
📄 목차
- Pandas
- Pandas basic
- .info()
- .describe()
- .sort_values()
- 데이터변수 [ ]
- .loc[ ]
- .iloc[ ]
- 추가적으로 다양한 기능
- Pandas DataFrame 구조
- Pandas로 엑셀 및 텍스트 파일 읽기
- Pandas basic
- Jupyter Notebook 실습
Pandas
- Python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 '모듈'
- 단일 프로세스에서 최대 효율을 보임
- 코딩/응용 가능한 엑셀
- 통상 pd로 import (수치해석적 함수가 많은 numpy는 통상 np로 import)
- Pandas Series Documentation
- 이외에 해당 웹페이지의 검색을 이용하여 사용하고자 하는 함수와 기능, 메서드 등을 참고할 것
Pandas basic
- 기본 데이터형은 series (index와 value로 이루어져 있음)

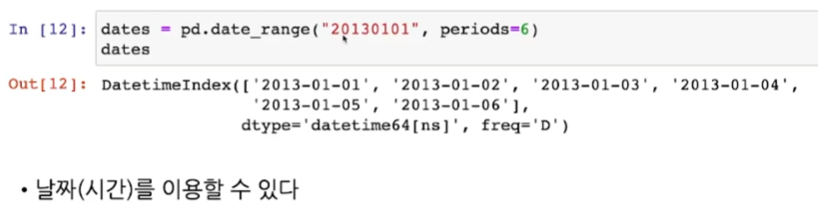
- 가장 많이 사용되는 데이터형은 DataFrame
- 밑의 이미지에서는 np.random.randn(행, 열)을 이용하여 난수를 생성하였음

- 밑의 이미지에서는 np.random.randn(행, 열)을 이용하여 난수를 생성하였음
- .head() >> 위에서부터 보거나, 처음 5개 행을 보고 싶을때
- .tail() >> 밑에서부터 보거나, 마지막 5개 행을 보고 싶을때
- .columns / .index / .values >> 열 이름, 인덱스, 값 조회할 때 쓰는 것
.info()
- DataFrame의 기본 정보 확인
- index, column, Dtype, memory usage...
.describe()
- DataFrame의 통계적 기본 정보 확인
- 열별 갯수 (count)
- 평균 (mean)
- 표준 편차 (std)
- 최소, 4분위 값들, 최대
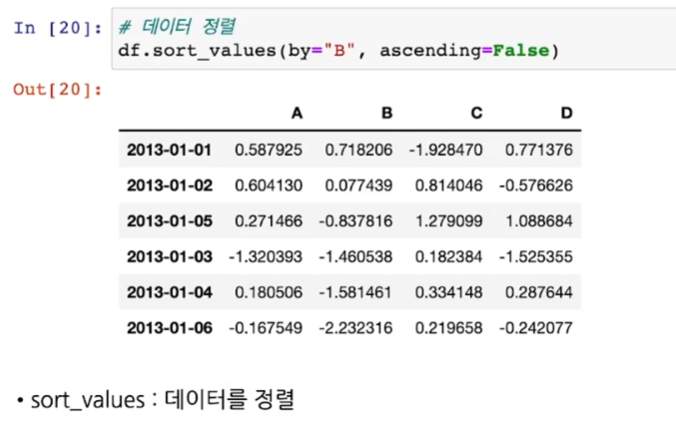
.sort_values()
- .sort_values(by = "열", ascending=False) >> 해당 열 내림차순 (True면 오름차순)
데이터변수 [ ]
- 변수["열"] >> 해당 열 정보만 읽어옴 (index와 value)
- ["0:3"] >> 0, 1, 2 index 행 정보 읽어옴 (인덱스 이름도 사용가능) - 현재 파이썬 이용하고 있음을 염두
.loc[ ]
- .loc[ : , ["A", "B"] ] >> A와 B 열의 모든 행 값 불러옴
- 보편적인 slice 기능
- colon 없이 index 이름 1개 쓰면 해당 1개의 행 값만 불러오게 됨.
.iloc[ ]
- .iloc[ ] >> 넘버링만으로 접근하는 방법
- .iloc[3]: index 2 행만
- .iloc[3:5, 0:2]: index 3, 4행이면서 0, 1열 정보
- .iloc[ [1, 2, 4], [0, 2] ]: index 1, 2, 4행이면서 0, 2열 정보
추가적으로 다양한 기능
- 데이터변수[condition]으로 사용되는 것이 일반적임
- df [ df [ "A" ] > 0 ] : A열의 0을 넘는 값의 전체 행들 출력
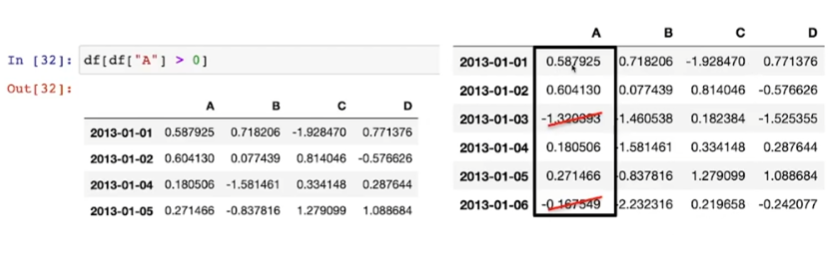
- df[df > 0] : 전체 데이터에서 0을 넘는 값들만 출력
- df [ df [ "A" ] > 0 ] : A열의 0을 넘는 값의 전체 행들 출력
- df [ "열 이름" ] = [ "넣을 값", ... ]
- 새로운 값 할당
- df [ "열 이름" ] .isin( [ "찾을 값", ... ] )
- 찾을 값이 존재하는 행은 True, 없는 행은 False 반환
- 위 코드를 df[ ] 안에 넣게 되면 True인 행 전체를 반환

- del df [ "열 이름" ] : 특정 열 제거
- .apply(np.cumsum) : 각 열 누적합 반환
Pandas DataFrame 구조
-
가장 왼쪽 열 = Index
-
가장 위 행 = column Name
-
각 열 = column
-
각 칸의 content = value
원하는 이름 column name column name column name index 0 value value value value index 1 value value value value index 2 value value value value index 3 value value value value
Pandas로 엑셀 및 텍스트 파일 읽기
CSV 파일
- 변수 = pandas.read_csv("파일 위치", encoding="utf-8")
변수.head()- pandas는 모듈이므로, 모듈 내의 read_csv()가 명령임
- encoding은 한글이 아닐 경우 설정해줄 필요 없음
엑셀 파일
- 변수 = pandas.read_excel("파일 위치")
변수.head()- pandas는 셀 병합 기능이 없기 때문에 엑셀에 저장된 것을 불러오면 이상한 출력이 될 수도 있음
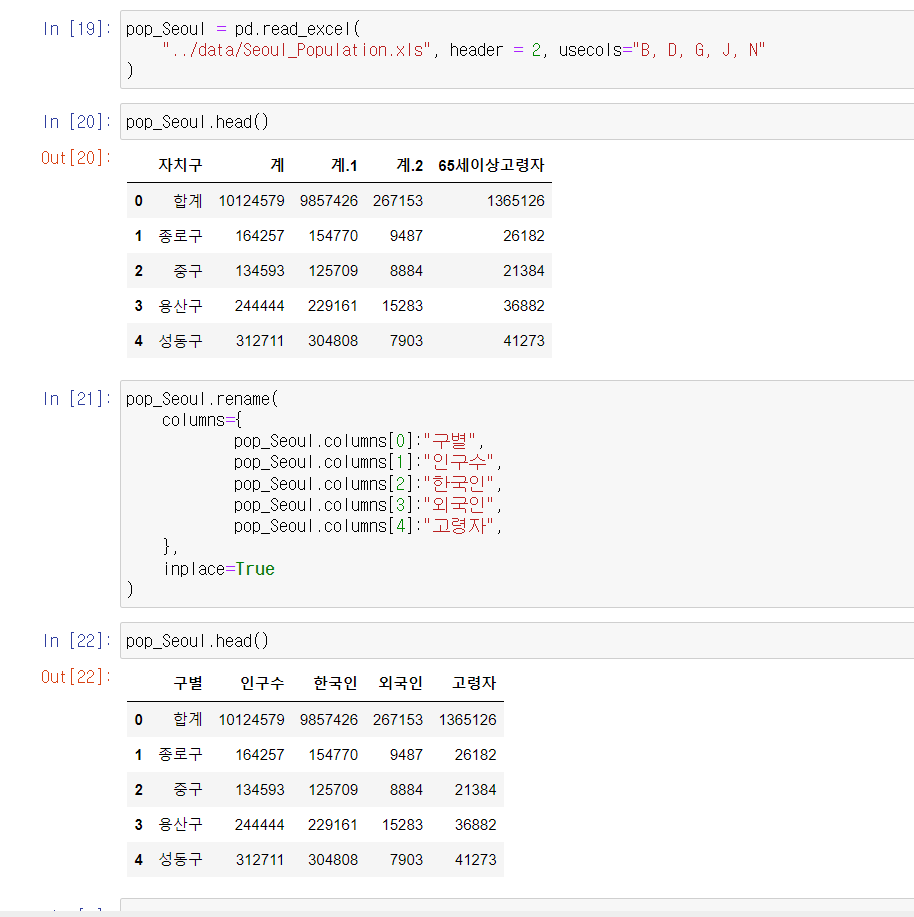
- 변수 = pandas.read_excel("파일 위치", header=#, usecols="B, D, G, J, N")
>> header가 2라면 index 1행부터 읽기 시작함
>> usecols는 불러올 column 지정
열 이름 변경
- (pandas 모듈 불렀고, csv도 변수에 저장하였을 때)
- 예시
변수.rename(columns={변수.columns[0]: "원하는 이름"}, inplace=True)
변수.head() - index 열은 열로 치지 않기에 column[0]는 인덱스 바로 옆 열을 의미.
- 변경되는 column name 위 표에 초록색으로 표시하였음
- 예시
Jupyter Notebook 실습
- miniconda3로 activate 환경 >> 해당 폴더로 이동 (cd 명령어 이용) >> jupyter notebook 명령
- pandas
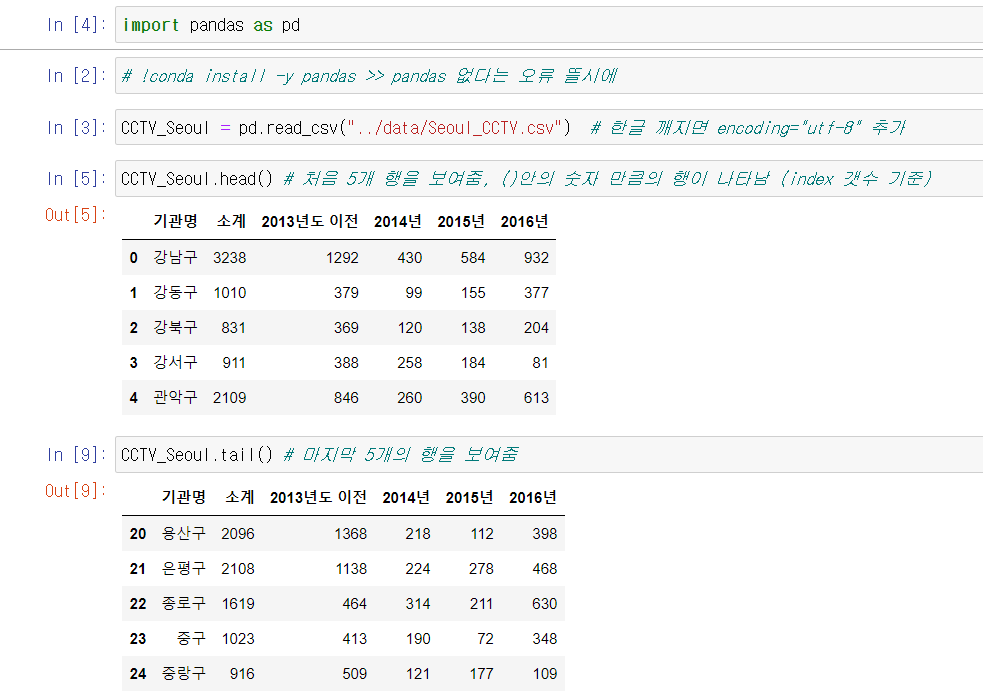
- 변수 = pd.read_csv("파일 위치") or .read_excel()
- 변수.head() >> 해당 데이터의 처음 5개 행을 보여줌
- 변수.tail() >> 마지막 5개 행을 보여줌
- 변수.columns >> 열 이름들을 나열해줌
- 변수.rename(columns={변수.columns[index]:"변경문자"}, inplace=True)
- inplace=True가 없으면 해당 코드에서 출력한 데이터만 바뀌어 나옴
- 원본의 column 명명을 바꿔주는 것이라고 이해
- ../ >> 상위 폴더 이동 명령
- jupyter에서 code line이 파란색일때 m키를 누르면 markdown 형식으로 넘어감
- 반대로 y 키를 누르면 coding 형식으로 넘어감

새싹 데이터 분석가 https://github.com/KulangK