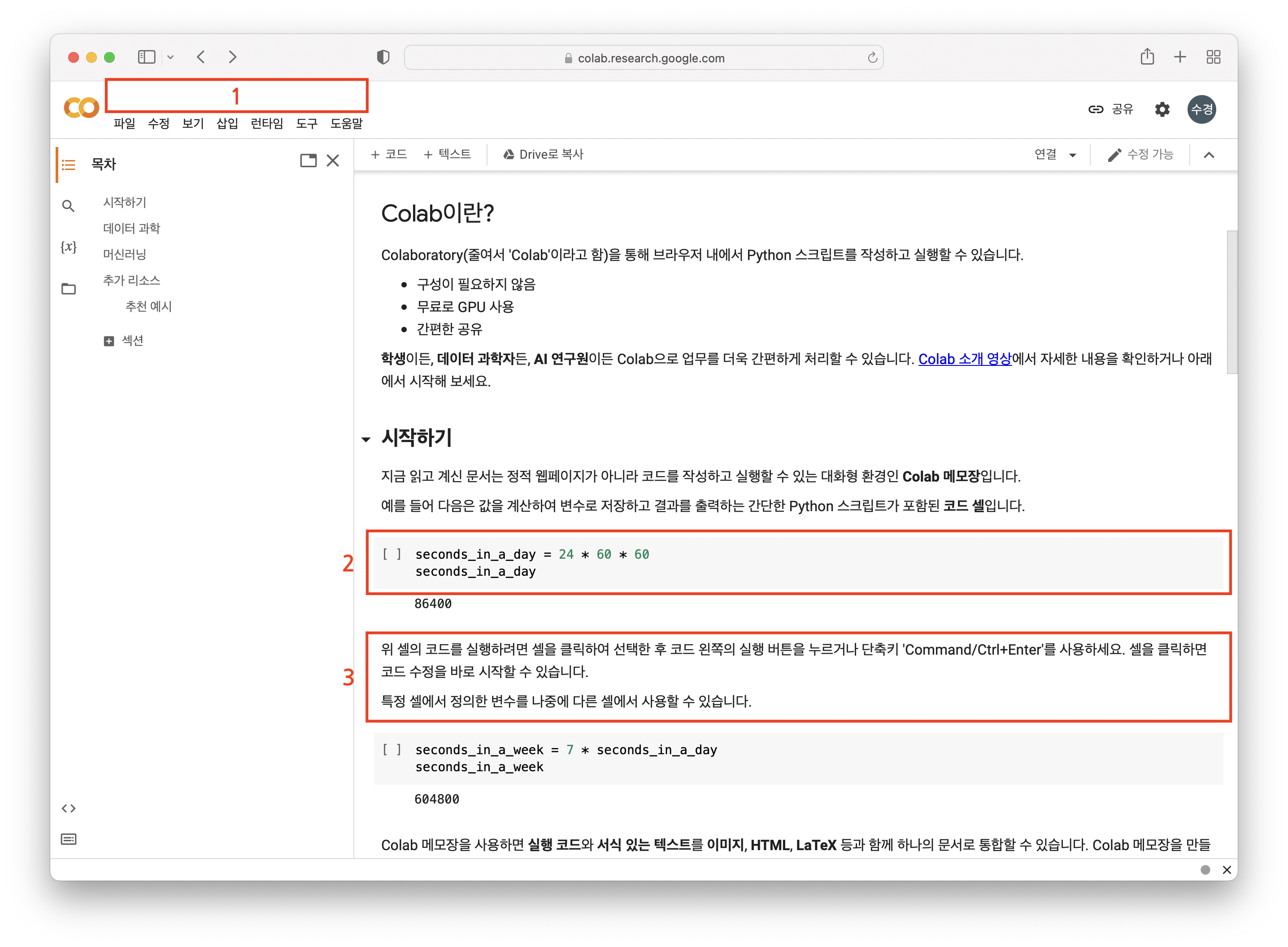
- 노트북의 제목
- 코드 셀(cell)
- 텍스트 셀
로 구성되어 있다.
코랩 노트북에서의 셀(cell) 은 코드 또는 텍스트의 덩어리로, 코랩에서 실행할 수 있는 최소 단위이다.
노트북은 보통 여러 개의 코드 셀과 텍스트 셀로 이루어져 있다.
텍스트 셀과 코드 셀이 무엇인지, 어떤 기능을 사용할 수 있는지 알아보자.
텍스트 셀
- 실행되는 코드가 아닌, 텍스트를 담을 수 있는 공간
- 코드를 설명하는 글을 쓰는 등 자유롭게 사용할 수 있다.
- 셀 하나에 아주 긴 글을 써도 되고 여러 셀에 나누어 작성해도 된다.
- 텍스트 셀을 수정하려면 원하는 셀로 이동한 후 Enter 키를 누르거나 마우스를 더블 클릭하여 편집 화면으로 이동할 수 있다.
- HTML과 마크다운을 혼용하여 사용할 수 있다.
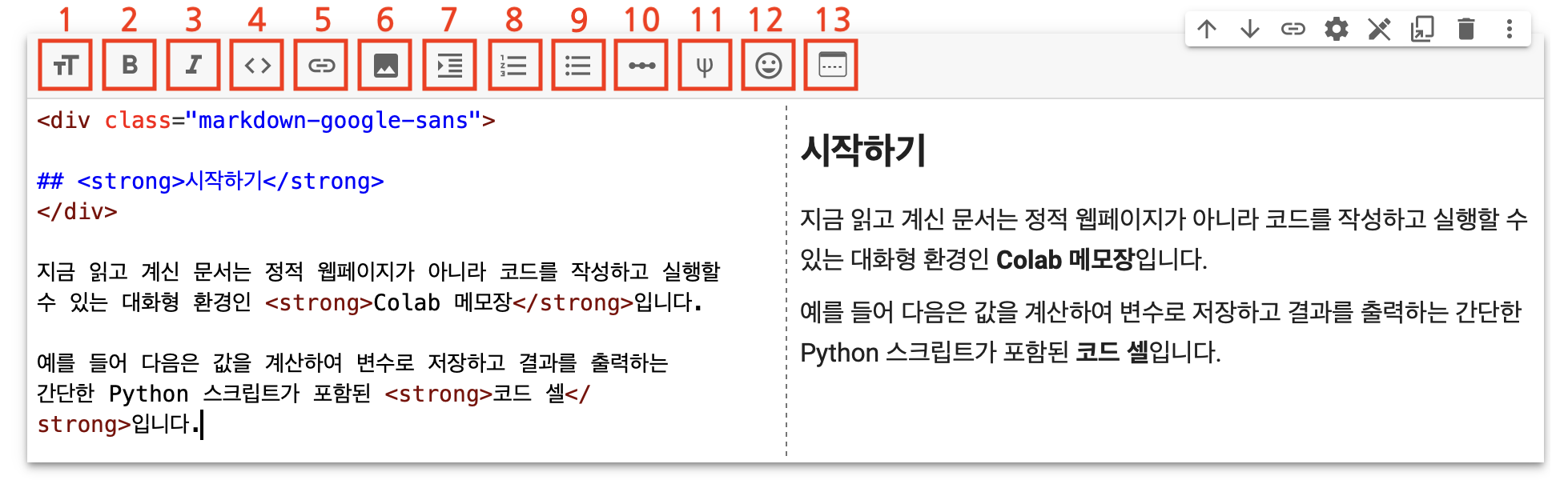
상단 툴바의 기능들은 아래와 같다.
- 현재 라인을 제목으로 바꾼다.
- 선택한 글자를 굵은 글자로 바꾼다.
- 선택한 글자를 이탤릭체로 바꾼다.
- 코드 형식으로 바꾼다.
글자를 선택하지 않고 이 버튼을 누르면 현재 커서 위치에 코드 블록을 만든다.
- 선택한 글자를 링크로 만든다.
- 현재 커서 위치에 이미지를 삽입한다.
- 현재 커서 위치에 들여 쓴 블록을 추가한다.
- 현재 커서 위치에 번호 매기기 목록을 추가한다.
- 현재 커서 위치에 글머리 기호 목록을 추가한다.
- 현재 커서 위치에 가로줄을 추가한다.
- 현재 커서 위치에 수학 기호를 추가한다.
- 현재 커서 위치에 이모티콘을 추가한다.
- 미리 보기 창의 위치를 오른쪽/아래로 바꾼다.
텍스트 셀의 수정을 끝내려면 ESC 키를 누른다.
코드 셀

코드 셀을 선택하면 코드와 코드의 실행 결과가 함께 선택된다.
코랩 노트북
- 앞서 설명한 것과 같이, 코랩은 클라우드 기반의 주피터 노트북 개발 환경이다.
- 코랩 노트북은 구글 클라우드의
가상 서버(virtual machine)를 사용하며, 이 노트북은 구글 클라우드의 컴퓨터 엔진(Computer Engine)에 연결되어 있다.
이 서버의 메모리는 약12기가이고, 디스크 공간은100기가이다.
즉, 구글 계정만 있으면 코랩 노트북을 사용해 무료로 가상 서버를 활용할 수 있는 것이다.
무료 계정의 제한 사항은 아래 2가지이다.
- 코랩 노트북으로 동시에 사용할 수 있는 구글 클라우드의 가상 서버는 최대 5개이다.
- 1개의 노트북을 12시간 이상 실행할 수 없다.

위 사진과 같이, 코랩 노트북을 생성하면 자동으로 구글 드라이브의 내 드라이브 > Colab Notebooks 폴더 아래에 저장된다.
요약
💡 코랩은 구글 계정이 있으면 누구나 사용할 수 있는 웹 브라우저 기반의 파이썬 코드 실행 환경이며 코랩의 프로그램 작성 단위를 코랩 노트북이라고 한다.
💡 코랩 노트북은 여러 개의 텍스트 셀, 코드 셀로 이루어져 있으며 코랩 노트북을 생성하면 자동으로 구글 드라이브에 저장된다.
3. 생선 마켓과 머신러닝(예시)
머신러닝은 누구도 알려주지 않는 기준을 스스로 찾고, 이 기준을 이용하여 판별할 수도 있다.
머신러닝을 구현하는 과정을 '도미와 빙어를 구분하는 머신러닝' 예시와 함께 살펴보자.
아래는 35마리 도미의 길이와 무게 정보를 담은 리스트이다.
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]이 책에서는 이러한 각 도미의 특징인 길이와 무게를 도미의 특성(feature)이라고 부른다.
💡 특성(feature): 데이터의 특징
두 특성(길이, 무게)을 숫자로 보는 것보다 그래프로 보는 것이 더 직관적이므로
길이를 x축으로 하고, 무게를 y축으로 하는 그래프를 그리고자 한다.
이런 그래프를 산점도(scatter plot)라 한다.
💡 산점도(scatter plot): x, y축으로 이뤄진 좌표계에서 두 변수(x, y)의 관계를 표현하는 그래프
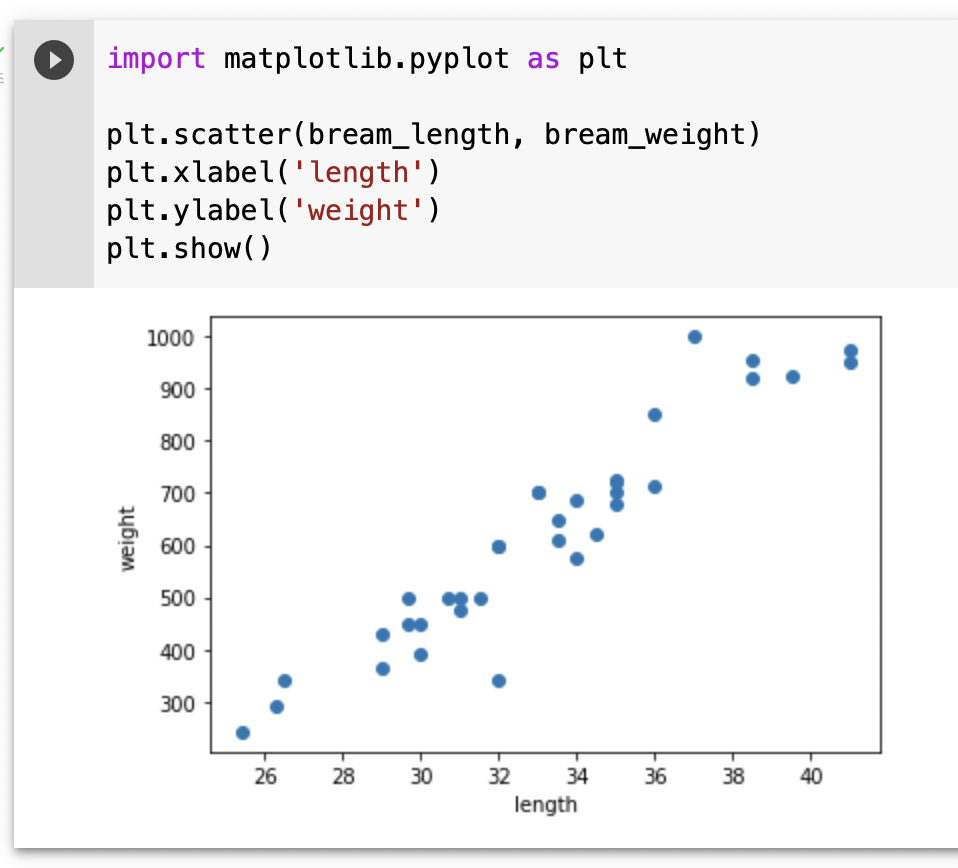
파이썬의 matplotlib 패키지를 임포트하여 산점도를 그리는 scatter() 함수를 사용할 수 있다.
💡
xlabel(),ylabel(): x, y축의 이름을 설정하는 함수
💡show(): 그래프를 화면에 출력하는 함수
위의 그래프와 같이 그래프가 일직선에 가까운 형태로 나타나는 경우를 선형(linear)적이라고 한다.
도미 데이터를 준비했으니, 빙어 데이터도 준비해보자.
아래는 14마리 빙어의 길이와 무게 정보를 담은 리스트이다.
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]마찬가지로 위의 빙어 특성들을 이용하여 산점도를 그려보자.
💡 하나의 좌표평면에 여러 개의 산점도를 그리고 싶다면 scatter()함수를 여러번 사용하면 된다!
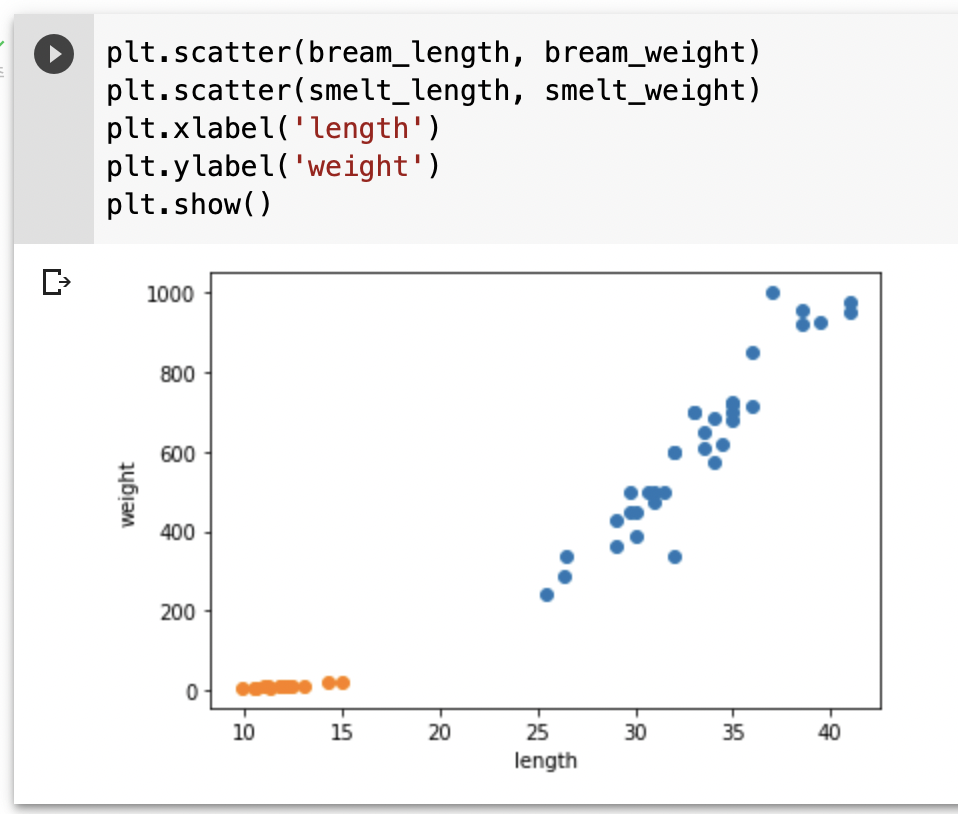
위 그래프로 알 수 있듯이 빙어는 길이가 늘어나더라도 무게가 많이 늘지 않는다.
따라서 빙어의 산점도도 선형적이지만, 무게가 길이에 영향을 덜 받는다고 볼 수 있다.
또한 위 코드에서도 알 수 있듯이, 파이썬에서 한 번 import 된 패키지는 다시 임포트할 필요가 없다.
( 위 코드에서 matplotlib을 임포트하지 않고도 사용한 모습을 볼 수 있다. )
여러 개의 산점도를 만들 경우, matplotlib 패키지가 알아서 색깔로 구분하여 나타낸다.
(주황 - 빙어, 파랑 - 도미)
이제 두 데이터를 스스로 구분하기 위한 첫 번째 머신러닝 프로그램을 만들어보자!
사이킷런 패키지로 첫 머신러닝 프로그램 만들어보기
첫 번째 머신러닝 프로그램으로는 가장 간단하고 이해하기 쉬운 사이킷런(scikit-learn) 패키지의 k-최근접 이웃(k-Nearest Neighbors) 알고리즘을 사용해보자.
(k-최근접 이웃 알고리즘에 대해서는 아래에서 더 자세히 설명하겠다.)
어떤 생선을 보고 도미인지 구분하는 머신러닝을 만들기 위해서는 그 머신러닝이 도미를 찾기 위한 기준을 학습해야 하는데, 이를 머신러닝에서는 훈련(training)이라고 한다.
💡 훈련(training): 모델에 데이터를 전달하여 규칙을 학습하는 과정
머신러닝을 훈련시키기 위해서는
- 예시가 되는 데이터셋과
- 그 예시 데이터의 정답 유무를 담은 정답 데이터
가 필요하다.
사이킷런 머신러닝 패키지를 사용하기 위해서는
[[25.4, 242.0], # [길이, 무게]
[26.3, 290.0],
...
]위와 같은 2차원 리스트 데이터가 필요하다.
2차원 리스트 형태를 만들기 위해 먼저 아래와 같이 도미와 빙어의 길이, 무게 데이터를 각각 하나의 리스트에 담자.
length = bream_length + smelt_length
weight = bream_weight + smelt_weight💡 파이썬에서는 리스트(list)끼리 덧셈을 수행하면 두 개의 리스트가 하나의 리스트로 합쳐진다.
즉, length와 weight 리스트에서 데이터는 각각 35개의 도미 정보 뒤에 14개의 빙어 정보 순서로 나열되어 있다.
위에서 만든 length와 weight 리스트를 2차원 리스트 형태로 만들기 위해 파이썬의 zip() 함수 + list comprehension 구문을 사용하겠다.
fish_data = [[l, w] for l, w in zip(length, weight)]예시 데이터를 준비했으니 정답 데이터도 준비해보자.
✔️ 우리가 구분하고자 하는 생선은 '도미'이니 도미를 정답으로, 빙어를 오답으로 만들어야 하고,
✔️ 머신러닝을 포함한 컴퓨터 프로그램은 문자를 직접 이해하지 못하므로 도미를 1, 빙어를 0으로 표현하자.
마찬가지로, 정답 데이터도 2차원 리스트로 표현해야 한다.
fish_target = [1] * 35 + [0] * 14예시 데이터와 정답 데이터를 준비했으니, 이제 사이킷런 패키지에서 k-최근접 이웃 알고리즘을 구현한 클래스인 KNeighborsClassifier 를 임포트하자.
from sklearn.neighbors import KNeighborsClassifier임포트한 KNeighborsClassifier 클래스의 객체를 생성하고,
예시 데이터와 정답 데이터로 훈련을 시켜보자.
사이킷런에서는 fit() 메서드로 훈련을 시킨다.
kn = KNeighborsClassifier()
kn.fit(fish_data, fish_target)kn 모델이 얼마나 잘 훈련되었는지 알고 싶을 때에는 사이킷런 패키지의 score() 메서드를 사용하면 된다.
kn.score(fish_data, fish_target)score() 함수는 0과 1 사이의 값을 반환하며, 1은 모든 데이터를 정확히 맞혔다는 것을 의미한다.
어떤 생선의 길이, 무게 데이터를 kn 모델이 어떻게 판별하는지 확인하고 싶다면 predict() 메서드를 사용하면 된다.

앞의 데이터는 도미(1), 뒤의 데이터는 빙어(0)로 예측한 모습을 확인할 수 있다.
k-최근접 이웃 알고리즘이란?
- 어떤 데이터에 대한 답을 구할 때, 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용하는 알고리즘 (
근묵자흑)
- 참고하는 주위의 다른 데이터의 개수는
n_neighbors매개변수로 사용자가 정하기 나름이다. ( 기본값 = 5 )kn49 = KNeighborsClassifier(n_neighbors=49) # 참고 데이터를 49개로 한 모델- 49개의 데이터(fish_data 전체)를 참고하여 판별할 경우, 도미 35개 / 빙어 15개로 항상 도미로 판정할 수 밖에 없음
( 도미의 개수가 더 많으니까, 다수 = 도미가 되기 때문)
- 49개의 데이터(fish_data 전체)를 참고하여 판별할 경우, 도미 35개 / 빙어 15개로 항상 도미로 판정할 수 밖에 없음
- 데이터를 모두 가지고 있기만 하면 사용할 수 있다.
- 데이터를 예측할 때는 가장 가까운 직선거리에 어떤 데이터가 있는지 확인하면 된다.
- 이러한 특징 때문에 데이터가 아주 많은 경우에는 사용하기 어렵다.
데이터의 크기 때문에 메모리가 많이 필요하고, 직선거리를 계산하는 데도 많은 시간이 필요하다.
요약
💡 데이터를 표현하는 성질을 특성이라 하며, 머신러닝은 이 특성으로 데이터들을 구분한다.
💡 우리는 이 장에서 사이킷런 패키지의 k-최근접 이웃 알고리즘을 활용하여 머신러닝 프로그램을 구현했는데, 이처럼 알고리즘이 구현된 객체를 모델이라고 부른다.
💡 모델이 데이터를 구분하는 기준을 세우기 위해서는 데이터들 간의 규칙을 찾아야 하는데, 이 과정을 훈련이라고 하며 사이킷런에서는fit()메서드를 활용하여 훈련시킬 수 있다.
💡 모델이 잘 훈련되었는지 확인하고 싶을 때에는 정확도 점수를 알려주는score()함수나 삽입하는 데이터로 예측하는predict()함수를 사용한다.
