spark_alone을 default로 실행
$ /skybluelee/spark3/sbin/start-all.sh
$ /skybluelee/hadoop3/sbin/start-all.sh
$ /skybluelee/zeppelin0/bin/zeppelin-daemon.sh restart
/skybluelee/spark3/sbin/stop-all.sh
/skybluelee/hadoop3/sbin/stop-all.sh
$ ssh spark-worker-01 /skybluelee/jdk8/bin/jps
5473 Jps
5346 Workermysql setting, db pos
ubuntu
$ mysql -u root -p
no pw
mysql> use skybluelee_db;
mysql> select * from projects;
+----+--------------+-------------------------+---------+
| id | name | website | manager |
+----+--------------+-------------------------+---------+
| 1 | Apache Spark | http://spark.apache.org | Michael |
| 2 | Apache Hive | http://hive.apache.org | Andy |
| 3 | Apache Kafka | http://kafka.apache.org | Justin |
| 4 | Apache Flink | http://flink.apache.org | Michael |
+----+--------------+-------------------------+---------+
4 rows in set (0.00 sec)zeppelin
val df = spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://spark-master-01:3306/skybluelee_db")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "projects")
.option("user", "root")
.option("password", "")
.load()
df.printSchema //--스키마 확인....
df.show(false) //--내용 확인....
root
|-- id: decimal(20,0) (nullable = true)
|-- name: string (nullable = true)
|-- website: string (nullable = true)
|-- manager: string (nullable = true)
+---+------------+-----------------------+-------+
|id |name |website |manager|
+---+------------+-----------------------+-------+
|1 |Apache Spark|http://spark.apache.org|Michael|
|2 |Apache Hive |http://hive.apache.org |Andy |
|3 |Apache Kafka|http://kafka.apache.org|Justin |
|4 |Apache Flink|http://flink.apache.org|Michael|
+---+------------+-----------------------+-------+Read Data From MySQL
1
dataframe cache
df.persist
df.show(false)
+---+------------+-----------------------+-------+
|id |name |website |manager|
+---+------------+-----------------------+-------+
|1 |Apache Spark|http://spark.apache.org|Michael|
|2 |Apache Hive |http://hive.apache.org |Andy |
|3 |Apache Kafka|http://kafka.apache.org|Justin |
|4 |Apache Flink|http://flink.apache.org|Michael|
+---+------------+-----------------------+-------+persist만으로는 동작하지 않으므로 show로 action 실행
Insert Data
%mysql
insert into skybluelee_db.projects (name, website, manager) VALUES ('Apache Storm', 'http://storm.apache.org', 'Andy');
select * from skybluelee_db.projects;
-- delete from skybluelee_db.projects where name = 'Apache Storm';
Apache Storm이 추가됨. 이를 spark에서 확인하면
df.show(false)
+---+------------+-----------------------+-------+
|id |name |website |manager|
+---+------------+-----------------------+-------+
|1 |Apache Spark|http://spark.apache.org|Michael|
|2 |Apache Hive |http://hive.apache.org |Andy |
|3 |Apache Kafka|http://kafka.apache.org|Justin |
|4 |Apache Flink|http://flink.apache.org|Michael|
+---+------------+-----------------------+-------+Apache Storm값이 존재하지 않음. 이유는 df라는 캐시된 dataframe에서 값을 읽기 때문
원본 데이터를 변경하더라도 캐시된 데이터에 영향을 주지 못함
df.unpersist
df.show(false)
+---+------------+-----------------------+-------+
|id |name |website |manager|
+---+------------+-----------------------+-------+
|1 |Apache Spark|http://spark.apache.org|Michael|
|2 |Apache Hive |http://hive.apache.org |Andy |
|3 |Apache Kafka|http://kafka.apache.org|Justin |
|4 |Apache Flink|http://flink.apache.org|Michael|
|5 |Apache Storm|http://storm.apache.org|Andy |
+---+------------+-----------------------+-------+캐시를 해제하면 df는 원본 데이터에서 갖고 오므로 Apache Storm이 추가된 것을 확인할 수 있음.
2
temp view 생성
df.createOrReplaceTempView("projects")
val df_sql = spark.sql("SELECT * FROM projects WHERE id > 3")
df_sql.show()
spark.table("projects").show()
spark.catalog.listTables.show()
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 1|Apache Spark|http://spark.apac...|Michael|
| 2| Apache Hive|http://hive.apach...| Andy|
| 3|Apache Kafka|http://kafka.apac...| Justin|
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
+--------+--------+-----------+---------+-----------+
| name|database|description|tableType|isTemporary|
+--------+--------+-----------+---------+-----------+
|projects| null| null|TEMPORARY| true|
+--------+--------+-----------+---------+-----------+python에서 실행
%pyspark
spark.table("projects").show() # OK!!....
print(spark.catalog.listTables()) # OK!!....
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 1|Apache Spark|http://spark.apac...|Michael|
| 2| Apache Hive|http://hive.apach...| Andy|
| 3|Apache Kafka|http://kafka.apac...| Justin|
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
df_sql.show() # NO??....
-> scala에서 사용했기 때문에 python은 인식 못함catalog는 모든 언어에 대해 접근 가능
scala -> python으로 실행하고자 하는 경우 변수는 공유가 되지 않으므로 dataframe으로 만들어 temp view로 만들어서 사용 가능.
3-1. sub query 작성
dbtable
val df_sub = spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://spark-master-01:3306/")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "(SELECT * FROM skybluelee_db.projects WHERE id > 3) as subprojects") //--SubQuery with Alias.... ('dbtable' option....) -> (SELECT <columns> FROM <dbtable>) -> Driver Web UI > SQL > Details for Query 확인....
.option("user", "root")
.option("password", "")
.load()
df_sub.show()
df_sub.rdd.getNumPartitions
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
df_sub: org.apache.spark.sql.DataFrame = [id: decimal(20,0), name: string ... 2 more fields]
res5: Int = 1url 옵션은 db까지 지정해도 되지만 하지 않아도 상관 없다. 위와 같이 dbtable에서 지정 가능함.
query 문을 ()로 감싸고 alias를 주어야 함.
partition의 개수가 1개 -> single thread로 읽는데 이를 병렬로 바꿔야 함
query
val df_sub2 = spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://spark-master-01:3306/")
.option("driver", "com.mysql.jdbc.Driver")
.option("query", "SELECT * FROM skybluelee_db.projects WHERE id > 3")
.option("user", "root")
.option("password", "")
.load()
df_sub2.show()
df_sub2.rdd.getNumPartitions
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
df_sub2: org.apache.spark.sql.DataFrame = [id: decimal(20,0), name: string ... 2 more fields]
res6: Int = 1query에서 작성시 alias를 작성할 필요 없음
spark 내부에서 alias를 처리해주기 때문 -> spark-master-01:4040/SQL 에서 확인 가능
3-2. PushedFilters
Log Check
$ sudo tail -f /var/lib/mysql/spark-master-01.logval df_sub3 = spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://spark-master-01:3306/")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "skybluelee_db.projects")
.option("user", "root")
.option("password", "")
.load()
.filter("id > 3")
.where("id = 4")
df_sub3.show()
df_sub3.rdd.getNumPartitions논리상으로는 WHERE은 mysql에서 실행되고 filter는 spark sql에서 실행됨
하지만 spark는 lazy한 특성을 가지고 있고 web ui에서 확인하면

PushedFilters에서 filter, where 동작이 담겨있고 이는 mysql에서 실행됨
4-1. Parallel and Distributed
val df_parallel = spark
.read
.format("jdbc")
.option("url", "jdbc:mysql://spark-master-01:3306/")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "skybluelee_db.projects")
.option("user", "root")
.option("password", "")
.option("numPartitions", 3) //--The maximum number of partitions that can be used for parallelism in table reading and writing....
.option("partitionColumn", "id") //--"partitionColumn" must be a numeric, date, or timestamp column from the table in question....
.option("lowerBound", 1) //--"lowerBound" and "upperBound" are just used to decide the partition stride, not for filtering the rows in table....
.option("upperBound", 5) //--"lowerBound" and "upperBound" are just used to decide the partition stride, not for filtering the rows in table....
.load()
df_parallel.show()
df_parallel.rdd.getNumPartitions
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 1|Apache Spark|http://spark.apac...|Michael|
| 2| Apache Hive|http://hive.apach...| Andy|
| 3|Apache Kafka|http://kafka.apac...| Justin|
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
df_parallel: org.apache.spark.sql.DataFrame = [id: decimal(20,0), name: string ... 2 more fields]
res10: Int = 3partitionColumn: 범위로 나눌 수 있는 numeric, date, timestamp를 변수로 사용. id를 사용해 3개의 partition으로 나누어 병렬로 읽을 수 있도록 만듦. 만약 이러한 값이 없다면 indexing을 하여 병렬 처리 가능.
lowerBound와 upperBound 사이에서 적절히 지정한 partition 개수로 나눔.
Write data to MySQL
write property setting
val prop: java.util.Properties = new java.util.Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "")
prop.setProperty("driver", "com.mysql.jdbc.Driver")SaveMode.Append: 기존 table에 insert
기존 df 확인
df.show
df_sub.show()
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 1|Apache Spark|http://spark.apac...|Michael|
| 2| Apache Hive|http://hive.apach...| Andy|
| 3|Apache Kafka|http://kafka.apac...| Justin|
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+df_sub
.select("name", "website", "manager")
.write
.mode(org.apache.spark.sql.SaveMode.Append) //--Append mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects", prop)
df.show
+---+------------+--------------------+-------+
| id| name| website|manager|
+---+------------+--------------------+-------+
| 1|Apache Spark|http://spark.apac...|Michael|
| 2| Apache Hive|http://hive.apach...| Andy|
| 3|Apache Kafka|http://kafka.apac...| Justin|
| 4|Apache Flink|http://flink.apac...|Michael|
| 5|Apache Storm|http://storm.apac...| Andy|
| 6|Apache Flink|http://flink.apac...|Michael|
| 7|Apache Storm|http://storm.apac...| Andy|
+---+------------+--------------------+-------+id는 상태에 맞게 수정됨
SaveMode.Overwrite
신규 테이블 생성
df_sub.show()
df_sub
.select("name", "website", "manager")
.write
.mode(org.apache.spark.sql.SaveMode.Overwrite) //--Overwrite mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects_new", prop)
mysql> show tables;
+-------------------------+
| Tables_in_skybluelee_db |
+-------------------------+
| projects |
| projects_new |
+-------------------------+
2 rows in set (0.00 sec)
mysql> select * from projects_new;
+--------------+-------------------------+---------+
| name | website | manager |
+--------------+-------------------------+---------+
| Apache Flink | http://flink.apache.org | Michael |
| Apache Storm | http://storm.apache.org | Andy |
| Apache Flink | http://flink.apache.org | Michael |
| Apache Storm | http://storm.apache.org | Andy |
+--------------+-------------------------+---------+
4 rows in set (0.00 sec)projects_new table을 하나더 생성함.
overwrite
df_sub
.select("id", "name", "website", "manager")
.write
.mode(org.apache.spark.sql.SaveMode.Overwrite) //--Overwrite mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects_new", prop)
mysql> select * from projects_new;
+------+--------------+-------------------------+---------+
| id | name | website | manager |
+------+--------------+-------------------------+---------+
| 4 | Apache Flink | http://flink.apache.org | Michael |
| 5 | Apache Storm | http://storm.apache.org | Andy |
| 6 | Apache Flink | http://flink.apache.org | Michael |
| 7 | Apache Storm | http://storm.apache.org | Andy |
+------+--------------+-------------------------+---------+
4 rows in set (0.00 sec) overwrite했기 때문에 id가 있는 테이블로 대체됨.
overwrite column add
df_sub
.select("id", "name", "website", "manager")
.withColumn("new_id", col("id") + 100) //--컬럼 추가....
.write
.mode(org.apache.spark.sql.SaveMode.Overwrite) //--Overwrite mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects_new", prop)
mysql> select * from projects_new;
+------+--------------+-------------------------+---------+--------+
| id | name | website | manager | new_id |
+------+--------------+-------------------------+---------+--------+
| 4 | Apache Flink | http://flink.apache.org | Michael | 104 |
| 5 | Apache Storm | http://storm.apache.org | Andy | 105 |
| 6 | Apache Flink | http://flink.apache.org | Michael | 106 |
| 7 | Apache Storm | http://storm.apache.org | Andy | 107 |
+------+--------------+-------------------------+---------+--------+
4 rows in set (0.00 sec) SaveMode.Overwrite with UDF + Insert
UDF: User Defined Function
val extractSuffixUDF = spark
.udf //--udf....
.register(
"myUDF",
(arg1: String) => arg1.substring(arg1.lastIndexOf(".")+1)
)UDF setting
website의 . 이하를 얻음
//--#01. Overwrite....
df_sub
.select("id", "name", "website", "manager")
.withColumn("website_suffix", extractSuffixUDF(col("website"))) //--컬럼 추가.... (w/ UDF 인스턴스....)
.write
.mode(org.apache.spark.sql.SaveMode.Overwrite) //--Overwrite mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects_new", prop)val 사용
//--#02. Append....
df_sub
.select("id", "name", "website", "manager")
.withColumn("website_suffix", callUDF("myUDF", 'website)) //--컬럼 추가.... (w/ UDF 이름.... callUDF(udf이름, 컬럼))
.write
.mode("append") //--Append mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects_new", prop)
mysql> select * from projects_new;
+------+--------------+-------------------------+---------+----------------+
| id | name | website | manager | website_suffix |
+------+--------------+-------------------------+---------+----------------+
| 4 | Apache Flink | http://flink.apache.org | Michael | org |
| 5 | Apache Storm | http://storm.apache.org | Andy | org |
| 6 | Apache Flink | http://flink.apache.org | Michael | org |
| 7 | Apache Storm | http://storm.apache.org | Andy | org |
-> overwrite
| 4 | Apache Flink | http://flink.apache.org | Michael | org |
| 5 | Apache Storm | http://storm.apache.org | Andy | org |
| 6 | Apache Flink | http://flink.apache.org | Michael | org |
| 7 | Apache Storm | http://storm.apache.org | Andy | org |
+------+--------------+-------------------------+---------+----------------+
-> append
8 rows in set (0.00 sec) UDF 이름 사용.
callUDF()의 두번째 인자의 column 값에 '이 하나만 존재함.
udf 조회
spark
.catalog
.listFunctions
.where($"name" like "%myUDF%")
.show(500, false)
+-----+--------+-----------+-----------------------------------------------------------+-----------+
|name |database|description|className |isTemporary|
+-----+--------+-----------+-----------------------------------------------------------+-----------+
|myUDF|null |null |org.apache.spark.sql.UDFRegistration$$Lambda$4612/258634388|true |
+-----+--------+-----------+-----------------------------------------------------------+-----------+ where 조건이 없다면 모든 함수가 나오므로 where 반드시 사용
query기반으로 UDF 사용
spark
.sql("""
SELECT
id,
name,
website,
manager,
myUDF(website) as website_suffix_by_sql --UDF 적용....
FROM
projects
""")
.write
.mode(org.apache.spark.sql.SaveMode.Overwrite) //--Overwrite mode....
.jdbc("jdbc:mysql://spark-master-01:3306/skybluelee_db", "projects_new", prop)query 내부에 함수 이용 사용.
JOIN
spark3 내부에 존재하는 example을 hdfs 환경에 업로드
%sh
/skybluelee/hadoop3/bin/hdfs dfs -put -f /skybluelee/spark3/examples/src/main/resources /skybluelee/data/
/skybluelee/hadoop3/bin/hdfs dfs -ls /skybluelee/data
Found 2 items
drwxr-xr-x - spark supergroup 0 2023-03-06 08:16 /skybluelee/data/airline_on_time
drwxr-xr-x - spark supergroup 0 2023-04-06 07:12 /skybluelee/data/resources
file 읽기
val df_people = spark.read.json("hdfs://spark-master-01:9000/skybluelee/data/resources/people.json")
df_people.show
println(df_people.schema)
df_people.printSchema
df_people.filter("age > 11").show
df_people.where($"age" > 11).show
df.show(false)
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
StructType(StructField(age,LongType,true), StructField(name,StringType,true))
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
+---+------+
|age| name|
+---+------+
| 30| Andy|
| 19|Justin|
+---+------+
+---+------+
|age| name|
+---+------+
| 30| Andy|
| 19|Justin|
+---+------+
+---+------------+-----------------------+-------+broadcast hash join
df_people
.filter("age > 11") //--조인하기 전 필터링 먼저 실행....
.join(df, df_people("name") === df("manager"))
.show(55)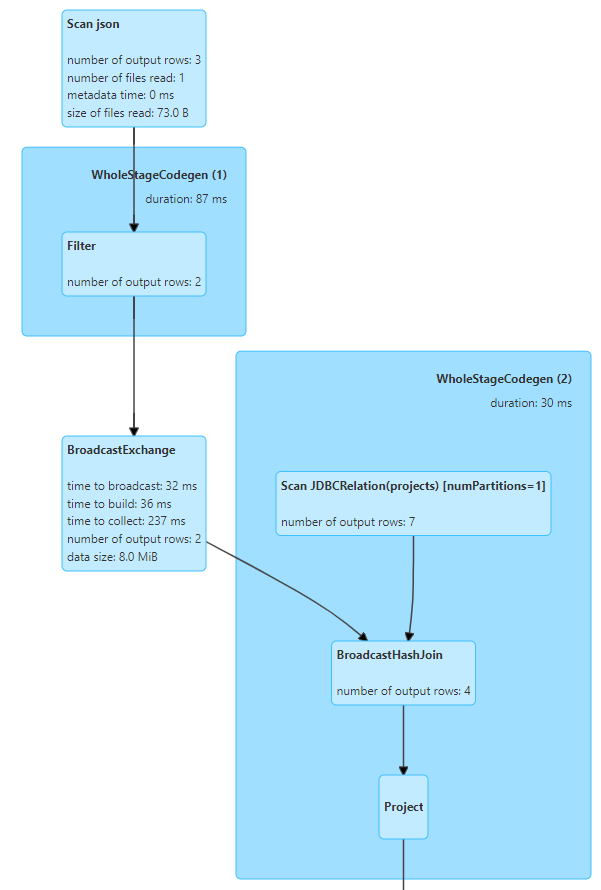
spark에서 table의 크기를 확인하고 요청하지 않아도 broadcast함.
join 이전에 filter 작업을 하는 것이 성능에 더 좋음
하지만 그렇게 하지 않더라도 spark에서 filter 이후에 join함
catalist optimizer가 실행 계획을 바꿈 join -> filter에서 filter -> join으로 변경
집계 함수
//--집계 #01....
df_people
.filter("age > 11")
.join(df, df_people("name") === df("manager"))
.groupBy(df("website"))
.count
.show
//--집계 #02....
df_people
.filter("age > 11")
.join(df, df_people("name") === df("manager"))
.groupBy(df("website"))
.agg(
avg(df_people("age")),
max(df("id"))
)
.show
+--------------------+-----+
| website|count|
+--------------------+-----+
|http://hive.apach...| 1|
|http://kafka.apac...| 1|
|http://storm.apac...| 2|
+--------------------+-----+
+--------------------+--------+-------+
| website|avg(age)|max(id)|
+--------------------+--------+-------+
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 7|
+--------------------+--------+-------+ sql join
df.createOrReplaceTempView("projects") //--TempView 생성....
df_people.createOrReplaceTempView("people") //--TempView 생성....
spark.catalog.listTables.show() //--테이블 목록 확인....
spark
.sql("""
SELECT
website,
avg(age),
max(id)
FROM
people a
JOIN
projects b
ON
a.name = b.manager
WHERE
a.age > 11
GROUP BY
b.website
""")
.show
+--------+--------+-----------+---------+-----------+
| name|database|description|tableType|isTemporary|
+--------+--------+-----------+---------+-----------+
| people| null| null|TEMPORARY| true|
|projects| null| null|TEMPORARY| true|
+--------+--------+-----------+---------+-----------+
+--------------------+--------+-------+
| website|avg(age)|max(id)|
+--------------------+--------+-------+
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 7|
+--------------------+--------+-------+ airline sql
%sh
# 로컬 다운로드 디렉토리 생성....
mkdir -p /skybluelee/data/airline_on_time_ext
# 데이터 로컬 다운로드....
wget https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/XTPZZY -O /skybluelee/data/airline_on_time_ext/airports.csv
wget https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/3NOQ6Q -O /skybluelee/data/airline_on_time_ext/carriers.csv
wget https://dataverse.harvard.edu/api/access/datafile/:persistentId?persistentId=doi:10.7910/DVN/HG7NV7/XXSL8A -O /skybluelee/data/airline_on_time_ext/plane-data.csv
# 데이터 HDFS 저장....
/skybluelee/hadoop3/bin/hdfs dfs -put -f /skybluelee/data/airline_on_time_ext /skybluelee/data/
/skybluelee/hadoop3/bin/hdfs dfs -ls /skybluelee/datahdfs에 airports, carriers, plane-data 업로드
데이터 확인
//--2006.csv....
val df_2006 = spark
.read
.option("header", true)
.option("inferSchema", false)
.csv("hdfs://spark-master-01:9000/skybluelee/data/airline_on_time/2006.csv")
//--2007.csv....
val df_2007 = spark
.read
.option("header", true)
.option("inferSchema", false)
.csv("hdfs://spark-master-01:9000/skybluelee/data/airline_on_time/2007.csv")
//--airports.csv....
val df_airports = spark
.read
.option("header", true)
.option("inferSchema", false)
.csv("hdfs://spark-master-01:9000/skybluelee/data/airline_on_time_ext/airports.csv")
//--carriers.csv....
val df_carriers = spark
.read
.option("header", true)
.option("inferSchema", false)
.csv("hdfs://spark-master-01:9000/skybluelee/data/airline_on_time_ext/carriers.csv")
df_2006.printSchema
df_airports.printSchema
df_carriers.printSchema
root
|-- Year: string (nullable = true)
|-- Month: string (nullable = true)
|-- DayofMonth: string (nullable = true)
|-- DayOfWeek: string (nullable = true)
|-- DepTime: string (nullable = true)
|-- CRSDepTime: string (nullable = true)
|-- ArrTime: string (nullable = true)
|-- CRSArrTime: string (nullable = true)
|-- UniqueCarrier: string (nullable = true)
|-- FlightNum: string (nullable = true)
|-- TailNum: string (nullable = true)
|-- ActualElapsedTime: string (nullable = true)
|-- CRSElapsedTime: string (nullable = true)
|-- AirTime: string (nullable = true)
|-- ArrDelay: string (nullable = true)
|-- DepDelay: string (nullable = true)
|-- Origin: string (nullable = true)
|-- Dest: string (nullable = true)
|-- Distance: string (nullable = true)
|-- TaxiIn: string (nullable = true)
|-- TaxiOut: string (nullable = true)
|-- Cancelled: string (nullable = true)
|-- CancellationCode: string (nullable = true)
|-- Diverted: string (nullable = true)
|-- CarrierDelay: string (nullable = true)
|-- WeatherDelay: string (nullable = true)
|-- NASDelay: string (nullable = true)
|-- SecurityDelay: string (nullable = true)
|-- LateAircraftDelay: string (nullable = true)
root
|-- iata: string (nullable = true)
|-- airport: string (nullable = true)
|-- city: string (nullable = true)
|-- state: string (nullable = true)
|-- country: string (nullable = true)
|-- lat: string (nullable = true)
|-- long: string (nullable = true)
root
|-- Code: string (nullable = true)
|-- Description: string (nullable = true)auto broadcast mode: Adaptive Query Execution(AQE)
println(spark.conf.get("spark.sql.autoBroadcastJoinThreshold")) //--Default : 10485760 bytes (10 MB)
println(spark.conf.get("spark.sql.adaptive.enabled")) //--Default : false -> true(since 3.2.0....)
spark.conf.set("spark.sql.adaptive.enabled", false) //--AQE Enabled 'FALSE' 설정....
println(spark.conf.get("spark.sql.adaptive.enabled")) //--Default : false -> true(since 3.2.0....)
10485760b
true
false10Mb 이상은 자동 broadcast
adaptive.enabled는 default가 true
AQE가 off인 상태임
파일 크기에 따른 join
df_2006
.join(df_2007, df_2006("FlightNum") === df_2007("FlightNum"))
.show()df_2006, df_2007는 600MB의 크기로 기본적으로 sort merge join을 실행한다.
df_2006
.join(df_carriers, df_2006("UniqueCarrier") === df_carriers("Code"))
.show(50) //--number of output rows: 51df_carriers는 42kB로 10MB이하는 broadcast join을 실행한다.
AQE를 직접 만들어보기
특정 크기 이하의 파일은 broadcast를 하는데 이를 이용하여 항공사별로 나누어 broadcast join을 유도
항공사 count
df_2006
.groupBy("UniqueCarrier")
.count()
.sort($"count".asc) //--"TZ"....
.show()
+-------------+-------+
|UniqueCarrier| count|
+-------------+-------+
| TZ| 19602|
| AQ| 35387|
| HA| 52173|
| F9| 90181|
| B6| 155732|
| AS| 159404|
| FL| 237645|
| EV| 273143|
| OH| 278099|
| YV| 304764|
| CO| 309389|
| NW| 432880|
| XE| 441470|
| UA| 500008|
| US| 504844|
| DL| 506086|
| OO| 548109|
| MQ| 550088|
| AA| 643597|
| WN|1099321|
+-------------+-------+ df_2006
.where(df_2006("UniqueCarrier") === "TZ") //--filtering....
.join(df_2007, df_2006("FlightNum") === df_2007("FlightNum"))
.show() 위는 broadcast join이 아닌 sort merge join이 실행되는데 where을 사용하였다 하더라도 필터링 이후의 df_2006의 크기를 알 수 없기 때문에 sort merge join이 실행됨.
AQE 활성화
spark.conf.set("spark.sql.adaptive.enabled", true) //--AQE Enabled 'TRUE' 설정....
println(spark.conf.get("spark.sql.adaptive.enabled")) //--Default : false -> true(since 3.2.0....)
df_2006
.where(df_2006("UniqueCarrier") === "TZ") //--filtering....
.join(df_2007, df_2006("FlightNum") === df_2007("FlightNum"))
.show()where 조건을 filtering하고 broadcast join하는 것을 확인.
broadcast join을 했지만 sort merge join 실행 시간과 큰 차이가 없음
broadcast 직접 설정
df_2006
.where(df_2006("UniqueCarrier") === "TZ") //--filtering....
.hint("broadcast") //--Join Strategy Hints.... ex) spark.table("src").join(spark.table("records").hint("broadcast"), "key").show()
.join(df_2007, df_2006("FlightNum") === df_2007("FlightNum"))
.show()broadcast 실행에 실행 시간이 크게 감소함.
broadcast를 hint로 주지 않으면 데이터를 셔플하고 필터링한 후 데이터의 감소를 확인하고 broadcast하는 반면 broadcast를 hint로 주면 필터링 후 바로 broadcast함.
Warehouse
mysql 5.7에 설치했음.
Spark Warehouse 내부에 영구적인 table 생성
println(spark.conf.get("spark.sql.warehouse.dir")) //--Default : spark-warehouse
spark
.sql("""
SELECT
website,
avg(age) avg_age,
max(id) max_id
FROM
people a
JOIN
projects b
ON a.name = b.manager
WHERE
a.age > 11
GROUP BY
b.website
""")
.write
.option("path", "hdfs://spark-master-01:9000/skybluelee/skybluelee_warehouse_mysql_5.7")
.mode("overwrite") //--Overwrite mode....
.saveAsTable("JoinedPeople") //--saveAsTable(<warehouse_table_name>)....
sql("SELECT * FROM JoinedPeople").show(1000)
hdfs://spark-master-01:9000/skybluelee/skybluelee_warehouse_mysql_5.7
+--------------------+-------+------+
| website|avg_age|max_id|
+--------------------+-------+------+
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 9|
+--------------------+-------+------+hdfs web UI: http://spark-master-01:9870/ 의 /kikang/skybluelee_warehouse_mysql_5.7 에서 확인 default location 못바꿈
spark warehouse table append
sql("SELECT max_id, avg_age, website FROM JoinedPeople") //--컬럼 순서 변경.... 컬럼 이름 유지....
.write
.mode("append") //--Append mode....
.saveAsTable("JoinedPeople") //--saveAsTable(<warehouse_table_name>)....
sql("SELECT * FROM JoinedPeople").show(1000)
+--------------------+-------+------+
| website|avg_age|max_id|
+--------------------+-------+------+
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 9|
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 9|
+--------------------+-------+------+컬럼 이름은 동일하나 컬럼 순서는 바뀌어도 된다.
spark warehouse table insert into
sql("SELECT website as site, avg_age as age, max_id as id FROM JoinedPeople") //--컬럼 순서 유지.... 컬럼 이름 변경....
.write
.insertInto("JoinedPeople") //--insertInto(<warehouse_table_name>)....
sql("SELECT * FROM JoinedPeople").show(1000)
+--------------------+-------+------+
| website|avg_age|max_id|
+--------------------+-------+------+
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 7|
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 7|
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 7|
|http://hive.apach...| 30.0| 2|
|http://kafka.apac...| 19.0| 3|
|http://storm.apac...| 30.0| 7|
+--------------------+-------+------+컬럼의 이름은 바뀌어도 상관 없으나 컬럼의 순서는 동일해야 한다.
append, insert into는 파일을 바꾸지 않고 추가함.
hdfs web UI에서 확인
Partition
df.write
.partitionBy("manager", "name") //--partitionBy
.mode("overwrite") //--Overwrite mode....
.saveAsTable("PartitionTable") //--saveAsTable(<warehouse_table_name>)....
sql("select * from PartitionTable").show(false)
+---+------------+-----------------------+-------+
|id |name |website |manager|
+---+------------+-----------------------+-------+
|1 |Apache Spark|http://spark.apache.org|Michael|
|2 |Apache Hive |http://hive.apache.org |Andy |
|3 |Apache Kafka|http://kafka.apache.org|Justin |
|4 |Apache Flink|http://flink.apache.org|Michael|
|5 |Apache Storm|http://storm.apache.org|Andy |
|6 |Apache Flink|http://flink.apache.org|Michael|
|7 |Apache Storm|http://storm.apache.org|Andy |
|8 |Apache Storm|http://storm.apache.org|Andy |
|9 |Apache Storm|http://storm.apache.org|Andy |
+---+------------+-----------------------+-------+
+---+-----------------------+-------+------------+
|id |website |manager|name |
+---+-----------------------+-------+------------+
|5 |http://storm.apache.org|Andy |Apache Storm|
|7 |http://storm.apache.org|Andy |Apache Storm|
|8 |http://storm.apache.org|Andy |Apache Storm|
|9 |http://storm.apache.org|Andy |Apache Storm|
|4 |http://flink.apache.org|Michael|Apache Flink|
|6 |http://flink.apache.org|Michael|Apache Flink|
|3 |http://kafka.apache.org|Justin |Apache Kafka|
|1 |http://spark.apache.org|Michael|Apache Spark|
|2 |http://hive.apache.org |Andy |Apache Hive |
+---+-----------------------+-------+------------+
partition의 결과는 첫번째 partition -> 두번째 partition의 형태로 이루어짐(경로를 확인)
이와 같이 만든다면 filtering을 할 때 특정 카테고리(partition)의 하위 값만 scan하면 되기 때문에 비용적 이득이 크다.
특정 partition에 대해 filtering한 table을 query로 날리면 metastore_db 내부의 partition table들을 찾아 감.
table 확인
spark.catalog.listTables.show(false)
spark
.read
.table("PartitionTable") //--table(<warehouse_table_name>)....
.show(false)
+--------------+--------+-----------+---------+-----------+
|name |database|description|tableType|isTemporary|
+--------------+--------+-----------+---------+-----------+
|joinedpeople |default |null |MANAGED |false |
|partitiontable|default |null |MANAGED |false |
|people |null |null |TEMPORARY|true |
|projects |null |null |TEMPORARY|true |
+--------------+--------+-----------+---------+-----------+
+---+-----------------------+-------+------------+
|id |website |manager|name |
+---+-----------------------+-------+------------+
|5 |http://storm.apache.org|Andy |Apache Storm|
|7 |http://storm.apache.org|Andy |Apache Storm|
|8 |http://storm.apache.org|Andy |Apache Storm|
|9 |http://storm.apache.org|Andy |Apache Storm|
|4 |http://flink.apache.org|Michael|Apache Flink|
|6 |http://flink.apache.org|Michael|Apache Flink|
|3 |http://kafka.apache.org|Justin |Apache Kafka|
|1 |http://spark.apache.org|Michael|Apache Spark|
|2 |http://hive.apache.org |Andy |Apache Hive |
+---+-----------------------+-------+------------+ people, projects와 같은 임시 table은 같은 세션에서만 확인 가능하나, joinedpeople, partitiontable는 다른 세션에서도 확인 가능하다.
big data partition
//--airline_on_time all....
val df_air_all = spark
.read
.option("header", true)
.option("inferSchema", false)
.csv("hdfs://spark-master-01:9000/skybluelee/data/airline_on_time/*.csv")
df_air_all.printSchema
df_air_all
.write
.partitionBy("Year", "Month", "UniqueCarrier") //--partitionBy
.mode("overwrite") //--Overwrite mode....
.saveAsTable("Airline_On_Time_Partitioned") //--saveAsTable(<warehouse_table_name>)....airline_on_time 전체 file에 대해 수행
val result = df_air_all
.where("Year=2007 and Month=12 and UniqueCarrier='AA'") //--필터링.... (Year, Month, UniqueCarrier)
println(result.count)
result.printSchema
z.show(result)
Took 2 min 6 sec. Last updated by anonymous at April 10 2023, 1:11:19 AM.val result_by_partition = spark
.table("Airline_On_Time_Partitioned")
.where("Year=2007 and Month=12 and UniqueCarrier='AA'") //--필터링.... (Year, Month, UniqueCarrier)
println(result_by_partition.count)
result_by_partition.printSchema
z.show(result_by_partition)
Took 1 sec. Last updated by anonymous at April 10 2023, 1:11:31 AM.같은 query이나 partition 여부에 따라 매우 큰 차이를 보임.
