J. Xie, L. Xu, and E. Chen, “Image denoising and inpainting with deep neural networks” 논문을 리뷰해보는 시간을 갖겠습니다.
Abstract
low-level vision problem 해결을 위해 sparse coding과 denoising autoencoder(DA)를 결합한 접근법 제시
또한 DA를 효과적으로 학습시킬 수 있는 "alternative training scheme"도 제시
이러한 접근법과 학습방법으로 기존엔 다루지 못했던 복잡한 문제들(이미지 위에 자막과 같은 pattern을 제거하는 task 등)과 더 나아가 blind inpainting(inpainting 되어야 할 image region에 대한 사전 정보 없이 inpainting task를 수행하는 task)에서 좋은 결과를 보임
Introduction
Image를 얻을 때 얻어지는 방식이나 인위적인 편집등에 의해서 Image가 손상되는 경우가 있음.
Image restoration의 목표는 이러한 손상된 Image로부터 손상되기 전 original image를 구하는 것임.
Denoising과 inpainting 둘 다 그 자체로도 의미가 있지만, preprocessing과 같은 다양한 곳에 활용이 가능.
Denoising의 경우 Image가 Gaussian noise를 받았을 때, Inpainting의 경우 Image에 특정 pixel값이 없을 때 정도로 예를 들 수 있음.
여기서는 denoising과 blind inpainting에 초점을 맞춰 진행.
Model Description
Problem Formulation
가 우리가 얻은 noisy image, 가 original image라고 가정했을 때 Image 손상 process는 다음과 같은 식으로 쓸 수 있음.
= (y)
: → 의 손상 process이고 input에 대해 손상을 일으키는 함수라고 생각하면 됨.
그렇다면 denoising task는 다음과 같이 정의할 수 있음
=
즉 을 가장 잘 근사할 수 있는 함수 를 찾는 것임.
Denoising Auto-encoder
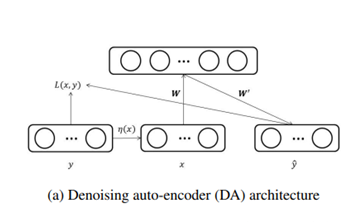
위 사진은 Denoising Autoencoder의 구조
( = 1,2,3,.....,)를 original data, 를 가 손상된 버젼이라고 가정했을 때, DA 는 다음과 같은 수식으로 정의 가능함
= (
=
(x) = (1+exp(-)) : sigmoid function
: hidden layer activation
: 의 근삿값
= : weights, biases
DA 학습의 경우 다음과 같은 reconstruction loss 함수 사용
=
한 DA를 학습해놓고, 그 DA의 hidden layer의 output을 다음 DA의 input으로 사용해 학습시키면 stacked denoising auto-encoder(SDA)가 만들어짐
Stacked Sparse Denoising Auto-encoders
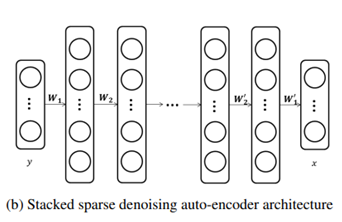
Stacked Sparse Denoising Autoencoder의 구조와 oprimization 방법에 대한 설명
( = 1, ,2, 3, 4, . . . , ) : 손상된 image
: original image
이 둘을 모델이 받아서 학습을 완료 시, 모델에 noisy image가 들어가면 clean image로 바꿔주는 task를 수행할 수 있음
DA 학습 시, Sparse coding의 이점을 활용하고 over-fitting을 막기 위해 reconstruction loss를 다음과 같이 정의함
= + + (
= + (1 - ), =
와 는 DA 설명할 때 정의했음
는 hideen layer activation의 평균
hidden layer의 sparsity를 위해 작은 를 설정시켜 Hidden layer의 activation 값이 작도록 유도.
따라서 hidden layer의 unit들은 대부분 0이 될 것이고, 이로서 hidden layer의 sparsity를 유지할 수 있음 = sparsity regularization.
첫 DA를 학습시킨 후, 와 를 다음으로 학습시킬 DA의 input으로 사용.
같은 방법으로 학습시킨 K개의 DA를 쌓아서 모델을 구성.
구성된 모델은 다음과 같은 loss로 다시 training
= + (
위의 수식과 달라진 점은 sparsity regularization이 없다는 것.
pre-trained 된 DA들의 weights가 regularization 역할 또한 수행하기 때문.
이 두 가지 training 과정(각 DA들 training, 구성된 model training)에서 opimization은 L-BFGS 알고리즘으로 수행했음.
Experiments
실험할 때는 gray-scale image를 사용했으나, color image로 generalization도 문제 없을 것으로 생각
training set과 test set을 구해서 noise를 가했음.
정량적인 측정 지표로 PSNR을 사용했음.
Denoising White Gaussian Noise
Image에 다양한 표준편차의 Gaussian noise를 가해줬음.
그러한 각각의 noise에 대해 한 SSDA model만으로 학습을 했고, 다양한 hyperparamter로 실험을 해서 가장 좋은 결과에 대해 설명하겠음.
K(DA의 개수)는 2로 설정을 했고, K가 더 많아져도 아주 약간 성능이 좋아질 뿐 계산량만 늘어나기 때문에 2로 설정.
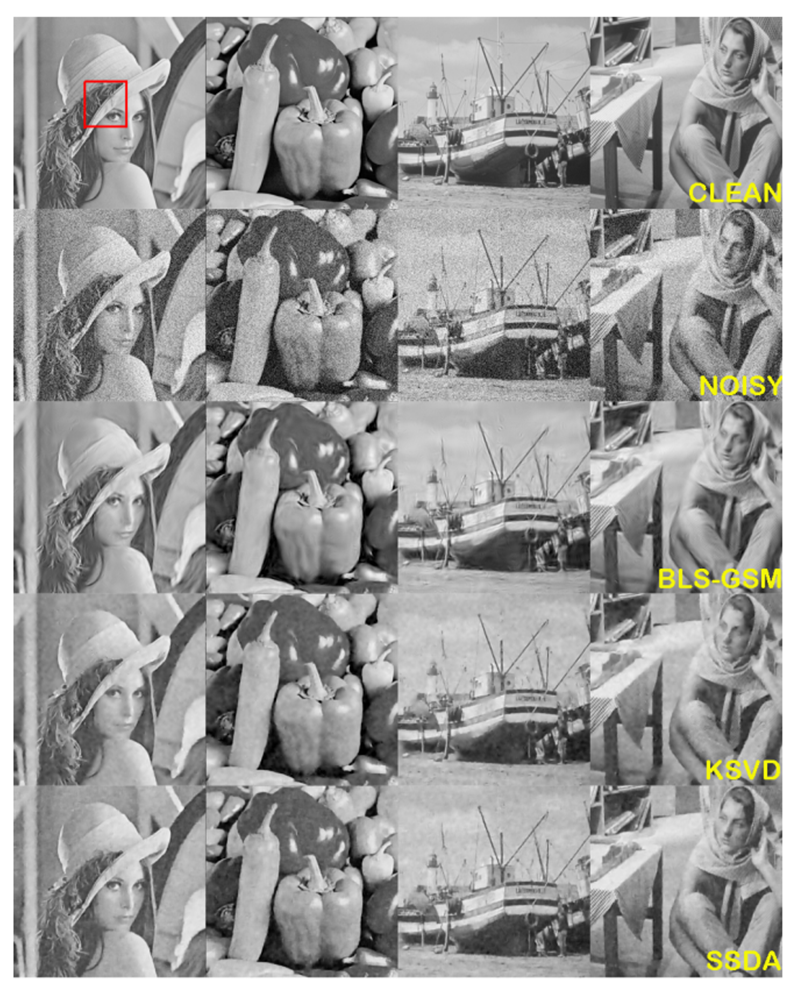
위부터 순서대로 Clean image, Noisy image, BLS-GSM으로 denoising 한 경우, KSVD로 denoising 한 경우, SSDA(proposed method)로 denoising 한 경우
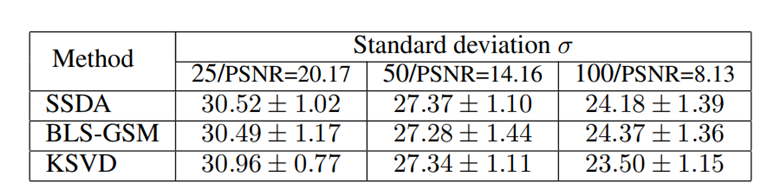
정량적 지표는 다음과 같고 세가지 method 중 눈에 띄는 차이는 없음.

하지만 확대해서 봤을 경우 SSDA가 좀 더 명확한 경계선과 texture detail 복원에 있어서 좋은 성능이 나옴을 확인할 수 있음.
Image Inpainting

Image inpainting task로는 Image위의 text를 제거하는 문제를 선택했음.
하지만 이러한 blind-inpainting task에서 비교할만한 알고리즘을 찾기 어려워 그냥 non-blind algorithm인 KSVD를 선택해서 비교했음.
이미지를 보면 SSDA가 작은 글자는 잘 제거하지만, 큰 글자의 경우에는 흐리게 남아있음을 확인할 수 있음.
하지만 SSDA는 blind algorithm임에도 불구하고 non-blind algorithm인 KSVD와 비교 가능한 수준의 결과물을 만들어냄.
이런 SSDA의 성능이 blind-inpainting task에서 큰 기여를 한다고 생각.
Hidden Layer Feature Analysis
지금까지 denoising auto-encoder를 학습시킬 때, noisy traning data 생성 시 임의의 무작위로 noise distribution을 가하는 것이 일반적이었음.
하지만 noisy data를 생성할 때 specific한 조건에 맞춰서 noise를 준다면 feature learning에 있어서 더욱 효과적일거라고 생각.
여러 noise 별로 DA를 학습시키고 learned feature를 SVM에 반영시켜서 classification 결과를 확인해봤음.
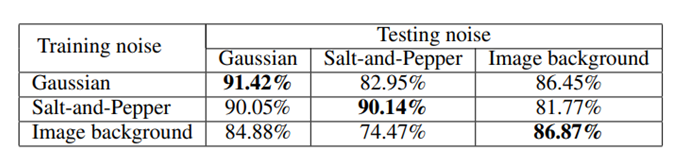
training data와 testing data에 같은 noise를 줬을 경우에 가장 높은 accuracy가 나옴을 확인할 수 있음.
이는 모델을 학습시킬 때 noise를 임의로 주지말고 좀 더 정교한 방법으로 realistic하게 noise를 가하면 더 좋은 결과가 나타날 수 있음을 의미.
Discussion
Prior vs Learned Structure
BLG-GSM과 같은 모델들은 모델 구조를 굉장히 정성스럽게 만들었고, random paramter들이 사용되어도 좋은 결과를 보여줌
하지만 SSDA의 경우 random paramter로 결과를 내면 아무런 의미가 없고, 이는 오로지 결과가 오로지 학습에 의존함을 의미함.
하지만 SSDA와 같은 학습에 의존하는 모델은 매우 다양한 방면에 사용이 가능함.
예를 들어, 약간의 수정만 있으면 audio signal에 대해서도 denoising이 가능하고, missing data를 찾는 preprocessing 과 같은 task에도 사용이 가능함.
Advantages and Limitations
전통적인 inpainting 알고리즘의 경우, inpainting 할 region을 model에 알려줘야 했음.
하지만 이는 시간도 낭비되고 또한 그 자체가 불가능한 상황도 있음.
SSDA의 경우 그런 상황에 있어서 매우 큰 이점을 갖고 있음.
Limitation의 경우 SSDA는 supervised training에 크게 의존한다는 것임.
실험결과 SSDA는 보지 못한 noise pattern들에 대해서 잘 작동했지만, 그러한 noise pattern들은 다 비슷하게 생겼었음.
다시 말하자면 SSDA는 training data에서 본 noise pattern만을 제거할 수 있다는 뜻임.
따라서 SSDA의 경우 특정 procedure에 의해 noise가 생긴 image를 reconstruction 하는 narrow한 task에 적합함.
Conclusion
denoising과 blind inpainting task를 수행할 수 있는 모델을 제시했음.
또한 DA를 효과적으로 학습시키는 방법도 제시했음.
실험에서 다른 method들과 비교 할 만한 좋은 결과도 도출했음.
우리의 non-linear approach가 blind-inpainting에서 이전에는 다루지 못했던 complex problem(ex: image위 text 제거)을 다룰 수 있음을 보였음.
