1. 학습내용
오늘은 어제에 이어 pandas를 이용해 표로 작성한 데이터로 그래프로 결과값을 보여주는 'Matplotlib'라이브러리를 배웠다.
그 전에 어제 배웠던 pandas를 이용한 표를 다시 나타내 보기로 했다.
import pandas as pd
from pandas import Series, DataFrame아래 자료는 미국의 69년도 부터 08년도까지의 성별 출생률을 나타낸 자료이다.
births = pd.read_csv('https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv')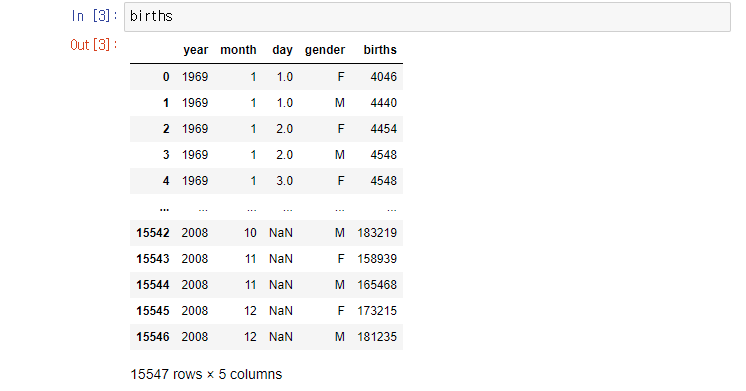
여기서 어제 처럼 하나의 열을 끝에 새로 추가하고 싶다. 바로 십년단위로 년도를 새로 만들거다.
그럴러면 먼저 변수 'births'안에 가져올 자료를 []안에 라벨명을 쓰고, 거기서 십단위를 잘라서단위를 나타내고 싶다. 그럴려면 먼저 10을 나눠서 소수점으로 만들어 버리고 그 다음을 버리고 싶으면 '/'을 두번 입력해 '// 10'이라 쓴다. 그러면 수치가 196으로 되는데 그걸 다시 10을 곱하면 1960이런식으로 찍히게 된다.
births['decade'] = births['year'] // 10 * 10
births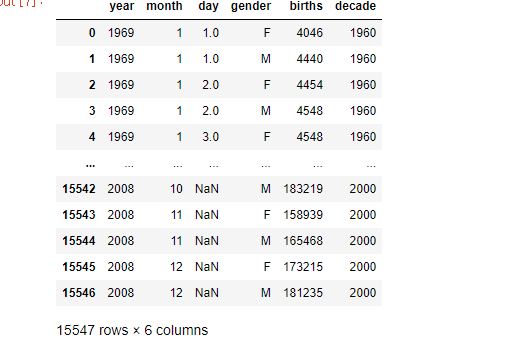
여기서 우리는 성별로 나눠서 년도별로 출생율의 합계를 보고 싶다 하면, 아래와 같이 쓰면된다.
births.pivot_table('births',index='decade',columns='gender',aggfunc='sum')엑셀의 그 '피벗테이블'이라고 생각하면 쉽다. 성별을 새로로 해서 보고 싶다면, columns에 넣으면 되고, 그 반대면 index에 적어주면 된다. 평균을 내고 싶다면, aggfunc는 쓰지 않아도 기본값으로 들어가지만 만약 여기서처럼 합계나 아니면 개수, 표준편차, 분산 등의 산식을 보여주려면
aggfunc= 를 넣어야 한다.
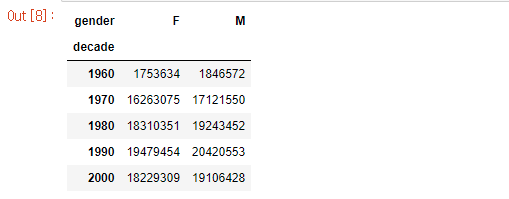
이렇게 나온 표를 그래프로 그려주기 위해선 먼저 'Matplotlib'라이브러리를 불러와야 한다.
import matplotlib.pyplot as plt그런다음 위의 표를 만든다고 적은 명령문을 그대로 적고 끝에 .plot()만 적으면 표가 만들어 진다.
births.pivot_table('births',index='year',columns='gender',aggfunc='sum').plot()이렇게 그래프를 만드는것은 일단 numpy로 배열을 만든 다음 그걸 토대로 그래프를 만든다.
import matplotlib.pyplot as plt
import numpy as np그리고 나서 일단 x를 변수로 아래와 같이 적으면 100개의 수가 든 배열이 완성된다.
x = np.linspace(0,10,100) #시작점 끝점 총계수(0~10까지 죽 늘여서 100개까지 만들라는뜻)그럼 이렇게 나온다.

그런다음 저 수를 x값을 따로, y축을 x값을 sin으로 감싼 값으로 놓고 그래프를 그리면 아래와 같이 나온다. 그런데 그냥 sin(x)라고 하면 안되고 numpy로 감싸야지 나온다.
그리고 그걸 그래프로 그리고 싶다면, plt에 그림을 그리라는 .plot를 쓰고 ()안에, x와 y값을 넣는다.
plt.plot(x, np.sin(x))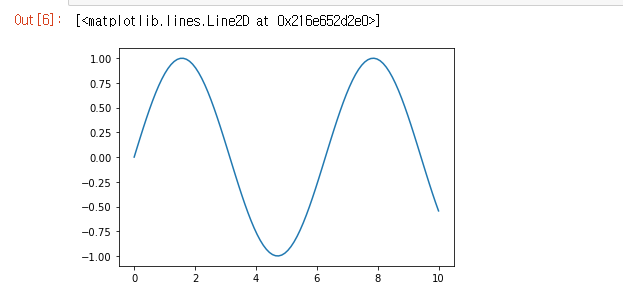
cos으로 하면 또 다르게 나온다.
위의 두 그래프를 합치는 것도 간단하다.
plt.plot(x, np.sin(x))
plt.plot(x, np.cos(x))
plt.plot(x, np.sin(x), '-')
plt.plot(x, np.cos(x), '--')선의 종류를 점선으로도 할수 있다. --가 점선이다.
만약 저 그래프를 따로 파일로 저장하고 싶다면, 아래와 같이 쓰면 가능하다.
fig = plt.figure() #그림판을 하나 준비해 놓으라는 의미
plt.plot(x, np.sin(x), '-') #plt메모리안에 그림이 남아있는것
plt.plot(x, np.cos(x), '--')
fig.savefig('my_figure.png')저장된 이미지를 다시 불러오는데는 아래와 같이 쓰면 된다.
from IPython.display import Image
Image('my_figure.png')아래는 어떤 파일 형식을 지원하는지 종류별로 나온것이다.
fig.canvas.get_supported_filetypes()
이제 위아래로 한 캔퍼스에 두개의 그림이 있게 할거다. 아래의 새로운 그림판을 만든다.
plt.figure()바깥쪽 프래임은 plot 이고 안에 두개 들어갈 판을 subplot이라 한다.
2개를 표현하려면 (2,1,1) <=2갠대 새로로는 하나고 그중 첫번째 그림을 선택한다 라고 쓰면된다.
plt.subplot(2,1,1)
plt.plot(x, np.sin(x))
plt.subplot(2,1,2)
plt.plot(x, np.cos(x))그럼 아래와 같이 나온다.
선의 색도 다르게 줄수 있다.
plt.plot(x, np.sin(x-0), color='blue')
plt.plot(x, np.sin(x-1), color='g') #green의 약자
plt.plot(x, np.sin(x-2), color='0.75')
plt.plot(x, np.sin(x-3), color='#FFDD44')
plt.plot(x, np.sin(x-4), color=(1.0,0.2,0.3))
plt.plot(x, np.sin(x-5), color='chartreuse')
선의 스타일도 각각 다르게 줄수 있다.
plt.plot(x, x+0, linestyle='solid')
plt.plot(x, x+1, linestyle='dashed')
plt.plot(x, x+2, linestyle='dashdot')
plt.plot(x, x+3, linestyle='dotted')
plt.plot(x, x+4, linestyle='-') #solid
plt.plot(x, x+5, linestyle='--') #dashed
plt.plot(x, x+6, linestyle='-.') #dashdot
plt.plot(x, x+7, linestyle=':') #dotted
스타일과 색 둘다 다르게 주고 싶다면 아래와 같이 주면 된다.
plt.plot(x, x+0, '-g')
plt.plot(x, x+1, '--c')
plt.plot(x, x+2, '-.k')
plt.plot(x, x+3, ':r')
만약 x축 범위를 반대로 쓰고 싶다면 아래와 같이 적고, .ylim으로 쓴다.
plt.plot(x, np.sin(x))
plt.xlim(10, 0) #x축 범위를 적어줌
plt.ylim(1.2, -1.2) #y축 범위
x축과 y축을 같이 범위의 폭을 적어주고 싶다면 아래와 같이 적는다.
plt.plot(x, np.sin(x))
plt.axis([1,11,-1.5,1.5])
그냥 수치를 적지 않고 폭을 좀게 출력하고 싶다면 'tight'라고 적으면 된다.
plt.plot(x, np.sin(x))
plt.axis('tight')
양 축을 똑같은 폭으로 맞춰서 하고 싶다면 'equal'로 하면된다.
plt.plot(x, np.sin(x))
plt.axis('equal') #양 축이 똑같은 폭으로 맞춰짐
그래프에 제목과 각 축의 라벨을 나타내려면 아래와 같이 하면 된다.
plt.plot(x, np.sin(x))
plt.title('A Sine Curve')
plt.xlabel('x')
plt.ylabel('sin(x)')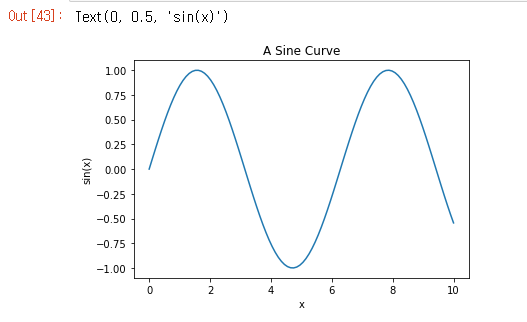
만약 범주를 넣고 싶다면 그래프를 그리고, label명을 적어준 다음, plt.legend()라고 쓰면 된다.
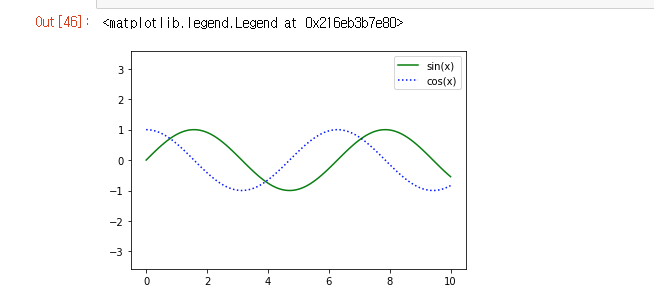
2. 어려웠던 점 및 해결 방안
아래의 코드가 이해가 잘 안되었다. 데이터를 점처럼 분포되어 있는 '산점도'를 나타내는 그래프중 두번째가 잘 이해가 안되었다.
rng = np.random.RandomState(0) #랜덤값을 기본값에서 만들어줌. 동일한 순서로 섞이게끔함.
for marker in ['o',',',',','x','+','v','^','<','>','s','d']: #[]는 점이 찍히는 스타일
plt.plot(rng.rand(5), rng.rand(5), marker, #점을 marker라고 부름. 5안에서 랜덤으로 값이 잡히겠끔함. 각각 x,y값 둘다 동일하게 줌.
label='marker={0}'.format(marker))
plt.legend() #그래프 스타일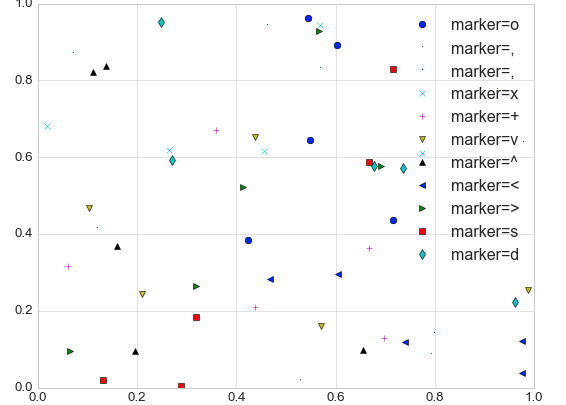
다시 동영상을 보니 이해가 갔다. 이해한 것은 주석을 달아주었다.
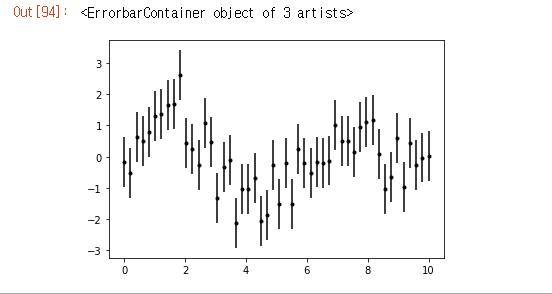
그리고 오차 표현이 있다.
#errorbar
x = np.linspace(0,10,50)
dy = 0.8 #오차값
y = np.sin(x) + dy * np.random.randn(50)
plt.errorbar(x, y, yerr=dy, fmt='.k') #yerr는 새로축으로 보고싶을때 새로로 출력 오차범위 만큼만 출력
#fmt는 그래프 스타일이다. '.'은 점으로 나타내겠다는 것'.k'는 점으로 찍고 검은색.마찬가지로 동영상을 보고 주석을 새로 달았다.
그 다음은 머신러닝 프레임워크중 sklearn을 배웠다. 불러온 데이터를 이 프레임워크을 이용해 머신러닝으로 배우게 해서 값을 도출하는것을 해보았다.
그 중에 아래가 이해가 되질 않았다.
train_input, test_input, train_label, test_label = train_test_split(iris_dataset['data'], iris_dataset['target'],
test_size=0.25, random_state=42)다시 동영상을 보니까 데이터를 테스트용과 학습용으로 나누어 학습이 잘되었는지 테스트하는걸로 보통은 나누어 둘을 비교해 제일 비슷하면 데이터가 비교적 정확하다고 하셨다.
데이터를 쪼개기 위해 새로 패키지를 import해야 했다.
from sklearn.model_selection import train_test_split나누는 걸 4개로 결론적으로 나눠진다 하셨는데, 두개 x,y를 한번 쪼개기 때문에 4개로 나눠지는거라고 하셨다 이걸 이해를 못해서 동영상을 다시봤다.
그래서 저 import한 'train_~'을 입력하고, 나눌 x에 해당하는 데이터와 y축에 해당하는 target을 적어준다.
train_test_split(iris_dataset['data'], iris_dataset['target'],
test_size=0.25, random_state=42) #0.25는 나누는 비율. 75%는 학습용, 25%는 test용으로 나뉜다는 말. 보통 0.4, 0.2, 0.25에서 많이 결정 그런데 우리는 한쪽에 데이터가 쏠리면 테스트용의 결과값이 제대로 나오지 않을 수 있으므로 데이터를 랜덤으로 섞어야 해서 random_state를 적어준다. 얼마나섞는지 강도를 대충 정해줌. 그리고 4개로 갈라진것을 각각 할당하기 위한 데이터 명을 임의로 적어준다.
각각 앞의 두개는 'data' 뒤의 두개는 'target'용 이다.
다음 분류 알고리즘 중에 최근접 알고리즘이란게 있는데 각각 분포된 두종류의 데이타 중에 어느 새로운 데이타가 애매한 쪽에 있으면 가장 가까운 종류의 데이터에 편입해준다.
from sklearn.neighbors import KNeighborsClassifier
그런다음 알고리즘을 메모리에 가져온다. 알고리즘을 어떻게 가지고 오는지 알려면 관련 cheatsheet를 참고한다.
knn = KNeighborsClassifier(n_neighbors=3) #()안에 근접한 것 중 몇개를 기준으로 구별할것인지 적어준다. 그런다음 .fit이란 명령을 주면 바로 학습을 한다.
()안에는 학습에 필요한 train input을 주고 타겟값을 준다.
knn.fit(train_input, train_label)그런다음 학습이 끝났으면 물어보면 답을 알려준다.
예측값을 한번 변수로 선언하고 print해본다.
predict_label = knn.predict(test_input)
print(predict_label) #예측값
print(test_label) #원래 test 값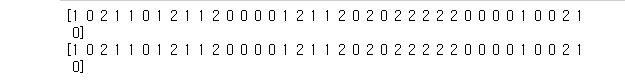
둘이 언뜻 봐도 값이 같다. 데이터가 너무 과접합되어있다는 말이다. 저렇게 100같으면 다른 데이터를 넣으면 값이 안나올수도 있으니 좋은 모델은 아니란 뜻이다.
둘의 정확도를 수치적으로 나타내기 위해 numpy이용해 계산을 해보기로 한다.
import numpy as np
print(f'test accuracy: {np.mean(predict_label == test_label)}')
#==로 서로 일치하는가에 대한 평균값(mean)을 구한다는 의미
그럼 저렇게 100로의 평균값이 나온다.
3. 학습소감
나머지는 그럭저럭 코드를 보고 의미를 비슷하게 알 수 있었는데, 오늘 마지막에 배운 머신러닝 모듈을 만드는 것에서는 좀 이해가 어려웠다.
그래도 처음으로 만든 모듈이라는 점이 새삼 신기했다. 점점 복습을 하지 않으면 이해가 어려운 과정까지 들어가는 기분이였다.
다음주는 더 코딩을 많이 하는걸로 하신다고 하는데 더 잘할 수 있었으면 좋겠다.
