
#전처리
1. 결측치 처리
- 결측치가 있는지 확인 후 제거하거나 적절한 값으로 채움
2. 변수 제거
- 분석에 의미가 없다고 판단되는 변수는 제거
3. x, y 분리
- target 변수를 지정 (y로 선언)
- target 이외의 변수들을 x로 선언
- x는 데이터프레임, y는 시리즈
4. 학습용, 평가용 데이터 분리
- 적절한 비율로 분리, 반복 실행시 동일한 결과를 위해 random_state=1 옵션 지정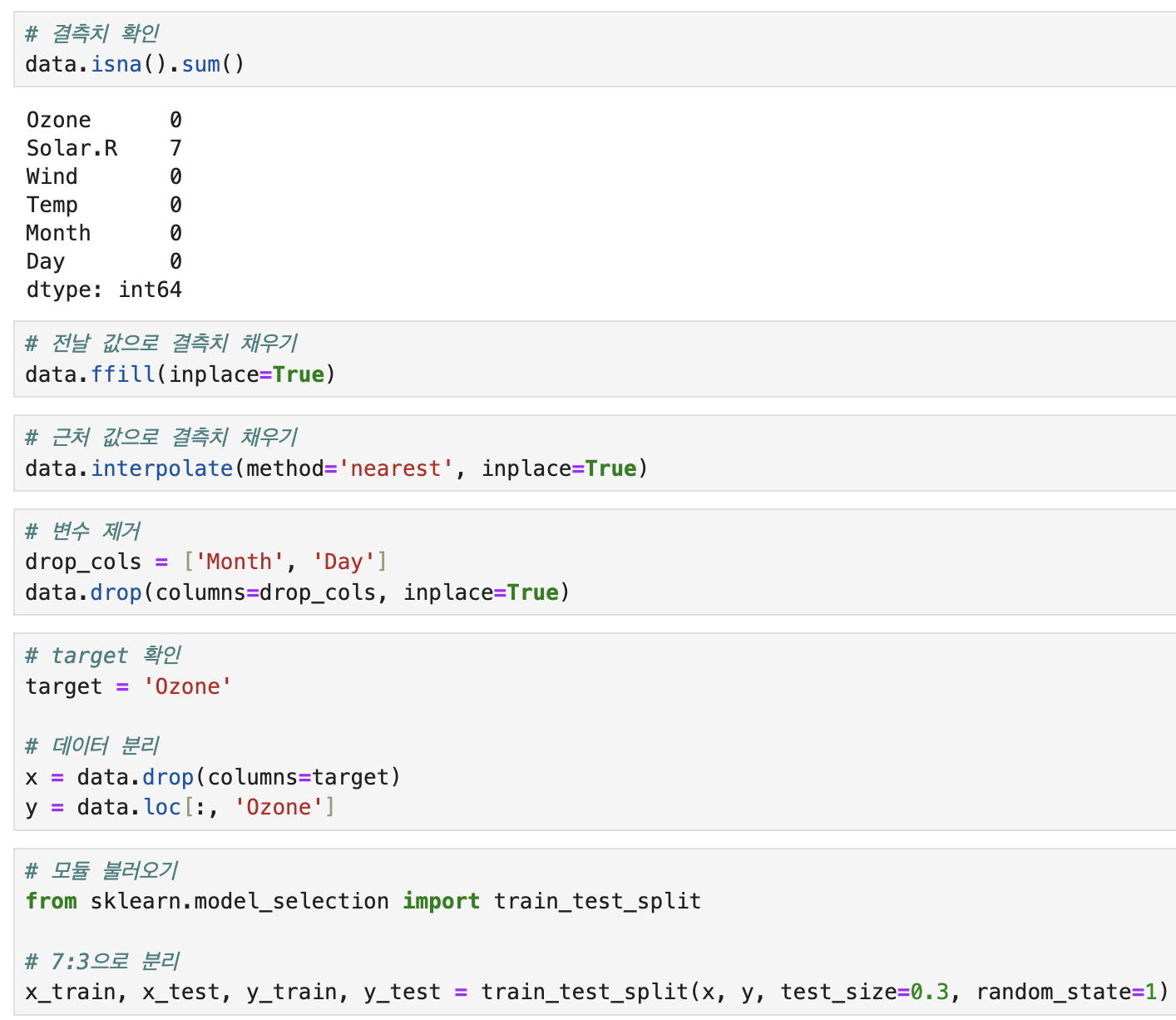
#모델링
회귀문제인지 분류문제인지 명확히 구분
1. 회귀
임의의 수치(연속적인 값)를 예측하는 문제
종속변수가 숫자일 때 사용
2. 분류
임의의 값(이름)을 예측하는 문제
종속변수가 이름일 때 사용1-1. 선형 회귀
모델 기반 학습
특성 & 타깃간 관계를 가장 잘 나타내는 선형 방정식을 구함 (a=기울기, b= y절편)
mean_absolute_error는 값이 작을수록 모델의 성능이 좋음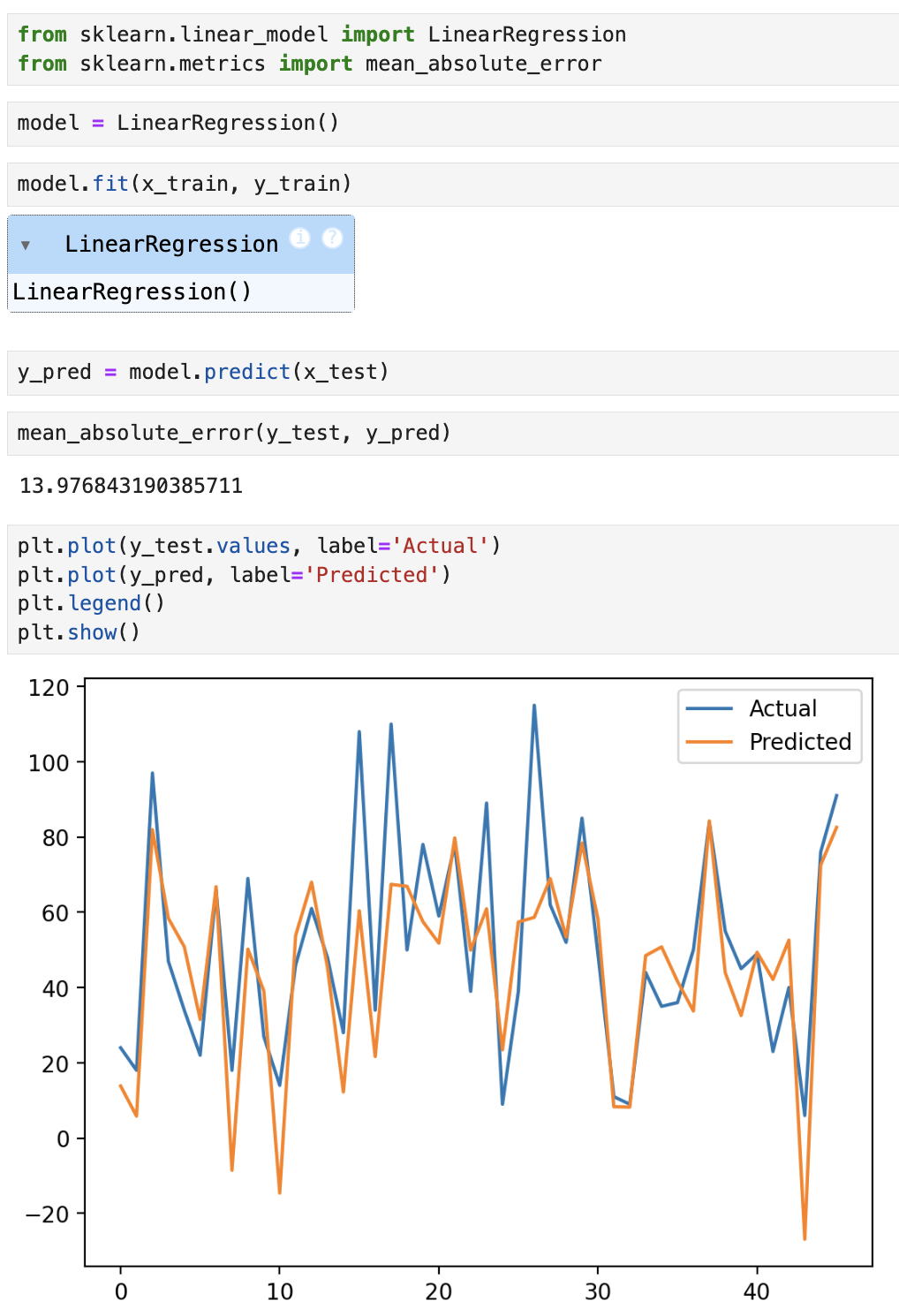
2-1. K-최근접 이웃 분류
사례 기반 학습
학습된 범위 이상 예측이 어려움
데이터 스케일링 필요할 수도 있음
결과를 시각화하기 어려움
1에 가까울수록 정확하게 예측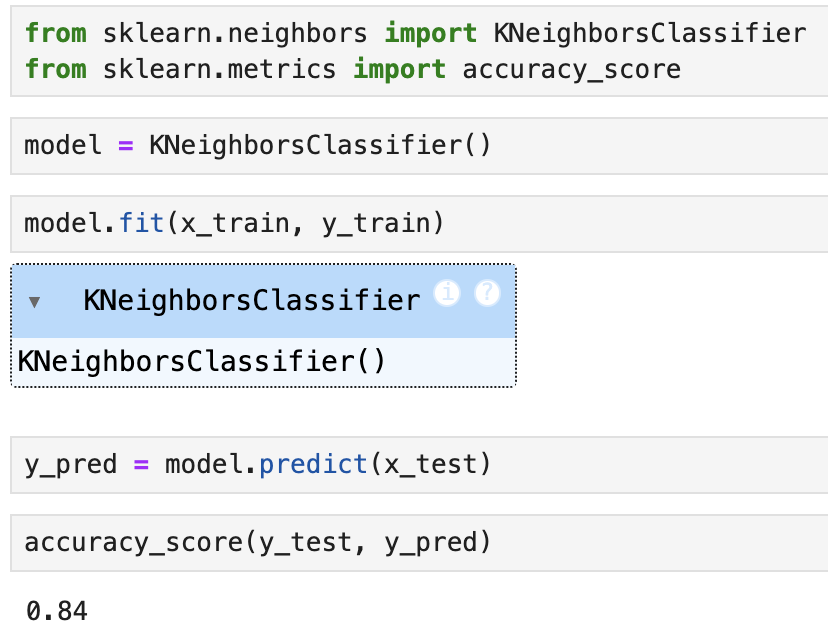
1-2. 회귀 성능 평가
- MAE (평균 절대 오차)
특이값이 많은 경우 사용, 값이 낮을수록 좋음
- MSE (평균 제곱 오차)
값이 낮을수록 좋음
- RMSE (평균 제곱근 오차)
값이 낮을수록 좋음
- MAPE (평균 절대 비율 오차)
값이 낮을수록 좋음
- R2-Score
1에 가까울수록 좋음
2-2. 분류 성능 평가
- accuracy (정확도)
1에 가까울수록 좋음
- precision (정밀도)
1에 가까울수록 좋음
- recall (재현율 = 민감도)
1에 가까울수록 좋음
- F1-Score
1에 가까울수록 좋음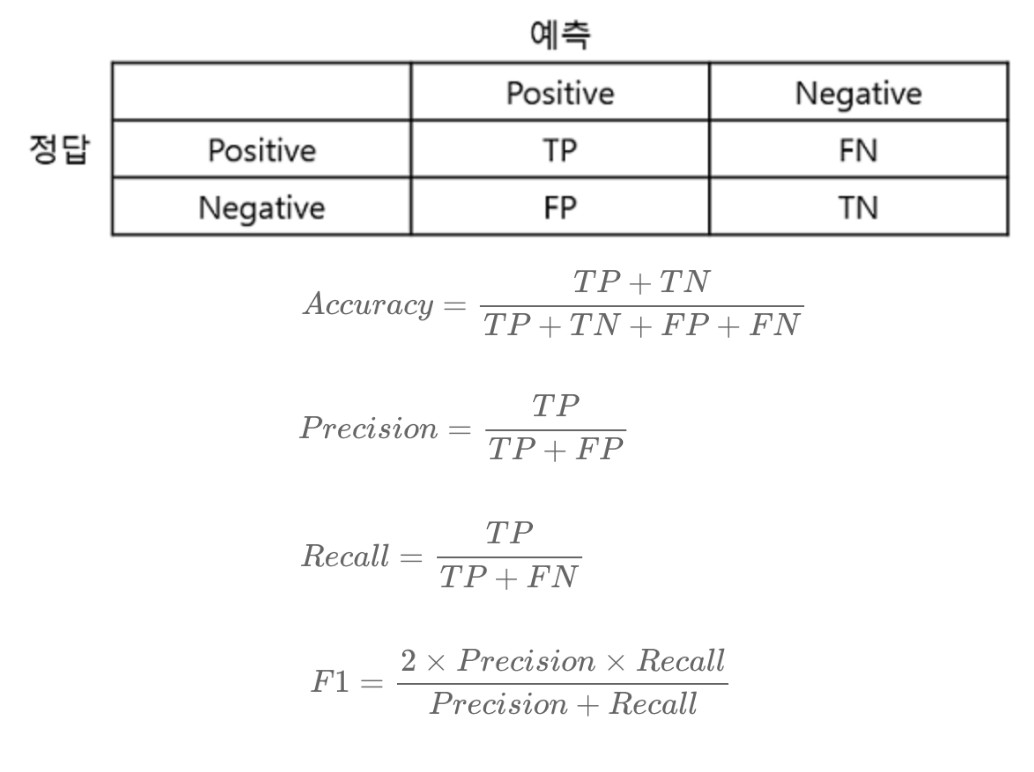
#classification_report
precision은 분류가 먼저
즉 N으로 분류를 먼저 했고 실제 결과도 N일 확률이 0.84라는 뜻
recall은 분류가 나중
즉 실제 결과가 N인데 분류를 N으로 했을 확률이 0.89라는 뜻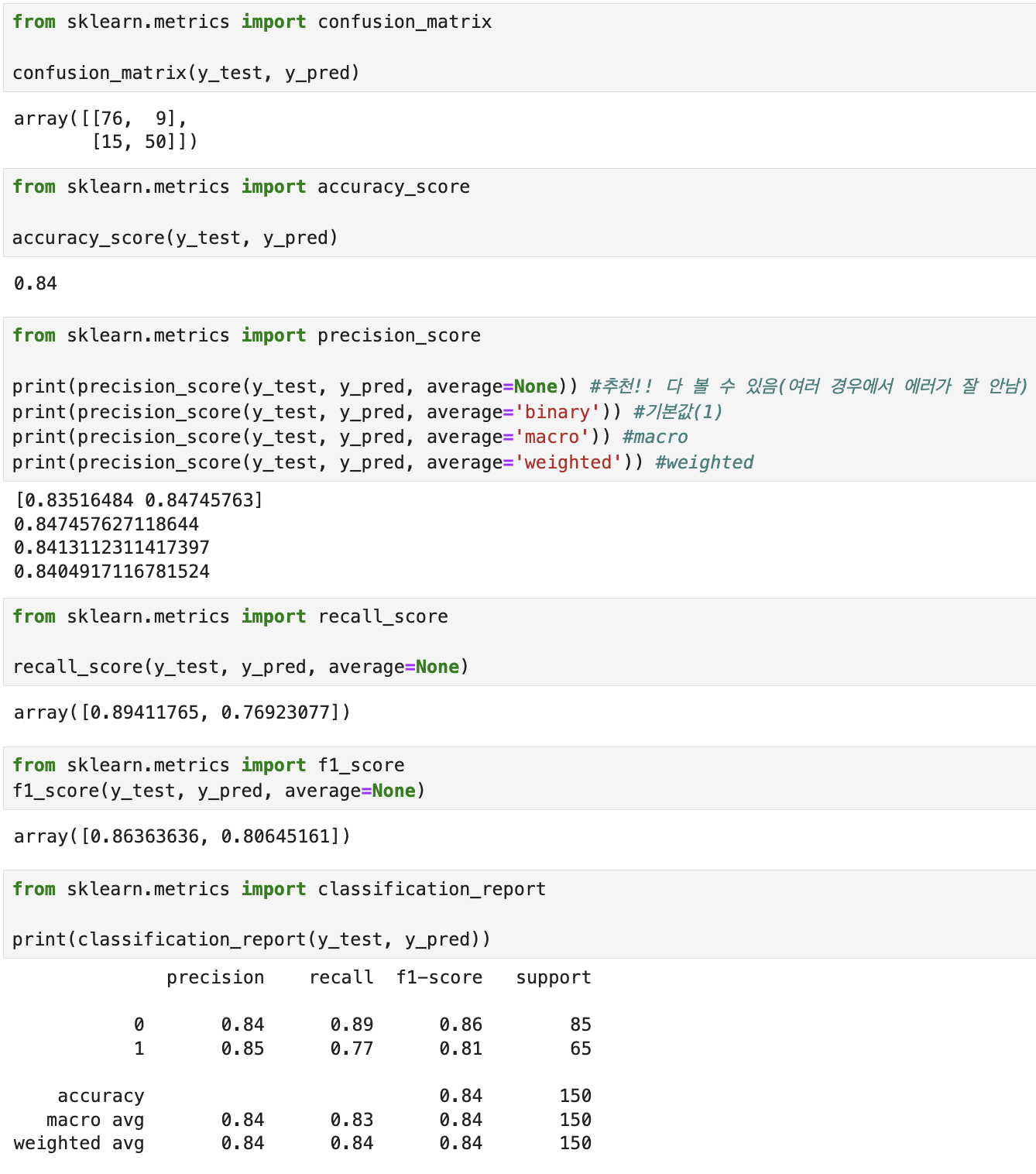

개발꿈나무