1. 학습내용
오늘은 Numpy와 Pandas를 해보았다.
Numpy
NumPy(Numerical Python)는 파이썬에서 과학적 계산을 위한 핵심 라이브러리이다. NumPy는 다차원 배열 객체와 배열과 함께 작동하는 도구들을 제공한다. 하지만 NumPy 자체로는 고수준의 데이터 분석 기능을 제공하지 않기 때문에 NumPy 배열과 배열 기반 컴퓨팅의 이해를 통해 pandas와 같은 도구를 좀 더 효율적으로 사용하는 것이 필요하다.
또 배열이 유연하고, 성능이 좋으며, n차원 데이터까지 잘 구축되는 장점이 있다.
그래서 이걸 배워보기 위해 index값과 values 값을 넣어볼거다.
일단
array 함수를 사용하여 배열 생성해 보자.
import numpy as np처음에 numpy를 호출해 가져와서 np라고 짧게 이름 붙인다.
그런다음 간단하게 1행의 4열짜리 list를 만들고 숫자를 넣은 함수를 선언한다.
# ndarry를 생성
arr = np.array([1,2,3,4])그런다음 print문으로 확인해보면 이렇게 출력된다.
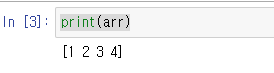
근데 저런식으로 출력되면 그냥 숫자의 배열인지, 숫자처럼 보이는 데이터 값인지 모른다.
그걸 알고 싶다면, 아래 처럼 입력해서 확인할 수 있다.
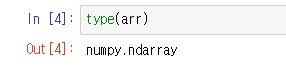
그럼 일반 배열은 아니고, numpy배열로 만들어진 것이라는 것을 알수 있다.
다음은 배열이 있으면 원래 배열안에 있던 값을 '0'으로 전부 바꾸는 코드를 해보았다.
np.zeros((3,3))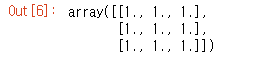
행과 열이 각각 3*3인 배열에 'zero'으로 값을 초기화 하라는 말이다.
만약 '1'로 하고 싶다면 대신 'ones'이라고 넣으면 된다.
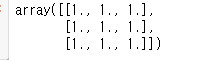
자세히 보면 숫자 뒤에 마침표처럼 점이 찍혀 있는데, 저게 찍혀 있으면 '1.'은 숫자 정수 '1'의 값이란 소리다.
만약에 숫자 값을 넣지 않고, 그냥 초기화 하고 싶다면, empty로 입력하면 되는데, 그러면 이상한 숫자값이 나온다.

이 숫자값은 저 공간을 사용했던 메모리 값이 나오는 것이다.
항상 메모리는 컴퓨터가 꺼진다고 해서 완전히 삭제되는것이 아니라 값이 남아있다가 재부팅되었을때 빠르게 실행된다고 한다.
그리고 일일히, 1,2,3..이런식으로 연속으로 된 수를 하나하나 입력할 필요 없이 '10'만 입력하면 순서대로 0부터 시작해서 9까지의 값이 들어간 배열이 만들어진다.

다음은 배열의 모양, 차수, 데이터 타입을 확인해 보는 걸 배워보았다.
아까처럼 변수를 아래와 같이 선언한다.
arr = np.array([[1,2,3],[4,5,6]])그럼 아래와 같이 출력된다. (참고로 print를 안써주고 그냥 입력해도 출력되지만 파이썬 프로그램 위에서는 에러가 뜰 확률이 높다)
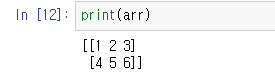
지금은 배열이 짧지만 만약 긴 배열의 모양을 확인하고 싶다면, 그러니까 행과 열의 갯수가 궁금하다면 아래와 같이 입력한다.
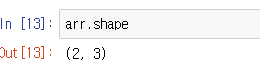
그럼 배열안에 들어가는 저 데이터 타입은 뭔가 궁금하면 변수.dtype이라고 입력하면 된다.
그럼 프로그램별로, 쓰고있는 컴퓨터의 종류나 운영체제 등등으로 결과값이 64비트나 32비트 등으로 다르게 나오는데 웬만하면 32이상으로는 대부분의 값들이 들어갈 수 있다고 한다.
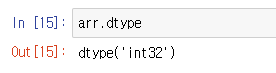
이번에는 데이터 타입을 float형 즉, 실수형으로 해보기로 했다.
똑같이 변수를 선언한다.
arr_float = arr.astype(np.float64) #.astype는 데이터 타입을 바꾼다는 명령문.그런다음 프린트를 하면 아래와 같이 나온다.

점이 붙어있으면 실수형이란 뜻이다. (1.0,2.0이런식..)
그런다음 데이터 타입을 확인 하는 코드를 또 입력하면 float64로 바뀌었다는 것을 알수 있다.

그런데 위에 실수형으로 바꾼건 arr이란 데이터 타입을 아예 바꾼게 아니라 바뀐 값을 새로 입력한 변수로 리턴해준다는 의미이다.
그래서 arr이란 변수는 그대로 살아있다. 증거로 그냥 arr의 데이터 타입이 뭔지 입력해보면 아까와 똑같이 나오는걸 알수 있을것이다.
그 다음은 두가지 이상의 배열을 연산자를 이용해 계산값을 나타내는 것을 해보았다.
arr1 = np.array([[1,2],[3,4]])
arr2 = np.array([[5,6],[7,8]])저렇게 함수 선언을 한다음, 아래와 같이 더하거나 곱하면 안의 값이 배열순에 겹쳐지는 두개의 값끼리 계산한 값이 나온다.

arr3 = np.add(arr1, arr2) #는 위의 +로 한 것과 같은 값이 나온다.
arr3 = np.multiply(arr1, arr2) #는 위의 *를 한 것과 같은 값이 나온다.Numpy 배열의 연산은 연산자 (+,-,*,/)나 함수(add, subtract, multiply, divide)로 가능하다.
이번에는 ndarray 배열 슬라이싱을 해보기로 했다.
슬라이싱은 큰 덩어리를 내가 원하는 만큼 잘라주는 것으로 아래 변수 값을 슬라이싱 해보았다.
# 배열 슬라이싱
arr = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr_1 = arr[:2,1:3] #3가지 열중 위에서 부터 2열까지 자르고, 그 잘린 결과에서 첫번째 순서의 행부터 3번째까지 잘라낸다는 의미다. :자체가 슬라이스의 의미를 가진다.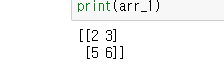
만약 변수를 선언한 값 전체를 슬라이스를 입력해 보여줄때가 있는데 왜 굳이 슬라이스해야 하나 싶지만 그게 필요한 때가 있다고 하셨다.
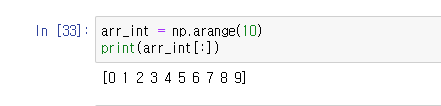
이번엔 변수 중에 어느 값보다 큰것이면 출력되는 것을 해보기로 했다.
먼저 새로 변수를 선언해 리스트를 만들고, 그 선언한 리스트 변수가 3보다 큰것에 해당하는 변수를 추가로 입력했다.
arr = np.array([[1,2,3,],[4,5,6,]])
idx = arr > 3
print(idx)
값이 맞으면 'ture' 틀리면 'false'로 출력되게 했다. 그런데 저걸 참, 거짓이 아니라 참에 해당하는 값만 출력되게 하고 싶으면 아래와 같이 입력한다.
print(arr[idx])그럼 해당 값인 [4 5 6] 이런식으로 출력된다.
이번엔 csv파일을 불러와서 출력해보고, 값을 계산하거나 하는 것을 해보았다.
redwine = np.loadtxt(fname='samples/winequality-red.csv',
delimiter=';', #파일상에서 값들을 분리한 마크를 입력한다.
skiprows=1) #1열을 제외하고 보여준다.해서 print하면 아래처럼 나온다.
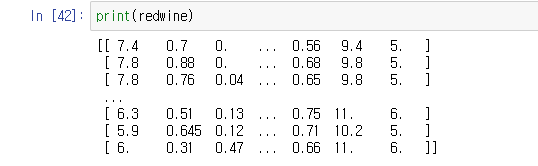
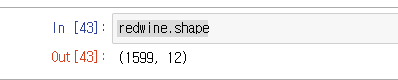
이 자료의 전체 값의 행 개수와 열의 개수를 알고 싶다면, 아래처럼 입력한다.
전체 핪과 평균값을 알고 싶다면 .sum과 .mean을 입력하면 값이 나온다.
그런데 우리는 특정 값들의 평균을 알고 싶다. 그렇다면 축의 개념을 이해해야 한다.
입력은 평균 입력과 동일한데 대신 축이라는 의미로 ()안에 'axis'라고 입력한다.
가로와 세로 축 중에 가로를 0 세로를 1이라고 한다고. 그래서 가로 축인 0을 쓰면 햇갈리면 안되는게 각 열의 대한것을 나타낸다. 그러므로 각 열의 평균값을 구할려면 0을 써야 한다.
print(redwine.mean(axis=0)) 그럼 각 열마다 또는 각 행마다 평균값 구하는 법을 알았으니 이제는 첫번째 열의 평균값을 구하고자 한다.
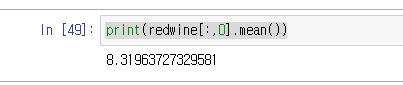
그럼 위에서 배운 슬라이싱을 이용해 구한다. 아까 전체 값을 나타낼때 슬라이싱을 이용한다는게 여기서의 예처럼 이용할 수 있다.
print(redwine[:,0].mean()) #:는 전체 값중 세로축만 모든 값이 선택되었다는 말. 그리고 뒤의 0은 그 자른 세로 축의 첫번째 배열을 선택한다는 의미다.그럼 이렇게 나온다.
그다음 판다스를 배웠다.
Pandas
자료구조: Series와 Dataframe
Pandas에서 제공하는 데이터 자료구조는 Series와 Dataframe 두가지가 존재하는데 Series는 시계열과 유사한 데이터로서 index와 value가 존재하고 Dataframe은 딕셔너리데이터를 매트릭스 형태로 만들어 준 것 같은 frame을 가지고 있다. 이런 데이터 구조를 통해 시계열, 비시계열 데이터를 통합하여 다룰 수 있다.
그냥 메모리에 있는 엑셀이라고 생각하라 하셨다. (참고로 시계열(時系列, 영어: time series)은 일정 시간 간격으로 배치된 데이터들의 수열을 말한다)

2. 어려웠던 점 및 해결 방안
pandas 도 입력방식이 기본적으로 Numpy와 비슷했다. 단지 표형테의 데이타베이스를 표형태로 깔끔하게 잘 보여주고 그 표를 내가 편집할 수 있다는 게 달랐다.
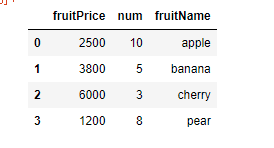
이런식으로 보여주는데 어떻게 보여줄수 있는지 이해가 잘 안됐는데, 처음에 import한 DataFrame때문에 그렇게 볼수 있었던 것이다.
또 신기한건 저렇게 만들어진 표에 새로운 열을 (데이터) 추가하고 싶으면 처음처럼 아래와 같이 입력해야 하는 줄 알았다.
fruitData = {'fruitName':['apple','banana','cherry','pear'],
'fruitPrice':[2500,3800,6000,1200],
'num':[10,5,3,8]
}아님 처음에 배웠던 series방식처럼 아래와 같이 입력한다거나.
fruitData = {'apple':2500, 'banana':3800, 'pear':1200, 'cherry':6000}
fruit = Series(fruitData)그런데 그냥 추가할 열의 이름을 []안에 적고 = 값 을 입력하면 추가가 된다! (기존의 데이터프레임 변수[]다음에)
fruitFrame['Year'] = 2016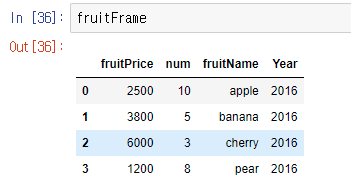
만약 전부 2016값이 아닌 각자 다른 값을 넣고 싶다면 아래와 같이 하면 된다.
먼저 변수를 선언해 주는데, 각 박스에 들어갈 값을 'series([])'에 넣고, 해당 하는 index(열)의 순서를 입력한다. 여기서는 예제로 두번째순서를 비우고 3가지 값만 넣어볼거다.
variable = Series([4,2,1],index=[0,2,3])
저렇게 해당 값이 출력되는지 확인하고, 새로 값을 넣을 열의 이름을 'stock'이라 짓고 거기에 해당 값을(변수명)넣는다.
fruitFrame['stock'] = variable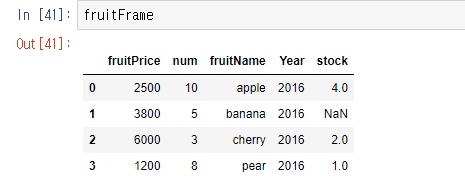
그럼 위와 같이 한줄이 추가되고 값이 다 다르게 출력된다. 두번째 순서인 칸은 공란으로 해서.
또 이번엔 복습하다 보니 오름차순은 .sort_values이고 이걸 반대로 하는것을 .sort_values(ascending=False)이라는 것을 또 알게 되었다.
이해가 안가는 게 있어서 동영상으로 돌려보니까. 서로 영향을 주는 데이터가 값이 높으면 높을수록 서로 영향이 크다는 상관계수는 이해했다. 값도 다시 보니 .corr라고 치면 된다고.
그런데 그걸 수많은 값들의 이름을 그룹으로 묶어 그룹별로 보여주게 하는 명령어 중에 이게 뭔가 싶어서 다시 동영상을 봤다.
german_grouped = german_sample['Credit Amount'].groupby(
german_sample['Type of apartment'])
german_grouped여기서 .groupby가 뭔지 몰랐다. 그룹을 짓는다는 것 까진 이해했는데 뭘 위해서 그룹을 짓는지를 몰라서 보니까 여기서 우리가 보고싶은게 아파트먼트 타입별(여기서3가지가 있는데)로 'credit amount'를 보고싶다는 것이였다.
그래서 두가지 데이터 중 한가지 기준이 되는 데이터를 .groupby뒤에 쓰고 기준과 묶을 것을 앞에 적는것이였다.
그런데 저렇게 그룹만 지으면 그룹을 지었다는 메시지만 뜨고 값이 안뜬다. 그룹으로 그래서 뭘하고 싶은지 컴퓨터가 모르기 때문이다.
우리는 여기서 평균값을 보기로 했으니 똑같이 변수.mean()해서 출력하면 아래와 같이 각각의 그룹별로 평균값이 나온다.

3. 학습소감
두가지 라이브러리를 배워보았다. 복습하니 천천히 이제 코드를 보면 무슨 뜻인지 대충 읽을 수 있게 되었다. 아직까지는 망망대해를 해쳐가는 기분이지만 둥근 튜브라도 일단 붙잡은 기분이다.
이번주가 끝나가는데 내일은 pandas 남은 내용을 마저 배우고 새로운 것을 배운다. 조금더 나아져 갔으면 하는 바람이다.
