[AI] EfficientNet을 통한 반려묘 안구 질환 진단
질병 D.비궤양성 각막염, E.안검염에 쓰인 EfficientNet을 통해 학습 및 모델을 작성하고 정확도를 분석하여 보자
EfficientNet
EfficientNet은 네트워크의 깊이(depth), 너비(width), 해상도(resolution) 사이에 어떤 관계가 있음을 경험적으로 발견하고, 이들을 효율적으로 조절하는 방법(Compound Scaling)을 고안하여 성능을 향상시킨 네트워크이다.
선정 이유
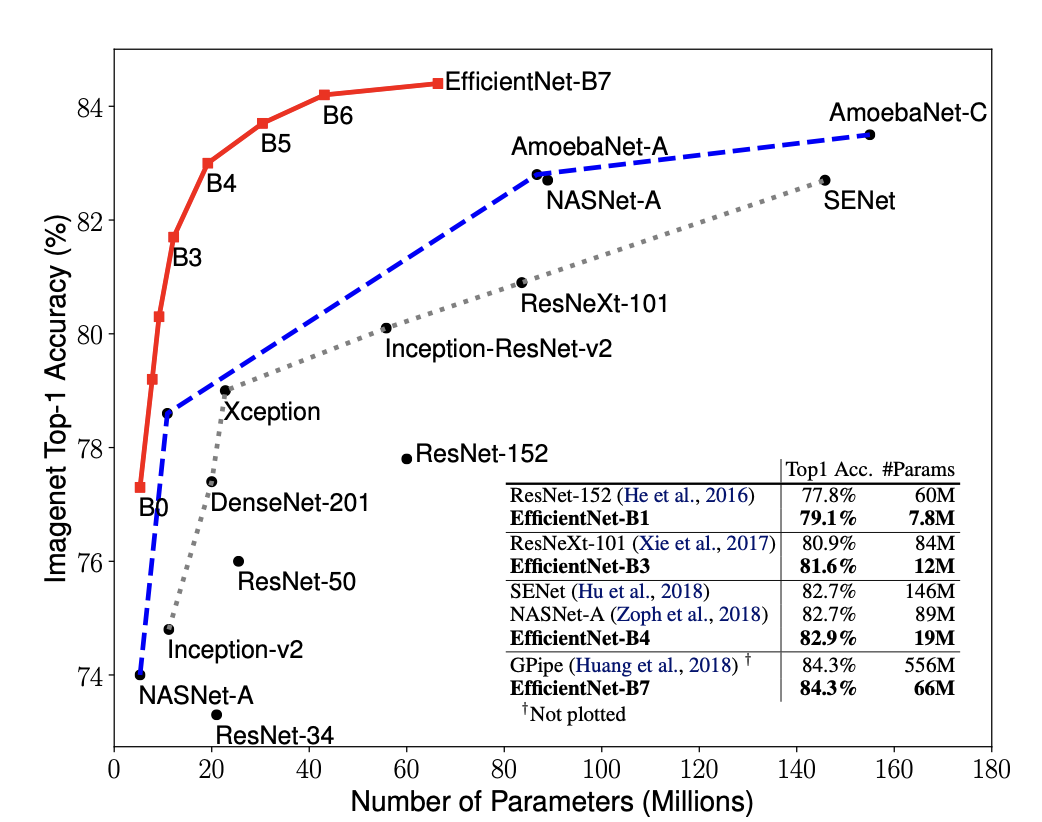
저희가 항상 문제가 되는 부분 중하나인 시간적인, 프로세스적인 제약과 함께, 모바일 어플리케이션으로 제작하는 것을 목표로 두었기 때문에, 모델의 용량과 크기도 중점적으로 고려하고, 해당 조건에 적합한 네트워크 중 하나로 선정하여 해당 모델을 작성하기로 하였다. 해당 네트워크 B0모델은 ResNet-50layer모델보다 parameter수가 수준으로 작으며, 정확도는 다소 높은수준으로 나타났다.
따라서 해당 모델을 선정하고 분석하기로 결정하게 되었다.
Efficient Net 기반 이론
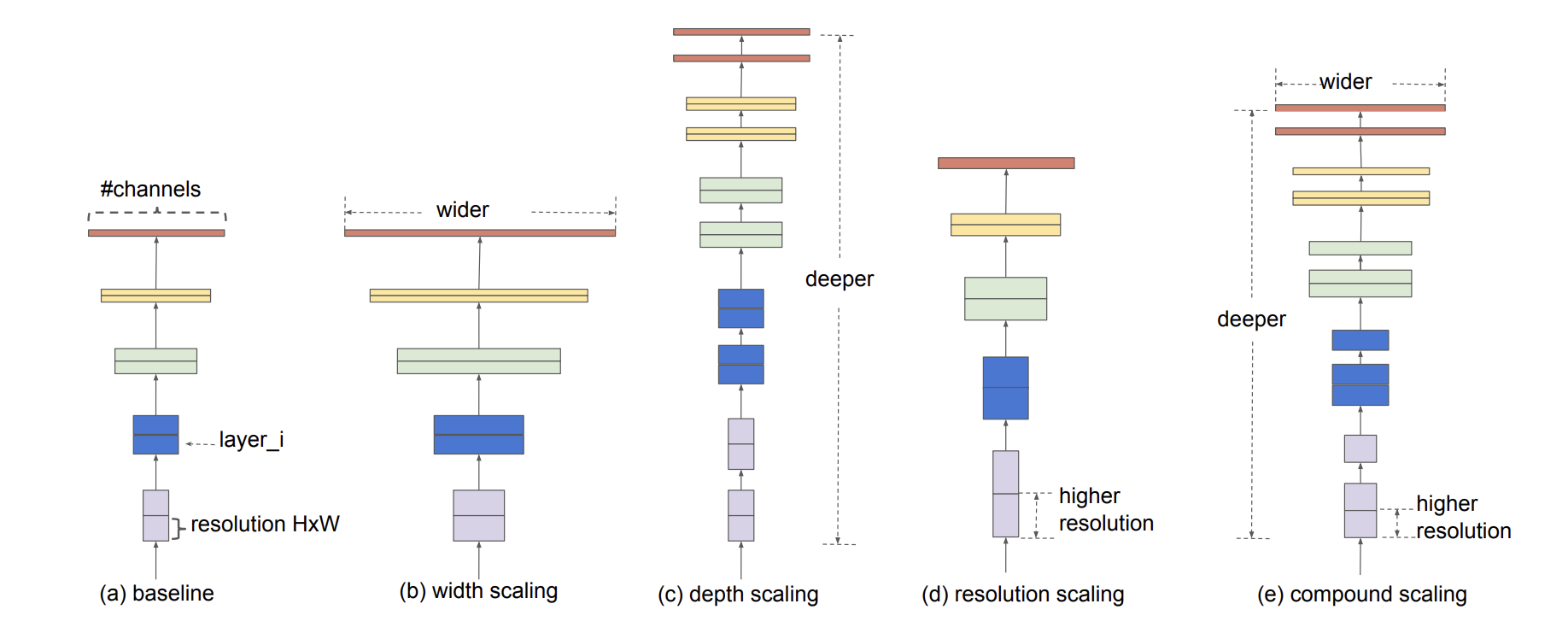
대표적인 scaling model들로, 집중하고 있는 모델은 (e)의 compound scailing에 이다.
하지만 이를 시행하기 위해서는 하드웨어 메모리 문제에 직면하게 된다.
결국 정확도를 더욱 높이기 위해서는 효율성을 더 높일 필요가 있어 추가 연구가 진행되었다.
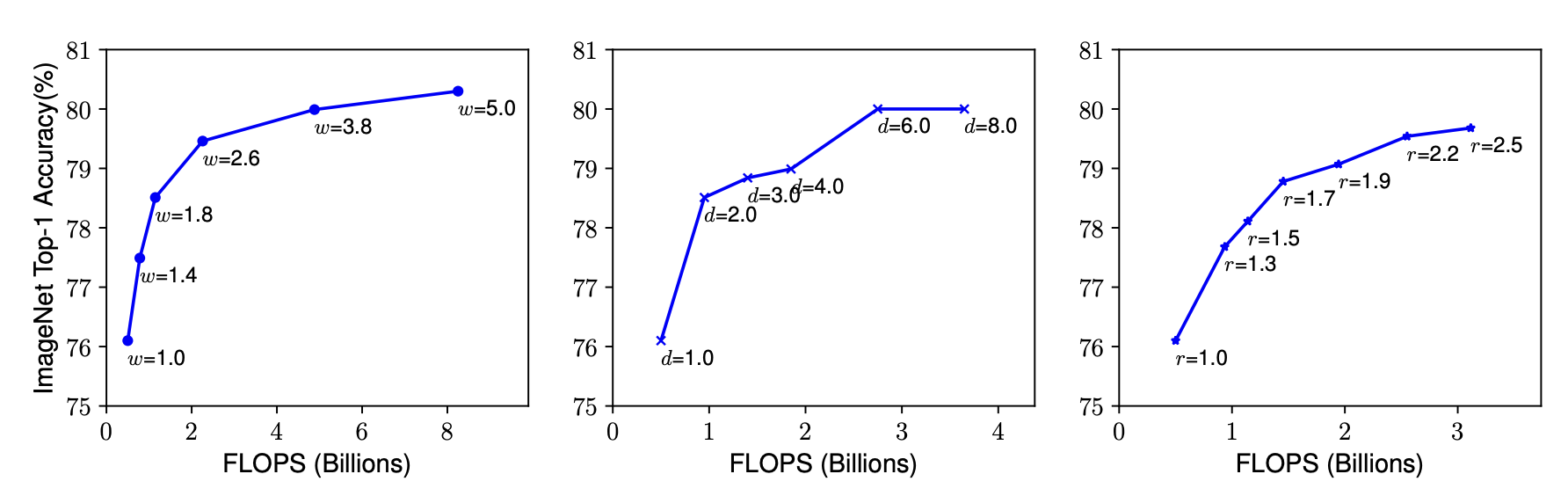
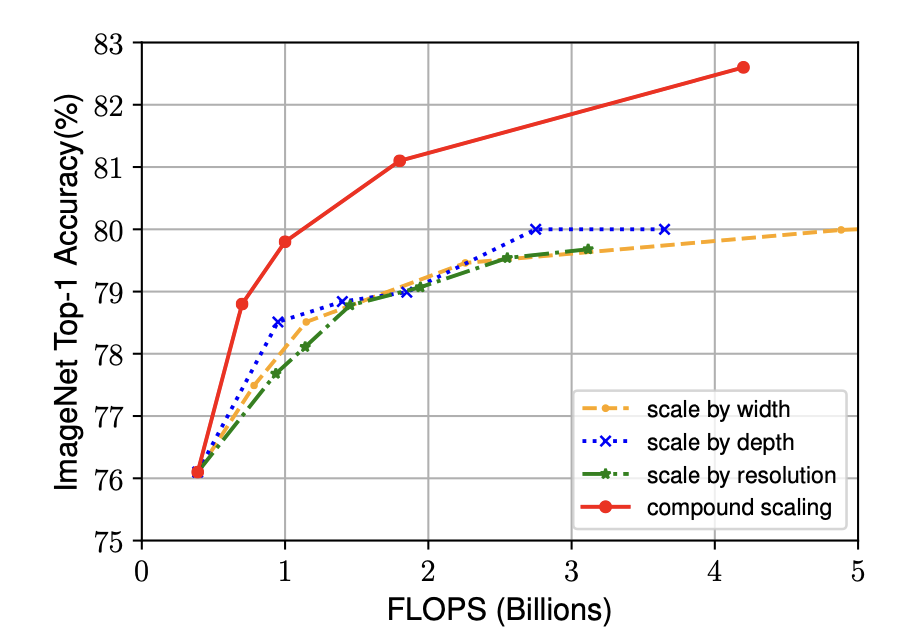
해당 그래프는 Baseline Model(ConvNet)에 대해 각각 너비(width), 깊이(depth), 해상도(resolution)에 대한 연산량과 정확도를 나타낸 것이다.
이를 통해 네트워크의 크기를 효과적으로 조절하여 다양한 효율성, 정확성을 토대로한 Trade-off를 지원함.
정리하자면, 네트워크의 깊이가 증가할수록 모델의 capacity가 커지고, 복잡한 feature를 잡아낼 수 있지만, Vashing gradient문제로인해 학습의 난이도가 올라간다. 각 레이어의 width가 커지면, 정확도가 높아지지만, 계산량이 제곱으로 늘어나게 된다. 마지막으로 해상도를 키우면, 더 세부적인 feature를 확인할 수 있어, 정확도는 높아지지만, 마찬가지로 계산량도 제곱으로 늘어난다. 이 때 셋 중 어느하나를 매우 크게 증가시키더라도, 일정수준 이상으로는 정확도가 더이상 좋아지지 않는 점을 밝혀냈다.Compound Scaling
주로 더 높은 해상도의 이미지에 대한 전처리로
"네트워크를 깊게 만들어 더 넓은 영역의 feature를 더 잘 잡아낼 수 있도록 하는 것이 유리하며, 큰 이미지일수록 세부적인 내용도 많아, 이를 잡아내기 위해 layer의 width를 증가시킬 필요가 있다"라는 이론을 바탕으로 Depth, Width, Resolution이라는 세가지 변수를 서로 함께 움직이는 것이 도움이 될 것이라는 생각에 나온 이론.
해당 연구를 통해 하나의 차원만 증가 시킬 때는 정확도를 80%이상으로 올리지 못하였지만, Depth, Width, Resolution을 같이 조절하는 compound scaling 방식의 처리가 정확도를 80%이상으로 만들 수 있으면서 자원을 효율적으로 사용하는 방법임을 입증하였다.
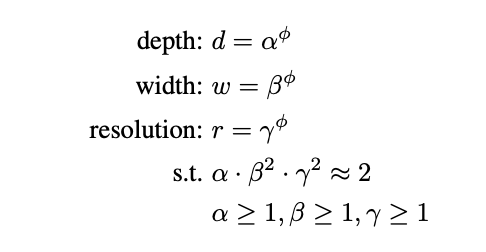
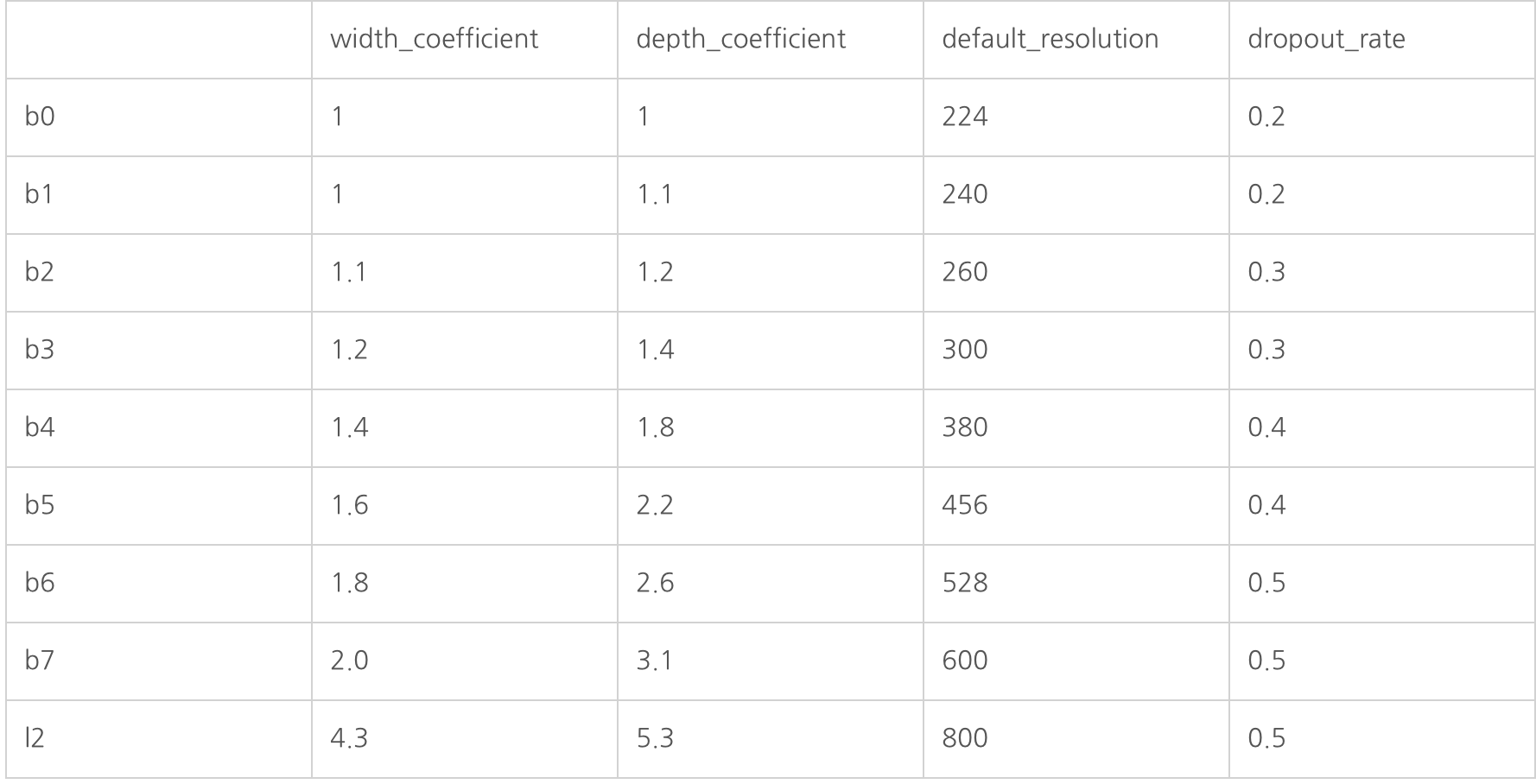
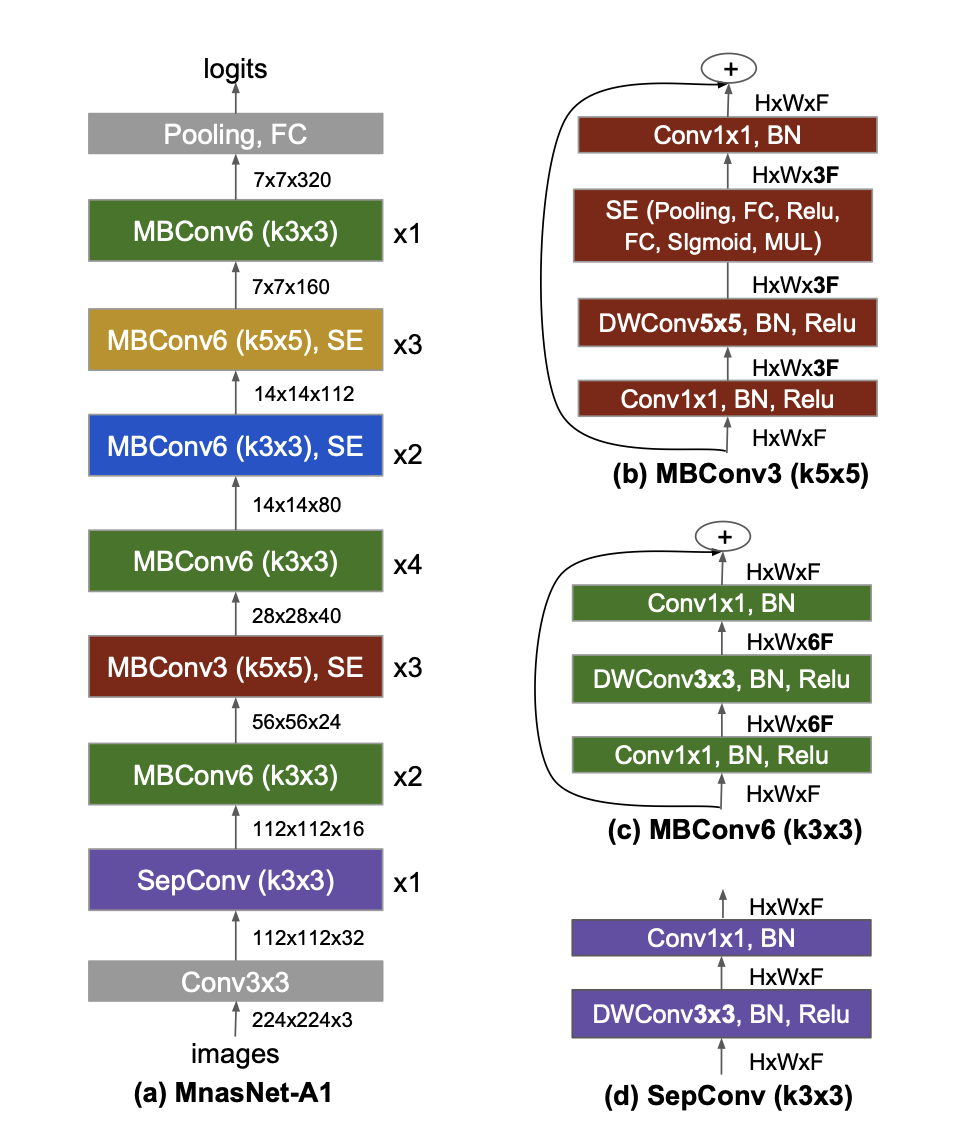
구조
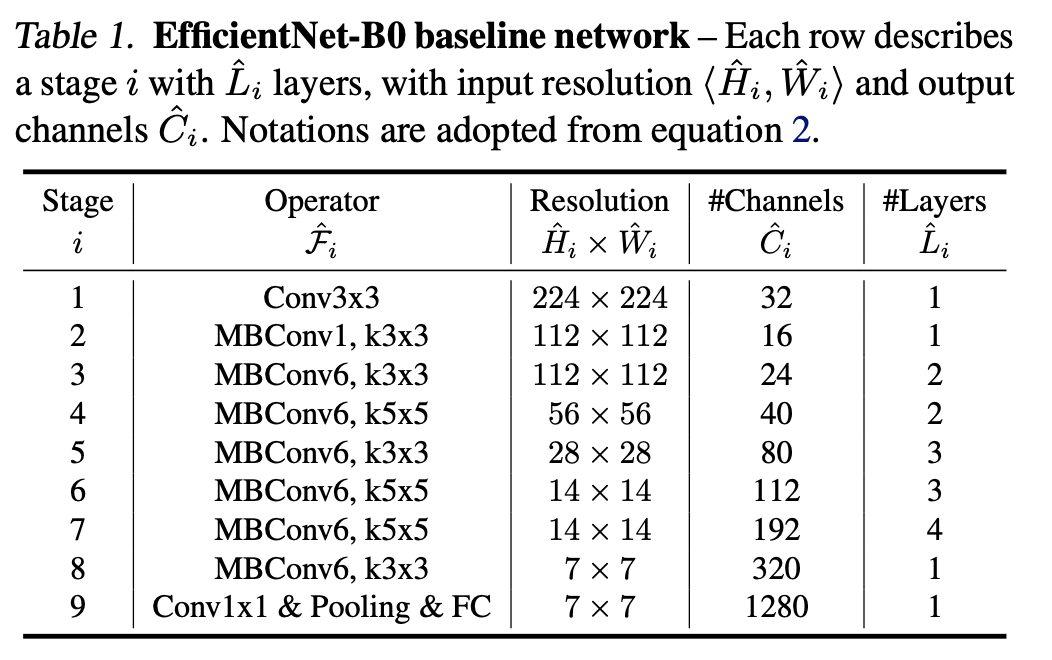
해당 표를 참고하여, EfficientNetB0를 포함한 전체적인 구조를 설게하여보자.
라이브러리 호출
### 라이브러리 !pip install tensorflow-addons from tensorflow.keras.models import Model import tensorflow_addons as tfa from tensorflow.keras.layers import Input,GlobalAveragePooling2D, Conv2D, BatchNormalization, Activation, Add, MaxPooling2D, AveragePooling2D, Flatten, Dense, ZeroPadding2D import matplotlib.pyplot as plt import numpy as np import pandas as pd import os import cv2 import time import math from tensorflow.keras.optimizers import Adam,SGD from tensorflow.keras.utils import to_categorical from tensorflow.keras.models import Sequential from sklearn.model_selection import train_test_split import tensorflow as tf import tensorflow.keras.backend as K from tensorflow.keras import layers import random from keras.preprocessing.image import ImageDataGenerator먼저 tensorflow-addons에서 필요한 활성화 함수
mish를 가져오기 위해 호출 : Google Colab환경에서 실행하기 때문에 일시적으로 addon라이브러리를 설치네트워크 변수설정
# EfficientNet 모델 파라미터 설정 # 네트워크 아키텍처 및 하이퍼파라미터 정의 se_ratio = 4 expand_ratio = 6 width_coefficient = 1.0 # B0 depth_coefficient = 1.0 # B0 default_resolution = 224 # B0 input_channels = 3 depth_divisor = 8 dropout_rate = 0.2 # B0 drop_connect_rate = 0.2 kernel_size = [3, 3, 5, 3, 5, 5, 3] num_repeat = [1, 2, 2, 3, 3, 4, 1] output_filters = [16, 24, 40, 80, 112, 192, 320] strides = [1, 2, 2, 2, 1, 2, 1] MBConvBlock_1_True = [True, False, False, False, False, False, False]모델에 대한 하이퍼 파라미터를 설정한다.
해당 표를 참고하여 네트워크 구조에 대한 매개변수를 설정하였다.
# Custom Layer: DropConnect 구현 # 사용자 정의 케라스 레이어를 정의, 드롭아웃(Dropout)의 변종 중 하나로, 네트워크의 일부 연결을 무작위로 비활성화시키는 역할을 합니다. class DropConnect(layers.Layer): def __init__(self, drop_connect_rate=0.0, **kwargs): super().__init__(**kwargs) self.drop_connect_rate = drop_connect_rate #call 메서드는 이 레이어가 호출될 때 실행되는 함수입니다. inputs는 입력 데이터이고, training은 현재 훈련 중인지 테스트 중인지를 나타내는 부울 값입니다. #_drop_connect 함수는 실제로 DropConnect을 수행하는 함수입니다. keep_prob은 드롭아웃 비율을 나타냅니다. 이 값은 1-drop_connect_rate로 계산됩니다. def call(self, inputs, training): def _drop_connect(): keep_prob = 1.0 - self.drop_connect_rate batch_size = tf.shape(inputs)[0] #random_tensor는 keep_prob 값에 무작위 노이즈를 추가한 것으로, 드롭아웃 연결을 무작위로 활성화 또는 비활성화하기 위해 사용됩니다. random_tensor = keep_prob random_tensor += K.random_uniform([batch_size, 1, 1, 1], dtype=inputs.dtype) #binary_tensor는 드롭아웃 연결을 제어하는 역할을 합니다. binary_tensor = tf.floor(random_tensor) # 최종적으로 Dropout이 적용된 output을 계산 output = tf.math.divide(inputs, keep_prob) * binary_tensor return output return K.in_train_phase(_drop_connect, inputs, training=training)_drop_connect 함수를 훈련 중에 호출하고, 테스트 중에는 그대로 inputs를 반환합니다. 즉,훈련 시에만 드롭아웃이 적용되고, 테스트 시에는 모든 연결이 유지시킵니다.
SE Block
# Custom 함수: Squeeze-and-Excitation Block 구현 def SEBlock(filters, reduced_filters): def _block(inputs): x = layers.GlobalAveragePooling2D()(inputs) x = layers.Reshape((1, 1, x.shape[1]))(x) x = layers.Conv2D(reduced_filters, 1, 1)(x) x = tfa.activations.mish(x) x = layers.Conv2D(filters, 1, 1)(x) x = layers.Activation('sigmoid')(x) x = layers.Multiply()([x, inputs]) return x return _blockSEBlock은 컨볼루션 신경망(CNN) 아키텍처에서 사용되는 활성화 강도(중요도)를 동적으로 조절하기 위한 메커니즘 중 하나로, 주어진 입력 Feature map의 중요한 정보를 강조하고 덜 중요한 정보를 억제하여 모델의 표현 능력을 향상시키는 block입니다.
먼저 Squeeze 단계에서 입력 특성 맵의 각 채널별로 평균 값을 계산합니다. 이것은 각 채널의 중요도를 요약하고, Excitation 단계에서 각 채널의 중요도를 사용하여, 각 채널의 활성화 값을 재가중치화를 진행합니다. 이를 Scale단계에서 입력 특성 맵을 다시 조절하고, 가중치화된 값과 원래의 입력 특성 맵을 곱하여 중요한 정보를 강조하는 구조를 가지고 있습니다. 이를통해 모델의 Feature map에서 중요한 정보를 강조하는 역할을 합니다. SE 블록은 각 채널의 중요도를 동적으로 조절하여 모델의 표현 능력을 향상시키고, 더 나은 성능을 얻을 수 있습니다.MBConv
MobileNetv2를 구성하는 기본적인 Block이다. MnasNet의 영향을 많이 받아 중간중간에 SEblock을 가지고있다.
def MBConvBlock(x, kernel_size, strides, drop_connect_rate, output_channels, MBConvBlock_1_True=False): output_channels = round_filters(output_channels, width_coefficient, depth_divisor)먼저 MBConv에 필요한 매개변수를 입력으로 받고,
if MBConvBlock_1_True: block = layers.DepthwiseConv2D(kernel_size, strides, padding='same', use_bias=False)(x) block = layers.BatchNormalization()(block) block = tfa.activations.mish(block) block = SEBlock(x.shape[3], x.shape[3] / se_ratio)(block) block = layers.Conv2D(output_channels, (1, 1), padding='same', use_bias=False)(block) block = layers.BatchNormalization()(block) return block만약 첫번째 Block을 맡고있는 MBConv1 Block인 경우에는 DepthwiseConv2D를 사용하여 깊이별 컨볼루션을 적용하고, 배치 정규화 및 활성화 함수를 적용하고, SEBlock, Conv2D와 배치 정규화를 적용하여 output을 도출합니다.
반면에 MBConv6 Block인 경우에는channels = x.shape[3] expand_channels = channels * expand_ratio block = layers.Conv2D(expand_channels, (1, 1), padding='same', use_bias=False)(x) block = layers.BatchNormalization()(block) block = tfa.activations.mish(block) block = layers.DepthwiseConv2D(kernel_size, strides, padding='same', use_bias=False)(block) block = layers.BatchNormalization()(block) block = tfa.activations.mish(block) block = SEBlock(expand_channels, channels / se_ratio)(block) block = layers.Conv2D(output_channels, (1, 1), padding='same', use_bias=False)(block) block = layers.BatchNormalization()(block)먼저 1x1 컨볼루션을 사용하여 채널 수를 expand_ratio(=6)를 사용하여 확장시키고, 그런 다음 DepthwiseConv2D를 사용하여 깊이별 컨볼루션을 적용하고, 배치 정규화 및 활성화 함수를 적용합니다. 그 뒤 SEBlock, Conv2D와 배치 정규화를 적용하여 output을 도출합니다.
if x.shape[3] == output_channels: block = DropConnect(drop_connect_rate)(block) block = layers.Add()([block, x]) return block마지막으로, 입력 특성 맵의 채널 수가 output_channels와 동일한 경우 DropConnect(Dropout)을 실행합니다.
해당 블록을 입력값과 결합하여 결과값을 도출합니다.EfficientNet Model Architecture
# EfficientNet 모델 아키텍처 정의 def EffNet(input_shape, num_classes): # 입력 이미지를 받아오는 레이어를 생성합니다. x_input = layers.Input(shape=(default_resolution, default_resolution, input_channels)) # 입력 이미지에 3x3 크기의 컨볼루션을 적용, 출력 채널을 32로 설정하며, 스트라이드를 2로 설정하여 입력 이미지의 해상도를 줄입니다 x = layers.Conv2D(round_filters(32, width_coefficient, depth_divisor), (3, 3), 2, padding='same', use_bias=False)(x_input) # 정규화를 진행 x = layers.BatchNormalization()(x) # mish 활성화 함수를 적용 x = tfa.activations.mish(x) num_blocks_total = sum(num_repeat) block_num = 0 for i in range(len(kernel_size)): # 각 블록에서 반복 횟수를 설정합니다. 이 횟수는 'depth_coefficient'를 기반으로 계산 round_num_repeat = round_repeats(num_repeat[i], depth_coefficient) #'DropConnect' 비율을 설정 drop_rate = drop_connect_rate * float(block_num) / num_blocks_total # MBConv 블록 실행 (첫번째만 MBConv1, 나머지는 MBConv6) x = MBConvBlock(x, kernel_size[i], strides[i], drop_rate, output_filters[i], MBConvBlock_1_True=MBConvBlock_1_True[i]) block_num += 1 if round_num_repeat > 1: for bidx in range(round_num_repeat - 1): drop_rate = drop_connect_rate * float(block_num) / num_blocks_total x = MBConvBlock(x, kernel_size[i], 1, drop_rate, output_filters[i], MBConvBlock_1_True=MBConvBlock_1_True[i]) block_num += 1 # 마지막 Convolution 레이어 x = layers.Conv2D(round_filters(1280, width_coefficient, depth_divisor), 1, padding='same', use_bias=False)(x) x = layers.BatchNormalization()(x) # 마지막 BN x = tfa.activations.mish(x) # 활성화 함수 x = layers.GlobalAveragePooling2D()(x) # Average Pooling x = layers.Dropout(dropout_rate)(x) #Dropout을 실행하고 x = layers.Dense(num_classes, activation='softmax')(x) # FC 분류기 "Softmax" 사용 model = tf.keras.models.Model(inputs=x_input, outputs=x) # 최종모델 작성 return model으로 구성되어있다.
결론
Compound Scailing을 적용한 모델이 object에 대한 디테일이나, 특징을 더 잘 잡아내는 경우가 있다. 뿐만 아니라, Width,Depth,Resolution간의 균형이 정확도가 더 높고 효율적인 방법이고, Model의 변환 (B0->B5)도 큰 형식 변경없이 용이하게 할 수 있는 모델임.
기존에 작성한 ResNet과 성능비교를 해보면, B0의 경우에는 확연히 빨라진 속도 차이를 갖고있으며, B5모델의 경우에는 학습에 도달하는 속도는 다소 느려, epoch을 다소 키우는 것이 필요하지만, 정확도 측면에서 다소 높은 경향을 보임. 전체적인 비용을 고려하여보고, 선택하는 것이 필요함.
개수가 6000개를 넘어가는 A.각막궤양, B.각막부골편, C.결막염은 컴퓨터단위(Google Colab)부족으로 인해 시행을 하지 못하였으나,
질병 D. 비궤양성 각막염의 경우는
모델 epoch 정확도 B0모델 100 85.83% B5모델 200 89.17% ResNet50 100 84.17% ResNet18 100 82.08% 질병 E. 안검염의 경우는
모델 epoch 정확도 B0모델 100 82.72% B5모델 200 84.82% ResNet50 100 80.33% ResNet18 100 79.50% 로 ResNet-50Layer모델에 비해 다소 높은 정확도를 보이고 있다.
Git:
https://github.com/Yeon1A/KWHackathon/blob/main/EffNetB5_disease_e.ipynb
