
#모델링
머신러닝은 KNN 알고리즘에서만 스케일링이 필수였지만 딥러닝에서는 스케일링이 무조건 전제되어야 함
모델 세팅하기 전까지 전처리는 비슷한 진행
but 모델 선언부터 코드가 달라짐
Sequential([Input(shape=(들어오는 데이터 형태), Dense(처리 후 나올 노드의 개수, activation='활성화 방식', ....])
레이어가 늘어나면 Dense도 늘어남
compile시의 optimizer는 Adam으로 고정하기
learning_rate는 다음 학습과의 간극 (숫자가 크면 한번에 너무 많이 넘어가고 너무 적으면 학습이 많이 진행되지 않음
validation_split은 검증용으로 쓸 데이터의 비율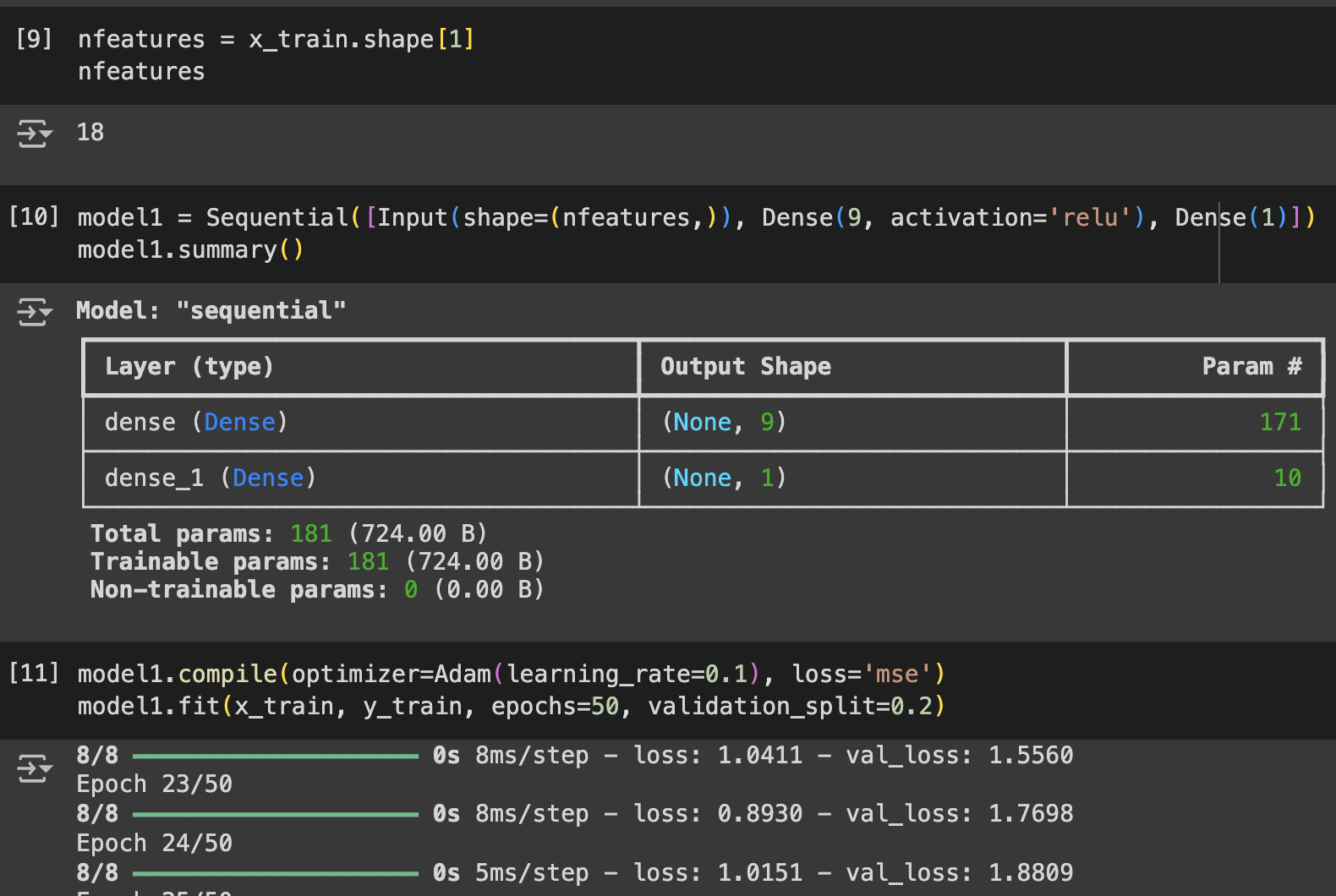
#이진분류
마지막 Dense지정 시 activation을 sigmoid로, compile시 loss를 binary_crossentropy로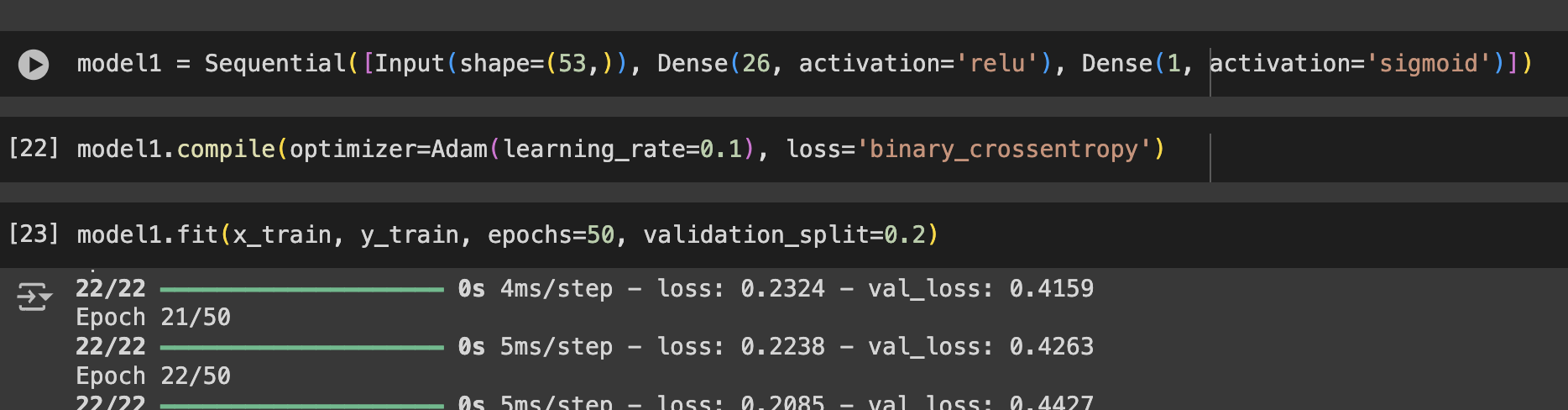
#다중분류
마지막 Dense지정 시 activation을 softmax, compile시 loss를 sparse_categorical_crossentropy로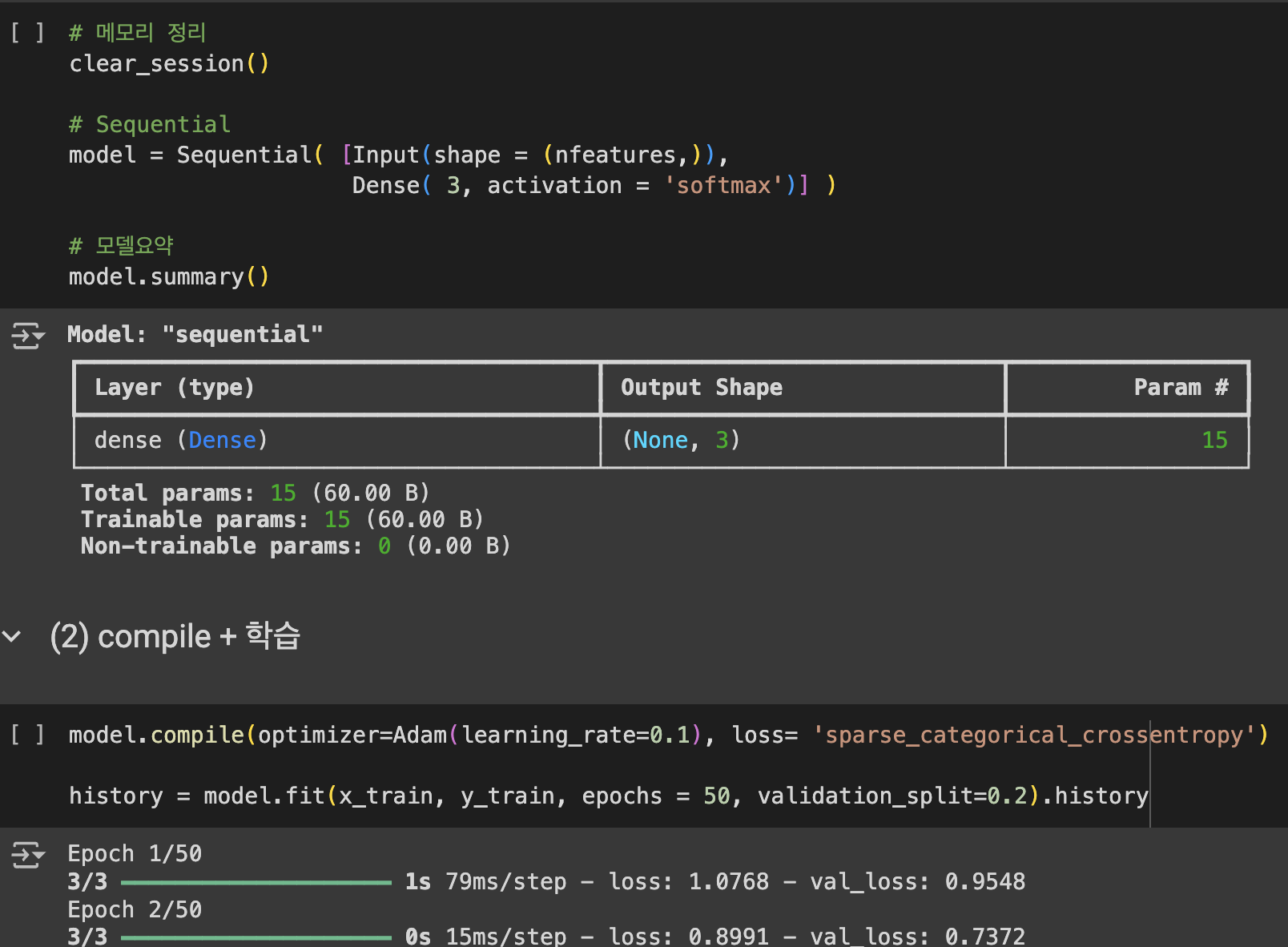

개발꿈나무