
Image Segmentation using CNN
Fully Convolutional Segmentation Network
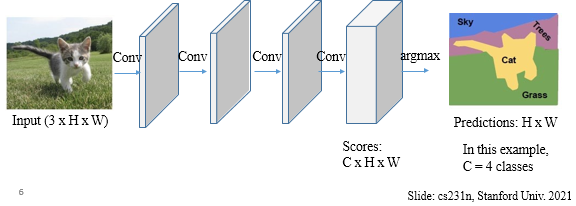
- 픽셀 크기를 유지. input과 output 사이즈가 같다.
- 사이즈가 크면 연산량이 많다는 문제
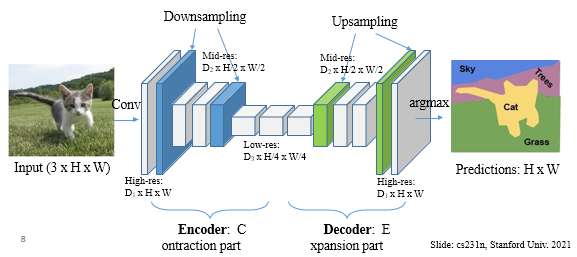
- Encoder-Decoder network
- Encoderd에서 high level feature를 뽑고 그걸 decoder 에서 확장
- Downsampling: pooling or strided (보통 stride=2로 1/2배)
- Upsampling: Transposed conv or interpolation(옆 칸 이용해서 빈칸 채우기)
U-Net Architecture
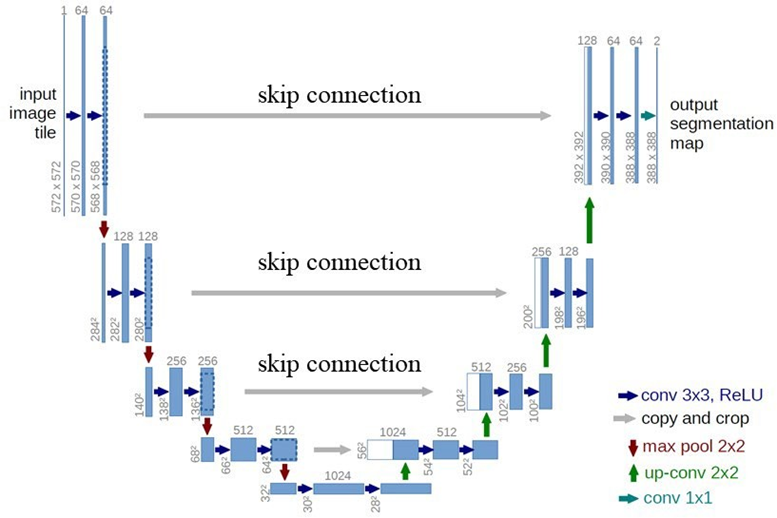
- Encoder-decoder network architecture with skip connections to help better decoding of output image in the decoder part.
// for Image Segmentation
- Weighted cross entropy loss function
- 데이터가 unbalanced 하면, boundary에서는 weight을 더 많이 주자.
Object Detection using CNN
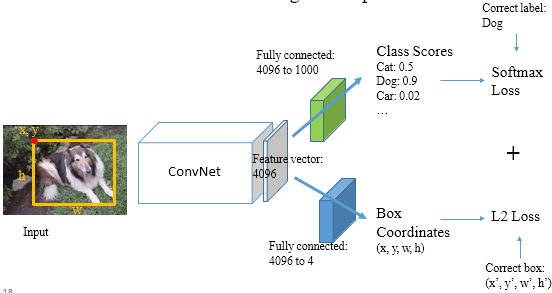
- Multi-task: Classification + Localization
- Localization은 regression
- Output 두 종류
- Image 내 rectangle을 그려서 detection -> 비효율적
Region Proposals
- 가능성 있는 영역, region proposals를 detection.
R-CNN
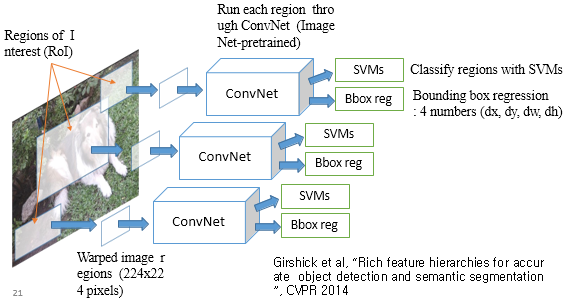
- Regions of Interest(RoI)마다 regressor를 둔다.
- 각 convNet에 들어가는 input은 cropped image. 각 결과 중 가장 best.
- 너무 느리다는 문제
Fast R-CNN
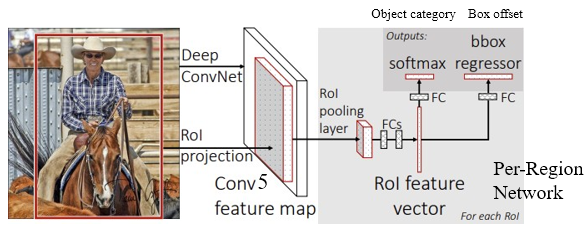
- Cropping 전에 image를 CNN에 pass.
- Image 한 장 통째로 넣어서 feature 뽑고, 그 feature에 해당하는 region을 가져오자 -> through backbone network
- 그 다음, crops + resize features -> 각 region에 대해, output: object category and box offset
Faster R-CNN
- Region proposal도 CNN에 맡기자 > RPN과 Fast R-CNN을 합쳐서 single network에서.
- RPN(Region Proposal Network)는 Anchor를 기준으로 다양한 사이즈의 박스들 사용
- 각 박스마다 region proposal를 해본다.
- Faster R-CNN is a single, unified network for object detection.
- The RPN module serves as the 'attention' of this unified network.
Two-stage object detector
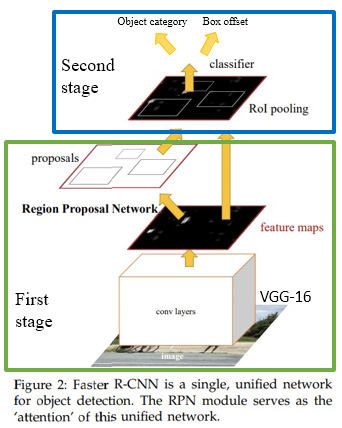
First stage: Run once per image
- Backbone network
- Region proposal network
Second stage: Run once per region
- Crop features: RoI pooling
- Predict object class
- Predict bounding box offset
Single-stage object detectors

- Two-stage 말고 하나의 stage로 하는 방법
- 입력 이미지를 grid로 나눈 후 여러 조합으로 검사
YOLO
- grid를 n*n으로 고정시키고, 정해진 사이즈의 Bounding box로 검출
- YOLO predicts multiple bounding boxes per grid cell.
SSD (Single Shot MultiBox Detector)
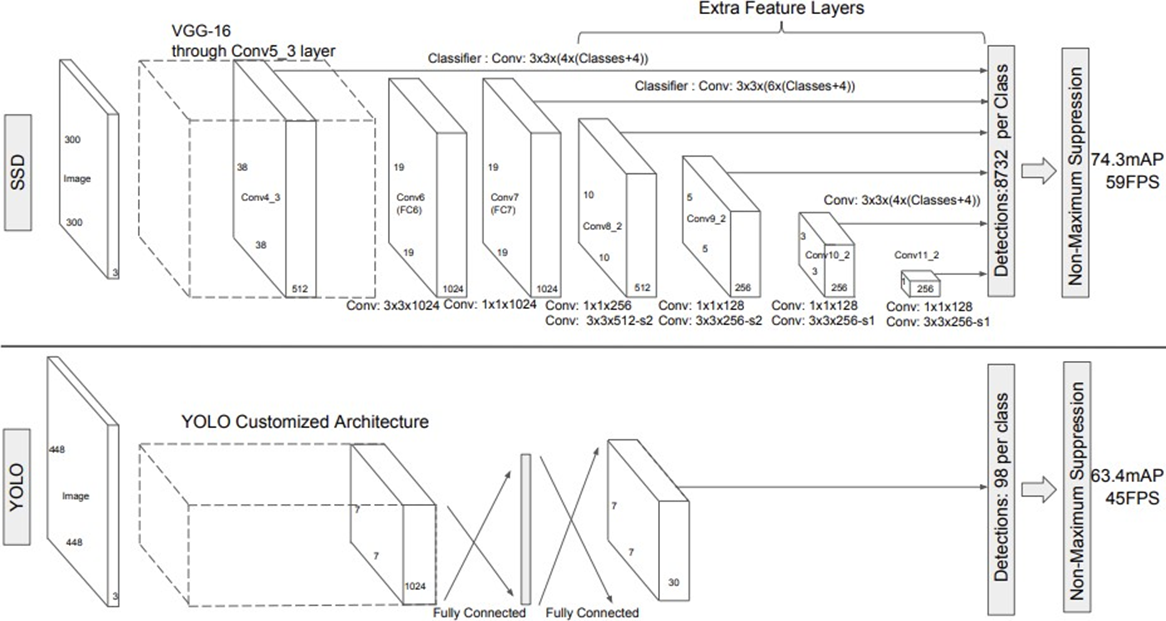
- YOLO와 다르게, 다양한 크기의 박스를 통해 검출. with different scales
- 이미지를 줄여서 같은 박스로도 큰 물체 검출 가능.
- feature map의 크기가 작아질 수록 더 큰 객체를 탐지할 수 있다.
- 영역별로 output이 나온다.
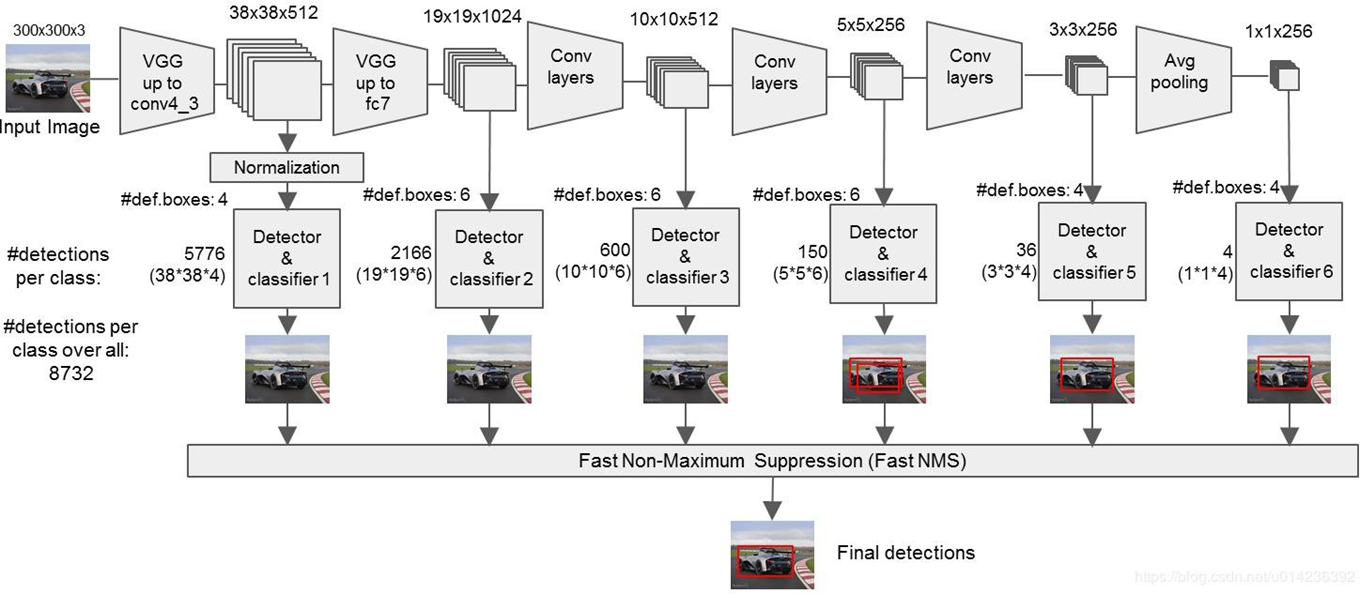
- 300*300 input이 들어가면, backbone인 VGG16을 거치고 그 이후 object detection을 한다.
- 3*3 conv를 통해서, output은 4개의 박스에서 각각 나옴. 근데 한 박스당 4개의 box offset value.
- VGG16 이후, 6개의 다른 feature map. 즉 6개의 다른 scale, 사이즈가 다른 object detection에 유리
- 300 by 300 > 1 by 1 까지 감소함. 큰 object detection에 유리

Übermensch