이번 포스팅에서는 데이터 관계를 시각화하는 방식들에 대해 글을 작성하겠다.
분량이 얼마 되지 않아 짧은 포스팅이 될것같다.
히트맵, 라인플롯, 산점도, 회귀선을 포함한 산점도를 살펴볼 예정이다.
데이터 관계 시각화
1. 히트맵(Heatmap)
히트맵은 데이터 간 관계를 색상으로 표현한 그래프이다.
비교해야할 데이터가 많을 때 주로 사용하며, heatmap() 함수를 이용한다.
이번에는 비행기 탑승자 수 데이터(연도별, 월별 탑승자 수를 나타내는 데이터)를 활용하여 진행해보겠다.
우선 데이터를 불러와 확인해보자.
Code
import seaborn as sns
flights = sns.load_dataset('flights') # 비행기 탑승자 수 데이터 불러오기
flights.head()Result
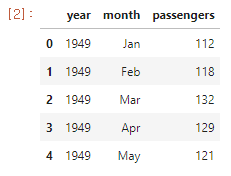
데이터 확인 결과 범주형 데이터 2개 (year, month)와 수치형 데이터 1개 (passengers)가 존재한다.
이 데이터를 히트맵을 그리는 데 활용하려면 데이터 구조를 바꾸어주어야한다.
이는 pandas의 pivot()함수를 사용하여 진행한다.
pivot() 함수 : index와 columns 파라미터에 전달한 피처를 각각 행과 열로 지정하고, values 파라미터에 전달한 피처를 합한 표를 반환한다.
pivot()함수 공식 문서 링크
여기서 알고 싶은 것은 각 연도의 월별 승객 수 이므로, month를 행으로, year를 열로, 합산할 데이터를 passengers로 지정한다.
Code
flights_pivot = flights.pivot(index='month',
columns='year',
values='passengers')
flights_pivotResult
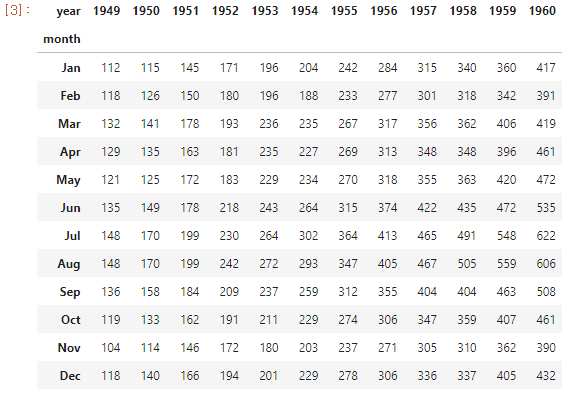
다음과 같이 각 연도의 월별 탑승자 수를 나타내는 표를 만들었다.
하지만 숫자로만 표시되고 나열되어 있어 추이까지는 한눈에 파악하기 힘들다.
이럴 때 사용하는 그래프가 히트맵이다!!!
flights_pivot 데이터를 히트맵으로 표현해보자.
Code
sns.heatmap(data=flights_pivot)
Result
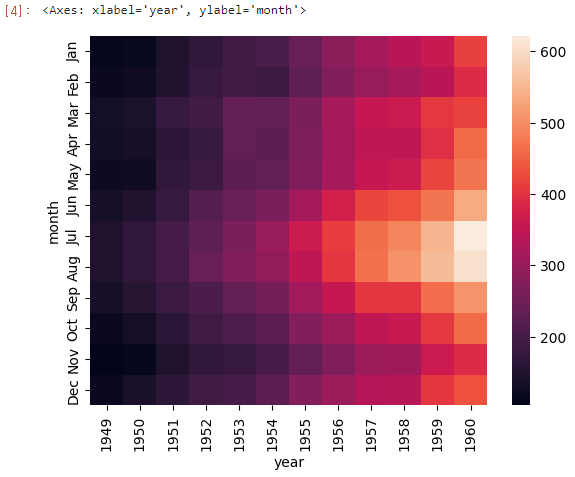
히트맵으로 표현하니 표로 볼 때보다 전체적인 양상을 훨씬 더 쉽게 알아볼 수 있다!
2. 라인플롯(lineplot)
라인플롯은 두 수치형 데이터 사이의 관계를 나타낼 때 사용한다.
기본적으로 x파라미터에 전달한 값에 따라 y파라미터에 전달한 값의 평균과 95%의 신뢰구간을 나타낸다.
Code
sns.lineplot(x='year', y='passengers', data=flights)
Result
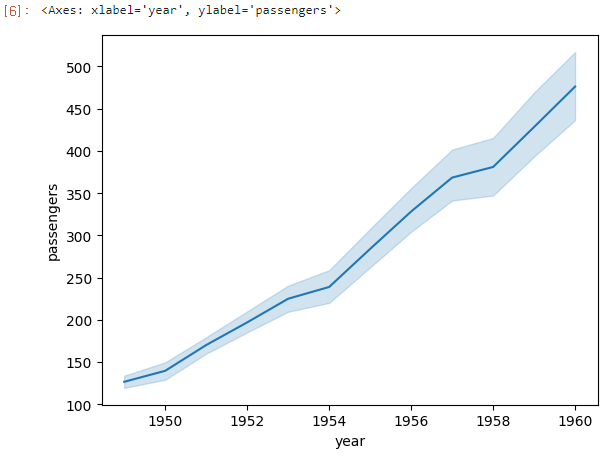
x축은 연도, y축은 평균 승객수나타낸다.
라인플롯 그래프에서 발견할 수 있는 insight
- 해가 갈수록 평균 승객 수가 많아진다.
- 실선 주변의 음영은 95% 신뢰구간을 나타낸다.
3. 산점도(scatterplot)
산점도는 두 데이터의 관계를 점으로 표현하는 그래프이다.
산점도 그래프를 보기 위해 총 비용과 팁 정보를 모아둔 tips 데이터셋을 활용하겠다.
Code
tips = sns.load_dataset('tips') # 팁 데이터 불러오기
tips.head()Result
이 데이터의 산점도를 그려보겠다.
Code
sns.scatterplot(x='total_bill', y='tip', data=tips)
Result
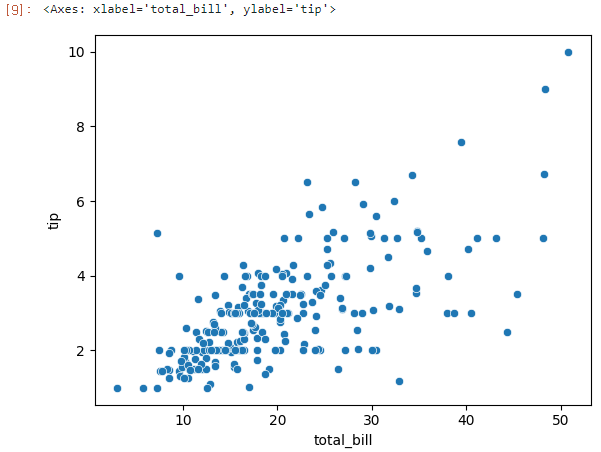
산점도 그래프에서 발견할 수 있는 insight
- 대체로 총액이 늘면 팁도 따라서 늘고 있다.
hue파라미터를 이용하여 특정 범주형 데이터별로 나누어 산점도 그래프를 그릴 수 있다.
다음은 시간(time)에 따라 나누어본 산점도 그래프이다.
Code
sns.scatterplot(x='total_bill', y='tip', hue='time', data=tips)
Result
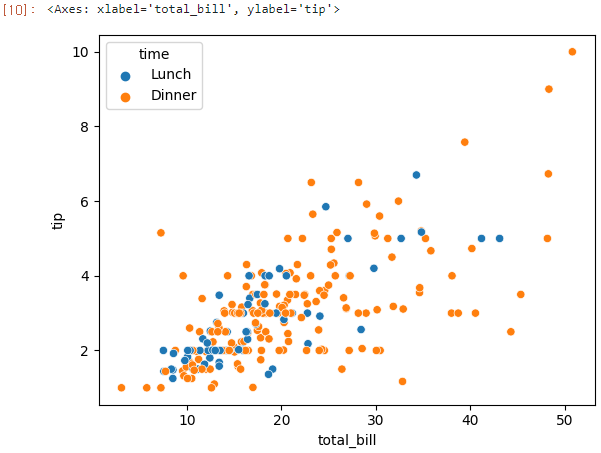
시간(time)에 따른 산점도 그래프에서 발견할 수 있는 insight
- 점심과 저녁으로 구분해 그려봤을 때, 전체적인 추이는 비슷해 보인다.
4. 회귀선을 포함한 산점도 그래프(regplot)
regplot()은 산점도와 선형 회귀선을 동시에 그려주는 함수이다.
회귀선을 그리면 전반적인 상관관계 파악이 좀 더 쉽다.
이번에도 산점도에서 진행했던 것과 동일하게 tips데이터를 활용해 그려보겠다.
Code
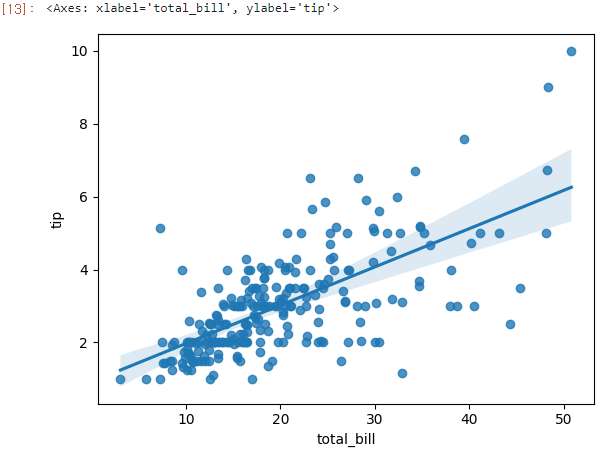
sns.regplot(x='total_bill', y='tip', data=tips)
Result
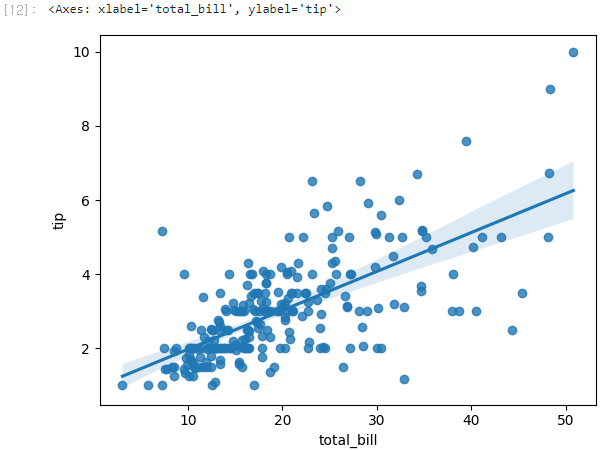
산점도와 함께 선형 회귀선이 나타난 그래프를 볼 수 있다.
선형 회귀선 주변 음영은 95% 신뢰구간을 의미한다.
신뢰구간을 99%로 늘리려면 ci파라미터에 99를 전달하면 된다.
Code
sns.regplot(x='total_bill', y='tip', ci=99, data=tips)
Result
99%의 신뢰구간으로 설정하니 음영 부분이 더 넓어진 것을 확인할 수 있다.
Wrap Up
이번 포스팅에서는 데이터의 관계를 시각화하는 여러 방식에 대해 알아보았다.
이제 다음 장은 2부의 경진대회를 푸는 데 필요한 주요 머신러닝 개념들을 요약, 정리 해둔 장인데, 굳이 글을 통해 정리할 필요는 없을 것 같다.
책에서도 2부에서 경진대회를 풀면서 떠오르지 않는 개념이 있다면 참고해도 좋다고 서술하였으므로, 이렇게 하는 방식으로 진행하고
본격적으로 경진대회로 넘어가기 전에 가볍게 한 번 읽고 넘어가면 좋을 것 같아서 그렇게 하겠다.
또한 관련 개념들을 아예 모르는 상태도 아닐 뿐더러 여러 라이브러리, 모델, 평가 지표 등을 경험해 본 적이 있어 스킵하겠다.
다음 포스팅은 머신러닝 경진대회 가장 첫 시작인
자전거 대여 수요 예측경진대회 시작 전에, 하이퍼파라미터 최적화 기법 중인베이지안 최적화기법은 한번도 사용해보지 않았던 것 같아 책의 내용을 기반으로 간단하게만 포스팅 하고 넘어가겠다.
