SQL
1.SQL

COUNT() 내부에 어떤 값이 들어가더라도 값은 동일하다안에 1이 있는 것은 record의 수를 계산하는 암묵적인 룰record의 수 만큼 더함(null 값 신경 X)null 값은 제외null 값 제외
2.zeppelin 설정
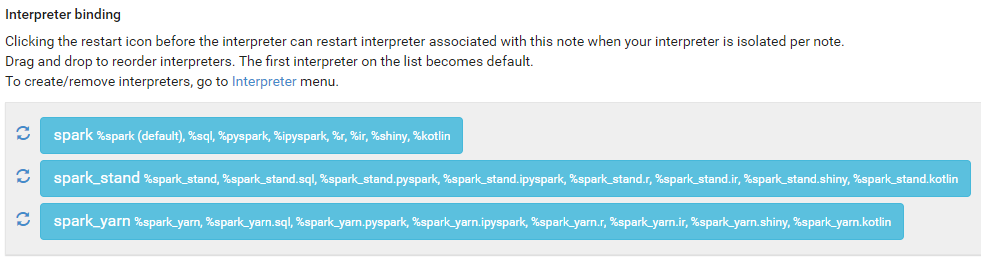
상단의 notebook -> create new notebook으로 실행우측의 설정(Interpreter binding)을 클릭해 기본 설정 확인 가능제일 위의 값이 default이며 순서를 변경하여 default를 다르게 설정할 수 있음%~ 를 사용해 spark, s
3.zeppelin 기본 실습
ubuntu에서 jps로 확인하면 SparkSubmit이 작동중인 것 확인 가능기본적으로 scala 사용python으로 사용하기 위해서는 %pyspark를 사용함jps에서 SparkSubmit이 추가로 동작하는 것을 확인할 수 있음spark master web ui:
4.spark_sql_zeppelin
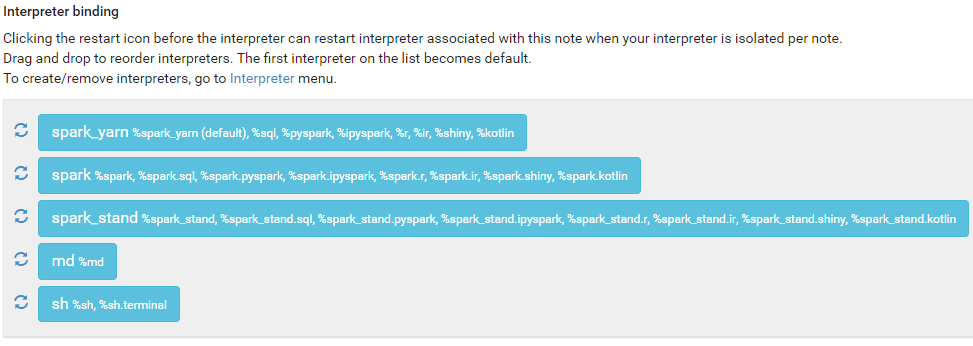
Import note -> Select JSON File/IPYNB Filespark_yarn을 default로 설정yarn cluster 실행원본 파일: 6.4Gbthree copy: 19.3GbRemoteInterpreterServer: zeppelin에서 실행중인
5.zeppelin airline 데이터 탐색

df = spark.read.csv("/skybluelee/dat/airline_on_time")sql에서 사용하기 위해 tempview로 등록df이 자주 사용될 예정이므로 캐시처리함action을 위한 countQ-01 항공사 목록?Q-02 항공사 개수?Q-03 항공사
6.spark mysql zeppelin

spark_alone을 default로 실행persist만으로는 동작하지 않으므로 show로 action 실행Apache Storm이 추가됨. 이를 spark에서 확인하면Apache Storm값이 존재하지 않음. 이유는 df라는 캐시된 dataframe에서 값을 읽기
7.spark sql thrift server

thriftserver가 jdbc odbc 연결로 spark sql을 사용할 수 있도록 함.thriftserver는 spark application중 하나.thrift server -> jdbc -> sqlsql -> jdbc -> SparkSubmit -> Execu
8.MySQL
데이터 수집 중 값이 변경 되었을 경우