
#결정트리
Decision Tree 사용
회귀와 분류 둘 다 사용 가능
모델링 과정은 비슷함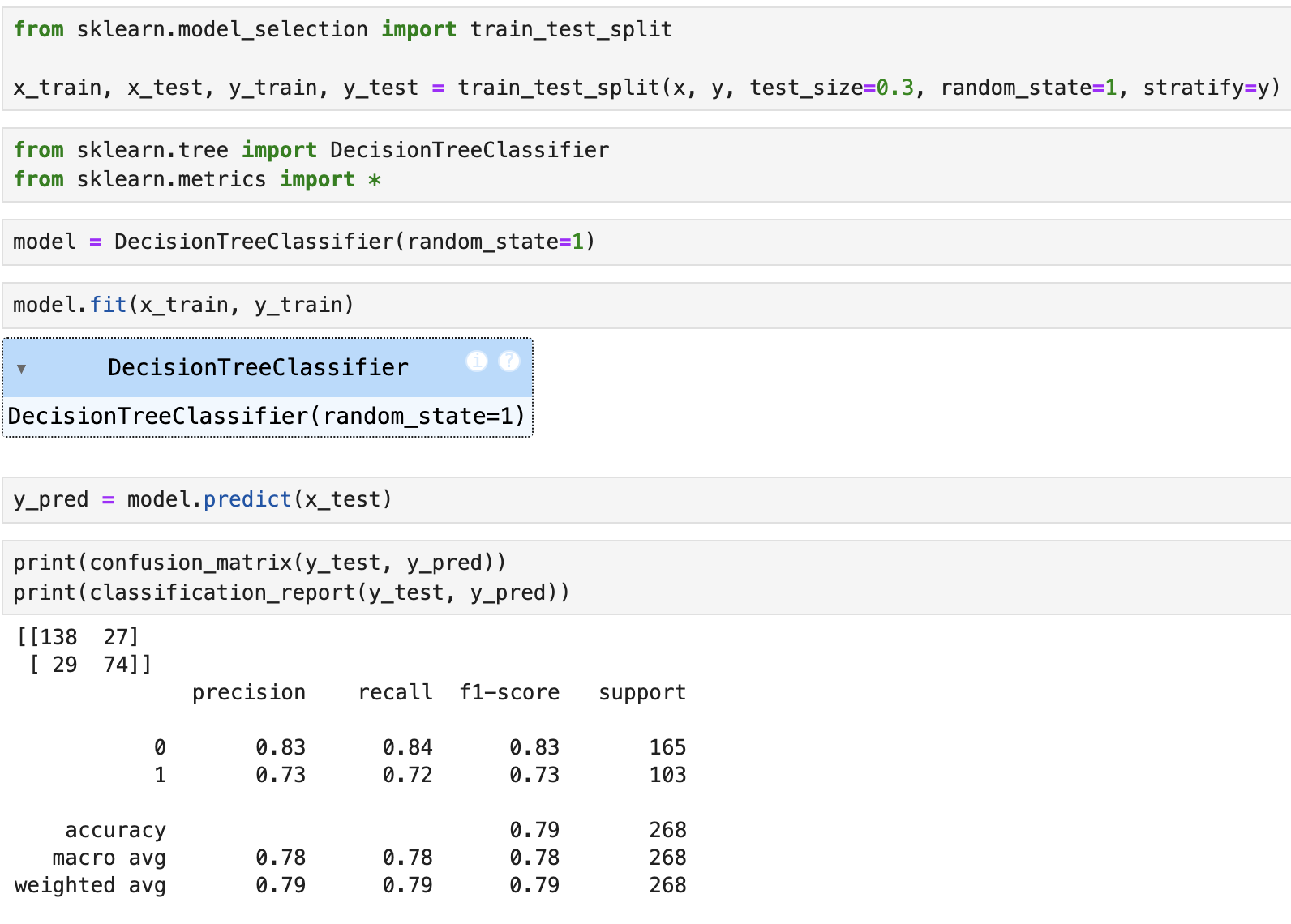
#결정트리 시각화
graphviz를 통해 시각화 가능
여태 배웠던 다른 그래프들도 사용 가능
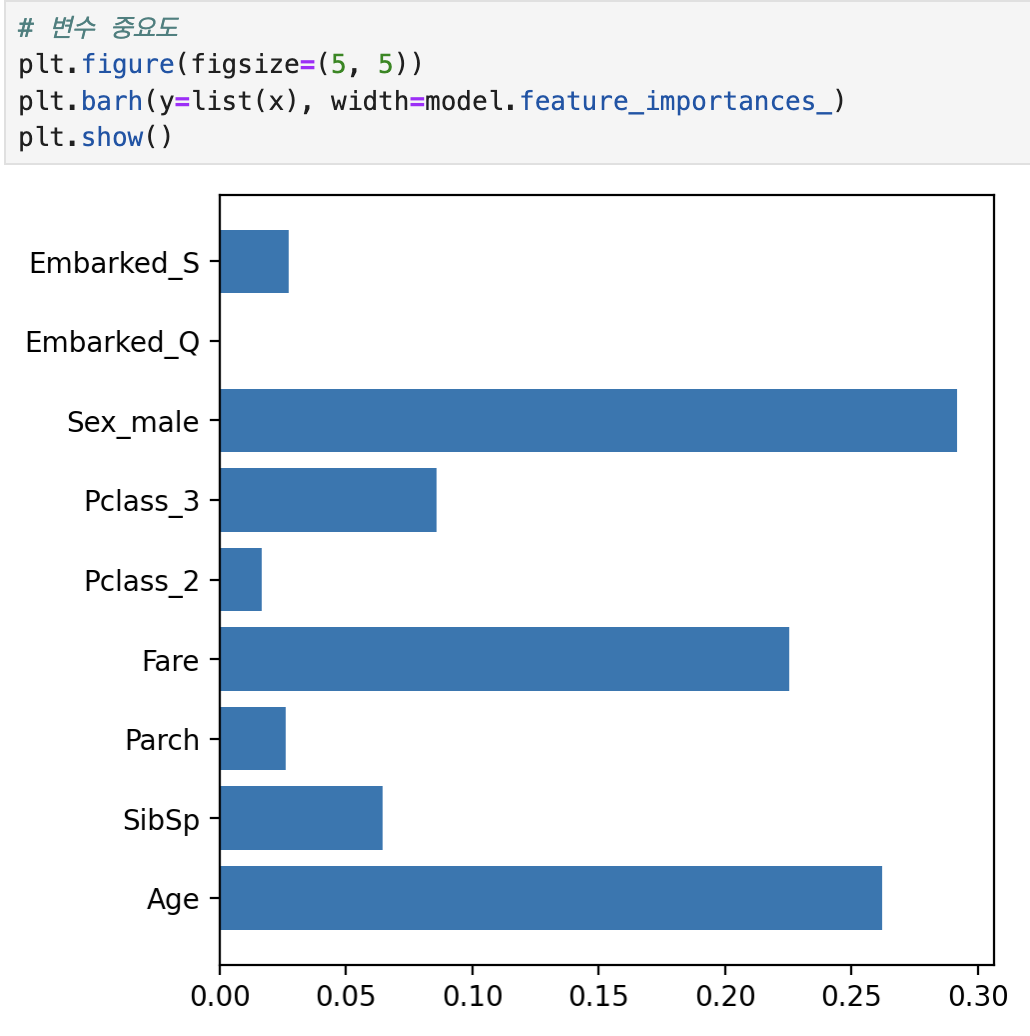
#결정트리 GridSearch
모델의 cross_val_score를 확인하고 모델을 GridSearchCV로 튜닝
이후 학습을 진행
RandomSearch는 튜닝 시 n_iter를 지정해야하지만 GridSearch는 필요 x
scoring은 accuracy가 default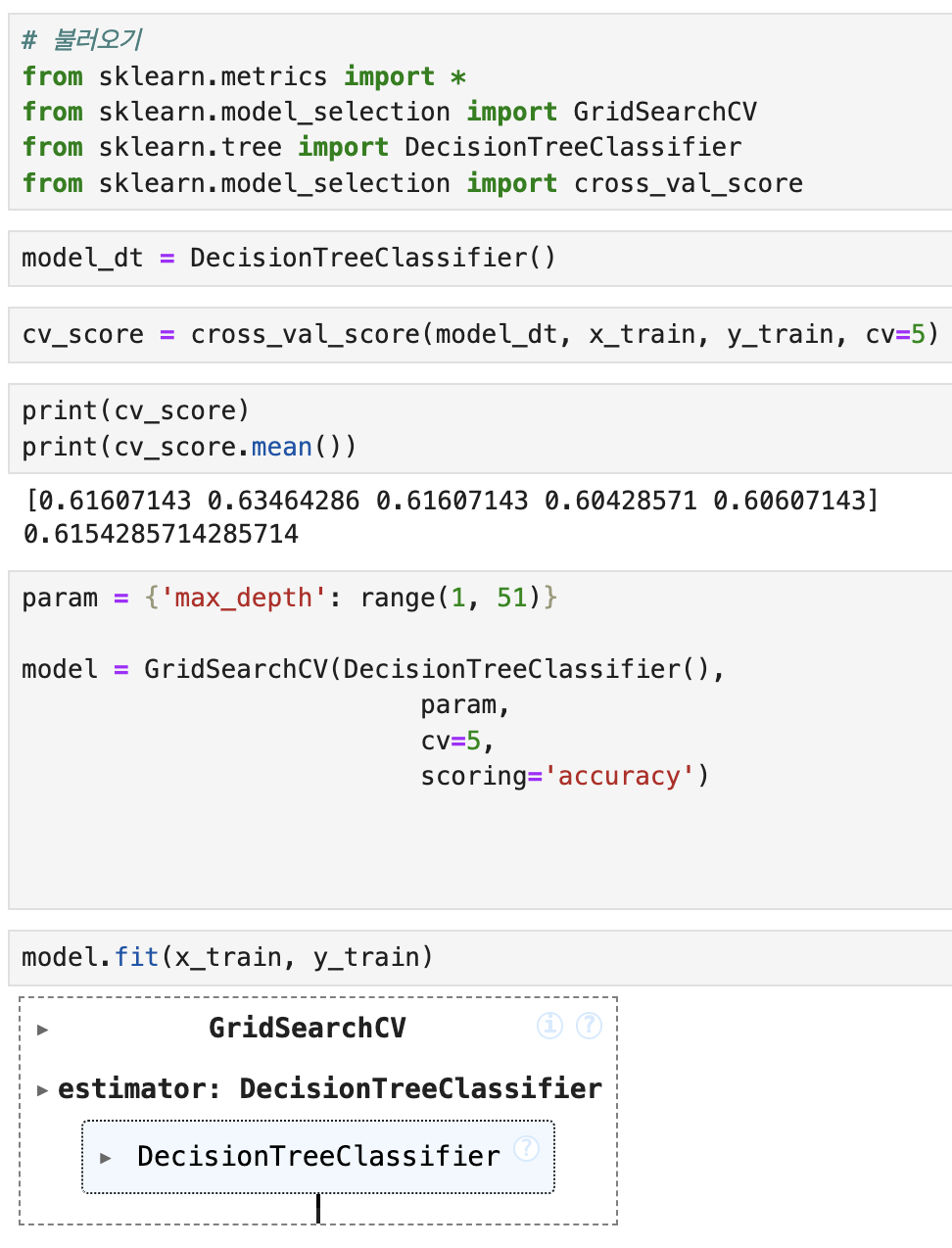
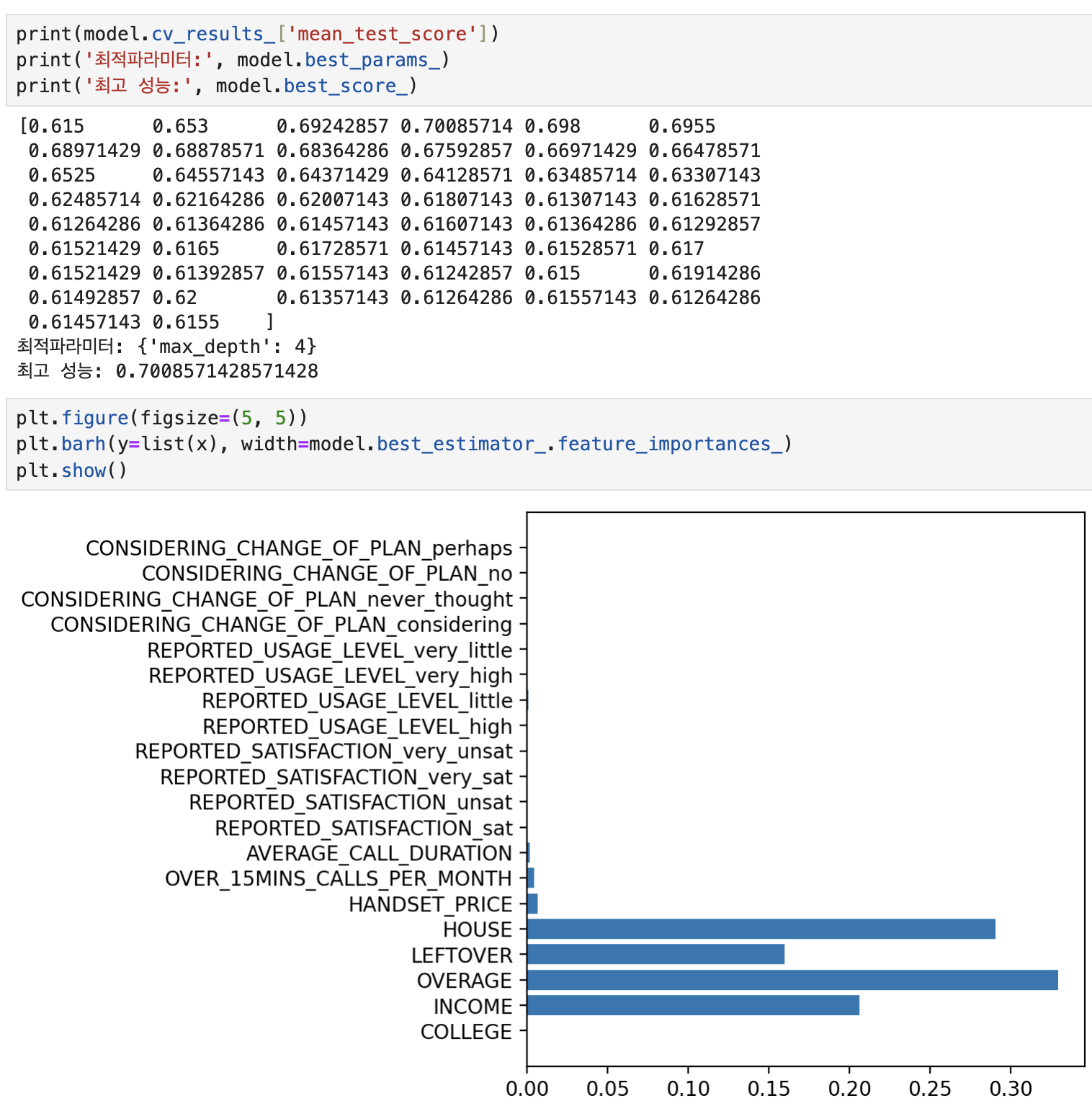
#앙상블
여러 개의 모델을 결합하여 더 정확한 모델을 얻는 방법
1. 보팅
여러 모델들 (다른 유형)의 예측 결과를 투표를 통해 최종 예측을 선정
하드 보팅 : 다수 모델이 예측한 값
소프트 보팅 : 모든 모델이 예측한 값의 결정 확률 평균에서 가장 높은 값
2. 배깅
데이터로부터 부트스트랩한 데이터로 모델들을 학습, 집계
같은 유형의 모델들을 사용 ( 복원 랜덤 샘플링)
범주형 데이터는 보팅, 연속형 데이터는 평균
대표적인 배깅 알고리즘이 Random Forest
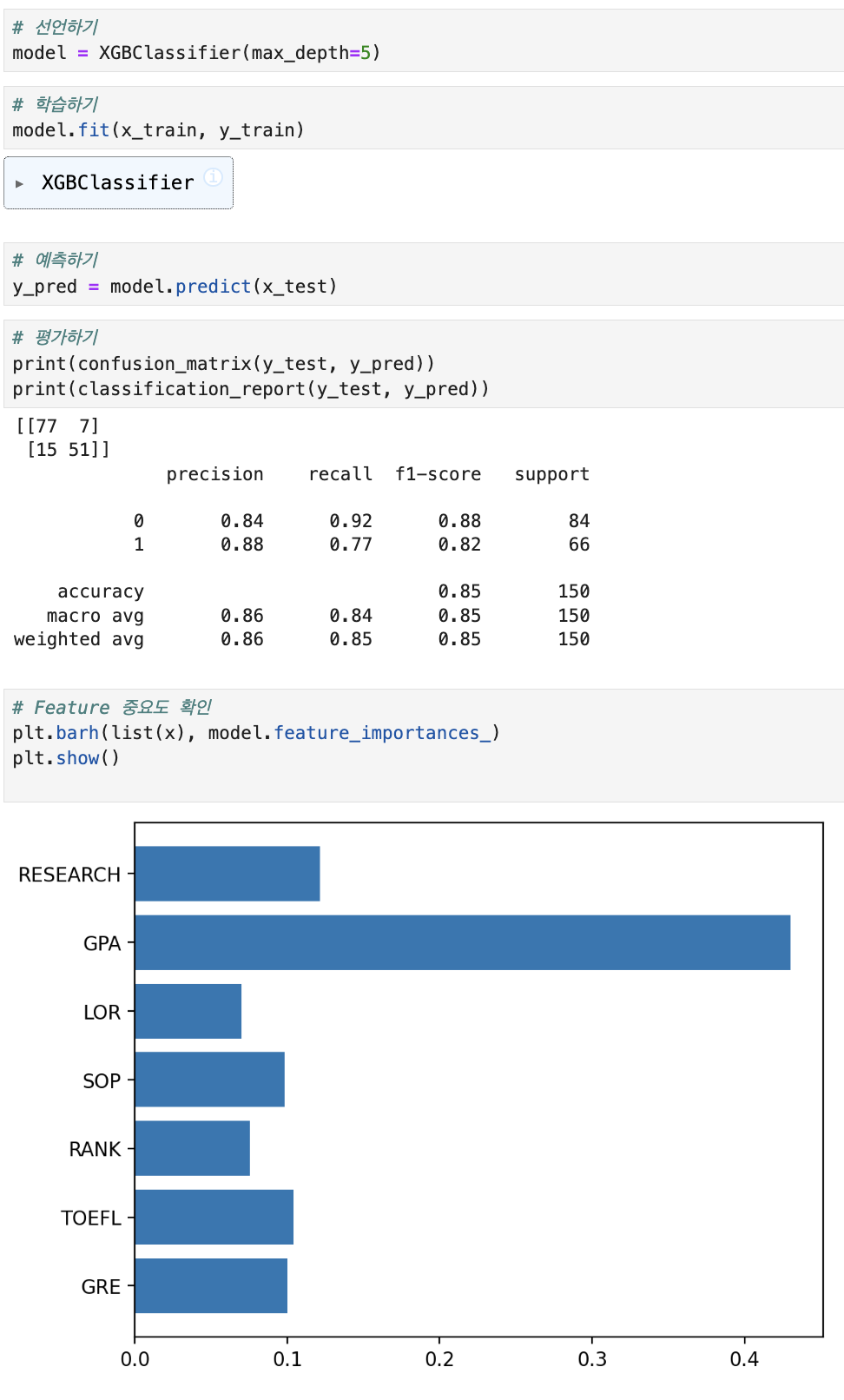
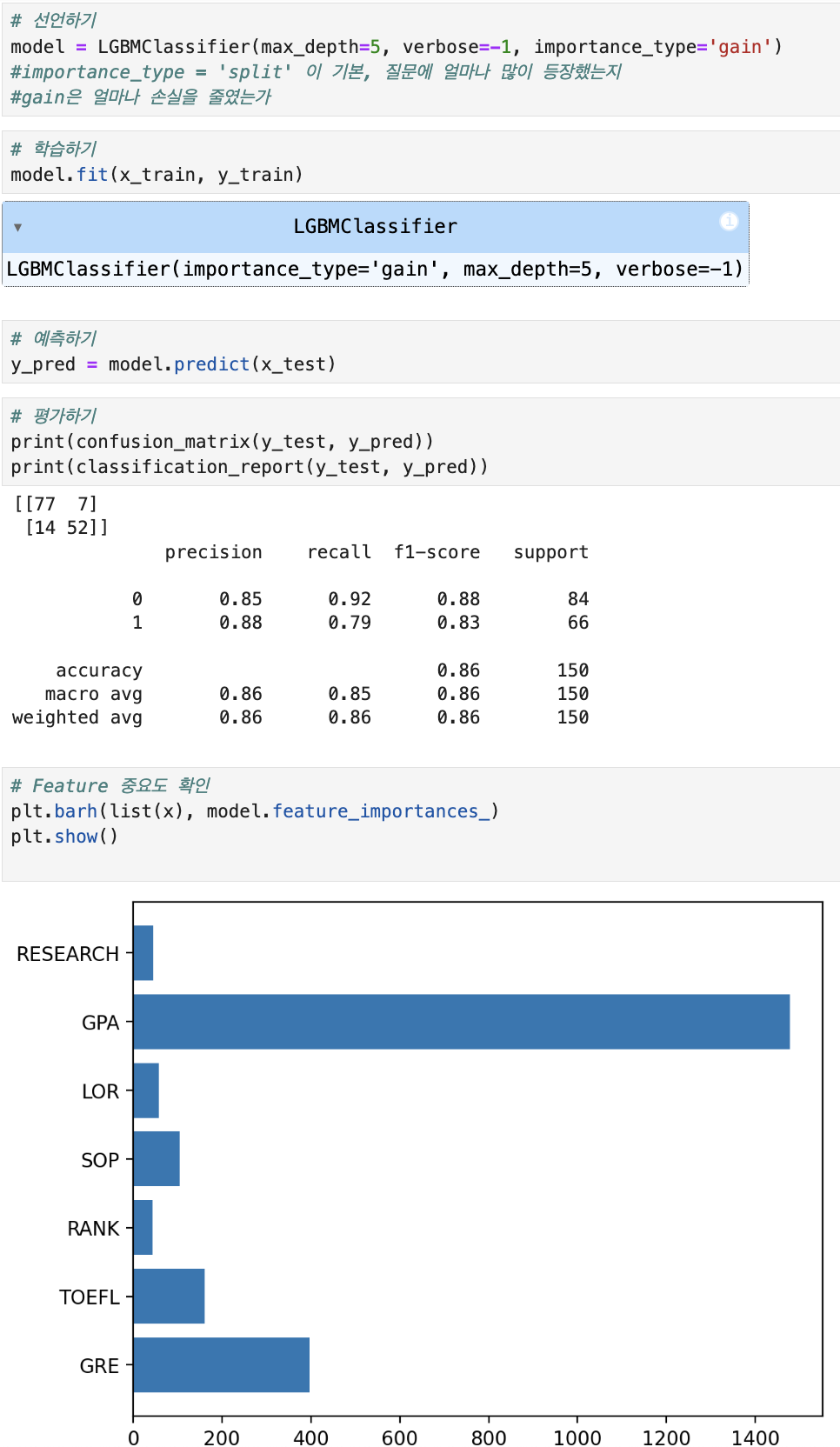
3. 부스팅
같은 유형의 모델들에 대해 순차적으로 학습 수행
이전 모델이 제대로 예측하지 못한 데이터에 가중치를 부여해 다음 모델이 학습
성능이 좋지만 속도가 느리고 과적합 발생 가능성이 있음
대표적인 알고리즘이 XGBoost, LightGBM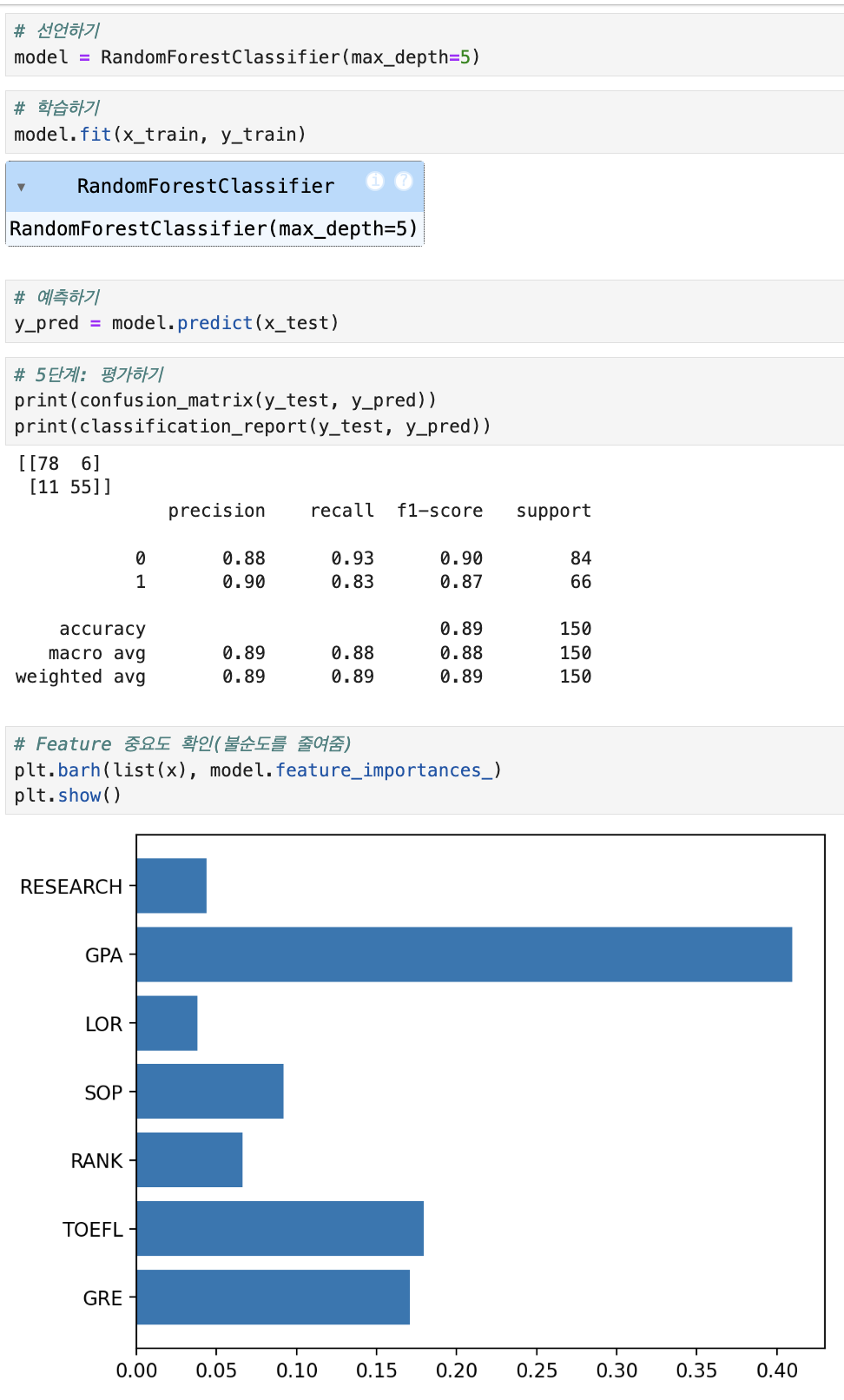

개발꿈나무