
📄 목차
- 데이터 병합과 정리
- 병합 (.merge())
- index 지정 (.set_index())
- 상관 관계 확인 (.corr())
- matplotlib
- 경향 확인
- numpy 활용
- 경향 외 데이터
1. 데이터 병합과 정리
병합 (.merge())
- merge에 대해
- pandas를 pd로 import 했을 때, 두 데이터 프레임 병합 방법
- pd.merge(데이터1, 데이터2, on="column name")
>> 열 이름 비교하여 동일한 데이터만 병합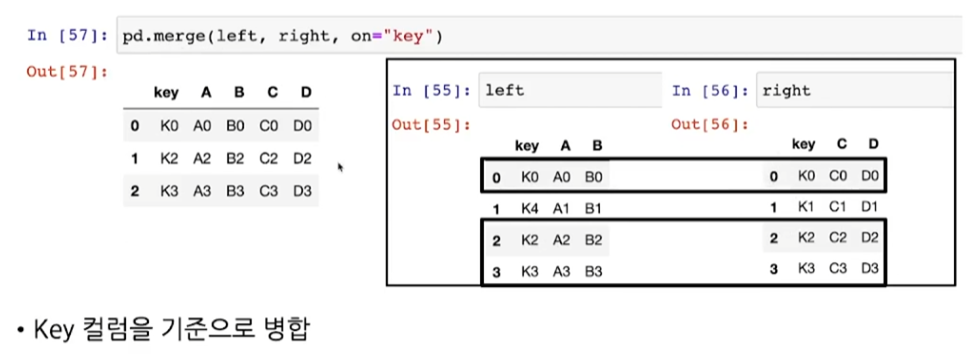
- pd.merge(데이터1, 데이터2, how="", on="column name")
- how="데이터1" >> 데이터1의 열 이름 기준으로 병합 (존재하지 않는 데이터는 NaN 표시)
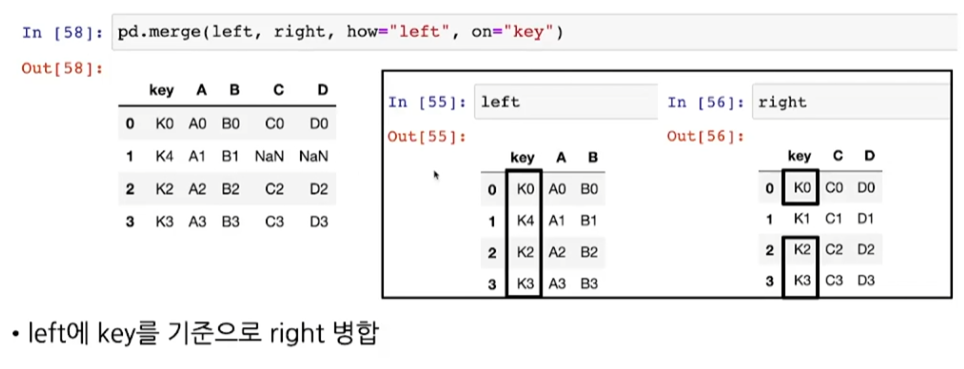
- 데이터2에 넣게 되면 반대로 작용
- how="outer" >> 데이터1과 데이터2 모두 병합
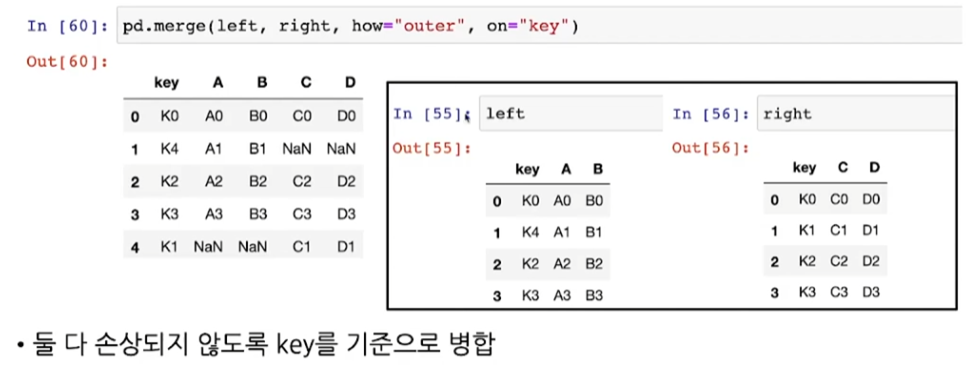
- how="inner" >> 교집합만 병합
- how="데이터1" >> 데이터1의 열 이름 기준으로 병합 (존재하지 않는 데이터는 NaN 표시)
- 이외에 .concat(), .join() 등의 방법이 있음
index 지정 (.set_index())
- 데이터.set_index("column name", inplace=True)
- 해당 열을 인덱스로 지정하게 됨.
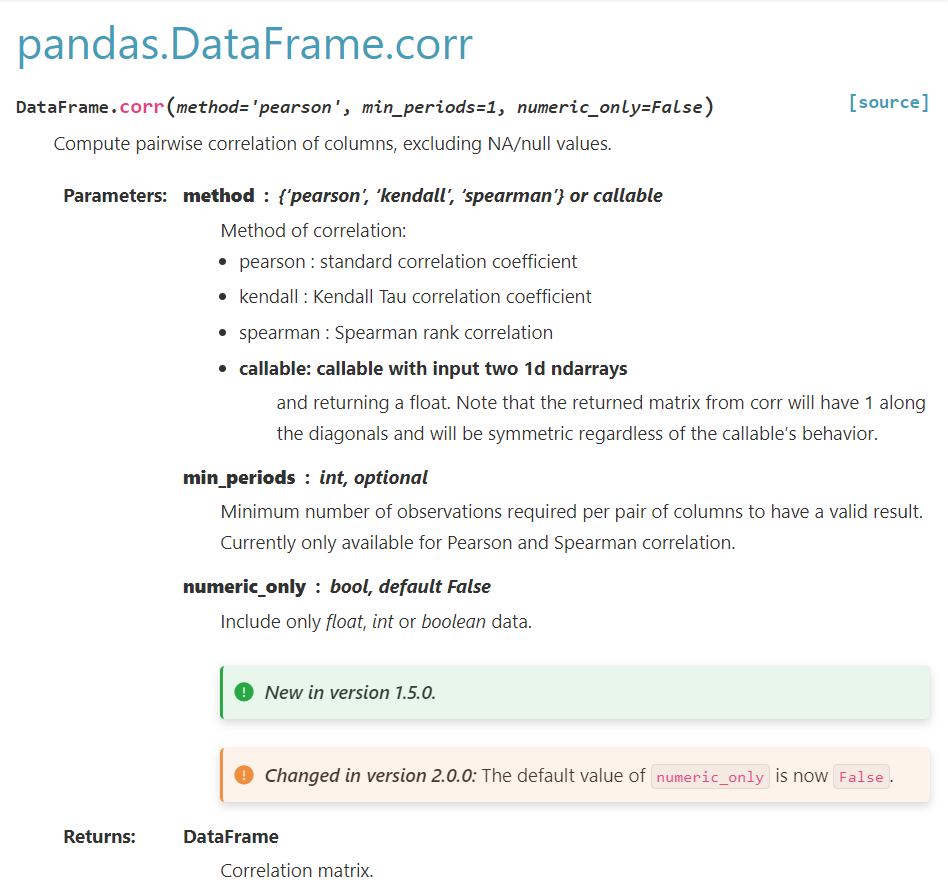
상관관계 확인 (.corr())
-
데이터.corr() >> 각 열의 내용을 서로 대입하여 상관계수를 출력함
- 0.2 이하: 상관 관계가 없거나 무시해도 좋은 수준
- 0.4 이하: 약한 상관관계
- 0.6 이상: 강한 상관관계
2. matplotlib
- matplotlib의 다양한 그래프
- 그래프 관련된 다양한 기능들

3. 경향 확인
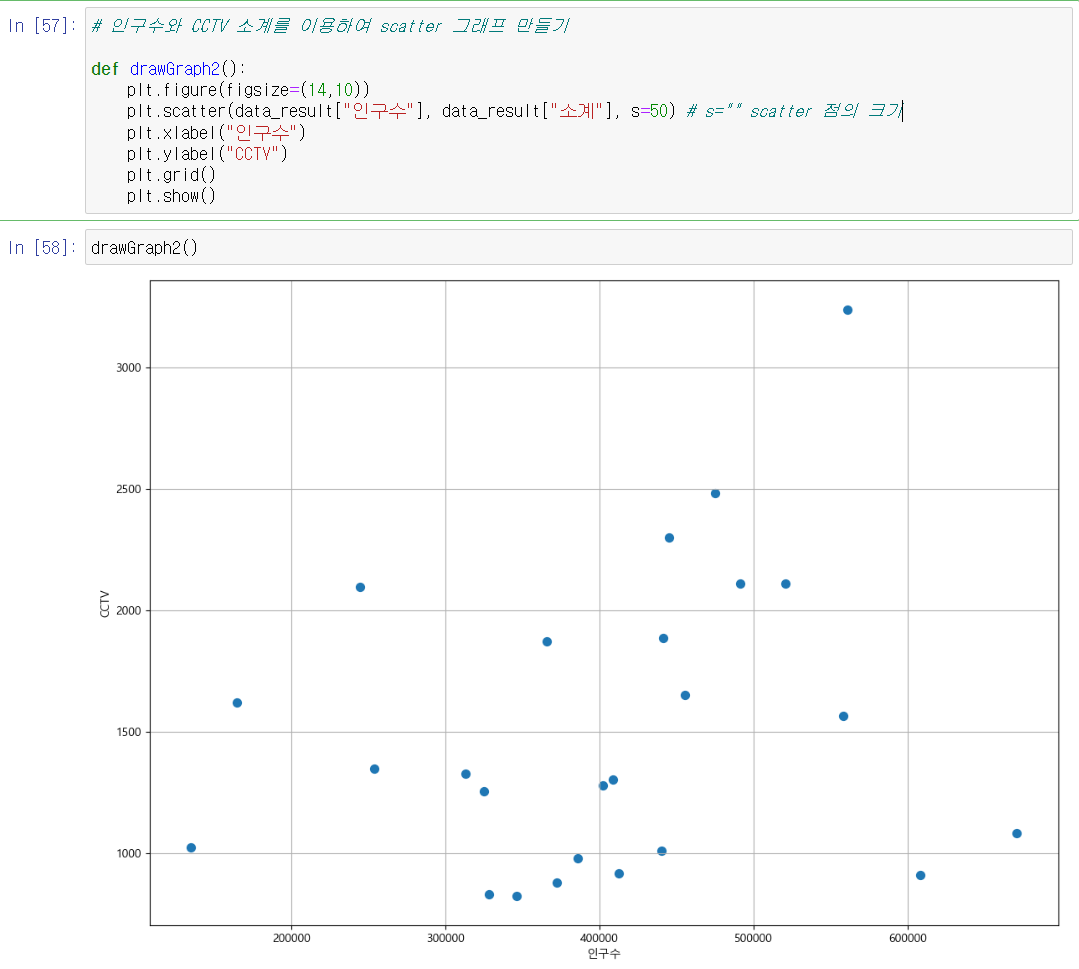
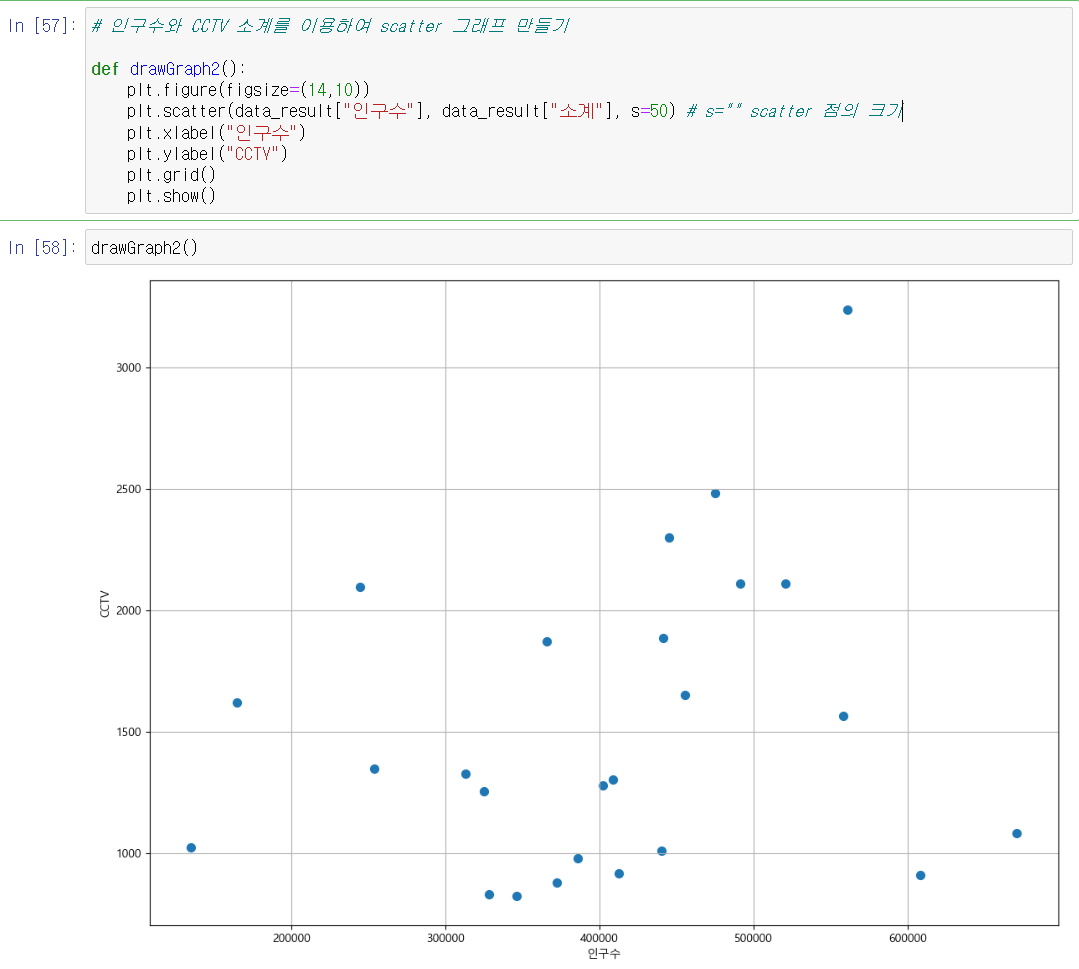
- 자치구별 인구수와 자치구별 cctv 소계를 이용하여 분산 그래프 만들었음.
numpy 활용
- numpy의 함수를 이용해 1차 직선을 만들어 비교
- np.polyfit
- 직선을 구성하기 위한 계수 계산
- np.poly1d
- polyfit으로 찾은 계수로 python에서 사용할 함수로 만들어 줌.
- 위에서 만든 값을 그래프를 만들 때 추가하면 됨
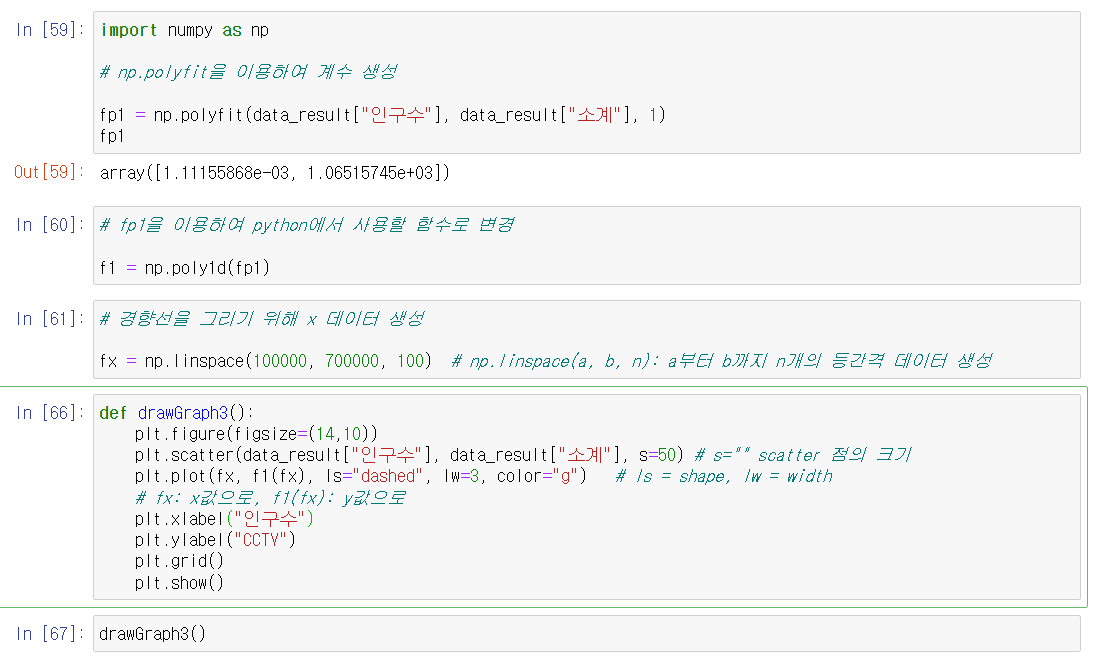
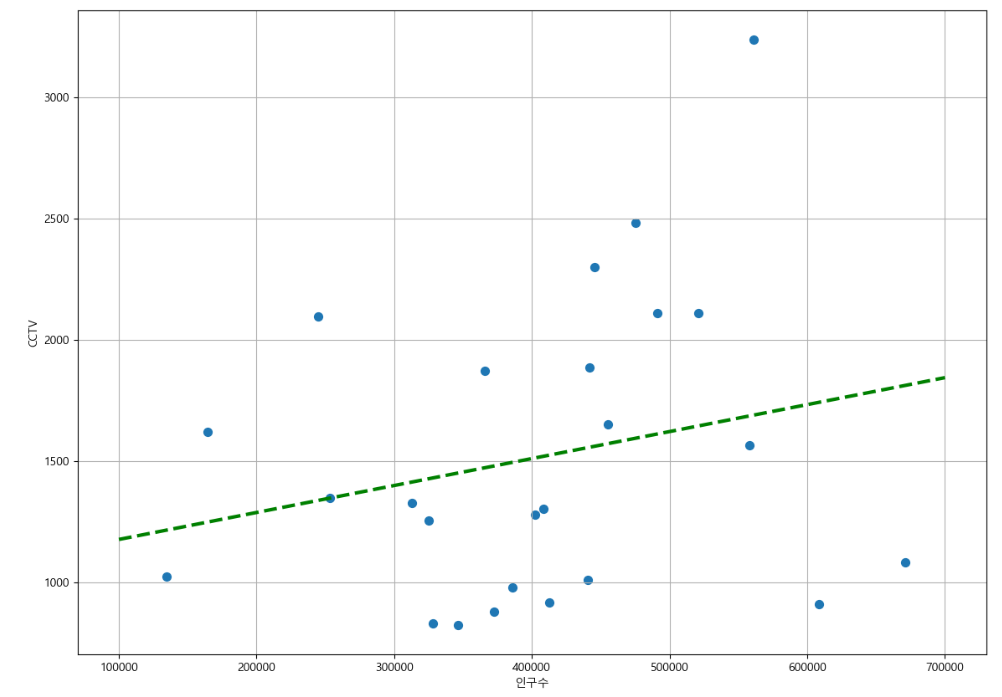
- np.polyfit을 이용하여 계수 생성 (fp1)
- np.poly1d를 이용하여 함수 생성 (f1)
- np.linspace를 이용하여 해당 함수들을 넣을 예시들을 일정 간격으로 생성 (fx)
- (3)은 x축 값에, 2(3)은 y축 값에 넣어 경향 선 생성
- f1으로 이미 함수는 만들어졌고 이를 보이기 위해서는 일정 간격으로 x값을 대입하여 선을 그려야 함.
- 수학과 동일함 y = f(x)
- 여기서 x = fx
- 함수는 f1
- y값은 f1(fx)임
- np.polyfit
4. 경향 외 데이터
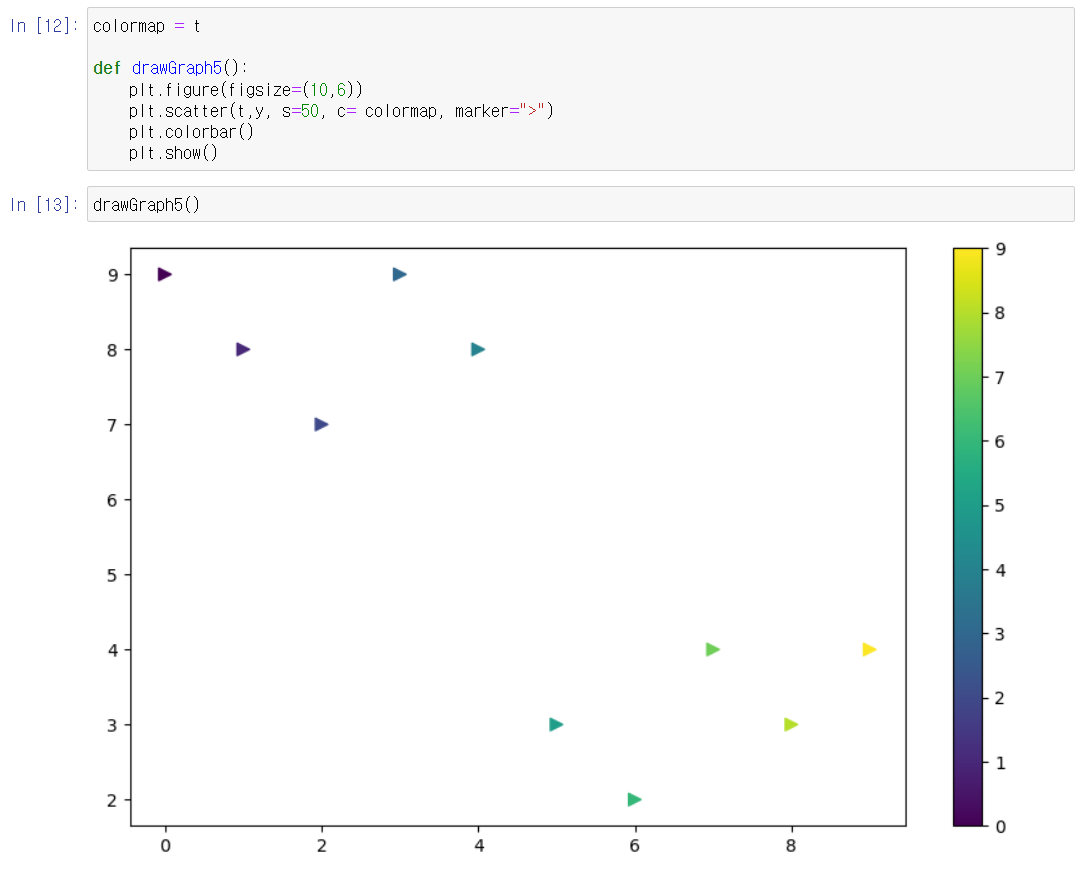
- colormap을 새로 만듦 (데이터 표시 색깔로 한눈에 볼 수 있도록)
- colormap percentile에 대해 확인 필요
- colormap
- 오차 값 데이터 열을 하나 만들어줌
- data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])
- f1(x) 는 x 인구에 맞는 평균 cctv 갯수임
- data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])
- 이후 오차별 오름차순, 내림차순을 만들어줌
- 이 오름차순, 내림차순 각각의 5개를 txt 표현해주면 됨
- plt.text(표시될 x축 위치, 표시될 y축 위치, 표시할 내용, 폰트 사이즈)
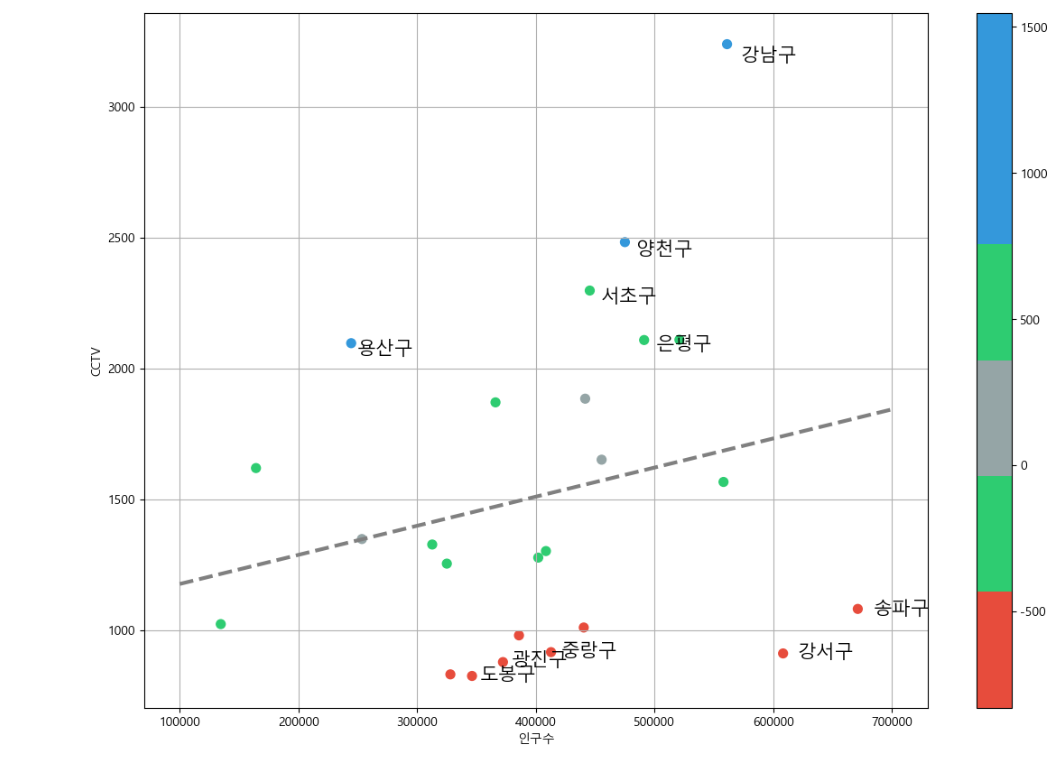
- 이렇게 그래프화까지 완료된 데이터는 따로 to_csv()함수 이용하여 저장


새싹 데이터 분석가 https://github.com/KulangK