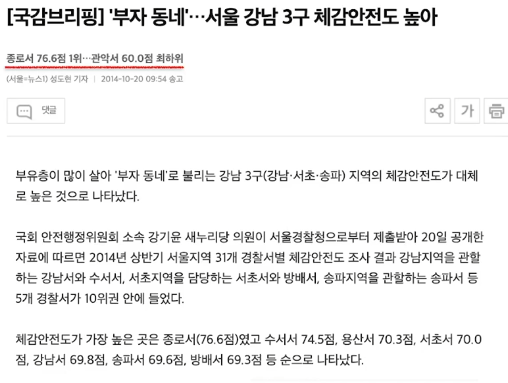
- 데이터 과학의 목적 : 가정 혹은 인식을 검증하고 표현하는 것
강남3구 범죄현황 데이터 개요 및 읽어오기
crime_raw_data = pd.read_csv(
'../data/02. crime_in_seoul.csv', thousands=',', encoding='euc-kr'
)pd.pivot_table(crime_raw_data, index=['구분']) 건수
구분
강남 670.5
강동 592.0
강북 421.3
강서 694.0
관악 757.8
광진 528.9
구로 591.7
금천 418.0
남대문 181.6
노원 572.7
도봉 315.4
동대문 507.2
동작 446.0
마포 591.9
방배 119.9
서대문 387.2
서부 268.8
서초 489.6
성동 362.2
성북 186.7
송파 798.0
수서 383.8
양천 510.0
영등포 695.6
용산 404.0
은평 297.9
종로 237.9
종암 233.1
중랑 561.5
중부 311.7
혜화 213.4pd.pivot_table(crime_raw_data, index=['구분', '죄종', '발생검거']) #제일 왼쪽기준으로 unique됨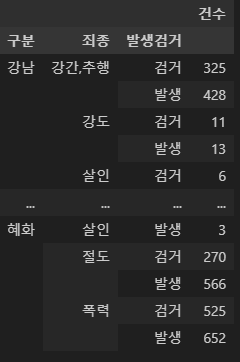
crime_station = pd.pivot_table(
crime_raw_data,
index=['구분'],
columns=['죄종', '발생검거'],
aggfunc=[np.sum],
fill_value=0
)
# 그러나 이렇게 정리된 데이터의 경우, column이 multi로 잡혀있음
crime_stationcrime_station.columns->
MultiIndex([('sum', '건수', '강간,추행', '검거'),
('sum', '건수', '강간,추행', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])->
crime_station['sum', '건수','강도','검거']이렇게 해야 데이터 찾기 가능
crime_station.columns = crime_station.columns.droplevel([0,1]) #다중 컬럼에서 특정 컬럼 제거
crime_station.columns->
MultiIndex([('강간,추행', '검거'),
('강간,추행', '발생'),
( '강도', '검거'),
( '강도', '발생'),
( '살인', '검거'),
( '살인', '발생'),
( '절도', '검거'),
( '절도', '발생'),
( '폭력', '검거'),
( '폭력', '발생')],
names=['죄종', '발생검거'])
수야는 코린이에서 더 나아갈거야