zeppelin 구동
$ /skybluelee/zeppelin0/bin/zeppelin-daemon.sh restart.zpln import
Import note -> Select JSON File/IPYNB File
EDA
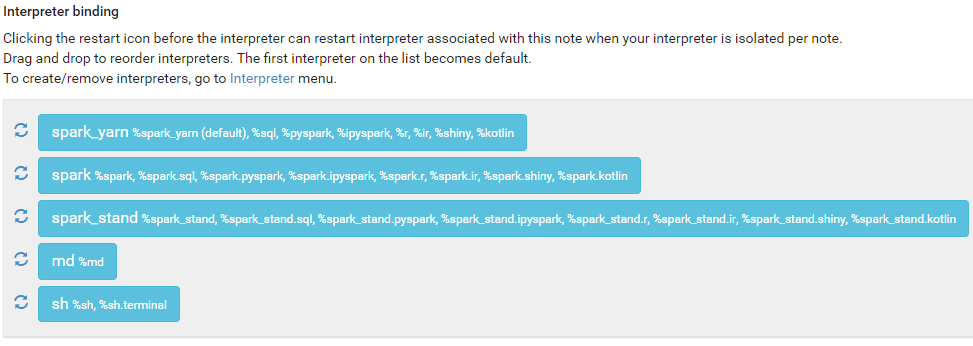
spark_yarn을 default로 설정
$ /skybluelee/hadoop3/sbin/start-all.shyarn cluster 실행
%sh
/skybluelee/hadoop3/bin/hdfs dfs -ls -h /skybluelee/data/airline_on_time # check files list....
/skybluelee/hadoop3/bin/hdfs dfs -du -s -h /skybluelee/data/airline_on_time # check disk usage....
Found 12 items
-rw-r--r-- 3 spark supergroup 515.3 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/1997.csv
-rw-r--r-- 3 spark supergroup 513.5 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/1998.csv
-rw-r--r-- 3 spark supergroup 527.3 M 2023-03-06 08:15 /skybluelee/data/airline_on_time/1999.csv
-rw-r--r-- 3 spark supergroup 543.7 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/2000.csv
-rw-r--r-- 3 spark supergroup 572.6 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/2001.csv
-rw-r--r-- 3 spark supergroup 505.9 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/2002.csv
-rw-r--r-- 3 spark supergroup 597.7 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/2003.csv
-rw-r--r-- 3 spark supergroup 638.8 M 2023-03-06 08:15 /skybluelee/data/airline_on_time/2004.csv
-rw-r--r-- 3 spark supergroup 639.9 M 2023-03-06 08:15 /skybluelee/data/airline_on_time/2005.csv
-rw-r--r-- 3 spark supergroup 640.9 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/2006.csv
-rw-r--r-- 3 spark supergroup 670.3 M 2023-03-06 08:15 /skybluelee/data/airline_on_time/2007.csv
-rw-r--r-- 3 spark supergroup 223.2 M 2023-03-06 08:16 /skybluelee/data/airline_on_time/2008.csv
6.4 G 19.3 G /skybluelee/data/airline_on_time원본 파일: 6.4Gb
three copy: 19.3Gb
$ jps
2723 Jps
2457 RemoteInterpreterServer
1513 NameNode
1770 SecondaryNameNode
1948 ResourceManager
1007 ZeppelinServerRemoteInterpreterServer: zeppelin에서 실행중인 shell
ResourceManager: yarn
NameNode, SecondaryNameNode: hdfs
경로
notebook -> aws -> ZeppelinServer(jps) -> %sh(shell) check -> RemoteInterpreterServer -> ZeppelinServer -> aws -> notebook
raw_data 확인
%pyspark
df_raw = spark.read\
.text("/skybluelee/data/airline_on_time")
df_raw.show(5, truncate=False)
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|value |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|Year,Month,DayofMonth,DayOfWeek,DepTime,CRSDepTime,ArrTime,CRSArrTime,UniqueCarrier,FlightNum,TailNum,ActualElapsedTime,CRSElapsedTime,AirTime,ArrDelay,DepDelay,Origin,Dest,Distance,TaxiIn,TaxiOut,Cancelled,CancellationCode,Diverted,CarrierDelay,WeatherDelay,NASDelay,SecurityDelay,LateAircraftDelay|
|1997,1,28,2,1615,1615,1728,1725,WN,1159,N683,73,70,60,3,0,ABQ,PHX,328,4,9,0,NA,0,NA,NA,NA,NA,NA |
|1997,1,29,3,1624,1615,1735,1725,WN,1159,N626,71,70,56,10,9,ABQ,PHX,328,4,11,0,NA,0,NA,NA,NA,NA,NA |
|1997,1,30,4,1626,1615,1730,1725,WN,1159,N321,64,70,52,5,11,ABQ,PHX,328,2,10,0,NA,0,NA,NA,NA,NA,NA |
|1997,1,31,5,1628,1615,1729,1725,WN,1159,N383,61,70,50,4,13,ABQ,PHX,328,4,7,0,NA,0,NA,NA,NA,NA,NA |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
only showing top 5 rowshdfs가 여러개인 경우 경로를
"hdfs://spark-master-01/skybluelee/data/airline_on_time"과 같이 앞에 설정할 수 있다
data loading
%pyspark
df = spark.read\
.csv("/skybluelee/data/airline_on_time",\
header = True,\
inferSchema = True)데이터 스키마 확인
%pyspark
df.printSchema()
root
|-- Year: integer (nullable = true)
|-- Month: integer (nullable = true)
|-- DayofMonth: integer (nullable = true)
|-- DayOfWeek: integer (nullable = true)
|-- DepTime: string (nullable = true)
|-- CRSDepTime: integer (nullable = true)
|-- ArrTime: string (nullable = true)
|-- CRSArrTime: integer (nullable = true)
|-- UniqueCarrier: string (nullable = true)
|-- FlightNum: integer (nullable = true)
|-- TailNum: string (nullable = true)
|-- ActualElapsedTime: string (nullable = true)
|-- CRSElapsedTime: string (nullable = true)
|-- AirTime: string (nullable = true)
|-- ArrDelay: string (nullable = true)
|-- DepDelay: string (nullable = true)
|-- Origin: string (nullable = true)
|-- Dest: string (nullable = true)
|-- Distance: integer (nullable = true)
|-- TaxiIn: string (nullable = true)
|-- TaxiOut: string (nullable = true)
|-- Cancelled: integer (nullable = true)
|-- CancellationCode: string (nullable = true)
|-- Diverted: integer (nullable = true)
|-- CarrierDelay: string (nullable = true)
|-- WeatherDelay: string (nullable = true)
|-- NASDelay: string (nullable = true)
|-- SecurityDelay: string (nullable = true)
|-- LateAircraftDelay: string (nullable = true)데이터 컬럼 개수 확인
%pyspark
print(df.columns)
print(len(df.columns))
['Year', 'Month', 'DayofMonth', 'DayOfWeek', 'DepTime', 'CRSDepTime', 'ArrTime', 'CRSArrTime', 'UniqueCarrier', 'FlightNum', 'TailNum', 'ActualElapsedTime', 'CRSElapsedTime', 'AirTime', 'ArrDelay', 'DepDelay', 'Origin', 'Dest', 'Distance', 'TaxiIn', 'TaxiOut', 'Cancelled', 'CancellationCode', 'Diverted', 'CarrierDelay', 'WeatherDelay', 'NASDelay', 'SecurityDelay', 'LateAircraftDelay']
29데이터 건수(개수) 확인
%pyspark
df.count()
70989394데이터 출력
%pyspark
df.show(5)
+----+-----+----------+---------+-------+----------+-------+----------+-------------+---------+-------+-----------------+--------------+-------+--------+--------+------+----+--------+------+-------+---------+----------------+--------+------------+------------+--------+-------------+-----------------+
|Year|Month|DayofMonth|DayOfWeek|DepTime|CRSDepTime|ArrTime|CRSArrTime|UniqueCarrier|FlightNum|TailNum|ActualElapsedTime|CRSElapsedTime|AirTime|ArrDelay|DepDelay|Origin|Dest|Distance|TaxiIn|TaxiOut|Cancelled|CancellationCode|Diverted|CarrierDelay|WeatherDelay|NASDelay|SecurityDelay|LateAircraftDelay|
+----+-----+----------+---------+-------+----------+-------+----------+-------------+---------+-------+-----------------+--------------+-------+--------+--------+------+----+--------+------+-------+---------+----------------+--------+------------+------------+--------+-------------+-----------------+
|1997| 1| 28| 2| 1615| 1615| 1728| 1725| WN| 1159| N683| 73| 70| 60| 3| 0| ABQ| PHX| 328| 4| 9| 0| NA| 0| NA| NA| NA| NA| NA|
|1997| 1| 29| 3| 1624| 1615| 1735| 1725| WN| 1159| N626| 71| 70| 56| 10| 9| ABQ| PHX| 328| 4| 11| 0| NA| 0| NA| NA| NA| NA| NA|
|1997| 1| 30| 4| 1626| 1615| 1730| 1725| WN| 1159| N321| 64| 70| 52| 5| 11| ABQ| PHX| 328| 2| 10| 0| NA| 0| NA| NA| NA| NA| NA|
|1997| 1| 31| 5| 1628| 1615| 1729| 1725| WN| 1159| N383| 61| 70| 50| 4| 13| ABQ| PHX| 328| 4| 7| 0| NA| 0| NA| NA| NA| NA| NA|
|1997| 1| 14| 2| 1503| 1425| 1619| 1535| WN| 1221| N513| 76| 70| 64| 44| 38| ABQ| PHX| 328| 4| 8| 0| NA| 0| NA| NA| NA| NA| NA|
+----+-----+----------+---------+-------+----------+-------+----------+-------------+---------+-------+-----------------+--------------+-------+--------+--------+------+----+--------+------+-------+---------+----------------+--------+------------+------------+--------+-------------+-----------------+
only showing top 5 rows데이터 출력 (z.show)
%pyspark
z.show(df)
z는 zeppelin만의 context이다.
데이터 출력(컬럼 지정)
%pyspark
df.select("Year",
"Month",
"DayofMonth",
"DayOfWeek",
"Origin",
"Dest",
"ActualElapsedTime",
"AirTime",
"DepDelay",
"ArrDelay",
"Cancelled").show(5)
+----+-----+----------+---------+------+----+-----------------+-------+--------+--------+---------+
|Year|Month|DayofMonth|DayOfWeek|Origin|Dest|ActualElapsedTime|AirTime|DepDelay|ArrDelay|Cancelled|
+----+-----+----------+---------+------+----+-----------------+-------+--------+--------+---------+
|1997| 1| 28| 2| ABQ| PHX| 73| 60| 0| 3| 0|
|1997| 1| 29| 3| ABQ| PHX| 71| 56| 9| 10| 0|
|1997| 1| 30| 4| ABQ| PHX| 64| 52| 11| 5| 0|
|1997| 1| 31| 5| ABQ| PHX| 61| 50| 13| 4| 0|
|1997| 1| 14| 2| ABQ| PHX| 76| 64| 38| 44| 0|
+----+-----+----------+---------+------+----+-----------------+-------+--------+--------+---------+
only showing top 5 rows 데이터 출력(컬럼 지정, z.show)
%pyspark
z.show(
df.select("Year",
"Month",
"DayofMonth",
"DayOfWeek",
"Origin",
"Dest",
"ActualElapsedTime",
"AirTime",
"DepDelay",
"ArrDelay",
"Cancelled")
)데이터 분포 확인
%pyspark
df.select("ActualElapsedTime",
"AirTime",
"DepDelay",
"ArrDelay").describe().show()
+-------+------------------+------------------+------------------+------------------+
|summary| ActualElapsedTime| AirTime| DepDelay| ArrDelay|
+-------+------------------+------------------+------------------+------------------+
| count| 70989394| 70989394| 70989394| 70989394|
| mean|125.16478232483837|103.40990304298207| 8.774435819587918| 7.316262003101938|
| stddev| 70.39732489317652| 72.70371630194026|31.182975034654735|33.750896861147524|
| min| -1| -1| -1| -1|
| max| NA| NA| NA| NA|
+-------+------------------+------------------+------------------+------------------+ 데이터 분포 확인(타입 변환)
NA와 같이 숫자가 아닌 값이 나오는 경우가 존재
%pyspark
df.select(df.ActualElapsedTime.cast('int'),
df.AirTime.cast('int'),
df.DepDelay.cast('int'),
df.ArrDelay.cast('int')).describe().show()
+-------+------------------+------------------+------------------+------------------+
|summary| ActualElapsedTime| AirTime| DepDelay| ArrDelay|
+-------+------------------+------------------+------------------+------------------+
| count| 69246371| 69246251| 69398900| 69246371|
| mean|125.16478232483837|103.40990304298207| 8.774435819587918| 7.316262003101938|
| stddev| 70.39732489317652| 72.70371630194025|31.182975034654742|33.750896861147524|
| min| -719| -3818| -1410| -1302|
| max| 1879| 3508| 2601| 2598|
+-------+------------------+------------------+------------------+------------------+ NA값은 type casting이 되지 않으므로 count의 값이 낮아짐
평균, 표준편차는 int값만 가지고 계산하므로 값이 동일
최소, 최대는 크기가 확실하게 변함
-> 제대로 된 통계를 보기 위해서는 값을 제대로 설정해야 함
데이터 분포 확인(summary, 컬럼, 항목)
%pyspark
df.select("ActualElapsedTime",
"AirTime",
"DepDelay",
"ArrDelay")\
.summary("count",
"mean",
"stddev",
"min",
"0%",
"5%",
"25%",
"50%",
"75%",
"95%",
"100%",
"max").show()
+-------+------------------+------------------+------------------+------------------+
|summary| ActualElapsedTime| AirTime| DepDelay| ArrDelay|
+-------+------------------+------------------+------------------+------------------+
| count| 70989394| 70989394| 70989394| 70989394|
| mean|125.16478232483837|103.40990304298207| 8.774435819587918| 7.316262003101938|
| stddev| 70.39732489317652| 72.70371630194026|31.182975034654735|33.750896861147524|
| min| -1| -1| -1| -1|
| 0%| -719.0| -3818.0| -1410.0| -1302.0|
| 5%| 49.0| 33.0| -8.0| -20.0|
| 25%| 73.0| 54.0| -3.0| -9.0|
| 50%| 106.0| 85.0| 0.0| -1.0|
| 75%| 157.0| 134.0| 7.0| 11.0|
| 95%| 272.0| 245.0| 59.0| 64.0|
| 100%| 1879.0| 3508.0| 2601.0| 2598.0|
| max| NA| NA| NA| NA|
+-------+------------------+------------------+------------------+------------------+ min의 값과 0%의 값이 동일해야하고, max의 값과 100%의 값이 동일해야 하지만 실제로는 그렇지 않다. 이또한 int와 str간의 문제이다.
데이터 분포 확인(summary, 컬럼, 항목, 타입 변환)
%pyspark
df.select(df.ActualElapsedTime.cast('int'),
df.AirTime.cast('int'),
df.DepDelay.cast('int'),
df.ArrDelay.cast('int'))\
.summary("count",
"mean",
"stddev",
"min",
"0%",
"5%",
"25%",
"50%",
"75%",
"95%",
"100%",
"max").show()
+-------+------------------+------------------+-----------------+------------------+
|summary| ActualElapsedTime| AirTime| DepDelay| ArrDelay|
+-------+------------------+------------------+-----------------+------------------+
| count| 69246371| 69246251| 69398900| 69246371|
| mean|125.16478232483837|103.40990304298207|8.774435819587918| 7.316262003101938|
| stddev| 70.39732489317653| 72.70371630194028|31.18297503465473|33.750896861147524|
| min| -719| -3818| -1410| -1302|
| 0%| -719| -3818| -1410| -1302|
| 5%| 49| 33| -8| -20|
| 25%| 73| 54| -3| -9|
| 50%| 106| 85| 0| -1|
| 75%| 157| 134| 7| 11|
| 95%| 272| 245| 59| 64|
| 100%| 1879| 3508| 2601| 2598|
| max| 1879| 3508| 2601| 2598|
+-------+------------------+------------------+-----------------+------------------+